


AGI is really getting closer!
In order to ensure that humans are not killed by AI, OpenAI has never stopped in deciphering the neural network/Transfomer black box.
In May last year, the OpenAI team released a shocking discovery: GPT-4 can actually explain the 300,000 neurons of GPT-2!
Netizens exclaimed that wisdom turns out to be like this.
 Picture
Picture
And just now, the head of the OpenAI Super Alignment Team officially announced that it will open source the software that has been used internally Big killer - Transformer Debugger (Transformer Debugger).
In short, researchers can use TDB tools to analyze the internal structure of Transformer to investigate the specific behavior of small models.
 Picture
Picture
In other words, with this TDB tool, it can help us analyze and analyze AGI in the future!
 Picture
Picture
The Transformer debugger combines sparse autoencoders with "automatic interpretability" developed by OpenAI - that is Automatically interpret small models with large models, combining technology.
Link: OpenAI explodes new work: GPT-4 cracks the GPT-2 brain! All 300,000 neurons have been seen through
 Picture
Picture
Paper address: https://openaipublic.blob.core.windows. net/neuron-explainer/paper/index.html#sec-intro
It is worth mentioning that researchers can quickly explore the internal structure of LLM without writing code.
For example, it can answer questions such as "Why does the model output token A instead of token B" and "Why does attention head H focus on token T".
 Picture
Picture
Because TDB can support neurons and attention heads, it allows researchers to ablate single neurons to intervene in the forward pass and observe the specific changes that occur.
However, according to Jan Leike, this tool is still an early version. OpenAI released it in the hope that more researchers can use it and further build on the existing basis. Improve.
