


The Chen Danqi team has just released a new LLMContext window extensionMethod:
It only uses 8k token documents for training, and can Llama-2 Window extended to 128k.
The most important thing is that in this process, the model only requires 1/6 of the original memory, and the model obtains 10 times the throughput.
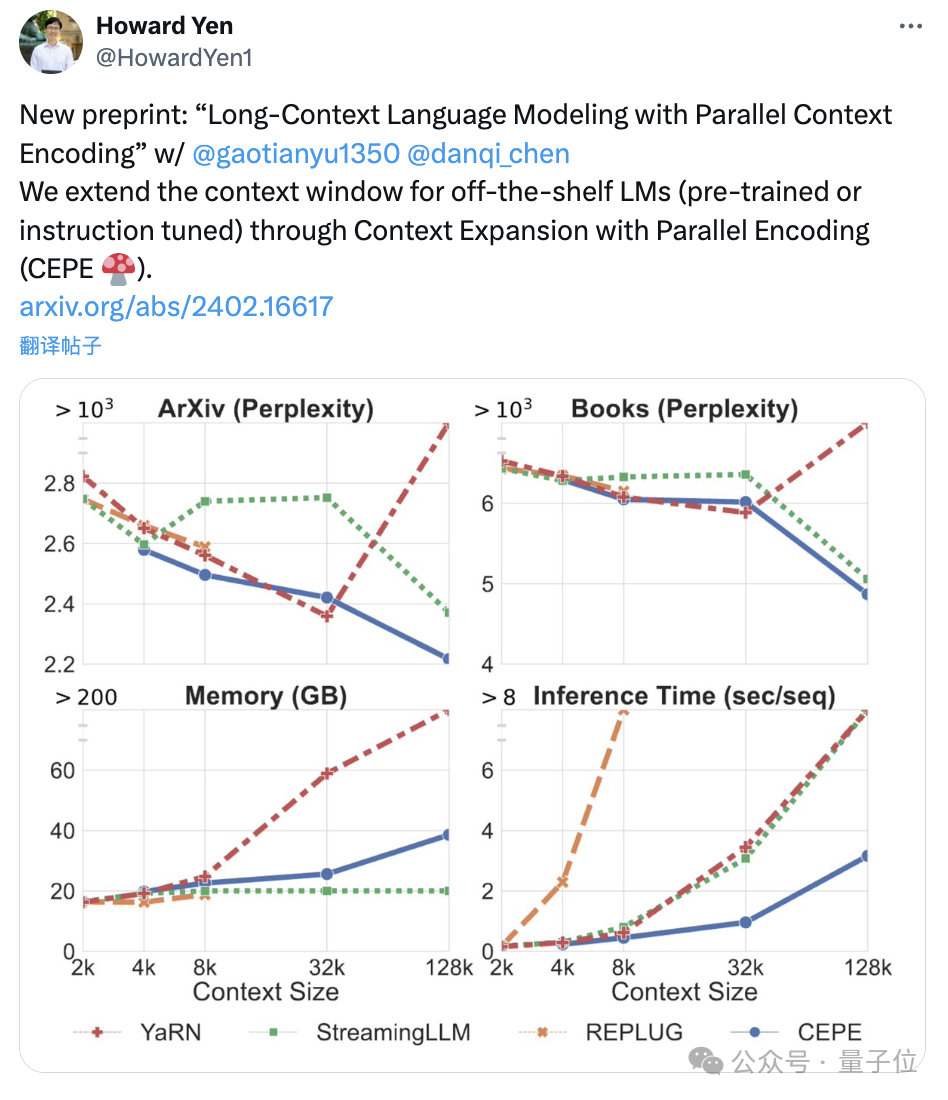
In addition, it can also greatly reduce the training cost:
Use this method to train 7B alpaca 2 For transformation, you only need a piece of A100 to complete it.
The team expressed:We hope this method will be useful and easy to use, and provideCurrently, the model and code have been released on HuggingFace and GitHub.cheap and effective long context capabilities for future LLMs.
CEPE, the full name is "Parallel Encoding Context Extension(Context Expansion with Parallel Encoding)”.
As a lightweight framework, it can be used to extend the context window of anypre-trained and directive fine-tuning model.
