


ImageNet accuracy was once the main indicator for evaluating model performance, but in today's computational vision field, this indicator gradually appears to be incomplete.
As computer vision models have become more complex, the variety of available models has increased significantly, from ConvNets to Vision Transformers. Training methods have also evolved to self-supervised learning and image-text pair training like CLIP, and are no longer limited to supervised training on ImageNet.
Although the accuracy of ImageNet is an important indicator, it is not sufficient to fully evaluate the performance of the model. Different architectures, training methods, and data sets may cause models to perform differently on different tasks, so relying solely on ImageNet to judge models may have limitations. When a model overfits the ImageNet dataset and reaches saturation in accuracy, the model's generalization ability on other tasks may be overlooked. Therefore, multiple factors need to be considered to evaluate the performance and applicability of the model.
Although CLIP's ImageNet accuracy is similar to ResNet, its visual encoder is more robust and transferable. This prompted researchers to explore the unique advantages of CLIP that were not apparent when considering only ImageNet metrics. This highlights the importance of analyzing other properties to help discover useful models.
Beyond this, traditional benchmarks cannot fully assess a model’s ability to handle real-world visual challenges, such as various camera angles, lighting conditions, or occlusions. Models trained on datasets such as ImageNet often find it difficult to leverage their performance in practical applications because real-world conditions and scenarios are more diverse.
These questions have brought new confusion to practitioners in the field: How to measure a visual model? And how to choose a visual model that suits your needs?
In a recent paper, researchers from MBZUAI and Meta conducted an in-depth discussion on this issue.

The research focuses on model behavior beyond ImageNet accuracy, analyzing the performance of major models in the field of computer vision, including ConvNeXt and Vision Transformer (ViT), which perform well in supervised and CLIP training paradigms lower performance.
The selected models have a similar number of parameters and almost the same accuracy on ImageNet-1K under each training paradigm, ensuring a fair comparison. The researchers deeply explored a series of model characteristics, such as prediction error type, generalization ability, invariance of learned representations, calibration, etc., focusing on the characteristics of the model without additional training or fine-tuning, hoping to directly References are provided by practitioners using pretrained models.
In the analysis, the researchers found that there were significant differences in model behavior across different architectures and training paradigms. For example, models trained under the CLIP paradigm produced fewer classification errors than those trained on ImageNet. However, the supervised model is better calibrated and generally outperforms on the ImageNet robustness benchmark. ConvNeXt has advantages on synthetic data, but is more texture-oriented than ViT. Meanwhile, supervised ConvNeXt performs well on many benchmarks, with transferability performance comparable to the CLIP model.
It can be seen that various models demonstrate their own advantages in unique ways, and these advantages cannot be captured by a single indicator. The researchers emphasize that more detailed evaluation metrics are needed to accurately select models in specific contexts and to create new ImageNet-agnostic benchmarks.
Based on these observations, Meta AI chief scientist Yann LeCun retweeted the study and liked:

For the supervised model, the researcher used ViT’s pre-trained DeiT3-Base/16, which has the same architecture as ViT-Base/16, but the training Method improvements; additionally ConvNeXt-Base is used. For the CLIP model, the researchers used the visual encoders of ViT-Base/16 and ConvNeXt-Base in OpenCLIP.
Please note that the performance of these models differs slightly from the original OpenAI models. All model checkpoints can be found on the GitHub project homepage. See Table 1 for detailed model comparison:

The researcher gave a detailed explanation of the model selection process:
1. Since researchers use pre-trained models, they cannot control the quantity and quality of data samples seen during training.
2. To analyze ConvNets and Transformers, many previous studies have compared ResNet and ViT. This comparison generally goes against ConvNet, as ViT is typically trained with more advanced recipes and achieves higher ImageNet accuracy. ViT also has some architectural design elements, such as LayerNorm, that were not incorporated into ResNet when it was invented many years ago. Therefore, for a more balanced evaluation, we compared ViT with ConvNeXt, a modern representative of ConvNet that performs on par with Transformers and shares many designs.
3. In terms of training mode, the researchers compared the supervised mode and the CLIP mode. Supervised models have maintained state-of-the-art performance in computer vision. CLIP models, on the other hand, perform well in terms of generalization and transferability and provide properties for connecting visual and linguistic representations.