 Picture
Picture
Project address: https://github.com/openai/transformer-debugger
To understand the working principle of this Transformer Debugger, you need to review a study related to alignment released by OpenAI in May 2023.

The TDB tool is based on two previously published studies and will not publish the paper
Simple Said that OpenAI hopes to use a model (GPT-4) with larger parameters and stronger capabilities to automatically analyze the behavior of the small model (GPT-2) and explain its operating mechanism.
 Picture
Picture
The preliminary results of OpenAI research at that time were that models with relatively few parameters were easy to understand, but as the model parameters increased As it gets bigger and the number of layers increases, the effect of explanation will plummet.
 Picture
Picture
OpenAI stated in the research at the time that GPT-4 itself was not designed to explain the behavior of small models, so overall for GPT The interpretation results of -2 are still poor.
 Picture
Picture
Algorithms and tools that can better explain model behavior need to be developed in the future.
The now open source Transformer Debugger is OpenAI’s phased achievement in the following year.
And this "better tool" - Transformer Debugger, combines the "sparse autoencoder" into the technical line of "using a large model to explain a small model".
Then the previous OpenAI process of using GPT-4 to explain small models in interpretability research was zero-coded, thus greatly lowering the threshold for researchers to get started.
On the GitHub project homepage, members of the OpenAI team passed a video Introducing the latest Transformer debugger tool.
Like a Python debugger, TDB lets you step through language model output, track important activations, and analyze upstream activations.