For any pretrained decoder-only language model, CEPE extends it by adding two small components:One is a small encoder for long The context is block-encoded;
One is the cross-attention module, which is inserted into each layer of the decoder to focus on the encoder representation.
The complete architecture is as follows: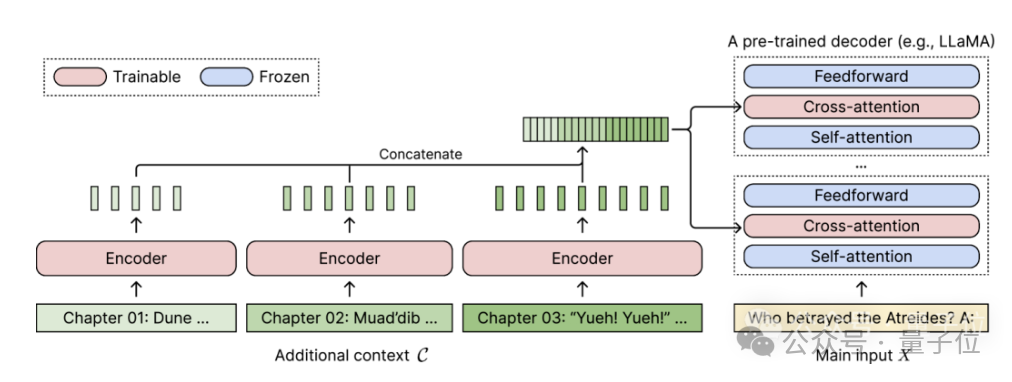
(1) The length can be generalized
because it is not subject to positional encoding A constraint, instead, has its context encoded in segments, each segment having its own positional encoding.(2) High efficiencyUsing small encoders and parallel encoding to process context can reduce computational costs.
(3) Reduce training cost
with a 400M encoder and cross-attention layer (a total of 1.4 billion parameters), it can be completed with an 80GB A100 GPU.
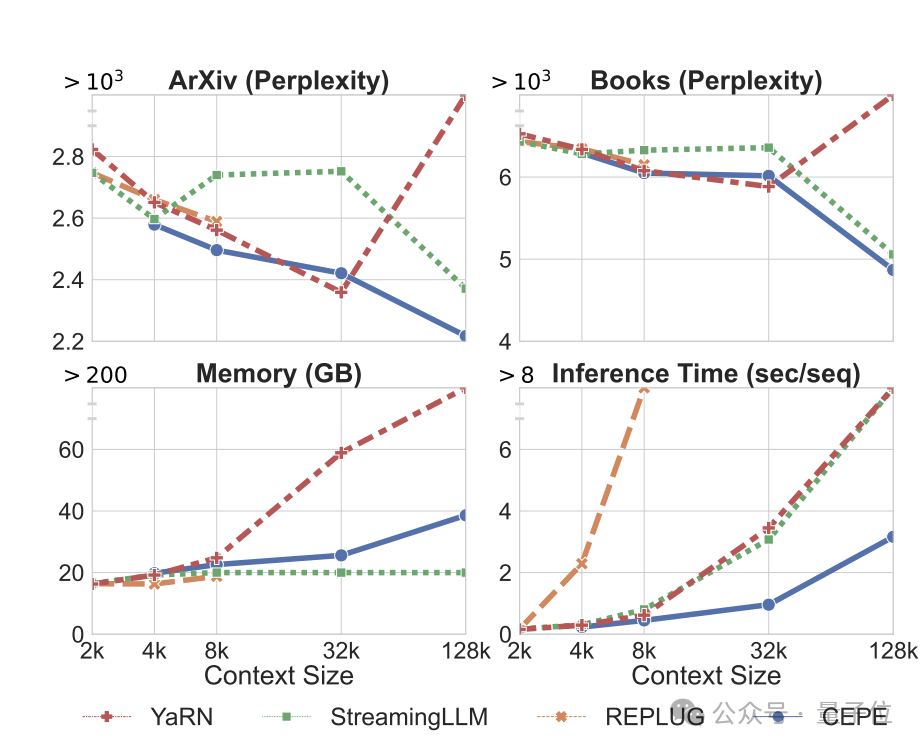
Perplexity continues to decreaseThe team applies CEPE to Llama-2 and trains on the filtered version of RedPajama with 20 billion tokens(only the Llama-2 pre-training budget 1%).
