


The diffusion model is currently the core module in generative AI and has been widely used in large generative AI models such as Sora, DALL-E, and Imagen. At the same time, diffusion models are increasingly being applied to time series. This article introduces you to the basic ideas of the diffusion model, as well as several typical works of the diffusion model used in time series, to help you understand the application principles of the diffusion model in time series.

The core of the generative model Yes, it is possible to sample a point from a random simple distribution and map this point to an image or sample in the target space through a series of transformations. What the diffusion model does is to continuously remove noise at the sampled sample points, and generate the final data through multiple noise removal steps. This process is very similar to the sculpture process. The noise sampled from the Gaussian distribution is the initial raw material. The process of removing noise is the process of constantly chipping away the excess parts of this material.
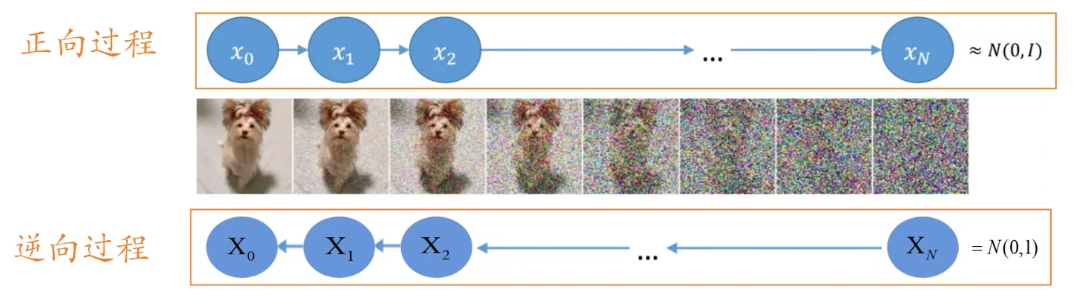
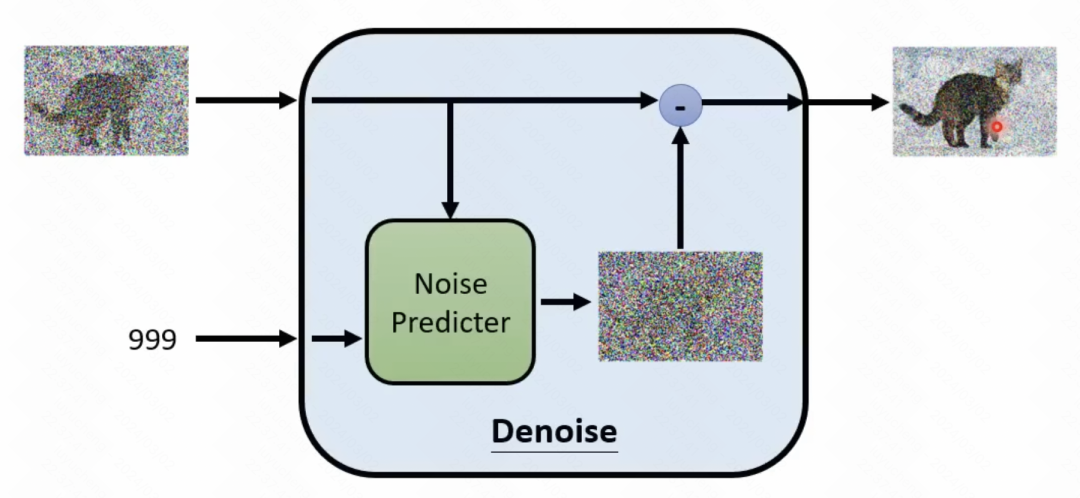
What is mentioned above is the reverse process, that is, gradually removing noise from a noise to obtain an image. This process is an iterative process, which requires T times of denoising to remove the noise from the original sampling points bit by bit. In each step, the result generated by the previous step is input, and the noise needs to be predicted, and then the noise is subtracted from the input to obtain the output of the current time step.