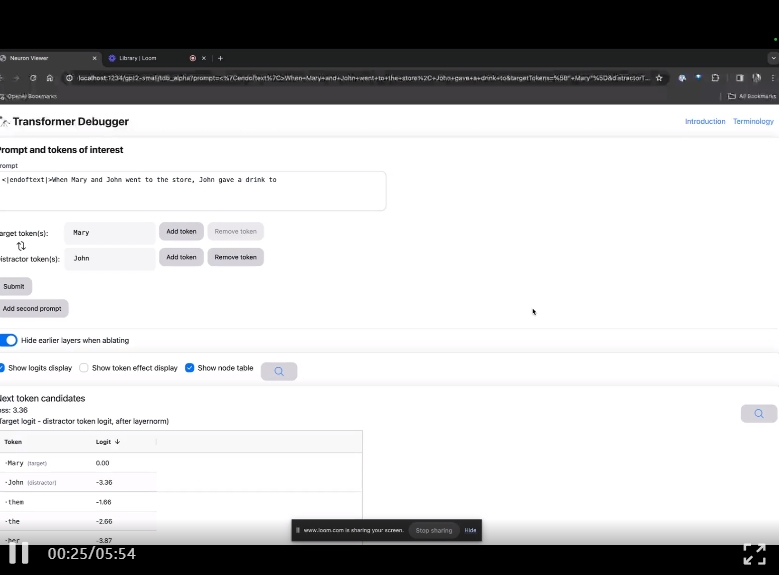
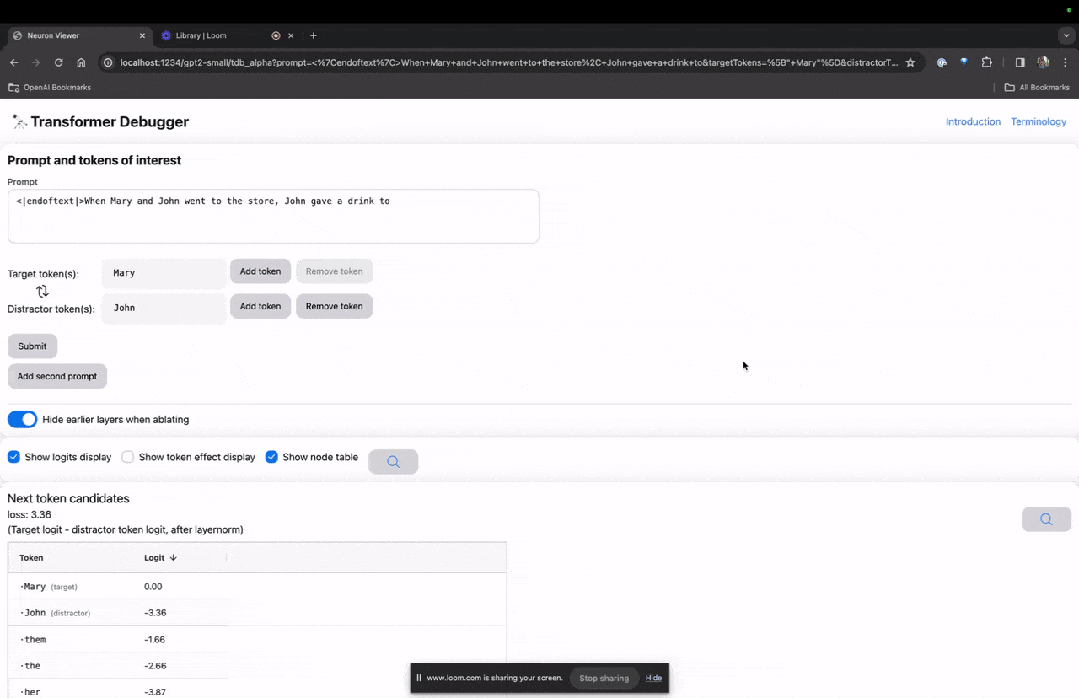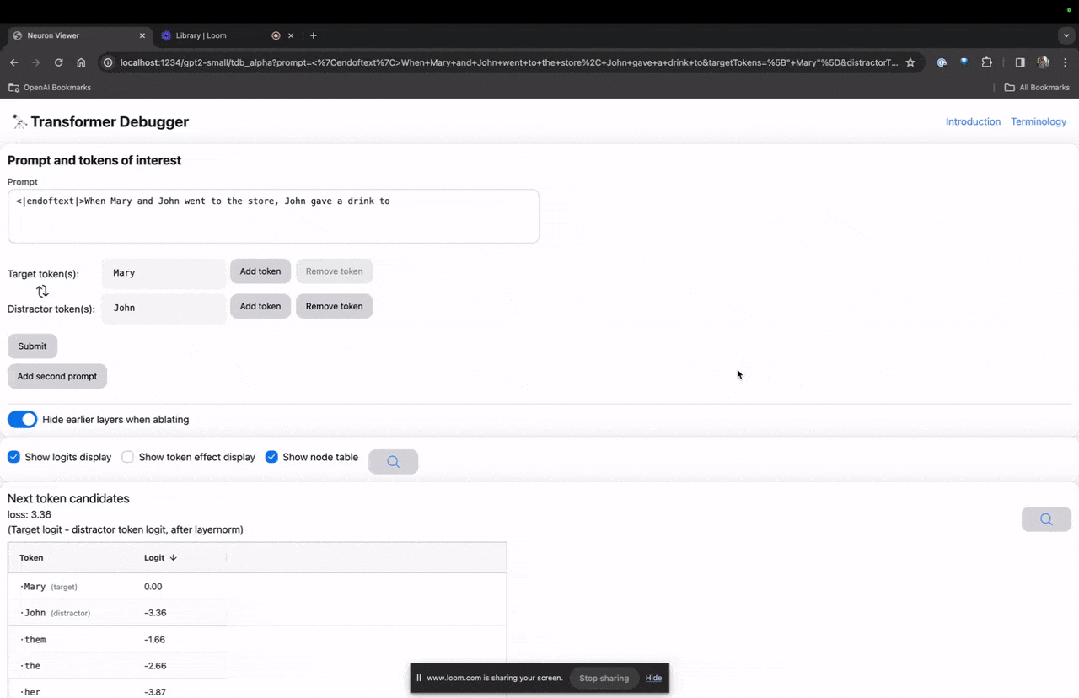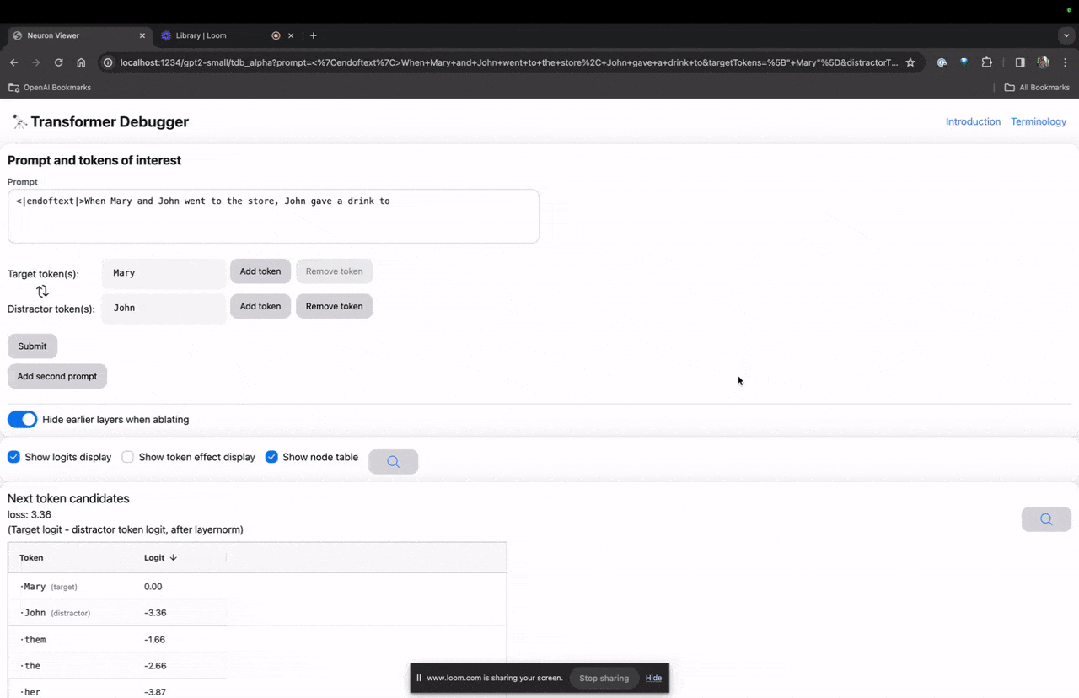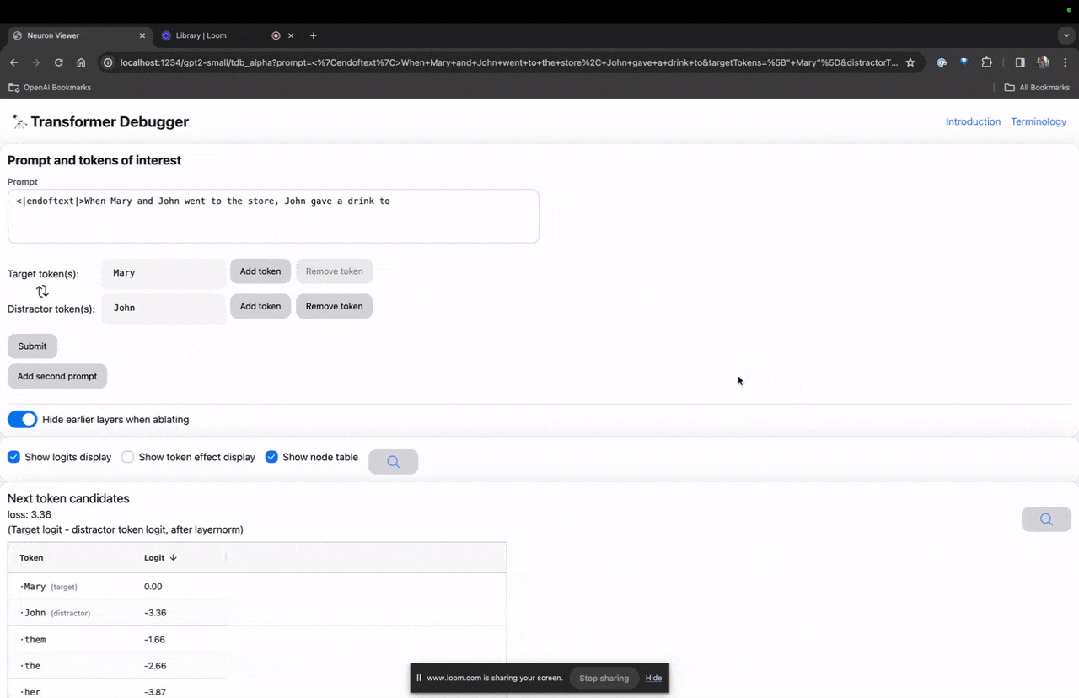
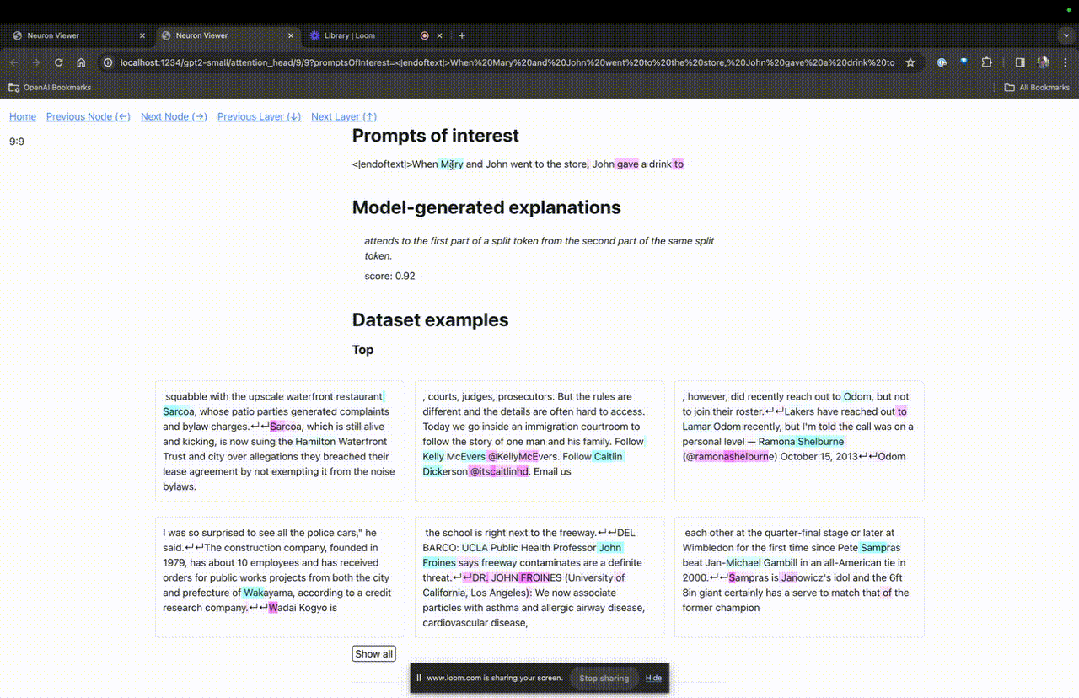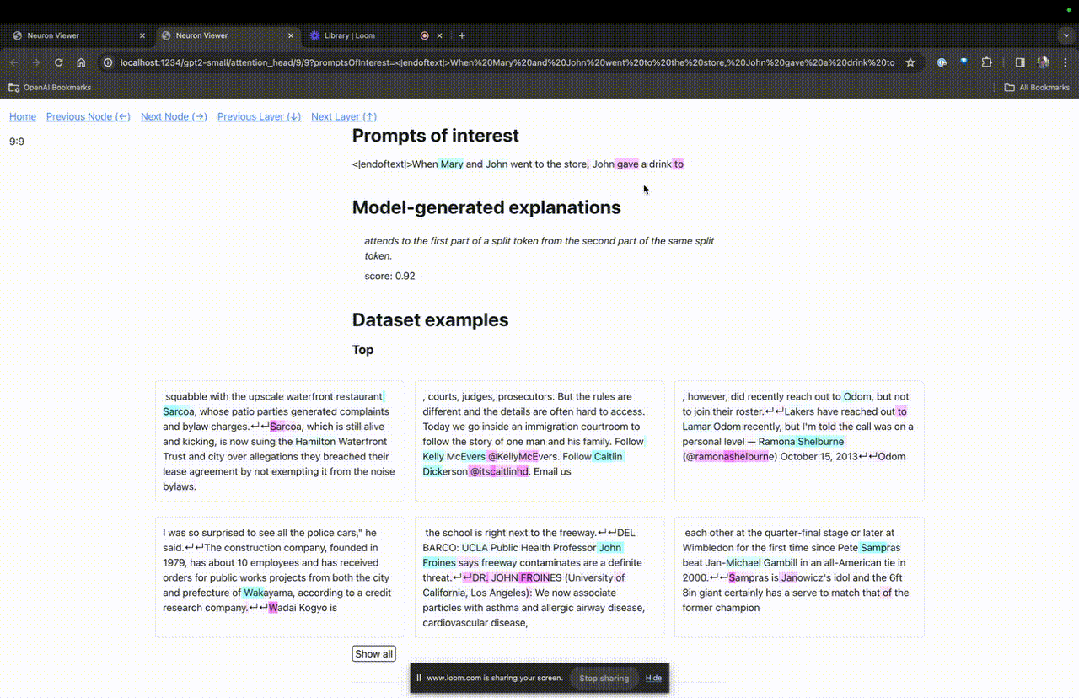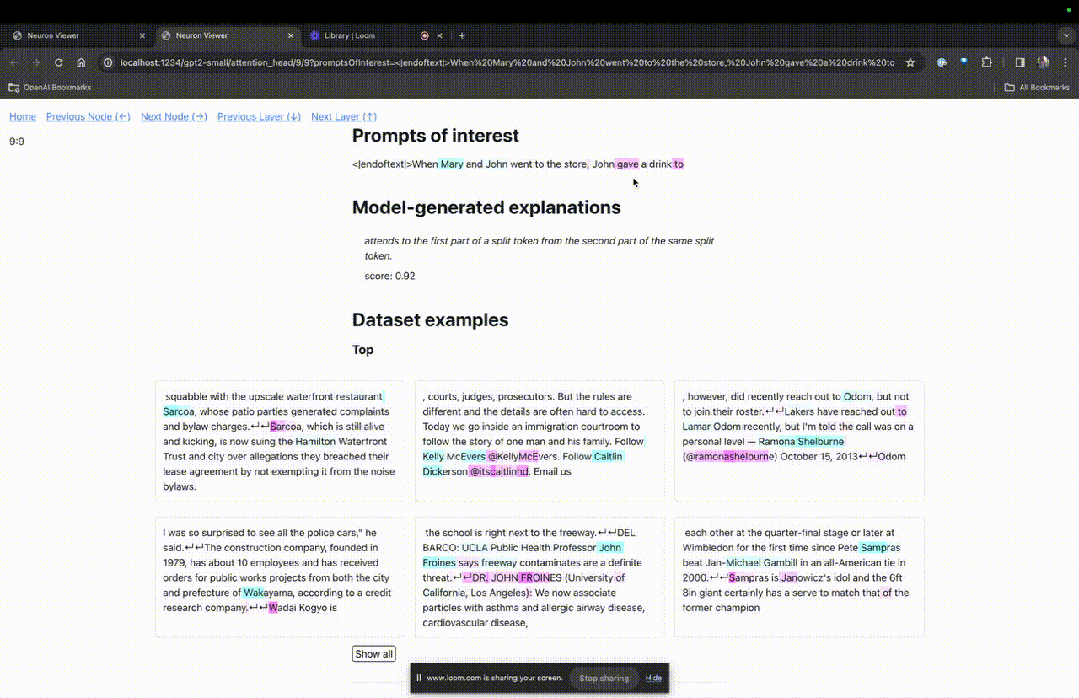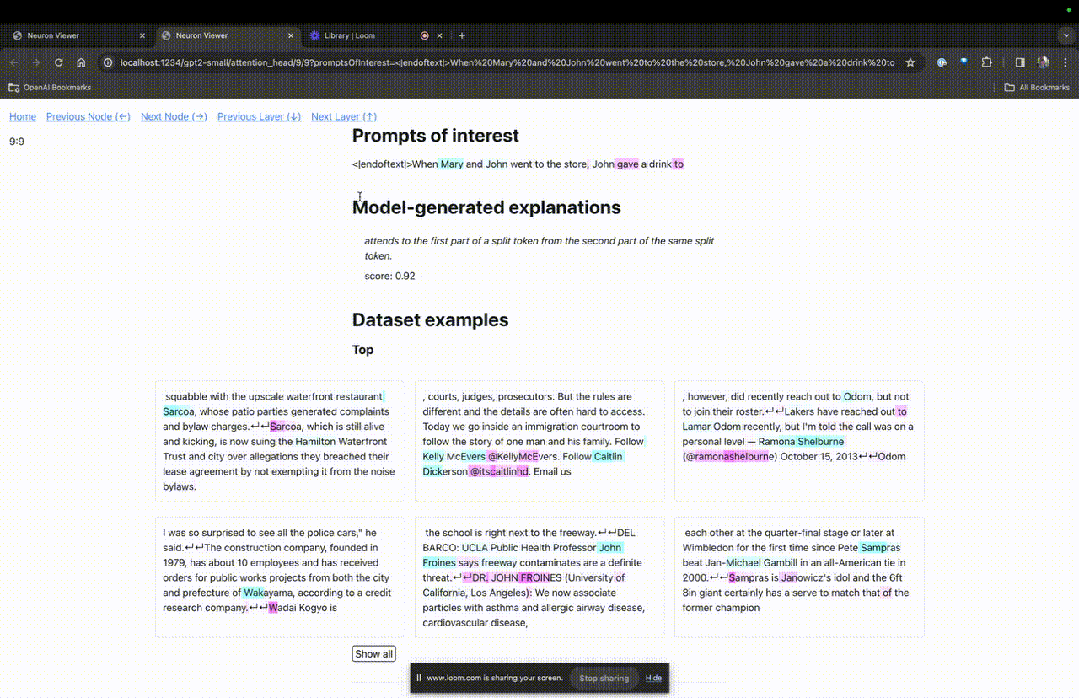
Enter the TDB homepage, first enter in the "Prompt" column - prompt and token of interest:
Mary and Johon went to the store, Johon gave a drink to....
The next step is to make a prediction of "next word", which requires inputting the target token. and disruptive tokens.
After the final submission, you can see the logarithm of predicted next word candidates given by the system.
The "node table" below is the core part of TDB. Each line here corresponds to a node, which activates a model component.
