


Large Language Models (LLMs) have developed rapidly in the past two years, and some phenomenal models and products have emerged, such as GPT-4, Gemini, Claude, etc., but most of them are closed source. There is a large gap between most open source LLMs currently accessible to the research community and closed source LLMs. Therefore, improving the capabilities of open source LLMs and other small models to reduce the gap between them and closed source large models has become a research hotspot in this field.
The powerful capabilities of LLM, especially closed-source LLM, enable scientific researchers and industrial practitioners to utilize the output and knowledge of these large models when training their own models. This process is essentially a knowledge distillation (KD) process, that is, distilling knowledge from a teacher model (such as GPT-4) into a smaller model (such as Llama), which significantly improves the capabilities of the small model. . It can be seen that the knowledge distillation technology of large language models is ubiquitous and is a cost-effective and effective method for researchers to help train and improve their own models.
So, how does the current work utilize closed-source LLM for knowledge distillation and data acquisition? How to efficiently train this knowledge into small models? What powerful skills can small models acquire from teacher models? How does LLM’s knowledge distillation play a role in industry with domain characteristics? These issues deserve in-depth thinking and research.
In 2020, Tao Dacheng's team published "Knowledge Distillation: A Survey", which comprehensively explored the application of knowledge distillation in deep learning. This technology is mainly used for model compression and acceleration. With the rise of large-scale language models, the application fields of knowledge distillation have been continuously expanded, which can not only improve the performance of small models, but also achieve model self-improvement.
In early 2024, Tao Dacheng's team collaborated with the University of Hong Kong and the University of Maryland to publish the latest review "A Survey on Knowledge Distillation of Large Language Models", which summarized 374 related works and discussed how to learn from large language models. Acquire knowledge, train smaller models, and the role of knowledge distillation in model compression and self-training. At the same time, this review also covers the distillation of large language model skills and the distillation of vertical fields, helping researchers to fully understand how to train and improve their own models.

Paper title: A Survey on Knowledge Distillation of Large Language Models
Paper link: https: //arxiv.org/abs/2402.13116
Project link: https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs
Overview Architecture
The overall framework of large language model knowledge distillation is summarized as follows:
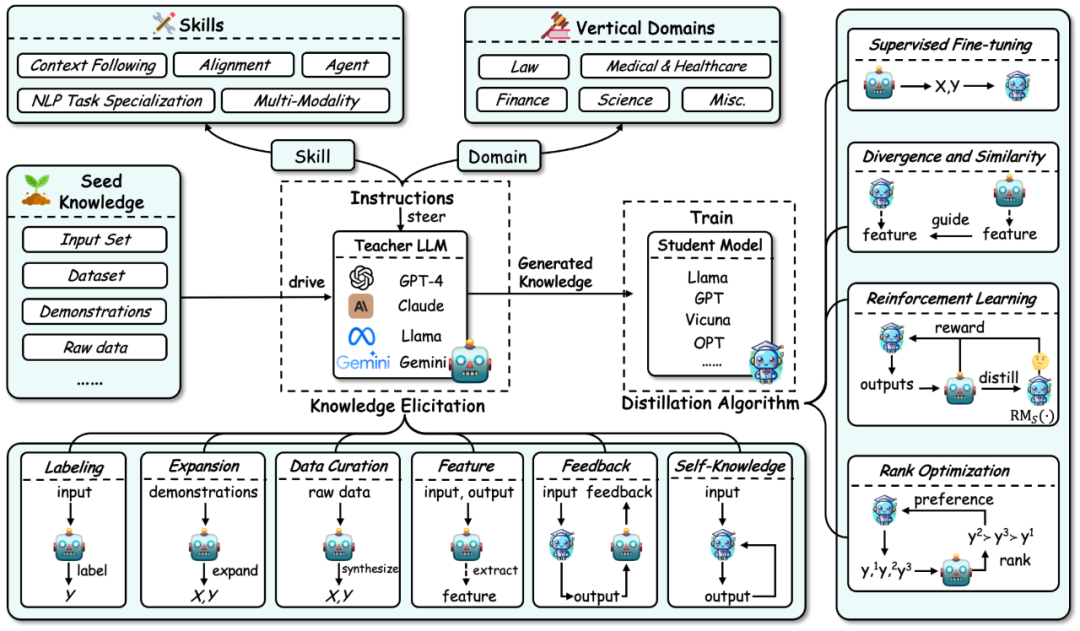
First, According to the process of knowledge distillation of large language models, this review decomposes knowledge distillation into two steps:
1.Knowledge Elicitation: How to obtain knowledge from the teacher model. The process mainly includes:
a) First build instructions to identify the skills or vertical areas of competency to be distilled from the teacher model. b) Then use seed knowledge (such as a certain data set) as input to drive the teacher model and generate corresponding responses, thereby guiding the corresponding knowledge. c) At the same time, the acquisition of knowledge includes some specific technologies: annotation, expansion, synthesis, feature extraction, feedback, and own knowledge. 2.Distillation Algorithms: That is, how to inject the acquired knowledge into the student model. The specific algorithms in this part include: supervised fine-tuning, divergence and similarity, reinforcement learning (reinforcement learning from AI feedback, RLAIF), and ranking optimization.