4. Since the self-supervised model showed similar behavior to the supervised model in preliminary testing, it was not included in the results. This may be due to the fact that they ended up being supervised fine-tuned on ImageNet-1K, which affects the study of many features.
Next, let’s take a look at how researchers analyzed different attributes.
Model error
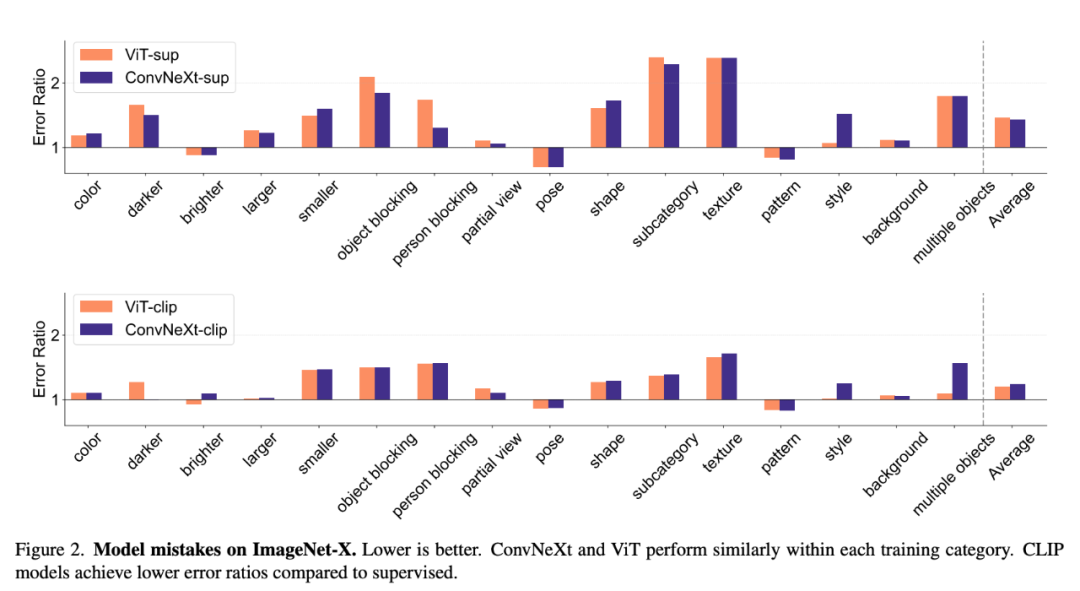
ImageNet-X is a dataset extending ImageNet-1K with detailed human annotation of 16 factors of variation, enabling in-depth analysis of model errors in image classification. It uses an error ratio metric (lower is better) to quantify a model's performance on specific factors relative to overall accuracy, allowing for a nuanced analysis of model errors. Results on ImageNet-X show:
#1. CLIP models make fewer errors in ImageNet accuracy relative to supervised models.