Here you need to train a module (denoising module) that predicts the noise of the current step. This module inputs the current step t, as well as the input of the current step, and predicts what the noise is. This module for predicting noise is performed through a forward process, which is similar to the Encoder part in VAE. In the forward process, an image is input, a noise is sampled at each step, and the noise is added to the original image to obtain the generated result. Then the generated result and the embedding of the current step t are used as input to predict the generated noise, thereby achieving the role of training the denoising module.
TimeGrad is one of the earliest methods to use diffusion models for time series forecasting. Different from the traditional diffusion model, TimeGrad introduces a denoising module based on the basic diffusion model and provides an additional hidden state for each time step. This hidden state is obtained by encoding the historical sequence and external variables through the RNN model, and is used to guide the diffusion model to generate the sequence. The overall logic is shown in the figure below.
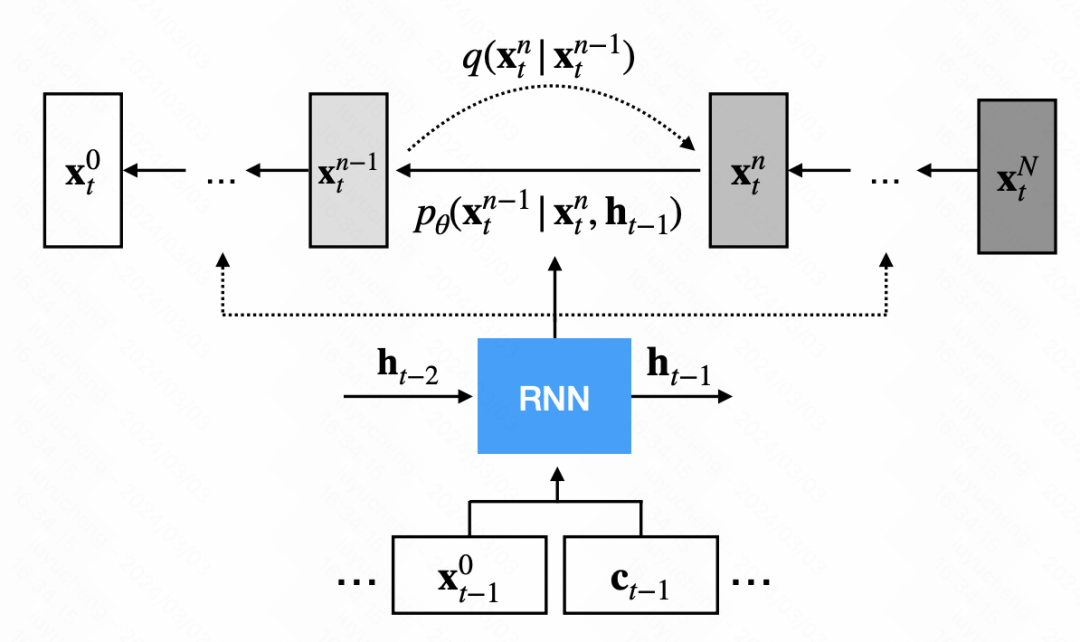
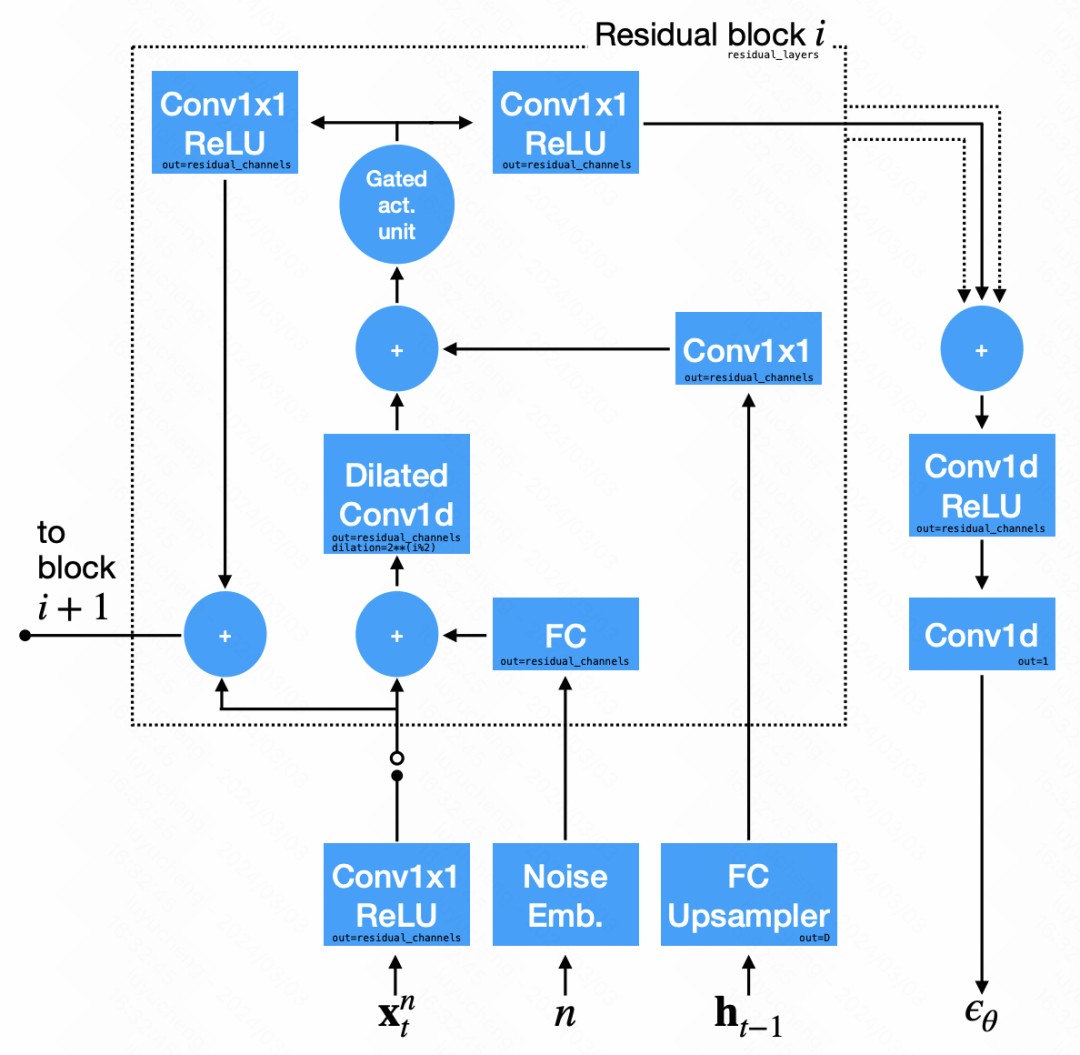
In the network structure of the denoising module, the convolutional neural network is mainly used. The input signal is divided into two parts: the first part is the output sequence of the previous step, and the second part is the hidden state output by the RNN, the result obtained after upsampling. These two parts are convolved and then added together for noise prediction.
This article uses the diffusion model to build Model time series filling task, the overall modeling method is similar to TimeGrad. As shown in the figure below, the initial time series has missing values. It is first filled with noise, and then the diffusion model is used to gradually predict the noise to achieve denoising. After multiple steps, the filling result is finally obtained.