The classification method of this review summarizes related work from three dimensions based on this process: knowledge distillation algorithms, skill distillation, and vertical field distillation. The latter two are distilled based on knowledge distillation algorithms. The details of this classification and a summary of the corresponding related work are shown in the figure below.
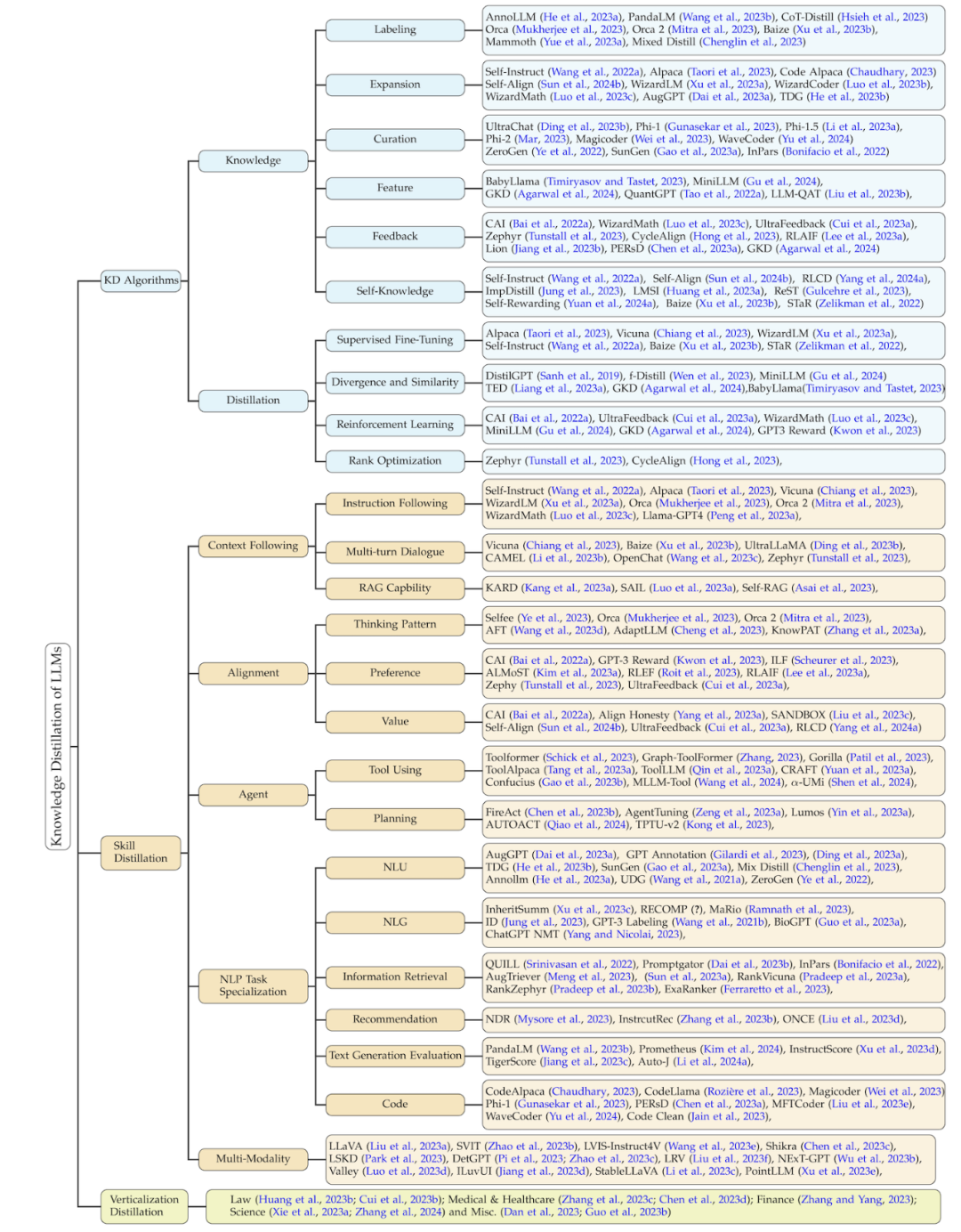
Knowledge distillation algorithm
Knowledge Elicitation
According to the Regarding the ways to acquire knowledge in the teacher model, this review divides its technologies into labeling, expansion, data synthesis, feature extraction, feedback, and self-generated knowledge. knowledge). Examples of each method are shown in the figure below:
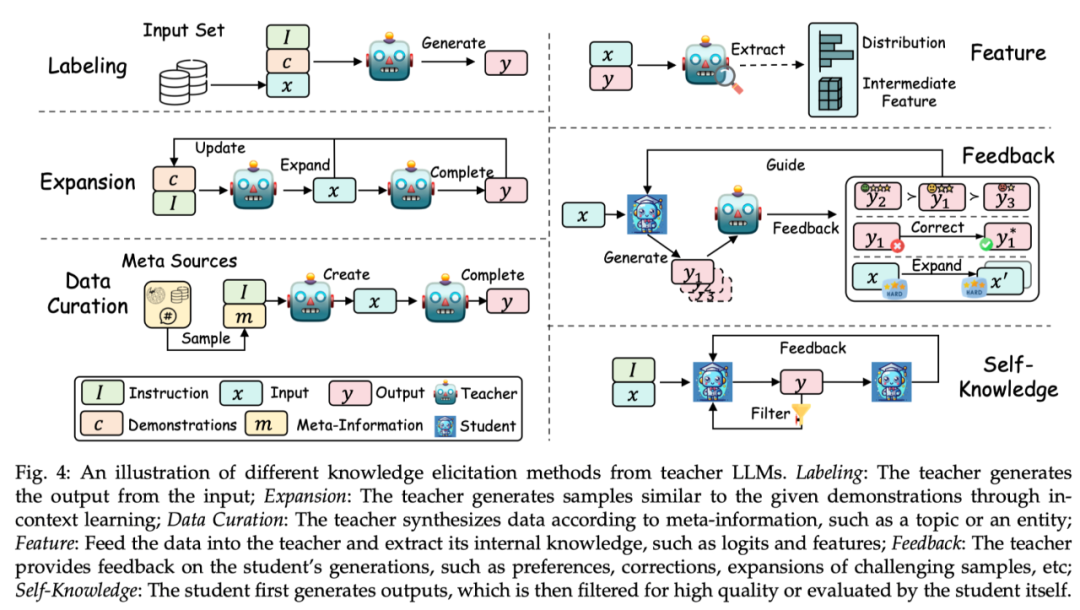
Labeling: Knowledge labeling refers to the teacher LLMs giving instructions based on instructions or examples. Certain inputs are used as seed knowledge to generate corresponding outputs. For example, seed knowledge is the input of a certain data set, and the teacher model labels the output of the thinking chain.
Expansion: A key feature of this technology is to use the contextual learning capabilities of LLMs to generate data similar to the example based on the provided seed example. The advantage is that more diverse and extensive data sets can be generated through examples. However, as the generated data continues to increase, data homogeneity problems may arise.
Data synthesis (Data Curation): A distinctive feature of data synthesis is that it synthesizes data from scratch. It uses a large amount of meta-information (such as topics, knowledge documents, original data, etc.) as diverse and huge amounts of seed knowledge to obtain large-scale and high-quality data sets from teacher LLMs.
Feature acquisition (Feature): The typical method to obtain feature knowledge is to output the input and output sequences to teacher LLMs, and then extract its internal representation. This method is mainly suitable for open source LLMs and is often used for model compression.
Feedback: Feedback knowledge usually provides feedback to the teacher model on the student's output, such as providing preferences, evaluation or correction information to guide students to generate better output.
Self-Knowledge: Knowledge can also be obtained from students themselves, which is called self-generated knowledge. In this case, the same model acts as both teacher and student, iteratively improving itself by distilling techniques and improving its own previously generated output. This approach works well for open source LLMs.
Summary: At present, the extension method is still widely used, and the data synthesis method has gradually become mainstream because it can generate a large amount of high-quality data. Feedback methods can provide knowledge that helps student models improve their alignment capabilities. Feature acquisition and self-generated knowledge methods have become popular due to the use of open source large models as teacher models. The feature acquisition method helps compress open source models, while the self-generated knowledge method can continuously improve large language models. Importantly, the above methods can be effectively combined, and researchers can explore different combinations to elicit more effective knowledge.
