


At the beginning of 2024, OpenAI dropped a blockbuster in the field of generative AI: Sora.
In recent years, technological iterations in the field of video generation have continued to accelerate, and many technology companies have also announced relevant technological progress and implementation results. Prior to this, Pika and Runway had launched similar products, but the demo released by Sora clearly single-handedly raised the standards in the field of video generation.
In the future competition, which company will be the first to create a product that surpasses Sora is still unknown.
Domestically, attention is focused on a number of major technology companies.
Previously, it was reported that Bytedance had developed a video generation model called Boximator before the release of Sora.
Boximator provides a way to precisely control the generation of objects in videos. Users do not need to write complex text instructions, but simply draw a box in the reference image to select the target, and then add additional boxes and lines to define the target's end position or the entire cross-frame motion path, as shown in the following figure:

ByteDance has maintained a low-key attitude towards this. Relevant people responded to the media that Boximator is their project to research technical methods for controlling object movement in the field of video generation. It is not yet fully finished, and there is still a big gap between it and leading foreign video generation models in terms of picture quality, fidelity and video duration.
It is mentioned in the relevant technical paper (https://arxiv.org/abs/2402.01566) that Boximator runs as a plug-in and can be easily integrated with existing video generation models. Integrate. By adding motion control capabilities, it not only maintains video quality but also improves flexibility and usability.
Video generation involves technologies in multiple subdivisions and is closely related to image/video understanding, image generation, super-resolution and other technologies. After in-depth research, it was found that ByteDance has publicly published some research results in multiple branches.
This article will introduce 9 studies from ByteDance’s intelligent creation team, involving many latest achievements such as Wensheng Picture, Wensheng Video, Tusheng Video, and Video Understanding. We might as well track the technological progress of exploring visual generative models from these studies.
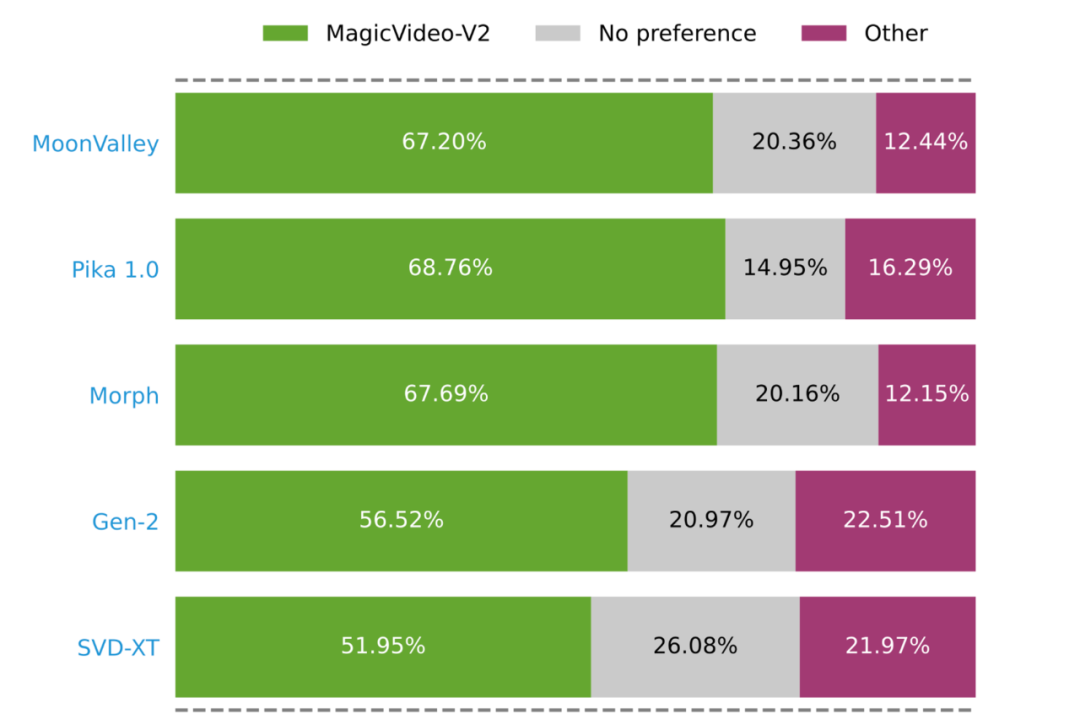
In early January this year, ByteDance released a video generation model MagicVideo-V2, which once triggered heated discussions in the community.