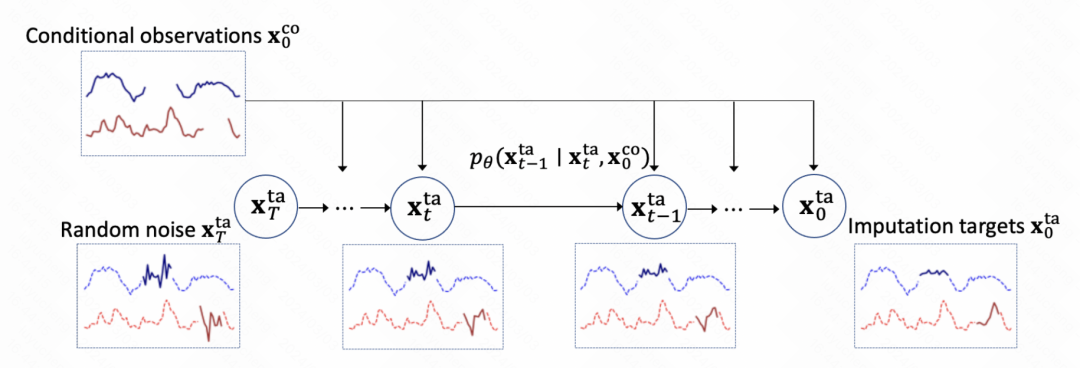
The core of the entire model is also the diffusion model training denoising module. The core is to train the noise prediction network. Each step inputs the current step embedding, historical observation results and the output of the previous moment to predict the noise results.
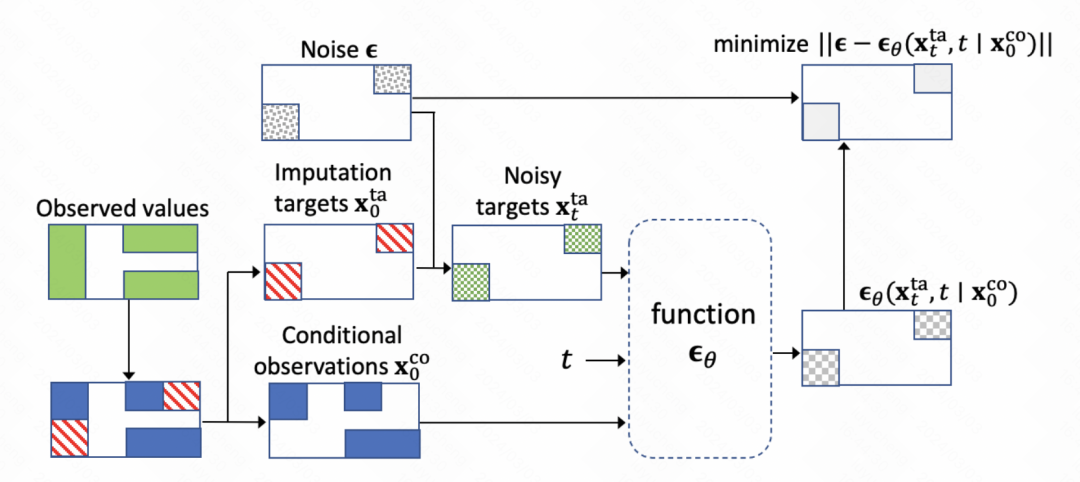
Transformer is used in the network structure, including two parts: Transformer in the time dimension and Transformer in the variable dimension.

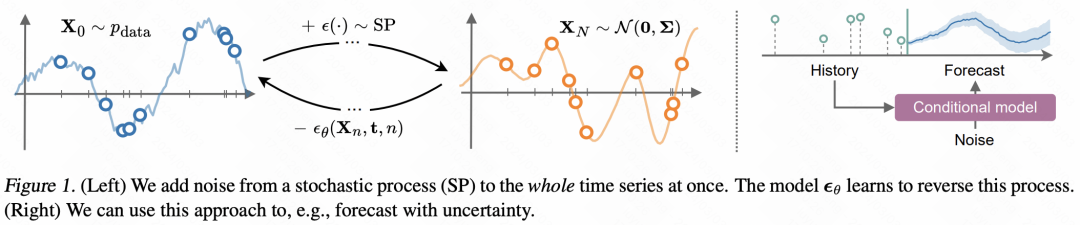
The method proposed in this article is compared to TimeGrad Going up a level, the function itself that generates the time series is directly modeled through the diffusion model. It is assumed here that each observation point is generated from a function, and then the distribution of this function is directly modeled instead of modeling the distribution of data points in the time series. Therefore, this paper changes the independent noise added in the diffusion model to noise that changes with time, and trains the denoising module in the diffusion model to denoise the function.