First, compared to two fully fine-tuned models, LLAMA2-32K and YARN-64K, CEPE achieves lower or comparableperplexity## on all datasets. #, with both lower memory usage and higher throughput.
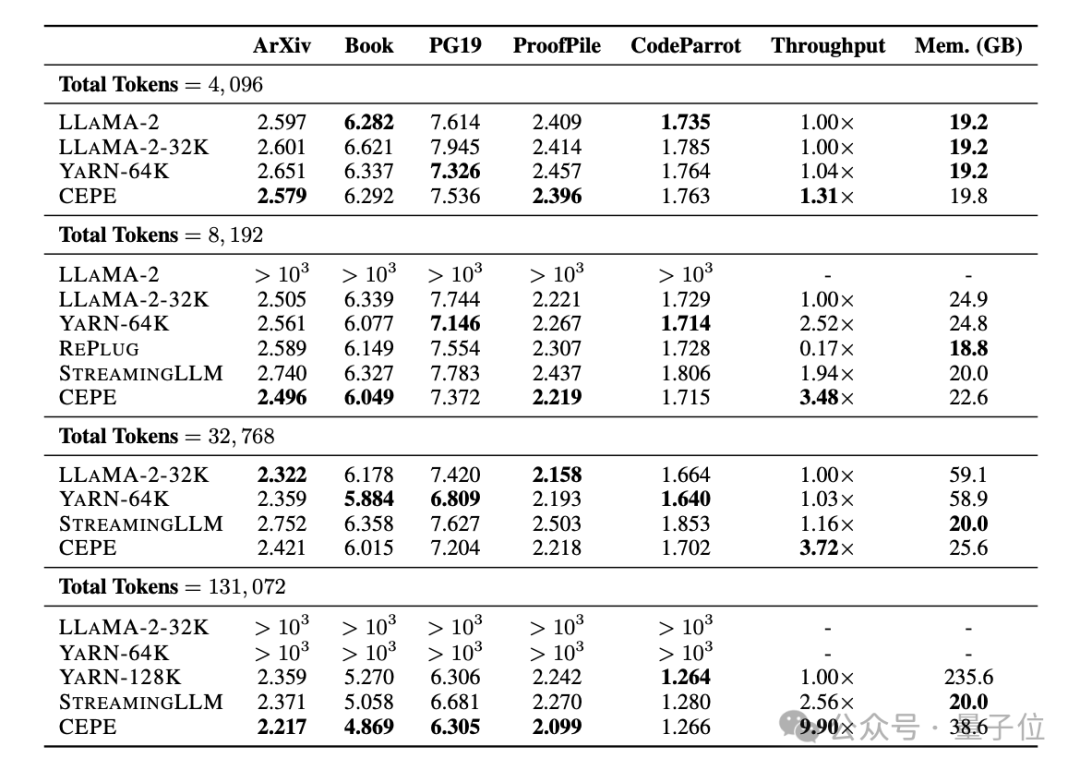 When the context is increased to 128k
When the context is increased to 128k
, CEPE’s perplexity continues to decrease while remaining low memory status. In contrast, Llama-2-32K and YARN-64K not only fail to generalize beyond their training length, but are also accompanied by a significant increase in memory cost.