2. All models are mainly affected by complex factors such as occlusion.
3. Texture is the most challenging element of all models.
Shape/Texture Deviation
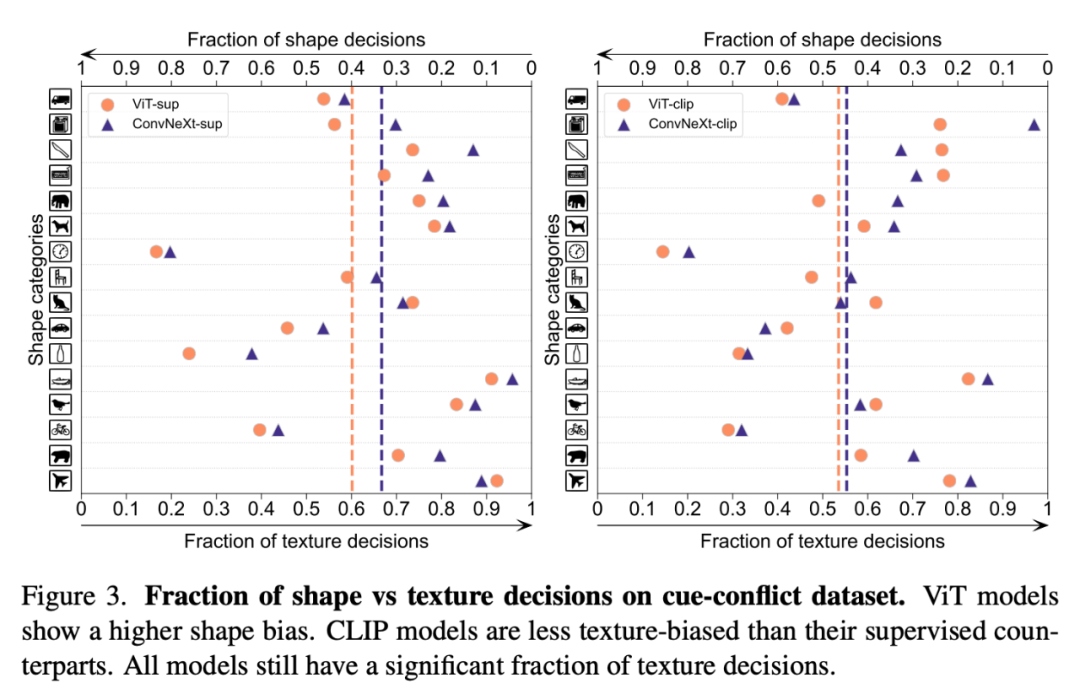
Shape-Texture Deviation will detect the model Whether to rely on fragile texture shortcuts rather than high-level shape cues. This bias can be studied by combining cue-conflicting images of different categories of shape and texture. This approach helps to understand to what extent a model's decisions are based on shape compared to texture. The researchers evaluated the shape-texture bias on the cue conflict dataset and found that the texture bias of the CLIP model was smaller than that of the supervised model, while the shape bias of the ViT model was higher than that of ConvNets.
Model Calibration
Calibrate the prediction confidence of the quantifiable model and its Consistency of actual accuracy can be assessed through metrics such as expected calibration error (ECE) and visualization tools such as reliability plots and confidence histograms. Calibration was evaluated on ImageNet-1K and ImageNet-R, classifying predictions into 15 levels. During the experiment, the researchers observed the following points:
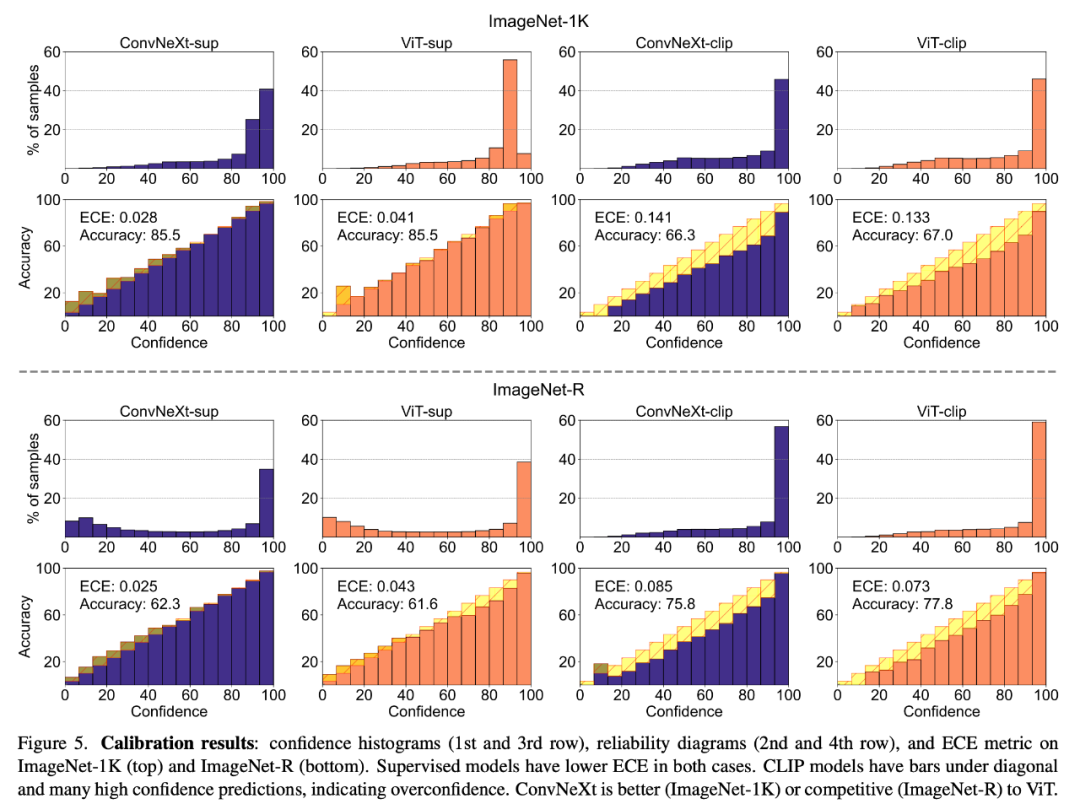
#1. The CLIP model is overconfident, while the supervised model is slightly underconfident.