 Picture
Picture
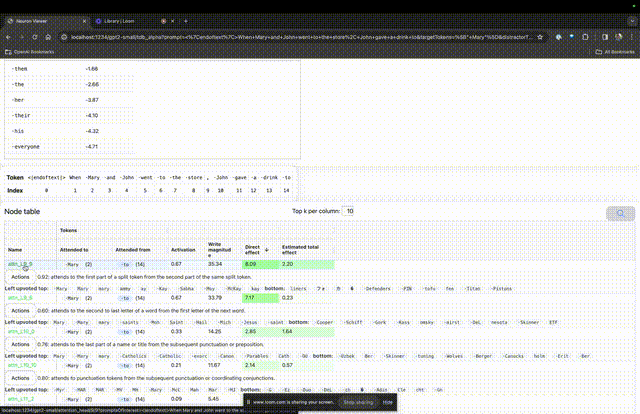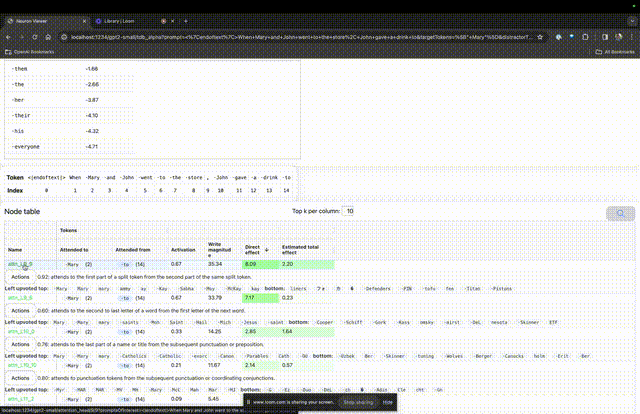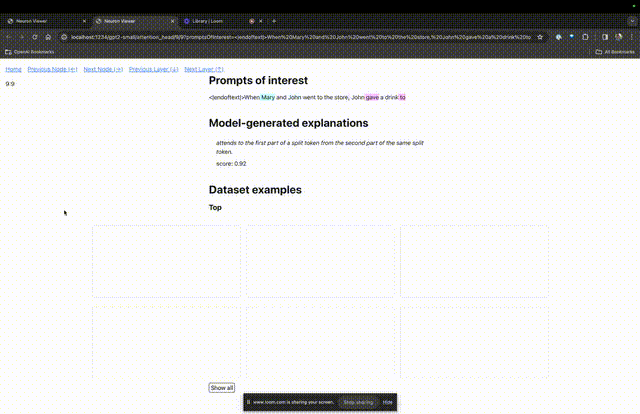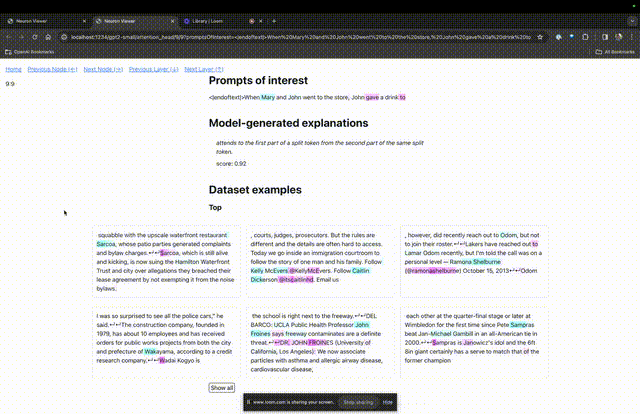
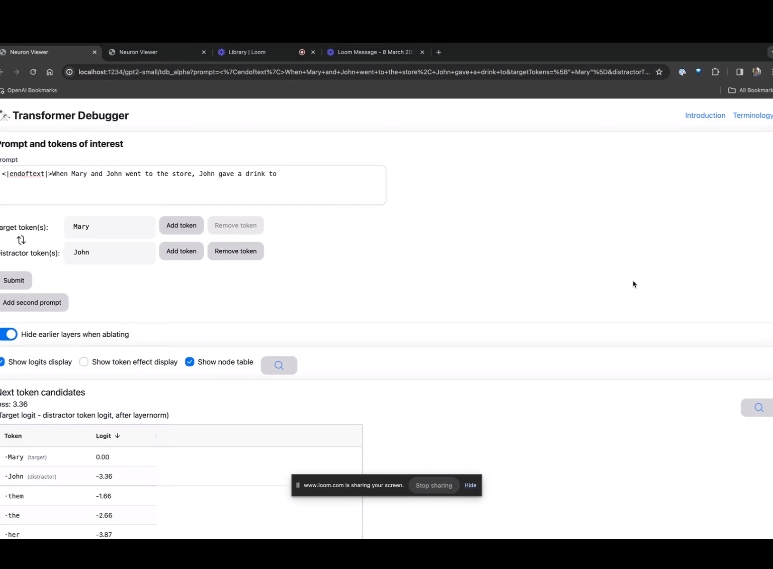
If you want to understand the function of the attention head that is very important in a specific prompt, click directly on the component name.
Then TDB will open the "Neuron Browser" page, and the previous prompt words will be displayed at the top.
 Picture
Picture
You can see light blue and pink tokens here. Under each token of the corresponding color, the attention from subsequent tags to this token will cause a large norm vector to be written to the subsequent token.
 Picture
Picture
In two other videos, the researchers introduce the concept of TDB and its role in understanding loops application. At the same time, he also demonstrated how TDB can qualitatively reproduce one of the findings in the paper.
In short, OpenAI is automatically explainable The idea behind this research is to let GPT-4 interpret the behavior of neurons in natural language, and then apply this process to GPT-2.
How is this possible? First, we need to "dissect" LLM.
Like brains, they are made up of "neurons" that observe certain patterns in text, which determines what the entire model says next.
For example, if such a prompt is given, "Which Marvel superheroes have the most useful superpowers?" "Marvel Superhero Neurons" may increase the model naming comics. The probability of a specific superhero in a Marvel movie.