 Secondly,
Secondly,
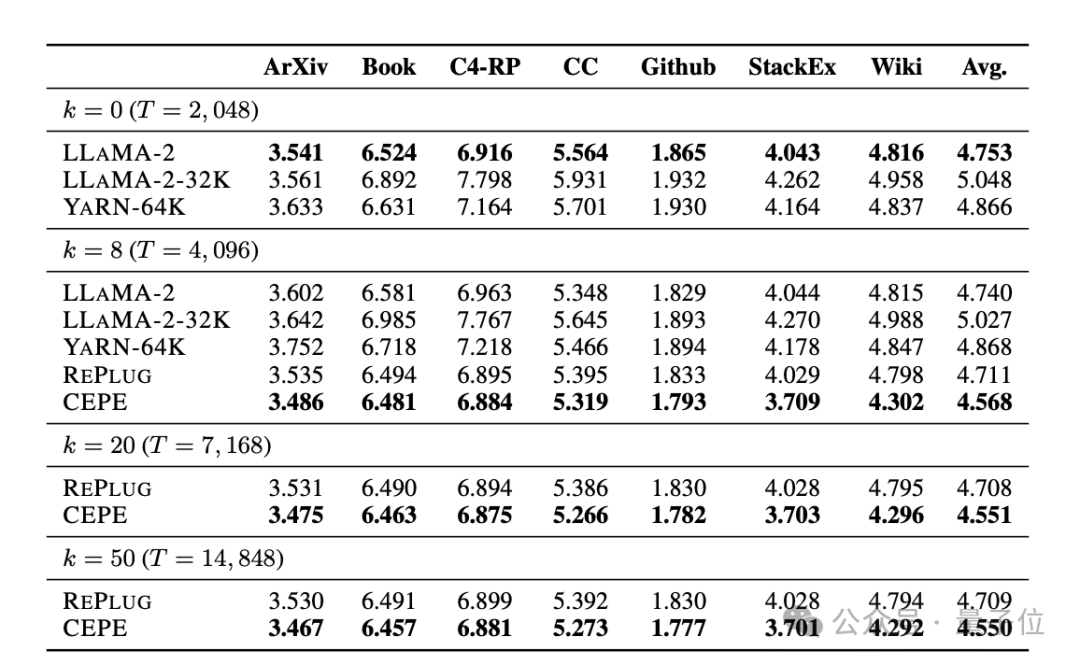
retrieval capability is enhanced. As shown in the following table:
By using the retrieved context, CEPE can effectively improve model perplexity, and its performance is better than RePlug.
It is worth noting that even if paragraph k=50 (training is 60), CEPE will continue to improve the perplexity.
This shows that CEPE transfers well to the retrieval enhancement setting, whereas the full-context decoder model degrades in this ability.
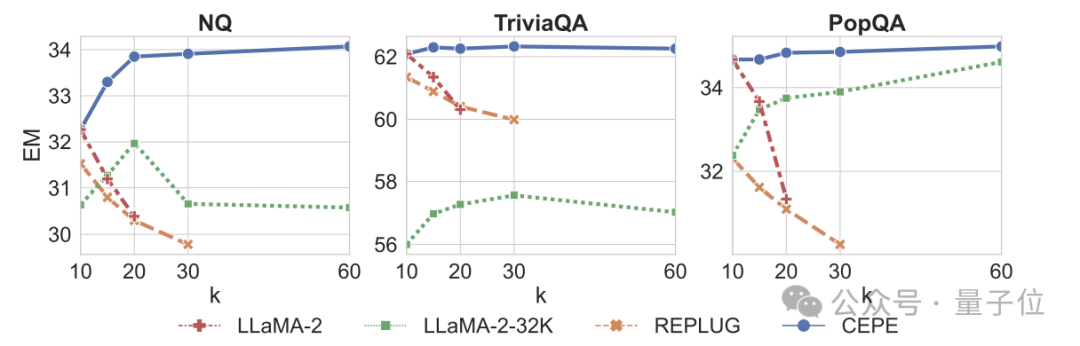
Third, open domain question and answer capabilitiesare significantly surpassed.
As shown in the figure below, CEPE is significantly better than other models in all data sets and paragraph k parameters, and unlike other models, the performance drops significantly as the k value becomes larger and larger.
This also shows that CEPE is not sensitive to a large number of redundant or irrelevant paragraphs.
So to summarize, CEPE outperforms on all the above tasks with much lower memory and computational cost compared to most other solutions.
Finally, based on these, the author proposed CEPE-Distilled (CEPED) specifically for the instruction tuning model.
It uses only unlabeled data to expand the context window of the model, distilling the behavior of the original instruction-tuned model into a new architecture through assisted KL divergence loss, thereby eliminating the need to manage expensive long context instruction tracking data.
Ultimately, CEPED can expand the context window of Llama-2 and improve the long text performance of the model while retaining the ability to understand instructions.
CEPE has a total of 3 authors.
Yan Heguang(Howard Yen) is a master's student in computer science at Princeton University.
The second person is Gao Tianyu, a doctoral student at the same school and a bachelor's degree graduate from Tsinghua University.
They are all students of the corresponding author Chen Danqi.

Original paper: https://arxiv.org/abs/2402.16617
Reference link: https://twitter. com/HowardYen1/status/1762474556101661158
The above is the detailed content of New work by Chen Danqi's team: Llama-2 context is expanded to 128k, 10 times throughput only requires 1/6 of the memory. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