The innovation of MagicVideo-V2 is the text-to-image model, video motion generator, reference The image embedding module and frame interpolation module are integrated into the end-to-end video generation pipeline. Thanks to this architectural design, MagicVideo-V2 can maintain a stable high-level performance in terms of "aesthetics", not only generating beautiful high-resolution videos, but also having relatively good fidelity and smoothness.
Specifically, the researchers first used the T2I module to create a 1024×1024 image that encapsulates the described scene. The I2V module then animates this static image to generate a 600×600×32 sequence of frames, with the underlying noise ensuring continuity from the initial frame. The V2V module enhances these frames to 1048×1048 resolution while refining the video content. Finally, the interpolation module extends the sequence to 94 frames, resulting in a 1048×1048 resolution video, and the generated video has high aesthetic quality and temporal smoothness.
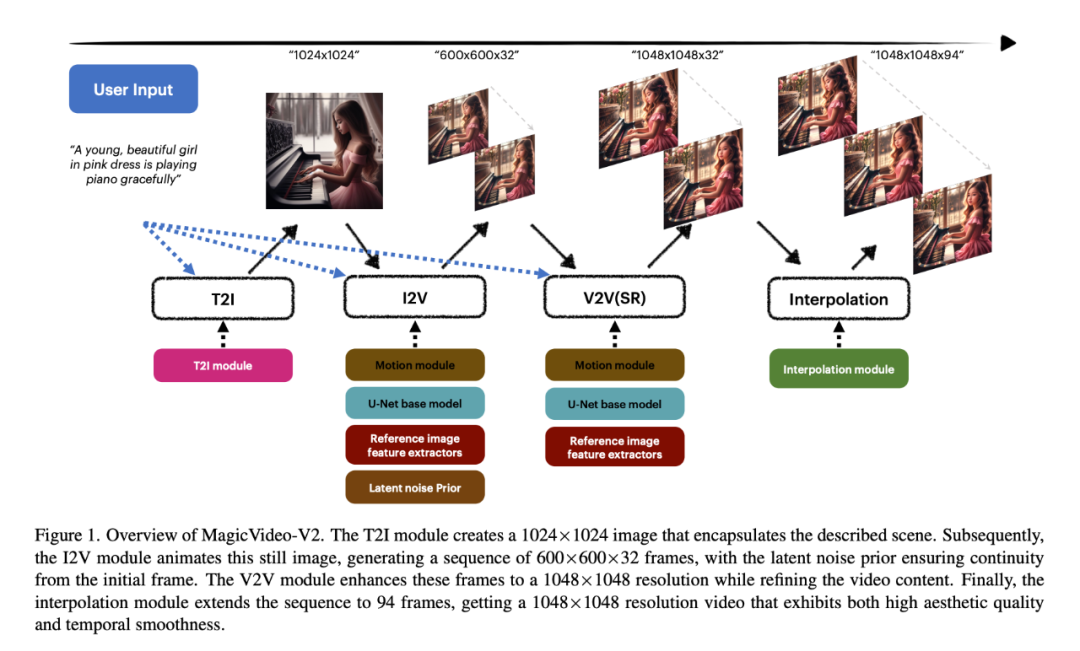
Large-scale user evaluation conducted by the researchers proves that MagicVideo-V2 is preferred over some well-known T2V methods (green, gray and pink bars Represents that MagicVideo-V2 is rated as better, fair or worse respectively).