OpenAI’s tool uses this setting to decompose the model into separate parts.
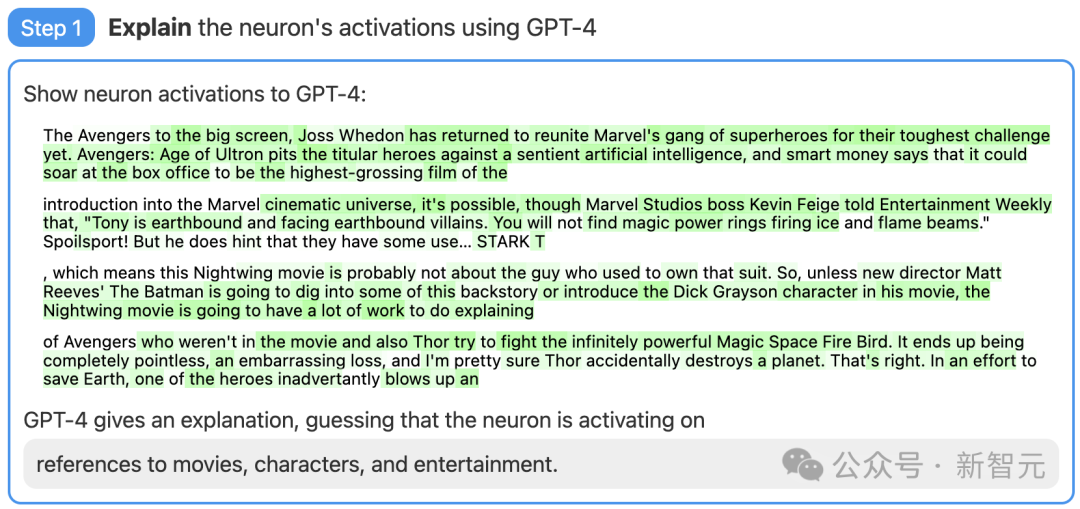
Step 1: Use GPT-4 to generate an explanation
First, find a GPT-2 neuron , showing relevant text sequences and activations to GPT-4.
Then, let GPT-4 generate a possible explanation based on these behaviors.
For example, in the example below, GPT-4 believes that this neuron is related to movies, characters, and entertainment.
 Picture
Picture
Step 2: Use GPT-4 for simulation
Next, let GPT-4 simulate what the neurons activated in this way will do based on the explanation it generated.
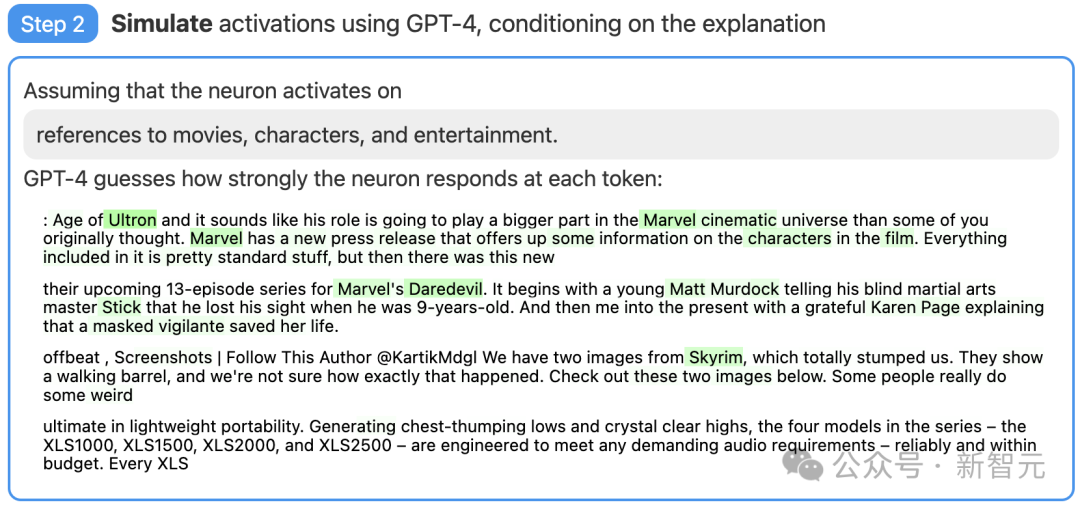 Picture
Picture
Step 3: Comparison and scoring
Finally, compare the behavior of the simulated neurons (GPT-4) with the behavior of the actual neurons (GPT-2) to see how accurate GPT-4's guess is.