2. Supervised ConvNeXt performs better calibration than supervised ViT.
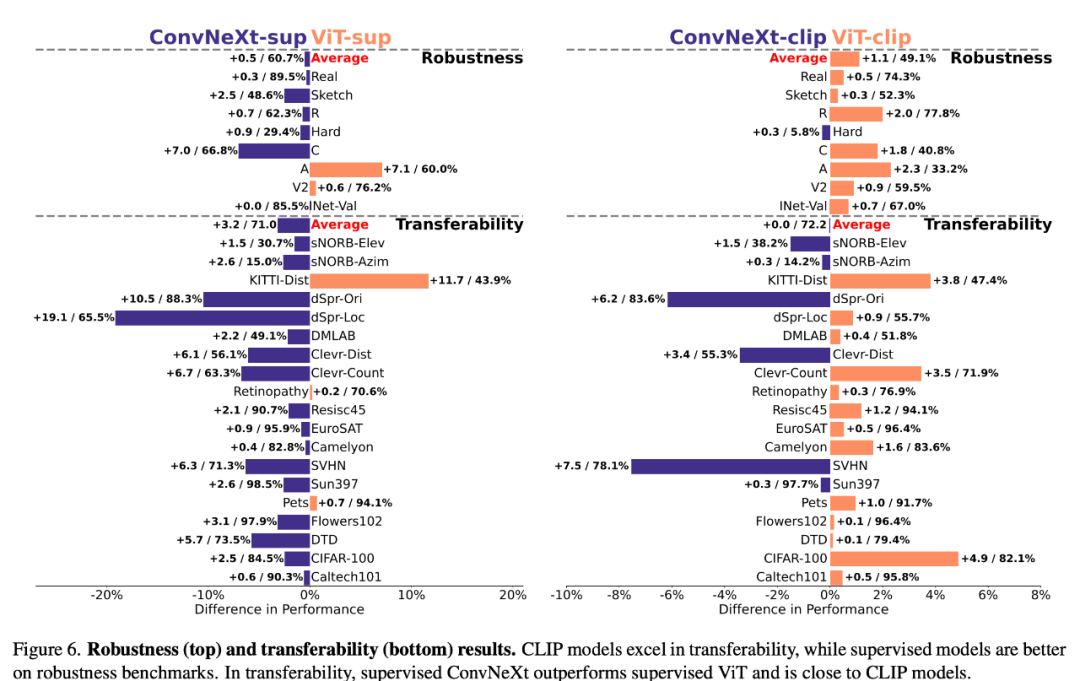
Robustness and transferability
The robustness and transferability of the model are important for adapting to changes in data distribution and The new mission is crucial. The researchers evaluated the robustness using various ImageNet variants and found that although the average performance of ViT and ConvNeXt models was comparable, except for ImageNet-R and ImageNet-Sketch, supervised models generally outperformed CLIP in terms of robustness. . In terms of transferability, supervised ConvNeXt outperforms ViT and is almost on par with the performance of the CLIP model, as evaluated on the VTAB benchmark using 19 datasets.