From the MagicVideo-V2 paper, we can see that the progress of video generation technology is inseparable from the paving the way of AIGC technologies such as Vincent Picture and Picture Video. The basis for generating high-aesthetic content lies in understanding, especially the improvement of the model's ability to learn and integrate visual and language modalities.
In recent years, the scalability and general capabilities of large language models have given rise to a research paradigm that unifies vision and language learning. In order to bridge the natural gap between the two modalities of "visual" and "language", researchers connect the representations of pre-trained large language models and visual models, extract cross-modal features, and complete tasks such as visual question answering, Tasks such as image captioning, visual knowledge reasoning, and dialogue.
In these directions, ByteDance also has related explorations.
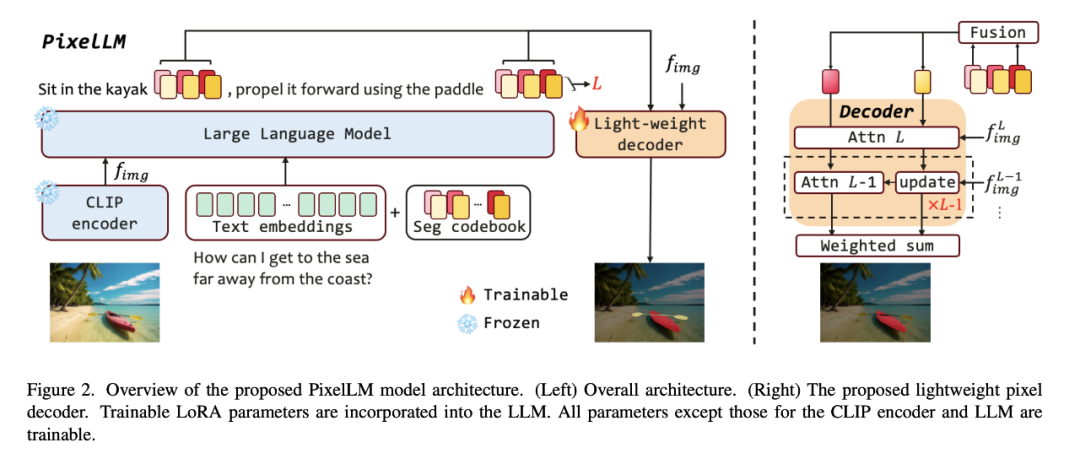
For example, to address the challenge of multi-objective reasoning and segmentation in open-world vision tasks, ByteDance teamed up with researchers from Beijing Jiaotong University and University of Science and Technology Beijing to propose an efficient large-scale pixel-level reasoning model called PixelLM. , and make it open source.

PixelLM can skillfully handle tasks with any number of open set objectives and varying inference complexity, The figure below demonstrates PixelLM's ability to generate high-quality object masks in various segmentation tasks.

The core of PixelLM is a novel pixel decoder and a segmentation codebook: the codebook contains learnable tokens that encode different The visual scale target refers to relevant context and knowledge, and the pixel decoder generates the target mask based on the hidden embedding of the codebook token and image features. While maintaining the basic structure of LMM, PixelLM can generate high-quality masks without additional, expensive visual segmentation models, thus improving efficiency and transferability to different applications.
It is worth noting that the researchers constructed a comprehensive multi-objective inference segmentation data set MUSE. They selected a total of 910k high-quality instance segmentation masks and detailed text descriptions based on image content from the LVIS dataset, and used these to construct 246k question-answer pairs.
Compared to images, if video content is involved, the challenge encountered by the model increases a lot. Because video not only contains rich and varied visual information, but also involves dynamic changes in time series.
When existing large multi-modal models process video content, they usually convert video frames into a series of visual tokens and combine them with language tokens to generate text. However, as the length of the generated text increases, the influence of the video content will gradually weaken, causing the generated text to deviate more and more from the original video content, producing so-called "illusions."
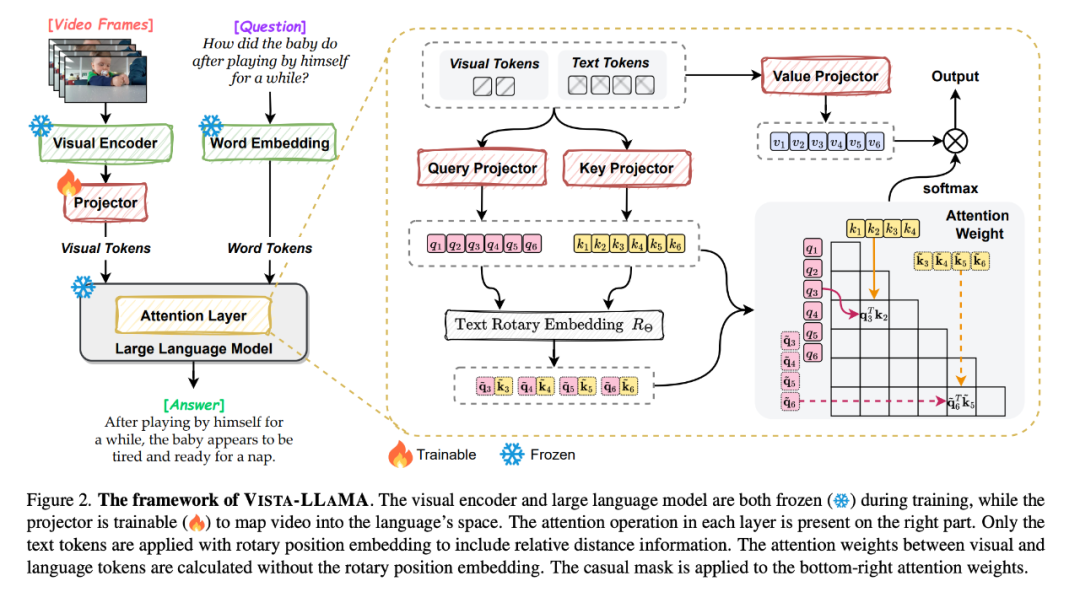
Faced with this problem, Bytedance and Zhejiang University proposed Vista-LLaMA, a multi-modal large model specifically designed for the complexity of video content.

