


In many practical applications, object pose estimation plays a key role, such as in fields such as embodied intelligence, robot operation, and augmented reality.
In this field, the first task to receive attention isInstance-level 6D pose estimation, which requires annotated data about the target object for model training to make the depth model object-specific properties and cannot be transferred to new objects. Later, the research focus gradually turned tocategory-level 6D pose estimation, which is used to process unseen objects, but requires that the object belongs to a known category of interest.
AndZero-sample 6D pose estimationis a more generalized task setting. Given a CAD model of any object, it aims to detect the target object in the scene and estimate Its 6D pose. Despite its significance, this zero-shot task setting faces significant challenges in both object detection and pose estimation.

## Figure 1. Zero-sample 6D object pose estimation task
Recently, segment all models SAM [1] has attracted much attention, and its excellent zero-sample segmentation ability is eye-catching. SAM achieves high-precision segmentation through various cues, such as pixels, bounding boxes, text and masks, etc., which also provides reliable support for the zero-sample 6D object pose estimation task, demonstrating its promising potential. Therefore, a new zero-sample 6D object pose estimation framework SAM-6D was proposed by researchers from Cross-Dimensional Intelligence, the Chinese University of Hong Kong (Shenzhen), and South China University of Technology. This research has been recognized by CVPR 2024.
Instance Segmentation Model (ISM) and Pose Estimation Model (PEM), to achieve the target from RGB-D scene images ; Among them, ISM uses SAM as an excellent starting point, combined with carefully designed object matching scores to achieve instance segmentation of arbitrary objects, and PEM solves the object pose problem through a local-to-local two-stage point set matching process. An overview of the SAM-6D is shown in Figure 2.
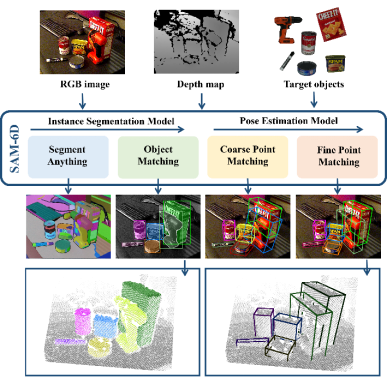
##
Overall, the technical contributions of SAM-6D can be summarized as follows:
SAM-6D is an innovative zero-sample 6D pose estimation framework that gives the CAD of any object The model implements instance segmentation and pose estimation of target objects from RGB-D images, and performs excellently on the seven core data sets of BOP [2].
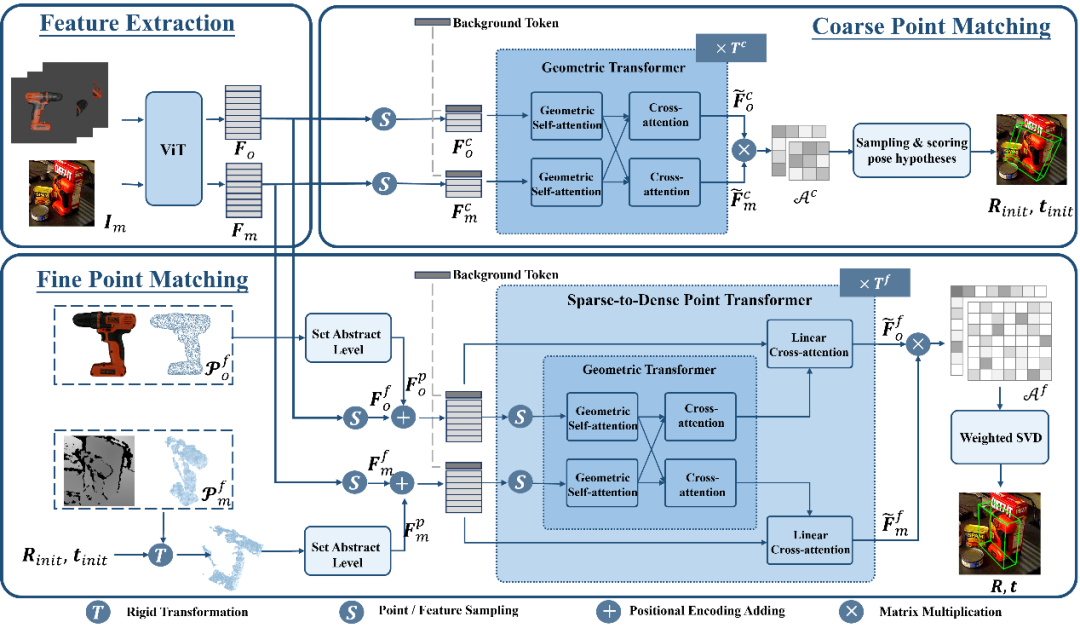
SAM-6D leverages the zero-shot segmentation capability of the segmentation-everything model to generate all possible candidate objects and designs a novel object matching score to identify objects corresponding to the target object. candidate.