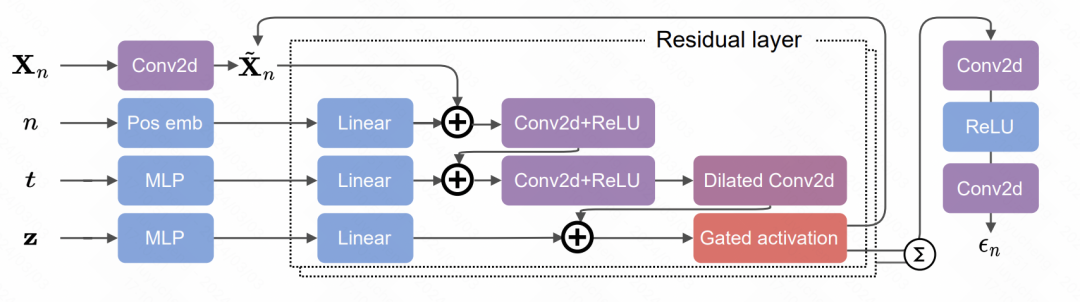
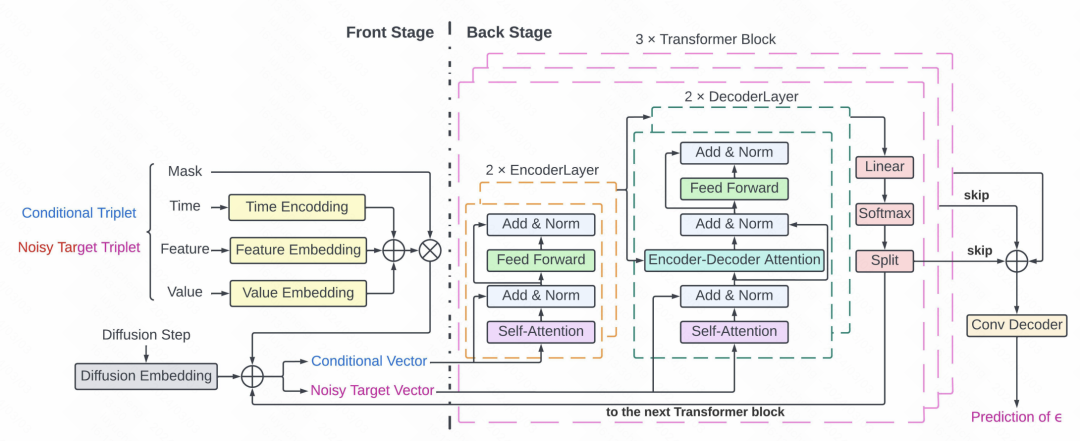
This article applies the diffusion model to key signal extraction in ICU. The core of this article is on the one hand the processing of sparse and irregular medical time series data, using value, feature, time triples to represent each point in the sequence, and using mask for the actual value part. On the other hand are prediction methods based on Transformer and diffusion models. The overall diffusion model process is shown in the figure. The principle of the image generation model is similar. The denoising model is trained based on the historical time series, and then the noise is gradually subtracted from the initial noise sequence in the forward propagation.

The specific noise prediction part of the diffusion model uses the Transformer structure. Each time point consists of a mask and a triplet, which are input to the Transformer and used as a denoising module to predict noise. The detailed structure includes 3 layers of Transformer. Each Transformer includes 2 layers of Encoder and 2 layers of Decoder networks. The output of the Decoder is connected using the residual network and input to the convolution Decoder to generate noise prediction results.
The above is the detailed content of An article summarizing the application of Diffusion Model in time series. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 Introduction to parametric modeling software
Introduction to parametric modeling software
 The difference between Java and Java
The difference between Java and Java
 How to trade VV coins
How to trade VV coins
 windows change file type
windows change file type
 Is the success rate of railway 12306 standby ticket high?
Is the success rate of railway 12306 standby ticket high?
 location.reload usage
location.reload usage








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



