The release of OpenAI Sora on February 16 undoubtedly marks a major breakthrough in the field of video generation. Sora is based on the Diffusion Transformer architecture, which is different from most mainstream methods on the market (extended by 2D Stable Diffusion). Why Sora insists on using Diffusion Transformer, the reasons can be seen from the paper published at ICLR 2024 (VDT: General-purpose Video Diffusion Transformers via Mask Modeling) at the same time two. This work was led by the research team of Renmin University of China and collaborated with the University of California, Berkeley, the University of Hong Kong, etc. It was first published on the arXiv website in May 2023 . The research team proposed a unified video generation framework based on Transformer - Video Diffusion Transformer (VDT), and gave a detailed explanation of the reasons for adopting the Transformer architecture. 
- Paper title: VDT: General-purpose Video Diffusion Transformers via Mask Modeling
- Article address: Openreview: https://openreview.net/pdf?id=Un0rgm9f04
- arXiv address: https://arxiv.org/abs/2305.13311
- Project address: VDT: General-purpose Video Diffusion Transformers via Mask Modeling
- Code address: https://github.com/RERV/VDT
1. The superiority and innovation of VDTResearchers said that the superiority of the VDT model using the Transformer architecture in the field of video generation is reflected in:
- Unlike U-Net, which is mainly designed for images, Transformer is able to capture long-term or irregular temporal dependencies with its powerful tokenization and attention mechanisms. properties to better handle the time dimension.
- Only when the model learns (or memorizes) world knowledge (such as space-time relationships and physical laws) can it generate videos consistent with the real world. Therefore, model capacity becomes a key component of video diffusion. Transformer has been proven to be highly scalable. For example, the PaLM model has up to 540B parameters, while the largest 2D U-Net model size at the time was only 2.6B parameters (SDXL), which makes Transformer more suitable than 3D U-Net. Video generation challenges.
- The field of video generation covers multiple tasks including unconditional generation, video prediction, interpolation, and text-to-image generation. Previous research often focused on a single task, often requiring the introduction of specialized modules for fine-tuning downstream tasks. Furthermore, these tasks involve a wide variety of conditional information that may differ across frames and modalities, requiring a powerful architecture that can handle different input lengths and modalities. The introduction of Transformer can unify these tasks.
The innovation of VDT mainly includes the following aspects:
- Applying Transformer technology to diffusion-based video generation demonstrates the great potential of Transformer in the field of video generation. The advantage of VDT is its excellent time-dependent capture capability, enabling the generation of temporally coherent video frames, including simulating the physical dynamics of three-dimensional objects over time.
- Propose a unified spatio-temporal mask modeling machine, which enables VDT to handle a variety of video generation tasks and achieves widespread application of the technology. VDT's flexible conditional information processing methods, such as simple token space splicing, effectively unify information of different lengths and modalities. At the same time, by combining with the spatiotemporal mask modeling mechanism proposed in this work, VDT has become a universal video diffusion tool that can be applied to unconditional generation, video subsequent frame prediction, frame interpolation, and image generation without modifying the model structure. Various video generation tasks such as video and video screen completion.