SAM-6D regards pose estimation as a local-to-local point set matching problem, adopts a simple but effective Background Token design, and proposes a two-dimensional algorithm for arbitrary objects. Stage point set matching model; the first stage implements coarse point set matching to obtain the initial object pose, and the second stage uses a novel sparse to dense point set transformer to perform fine point set matching to further optimize the pose.
Instance Segmentation Model (ISM)
SAM-6D uses the Instance Segmentation Model (ISM) to detect and segment masks of arbitrary objects .
Given a cluttered scene represented by RGB images, ISM utilizes the zero-shot transfer capability of the Segmentation Everything Model (SAM) to generate all possible candidates. For each candidate object, ISM calculates an object match score to estimate how well it matches the target object in terms of semantics, appearance, and geometry. Finally, by simply setting a matching threshold, instances matching the target object can be identified.
The calculation of the object matching score is obtained by the weighted sum of the three matching items:
Semantic matching items- For the target object, ISM renders multiple views Object template, and use the DINOv2 [3] pre-trained ViT model to extract the semantic features of the candidate object and object template, and calculate the correlation score between them. The semantic matching score is obtained by averaging the top K highest scores, and the object template corresponding to the highest correlation score is regarded as the best matching template.
Appearance matching item- For the best matching template, use the ViT model to extract image block features and calculate the correlation between it and the block features of the candidate object to obtain the appearance matching item Score, used to distinguish semantically similar but visually different objects.
Geometric Match- ISM also designed a geometric match score to account for factors such as differences in shape and size of different objects. The average of the rotation corresponding to the best matching template and the point cloud of the candidate object can give a rough object pose, and the bounding box can be obtained by rigidly transforming and projecting the object CAD model using this pose. Calculating the intersection-over-union (IoU) ratio between the bounding box and the candidate bounding box can obtain the geometric matching score.
Pose Estimation Model (PEM)
For each candidate object that matches the target object, SAM-6D utilizes a Pose Estimation Model (PEM) to predict its relative 6D pose of the object CAD model.
The sampling point sets of segmented candidate objects and object CAD models are represented as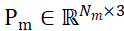 and
and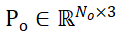 respectively, where N_m and N_o represent the number of their points; at the same time, the characteristics of these two point sets are represented as
respectively, where N_m and N_o represent the number of their points; at the same time, the characteristics of these two point sets are represented as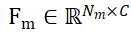 and
and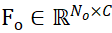 , C represents the number of channels of the feature. The goal of PEM is to obtain an assignment matrix that represents the local-to-local correspondence from P_m to P_o; due to occlusion, P_o only partially matches P_m, and due to segmentation inaccuracy and sensor noise, P_m only partially matches Partial AND matches P_o.
, C represents the number of channels of the feature. The goal of PEM is to obtain an assignment matrix that represents the local-to-local correspondence from P_m to P_o; due to occlusion, P_o only partially matches P_m, and due to segmentation inaccuracy and sensor noise, P_m only partially matches Partial AND matches P_o.
In order to solve the problem of assigning non-overlapping points between two point sets, ISM equips them with Background Tokens, marked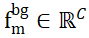 and
and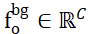 , which can effectively establish local-to-local relationships based on feature similarity. Correspondence. Specifically, the attention matrix can first be calculated as follows:
, which can effectively establish local-to-local relationships based on feature similarity. Correspondence. Specifically, the attention matrix can first be calculated as follows:
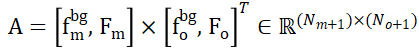
Then the distribution matrix can be obtained
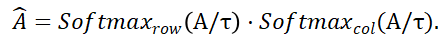
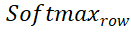 and
and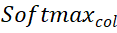 represent softmax operations along rows and columns respectively, and
represent softmax operations along rows and columns respectively, and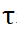 represents a constant. The value of each row in
represents a constant. The value of each row in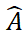 (except the first row) represents the matching probability of each point P_m in the point set P_m with the background and the midpoint of P_o. By locating the index of the maximum score, the point matching P_m can be found ( including background).