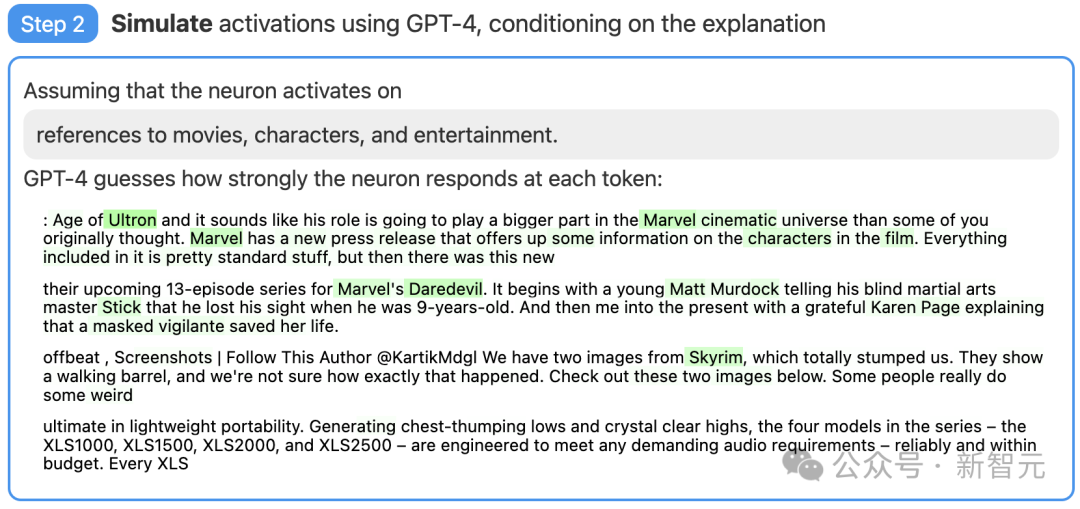 Picture
Picture
Through the rating, OpenAI researchers We measured how this technique works on different parts of the neural network. This technique does not explain as well for larger models, probably because later layers are more difficult to explain.
 Picture
Picture
Currently, the vast majority of explanations have very low ratings, but researchers have also found that iterative explanations can be Improve your score by using larger models, changing the architecture of the model being explained, etc.
Now, OpenAI is open-sourcing the data set and visualization tools for the results of "Using GPT-4 to explain all 307,200 neurons in GPT-2" and also making them available on the market through the OpenAI API. codes for explanations and scoring of existing models, and calls on the academic community to develop better techniques that produce higher-scoring explanations.
In addition, the team also found that the larger the model, the higher the consistency rate of the explanation. Among them, GPT-4 is closest to humans, but there is still a big gap.
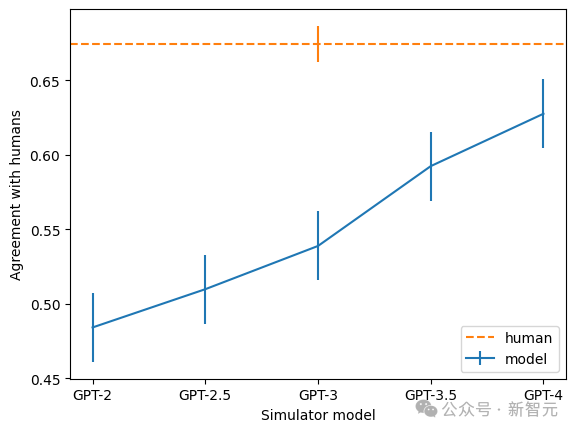 Picture
Picture
The following are examples of neurons in different layers being activated. It can be seen that the higher the number of layers, the more abstract.
 Picture
Picture
 Picture
Picture
 Picture
Picture
 picture
picture
The sparse autoencoder used by OpenAI is a model with a bias at the input end, and also includes a A linear layer with biases and ReLU, and another linear layer and biases for the decoder.
The researchers found that the bias term is very important to the performance of the autoencoder. They relate the bias applied in the input and output. The result is equivalent to subtracting the fixed bias from all activations. .
The researchers used the Adam optimizer to train the autoencoder to reconstruct the MLP activations of the Transformer using MSE. Using the MSE loss can avoid the challenge of polysemantics, and use the loss plus an L1 penalty to encourage sparsity.
When training an autoencoder, several principles are very important.
The first is scale. Training an autoencoder on more data makes features subjectively "sharper" and more interpretable. So OpenAI uses 8 billion training points for the autoencoder.
Secondly, during training, some neurons will stop firing, even over a large number of data points.
The researchers then "resampled" these dead neurons during training, allowing the model to represent more features for a given autoencoder hidden layer dimension, thus producing better results. .
How to judge whether your method is effective? In machine learning, you can simply use loss as a standard, but it is not easy to find a similar reference here.
For example, look for an information-based metric so that in a sense, the best decomposition is the one that minimizes the total information of the autoencoder and the data.
- But in fact, total information often has nothing to do with subjective feature interpretability or activation sparsity.
Ultimately, the researchers used a combination of several additional metrics:
- Manual inspection: whether the feature looked ok explain?
- Feature Density: Real-time number of features and the percentage of tokens that trigger them is a very useful guide.
- Reconstruction loss: A measure of how well the autoencoder reconstructs the MLP activations. The ultimate goal is to account for the functionality of the MLP layer, so the MSE loss should be low.
- Toy Model: Using an already well-understood model allows a clear assessment of the performance of the autoencoder.
However, the researchers also expressed their hope to determine better indicators for dictionary learning solutions from the sparse autoencoders trained on Transformer.
Reference:
The above is the detailed content of OpenAI officially announced the open source Transformer Debugger! No need to write code, everyone can crack the LLM black box. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