2. Detailed interpretation of VDT’s network architecture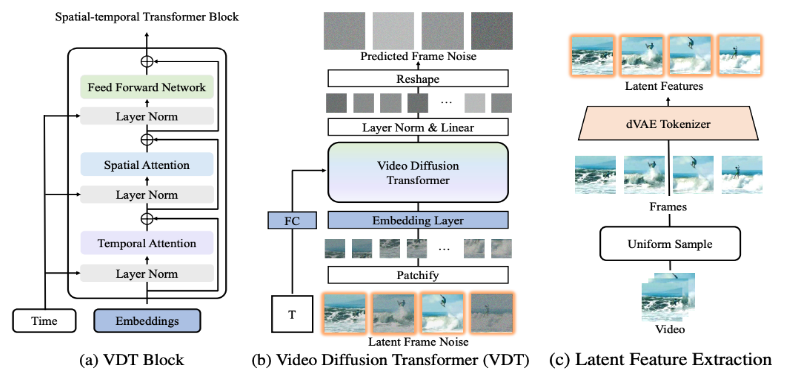
The VDT framework is very similar to Sora's framework and consists of the following parts: Input/Output Features. The goal of VDT is to generate an F×H×W×3 video segment consisting of F frames of video of size H×W. However, if raw pixels are used as input to VDT, especially when F is large, it will lead to extremely computational complexity. To solve this problem, inspired by the latent diffusion model (LDM), VDT uses a pre-trained VAE tokenizer to project the video into the latent space. Reducing the vector dimensions of input and output to F×H/8×W/8×C of latent features/noise accelerates the training and inference speed of VDT, where the size of the latent features of F frame is H/8×W/8 . Here 8 is the downsampling rate of VAE tokenizer, and C represents the latent feature dimension. Linear embedding. Following the Vision Transformer approach, VDT partitions the latent video feature representation into non-overlapping patches of size N×N. Space-time Transformer Block. Inspired by the success of spatiotemporal self-attention in video modeling, VDT inserted a temporal attention layer into the Transformer Block to obtain temporal dimension modeling capabilities. Specifically, each Transformer Block consists of a multi-head temporal attention, a multi-head spatial attention and a fully connected feed-forward network, as shown in the figure above. Comparing the latest technical report released by Sora, we can see that there are only some subtle differences between VDT and Sora in the implementation details. First of all, VDT adopts the method of processing the attention mechanism separately in the space and time dimensions, while Sora merges the time and space dimensions and uses a single attention mechanism to handle it. This separation of attention approach has become quite common in the video field and is often seen as a compromise option under the constraints of video memory. VDT chooses to use split attention because of limited computing resources. Sora's powerful video dynamic capabilities may come from the overall attention mechanism of space and time.
#Secondly, unlike VDT, Sora also considers the fusion of text conditions. There has also been previous research on text conditional fusion based on Transformer (such as DiT). It is speculated that Sora may further add a cross-attention mechanism to its module. Of course, directly splicing text and noise as a form of conditional input is also a potential possibility. .
During the research process of VDT,
researchers replaced U-Net, a commonly used basic backbone network, with Transformer. This not only verified the effectiveness of Transformer in video diffusion tasks, showing the advantages of easy expansion and enhanced continuity, but also triggered their further thinking about its potential value. With the success of the GPT model and the popularity of the autoregressive (AR) model, researchers have begun to explore deeper applications of Transformer in the field of video generation, and consider whether it can Provide new ways to achieve visual intelligence. The field of video generation has a closely related task - video prediction. The idea of predicting the next video frame as a path to visual intelligence may seem simple, but it is actually a common concern among many researchers.
Based on this consideration, researchers hope to further adapt and optimize their models on video prediction tasks. The video prediction task can also be regarded as conditional generation, where the given conditional frames are the first few frames of the video. VDT mainly considers the following three condition generation methods:
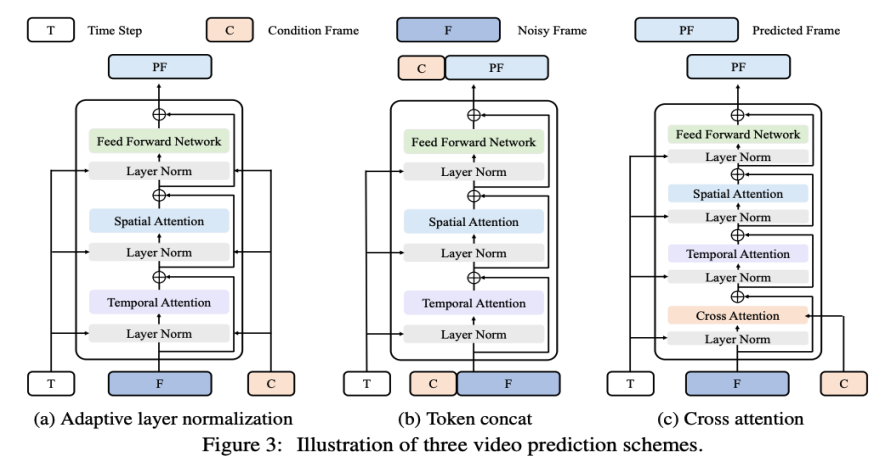 Adaptive layer normalization. A straightforward way to achieve video prediction is to integrate conditional frame features into layer normalization of VDT Blocks, similar to how we integrate temporal information into the diffusion process. Cross Attention. Researchers have also explored using cross-attention as a video prediction scheme, where conditional frames are used as keys and values, and noise frames are used as queries. This allows fusion of conditional information with noise frames. Before entering the cross-attention layer, use VAE tokenizer to extract the features of the conditional frame and patch them. Meanwhile, spatial and temporal position embeddings are also added to help our VDT learn the corresponding information in conditional frames. Token splicing. The VDT