Distilling Algorithms
After acquiring knowledge, it needs to be distilled into the student model. Distillation algorithms include: supervised fine-tuning, divergence and similarity, reinforcement learning, and ranking optimization. An example is shown below:
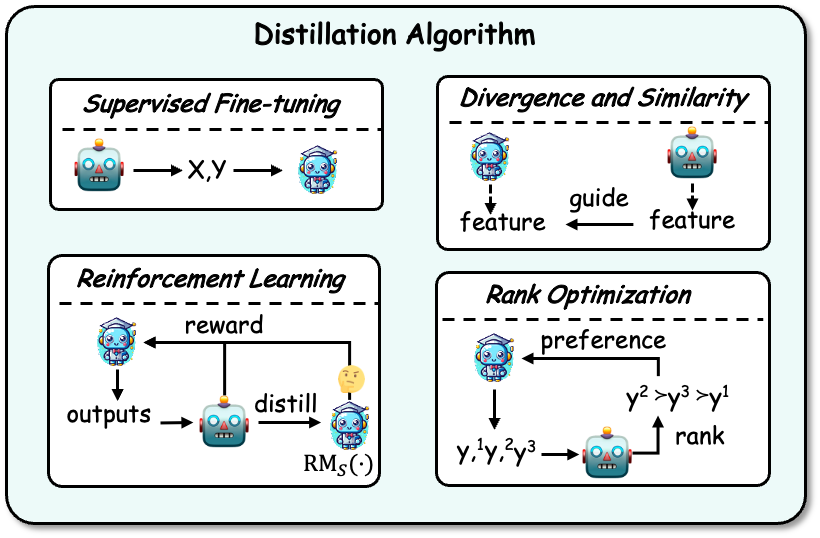
Supervised fine-tuning: Supervised fine-tuning (SFT) fine-tunes the student model by maximizing the likelihood of the sequences generated by the teacher model, allowing the student model to imitate the teacher model. This is currently the most commonly used technique in knowledge distillation of LLMs.
Divergence and Similarity: This algorithm uses the internal parameter knowledge of the teacher model as a supervision signal for student model training, and is suitable for open source teacher models. Methods based on divergence and similarity align probability distributions and hidden states respectively.
Reinforcement Learning: This algorithm is suitable for using teacher feedback knowledge to train student models, that is, RLAIF technology. There are two main aspects: (1) using teacher-generated feedback data to train a student reward model, (2) optimizing the student model by maximizing the expected reward through the trained reward model. Teachers can also serve directly as reward models.
Rank Optimization: Ranking optimization can also inject preference knowledge into the student model. Its advantages are stability and high computational efficiency, such as some classic algorithms such as DPO, RRHF, etc.
SKILL DISTILLATION
As we all know, large language models have many excellent capabilities. Through knowledge distillation technology, instructions are provided to control teachers to generate knowledge containing corresponding skills and train student models so that they can acquire these abilities. These capabilities mainly include capabilities such as following context (such as instructions), alignment, agents, natural language processing (NLP) tasks, and multi-modality.
The following table summarizes the classic work of skill distillation, and also summarizes the skills, seed knowledge, teacher model, student model, knowledge acquisition method, and distillation algorithm involved in each work.
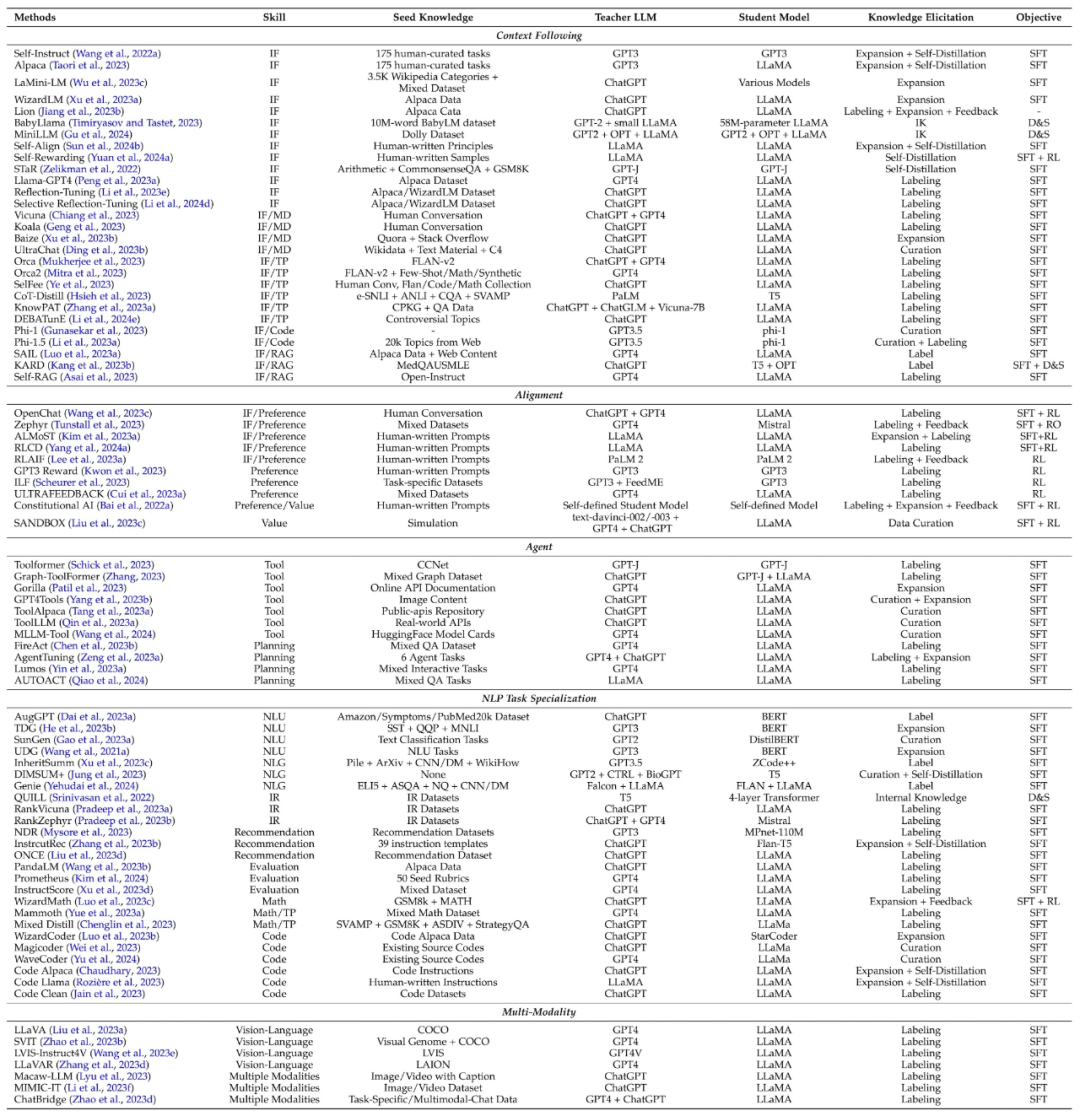
Vertical Domain Distillation
In addition to large language models in general fields, there are now a lot of work training large language models in vertical fields , which helps the research community and industry to apply and deploy large language models. Although large language models (such as GPT-4) have limited domain knowledge in vertical fields, they can still provide some domain knowledge and capabilities or enhance existing domain data sets. The fields involved here mainly include (1) law, (2) medical health, (3) finance, (4) science, and some other fields. The taxonomy and related work in this part are shown below:

Future Directions
This review explores the current large language models Problems in knowledge distillation and potential future research directions mainly include:
Data selection: How to automatically select data to achieve better distillation results?
Multi-teacher distillation: Explore the distillation of knowledge from different teacher models into one student model.
Richer knowledge in the teacher model: You can explore richer knowledge in the teacher model, including feedback and feature knowledge, as well as explore multiple knowledge acquisition methods. combination.
Overcoming catastrophic forgetting during distillation: The ability to effectively preserve the original model during knowledge distillation or transfer remains a challenging issue.
Trusted Knowledge Distillation: At present, KD mainly focuses on distilling various skills, and pays relatively little attention to the credibility of large models.
Weak-to-Strong Distillation(Weak-to-Strong Distillation). OpenAI proposes the concept of "weak-to-strong generalization", which requires exploring innovative technical strategies so that weaker models can effectively guide the learning process of stronger models.
Self-Alignment (Self-Distillation). Instructions can be designed so that the student model autonomously improves and aligns its generated content by generating feedback, criticism, and explanations.
Conclusion
This review provides a comprehensive and comprehensive review of how to use the knowledge of large language models to improve student models, such as open source large language models. Systematically summarized, including the recently popular self-distillation technology. This review divides knowledge distillation into two steps: knowledge acquisition and distillation algorithm, and also summarizes skill distillation and vertical field distillation. Finally, this review explores the future direction of distilling large language models, hoping to push the boundaries of knowledge distillation of large language models and obtain large language models that are more accessible, efficient, effective, and credible.
The above is the detailed content of Summarizing 374 related works, Tao Dacheng's team, together with the University of Hong Kong and UMD, released the latest review of LLM knowledge distillation. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