Vista-LLaMA adopts an improved attention mechanism - Visual Equidistance Token Attention (EDVT), which removes the traditional attention mechanism when processing visual and text tokens. Relative position encoding, while retaining the relative position encoding between texts. This method greatly improves the depth and accuracy of the language model's understanding of video content.
In particular, the serialized visual projector introduced by Vista-LLaMA provides a new perspective on the time series analysis problem in video, which encodes the temporal context of visual tokens through a linear projection layer , which enhances the model’s ability to understand dynamic changes in the video.
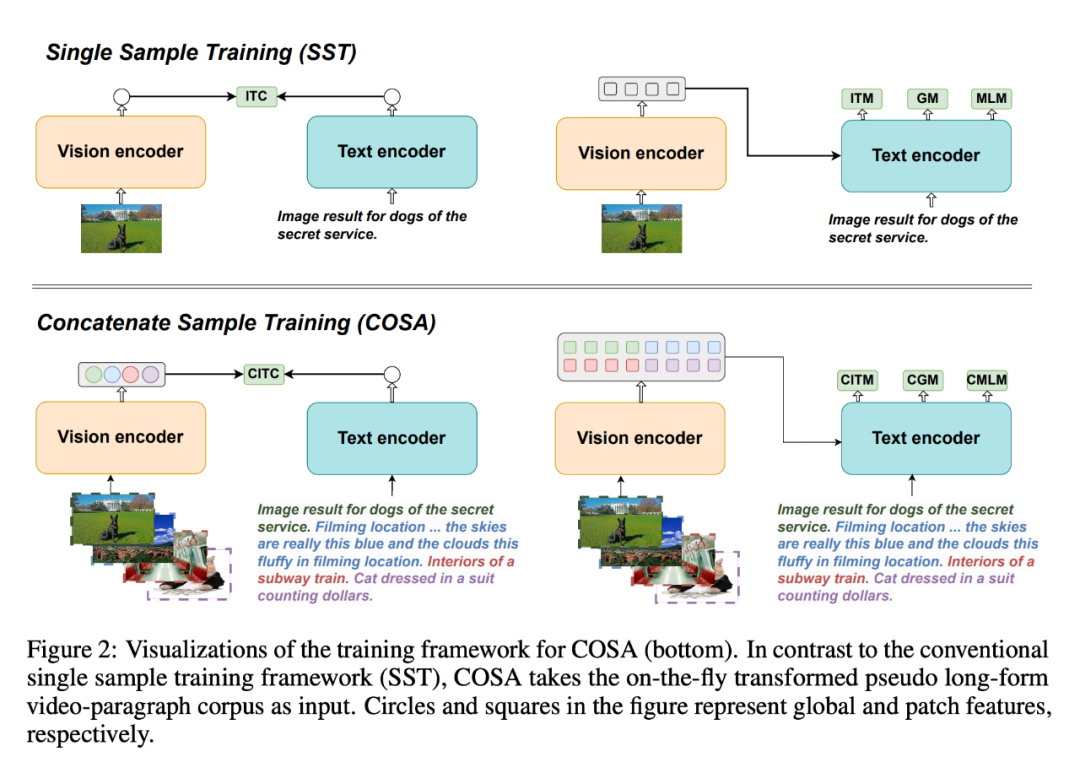
In a study recently accepted by ICLR 2024, ByteDance researchers also explored a boosting model for video content learning Ability pre-training methods.
Due to the limited scale and quality of video-text training corpus, most visual language basic models adopt image-text data sets for pre-training and mainly focus on visual semantic representation modeling. Temporal semantic representation and correlation are ignored.
To solve this problem, they proposed COSA, a concatenated sample pre-trained visual language base model.