model adopts a pure Transformer architecture, so directly using conditional frames as input tokens is a more intuitive method for VDT. We achieve this by concatenating conditioned frames (latent features) and noise frames at the token level, which are then fed into the VDT. Next, they segmented the output frame sequence of VDT and used the predicted frames for a diffusion process, as shown in Figure 3 (b). The researchers found that this scheme demonstrated the fastest convergence speed and provided better performance in the final results compared with the first two methods. In addition, the researchers found that even if fixed-length conditional frames are used during training, VDT can still accept conditional frames of any length as input and output consistent prediction features. Under the framework of VDT, in order to achieve the video prediction task, there is no need to make any modifications to the network structure, only the input of the model needs to be changed. This finding leads to an intuitive question: Can we further exploit this scalability to extend VDT to more diverse video generation tasks - such as image generation video - without introducing any additional Module or parameter . By reviewing the capabilities of VDT in unconditional generation and video prediction, the only difference lies in the type of input features. Specifically, the input can be purely noisy latent features, or a concatenation of conditional and noisy latent features. Then, the researcher introduced Unified Spatial-Temporal Mask Modeling to unify the conditional input, as shown in Figure 4 below:
Adaptive layer normalization. A straightforward way to achieve video prediction is to integrate conditional frame features into layer normalization of VDT Blocks, similar to how we integrate temporal information into the diffusion process. Cross Attention. Researchers have also explored using cross-attention as a video prediction scheme, where conditional frames are used as keys and values, and noise frames are used as queries. This allows fusion of conditional information with noise frames. Before entering the cross-attention layer, use VAE tokenizer to extract the features of the conditional frame and patch them. Meanwhile, spatial and temporal position embeddings are also added to help our VDT learn the corresponding information in conditional frames. Token splicing. The VDT model adopts a pure Transformer architecture, so directly using conditional frames as input tokens is a more intuitive method for VDT. We achieve this by concatenating conditioned frames (latent features) and noise frames at the token level, which are then fed into the VDT. Next, they segmented the output frame sequence of VDT and used the predicted frames for a diffusion process, as shown in Figure 3 (b). The researchers found that this scheme demonstrated the fastest convergence speed and provided better performance in the final results compared with the first two methods. In addition, the researchers found that even if fixed-length conditional frames are used during training, VDT can still accept conditional frames of any length as input and output consistent prediction features. Under the framework of VDT, in order to achieve the video prediction task, there is no need to make any modifications to the network structure, only the input of the model needs to be changed. This finding leads to an intuitive question: Can we further exploit this scalability to extend VDT to more diverse video generation tasks - such as image generation video - without introducing any additional Module or parameter . By reviewing the capabilities of VDT in unconditional generation and video prediction, the only difference lies in the type of input features. Specifically, the input can be purely noisy latent features, or a concatenation of conditional and noisy latent features. Then, the researcher introduced Unified Spatial-Temporal Mask Modeling to unify the conditional input, as shown in Figure 4 below:
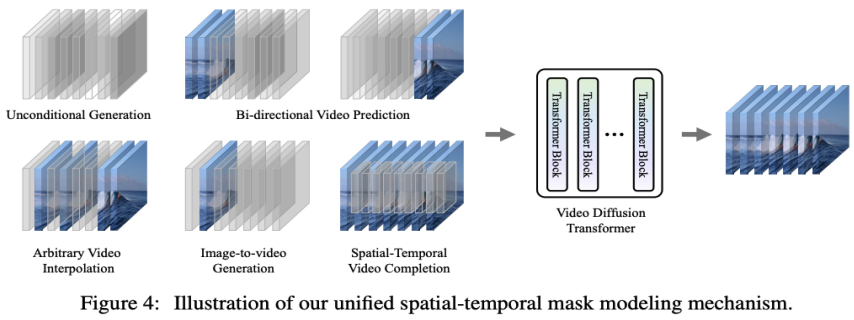
3. Performance evaluation of VDTWith the above method, the VDT model can not only handle unconditional video generation and video prediction tasks seamlessly, but also be able to do so by simply adjusting the input features , extended to a wider range of video generation fields, such as video frame interpolation, etc. This embodiment of flexibility and scalability demonstrates the powerful potential of the VDT framework and provides new directions and possibilities for future video generation technology. 