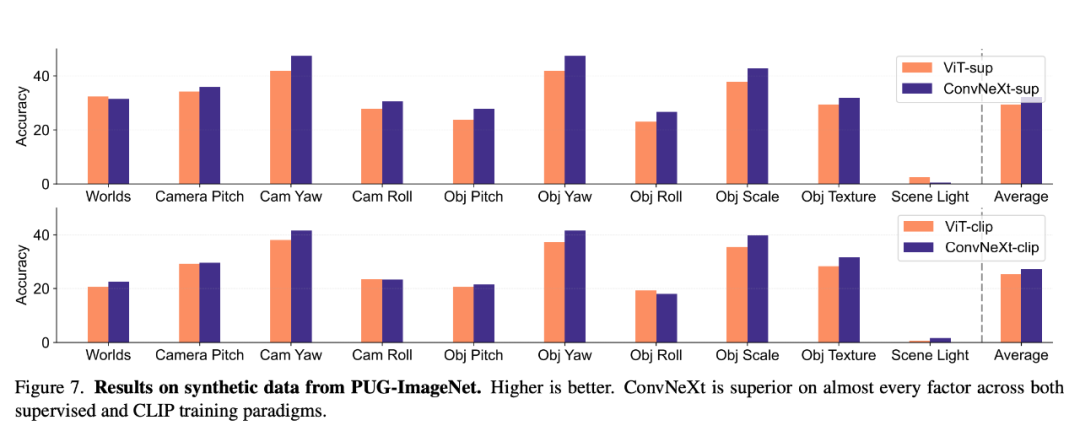
Synthetic data
Synthetic data sets such as PUG-ImageNet can accurately Controlling factors such as camera angle and texture is a promising research path, so the researchers analyzed the performance of the model on synthetic data. PUG-ImageNet contains photorealistic ImageNet images with systematic variation in factors such as pose and lighting, and performance is measured as absolute top-1 accuracy. The researchers provide results on different factors in PUG-ImageNet and find that ConvNeXt outperforms ViT in almost all factors. This shows that ConvNeXt outperforms ViT on synthetic data, while the gap for the CLIP model is smaller because the accuracy of the CLIP model is lower than the supervised model, which may be related to the lower accuracy of the original ImageNet.
Transformation invariance
Transformation invariance refers to the ability of the model to generate Consistent representations that are not affected by input transformations thus preserving semantics, such as scaling or moving. This property enables the model to generalize well across different but semantically similar inputs. Methods used include resizing images for scale invariance, moving crops for position invariance, and adjusting the resolution of ViT models using interpolated positional embeddings.
They evaluate scale, motion, and resolution invariance on ImageNet-1K by varying crop scale/position and image resolution. ConvNeXt outperforms ViT in supervised training. Overall, the model is more robust to scale/resolution transformations than to movements. For applications that require high robustness to scaling, displacement, and resolution, the results suggest that supervised ConvNeXt may be the best choice.

Overall, each model has its own unique advantages. This suggests that model selection should depend on the target use case, as standard performance metrics may ignore critical nuances of a specific task. Furthermore, many existing benchmarks are derived from ImageNet, which also biases the evaluation. Developing new benchmarks with different data distributions is crucial to evaluate models in a more real-world representative environment.
The following is a summary of the conclusions of this article:
ConvNet and Transformer
1. Supervised ConvNeXt outperforms supervised ViT on many benchmarks: it is better calibrated, more invariant to data transformations, and exhibits better transferability and robustness.
2. ConvNeXt performs better than ViT on synthetic data.
3. ViT has greater shape deviation.
Supervision and CLIP
#1. Although the CLIP model is superior in terms of transferability, there is supervision ConvNeXt performed competitively in this task. This demonstrates the potential of supervised models.
2. Supervised models perform better on robustness benchmarks, probably because these models are all ImageNet variants.
3. The CLIP model has greater shape bias and fewer classification errors compared to ImageNet’s accuracy.
The above is the detailed content of In the post-Sora era, how do CV practitioners choose models? Convolution or ViT, supervised learning or CLIP paradigm. For more information, please follow other related articles on the PHP Chinese website!
 What are the production methods of html5 animation production?
What are the production methods of html5 animation production?
 Three major characteristics of java
Three major characteristics of java
 jdk environment variable configuration
jdk environment variable configuration
 mstsc remote connection failed
mstsc remote connection failed
 What are the common management systems?
What are the common management systems?
 Solution to invalid signature
Solution to invalid signature
 What are the definitions of arrays?
What are the definitions of arrays?
 How to enter root privileges in linux
How to enter root privileges in linux








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