Through rigorous training on a large dataset of image-text pairs, diffusion models are able to generate detailed images based entirely on textual information. In addition to image generation, diffusion models can also be used for audio generation, time series generation, 3D point cloud generation, and more.
For example, in some short video applications, users only need to provide a picture to generate a fake action video.
The Mona Lisa, who has maintained a mysterious smile for hundreds of years, can run immediately:

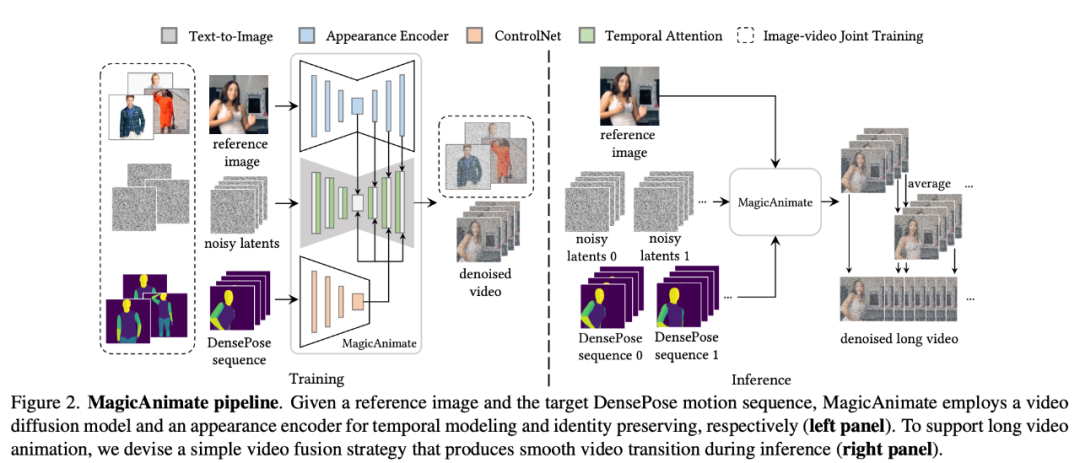
MagicAnimate is a diffusion-based human image animation framework that can well ensure the temporal consistency of the entire animation and improve animation fidelity in the task of generating videos based on specific motion sequences. Moreover, the MagicAnimate project is open source. In order to solve the common "flickering" problem of generated animations, the researchers merged the temporal attention (temporal attention) blocks into the diffusion backbone network to build a video diffusion model for temporal modeling. MagicAnimate breaks the entire video into overlapping segments and simply averages the predictions of the overlapping frames. Finally, the researchers also introduced an image-video joint training strategy to further enhance the reference image retention capability and single-frame fidelity. Although only trained on real human data, MagicAnimate has demonstrated the ability to generalize to a variety of application scenarios, including animation of unseen domain data, integration with text-image diffusion models, and multi-person animation. . Another research based on the idea of diffusion model, "DREAM-Talk", solves the problem of generating talking emotional words from a single portrait image. Face task. "DREAM-Talk" is a diffusion-based audio driver framework, divided into two stages: First, the researchers proposed a novel diffusion module EmoDiff, which can be used based on audio and reference Emotion styles generate a variety of highly dynamic emotional expressions and head poses. Given the strong correlation between lip movements and audio, the researchers then improved the dynamics using audio features and emotional styles to improve lip synchronization accuracy, and also deployed a video-to-video rendering module to achieve Transfer expressions and lip movements to any portrait. From the effect point of view, DREAM-Talk is indeed good in terms of expression, lip synchronization accuracy and perceived quality:
For example, many people are concerned about the quality of generated content (corresponding to SAG, DREAM-Talk). This may be related to some steps in the generation process of the diffusion model, such as guided sampling. Guided sampling in diffusion models can be roughly divided into two categories: those that require training and those that do not require training. Training-free guided sampling utilizes ready-made pre-trained networks (such as aesthetic evaluation models) to guide the generation process, aiming to obtain knowledge from the pre-trained models with fewer steps and higher accuracy. Current training-unguided sampling algorithms are based on one-step estimation of clean images to obtain the guidance energy function. However, since the pre-trained network is trained on clean images, the one-step estimation process for clean images may be inaccurate, especially in the early stages of the diffusion model, resulting in inaccurate guidance at early time steps. In response to this problem, ByteDance and researchers from the National University of Singapore jointly proposed the Symplectic Adjoint Guidance (SAG). A paper recently selected for ICLR 2024 focuses on the "critical sensitivity method of gradient backpropagation of diffusion probability model".