Interestingly, in addition to text-to-video, OpenAI also demonstrated other amazing tasks of Sora, including image-based generation, front and rear video prediction and different video clips The examples of fusion are very similar to the downstream tasks supported by the Unified Spatial-Temporal Mask Modeling proposed by the researcher; at the same time, kaiming's MAE is also cited in the reference literature. Therefore, it is speculated that the bottom layer of Sora also uses a MAE-like training method. #Researchers also explored the simulation of simple physical laws by the generative model VDT. They conducted experiments on the Physion dataset, where VDT uses the first 8 frames as conditional frames and predicts the next 8 frames. In the first example (top two rows) and the third example (bottom two rows), VDT successfully simulates physical processes involving a ball moving along a parabolic trajectory and a ball rolling on a plane and colliding with a cylinder . In the second example (middle two rows), the VDT captures the speed/momentum of the ball as it comes to a stop before hitting the cylinder. This proves that the Transformer architecture can learn certain physical laws. 
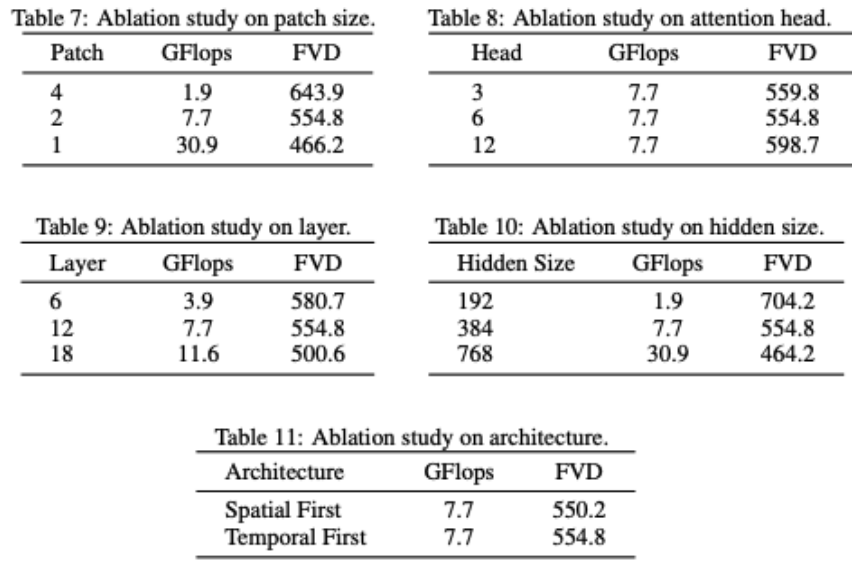
VDT partially ablates the network structure. It can be found that model performance is strongly related to GFlops, and some details of the model structure itself do not have a great impact. This is also consistent with the findings of DiT. The researchers also conducted some structural ablation studies on the VDT model. The results show that reducing the Patchsize, increasing the number of Layers, and increasing the Hidden Size can further improve the performance of the model. The positions of Temporal and Spatial attention and the number of attention heads have little impact on the results of the model. There are some design trade-offs required, but overall there is no significant difference in model performance while maintaining the same GFlops. However, an increase in GFlops leads to better results, demonstrating the scalability of the VDT or Transformer architecture. #VDT’s test results demonstrate the effectiveness and flexibility of the Transformer architecture in handling video data generation. Due to limitations of computing resources, VDT experiments were only conducted on some small academic datasets. We look forward to future research to further explore new directions and applications of video generation technology based on VDT, and we also look forward to Chinese companies launching domestic Sora models as soon as possible. The above is the detailed content of Domestic universities build Sora-like model VDT, and the universal video diffusion Transformer was accepted by ICLR 2024. For more information, please follow other related articles on the PHP Chinese website!



 What are the production methods of html5 animation production?
What are the production methods of html5 animation production?
 Three major characteristics of java
Three major characteristics of java
 jdk environment variable configuration
jdk environment variable configuration
 mstsc remote connection failed
mstsc remote connection failed
 What are the common management systems?
What are the common management systems?
 Solution to invalid signature
Solution to invalid signature
 What are the definitions of arrays?
What are the definitions of arrays?
 How to enter root privileges in linux
How to enter root privileges in linux








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