(except the first row) represents the matching probability of each point P_m in the point set P_m with the background and the midpoint of P_o. By locating the index of the maximum score, the point matching P_m can be found ( including background).
Once the calculation is , all matching point pairs {(P_m,P_o)} and their matching scores can be gathered, and finally weighted SVD is used to calculate the object pose.
, all matching point pairs {(P_m,P_o)} and their matching scores can be gathered, and finally weighted SVD is used to calculate the object pose.
## Based on the strategy of Background Token, two point set matching stages are designed in PEM. The model structure is shown in Figure 3, which includes three modules:feature extraction, rough point set matching and fine point set matching.
The rough point set matching module implements sparse correspondence to calculate the initial object pose, and then uses the pose to transform the point set of the candidate object to achieve position coding learning.The fine point set matching module combines the position encoding of the sample point sets of the candidate object and the target object, thereby injecting the rough correspondence in the first stage, and further establishing dense correspondence to obtain a more precise object pose. In order to effectively learn dense interactions at this stage, PEM introduces a novel sparse to dense point set transformer, which implements interactions on sparse versions of dense features, and utilizes Linear Transformer [5] to transform the enhanced sparse features into Diffusion back into dense features.
Experimental results
For the two sub-models of SAM-6D, the instance segmentation model (ISM) is built based on SAM without the need for network retraining and finetune, while the pose estimation model (PEM) is provided by MegaPose [4] Large-scale ShapeNet-Objects and Google-Scanned-Objects synthetic datasets for training.
To verify its zero-sample capability, SAM-6D was tested on seven core data sets of BOP [2], including LM-O, T-LESS, TUD-L, IC-BIN, ITODD, HB and YCB-V. Tables 1 and 2 show the comparison of instance segmentation and pose estimation results of different methods on these seven datasets, respectively. Compared with other methods, SAM-6D performs very well on both methods, fully demonstrating its strong generalization ability.
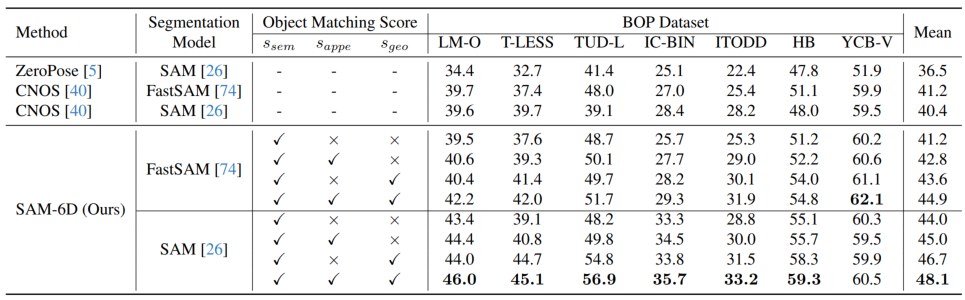
## to be compared.
Table 2. Comparison of attitude estimation results of different methods on the seven core data sets of BOP
Figure 4 shows Visualization results of detection segmentation and 6D pose estimation of SAM-6D on seven BOP data sets, where (a) and (b) are the test RGB images and depth maps respectively, (c) is the given target object, and (d) and (e) are the visualization results of detection segmentation and 6D pose respectively.
## Figure 4. Visualization results of SAM-6D on the seven core data sets of BOP.
For more implementation details of SAM-6D, welcome to read the original paper.References:
[1] Alexander Kirillov et. al., "Segment anything."
[2] Martin Sundermeyer et. al., "Bop challenge 2022 on detection, segmentation and pose estimation of specific rigid objects."
[3] Maxime Oquab et. al., "Dinov2 : Learning robust visual features without supervision."
[4] Yann Labbe et. al., "Megapose: 6d pose estimation of novel objects via render & compare .”
[5] Angelos Katharopoulos et. al., “Transformers are rnns: Fast autoregressive
transformers with linear attention.”
The above is the detailed content of CVPR 2024 | Zero-sample 6D object pose estimation framework SAM-6D, one step closer to embodied intelligence. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