In this paper, the AdjointDPM proposed by the researchers first generates new samples from the diffusion model by solving the corresponding probability flow ODE. Then, the gradient of the loss in model parameters (including conditioning signals, network weights, and initial noise) is backpropagated using the adjacency sensitivity method by solving another augmented ODE. In order to reduce numerical errors during forward generation and gradient backpropagation, the researchers further reparameterized the probabilistic flow ODE and enhanced ODE into simple nonrigid ODEs using exponential integration. The researchers pointed out that AdjointDPM is extremely valuable in three tasks: converting visual effects into recognized text embeddings, fine-tuning diffusion probability models for specific types of stylization, and optimization Initial noise to generate adversarial samples for security auditing to reduce costs in optimization efforts. For visual perception tasks, the method of using text-to-image diffusion model as a feature extractor has also received more and more attention. In this direction, ByteDance researchers proposed a simple and effective solution in their paper.
Meta-cues serve two purposes: first, as a direct replacement for text embeddings in T2I models, they can activate task-relevant features during feature extraction; second, they will be used to rearrange the extracted features to ensure the model focuses on the features most relevant to the task at hand. In addition, the researchers also designed a cyclic refinement training strategy to fully utilize the characteristics of the diffusion model to obtain stronger visual features. How far is there to go before the "Chinese version of Sora" is born? But compared with Sora, whether it is ByteDance or a number of star companies in the field of AI video generation, there is a gap visible to the naked eye. Sora's advantages are based on its belief in Scaling Law and breakthrough technological innovation: unifying video data through patches, relying on technical architectures such as Diffusion Transformer and the semantic understanding capabilities of DALL・E 3, it has truly achieved "far ahead". From the explosion of Wenshengtu in 2022 to the emergence of Sora in 2024, the speed of technological iteration in the field of artificial intelligence has exceeded everyone's imagination. In 2024, I believe there will be more “hot products” in this field. Byte is obviously also stepping up investment in technology research and development. Recently, Google VideoPoet project leader Jiang Lu, and Chunyuan Li, a member of the open source multi-modal large model LLaVA team and former Microsoft Research chief researcher, have all been revealed to have joined the ByteDance intelligent creation team. The team is also vigorously recruiting, and a number of positions related to large model algorithms have been posted on the official website. Not only Byte, old giants such as BAT have also released many eye-catching video generation research results, and a number of large model startups are even more aggressive. What new breakthroughs will be made in Vincent Video Technology? We'll see. 

We know that in this task, It is difficult to achieve expressive emotional dialogue and accurate lip synchronization at the same time. Usually, in order to ensure the accuracy of lip synchronization, the expressiveness is often greatly compromised. 

##SAG computes gradient guidance through two inner stages : First, SAG estimates the clean image through n function calls, where n serves as a flexible parameter that can be adjusted according to specific image quality requirements. Second, SAG uses the symmetric dual method to obtain gradients with respect to memory requirements accurately and efficiently. This approach can support a variety of image and video generation tasks, including style-guided image generation, aesthetic improvement, and video stylization, and effectively improves the quality of generated content. 
##Paper title: Adjoint Sensitivity Method for Gradient Backpropagation of Diffusion Probabilistic Models

In these new papers, we have learned about a series of active explorations in video generation technology by domestic technology companies such as ByteDance.
The above is the detailed content of What technologies does ByteDance have behind the misunderstood 'Chinese version of Sora'?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



