


Although visual language models (VLMs) have made significant progress on many tasks, including image description, visual question answering, embodied planning, and action recognition, challenges remain in spatial reasoning. Many models still have difficulty understanding the location or spatial relationships of targets in three-dimensional space. This shows that in the process of further developing visual language models, it is necessary to focus on solving the problem of spatial reasoning to improve the accuracy and efficiency of the model in processing complex visual tasks.
Researchers often explore this question through human physical experience and evolutionary development. Humans have inherent spatial reasoning skills that allow them to easily determine spatial relationships, such as relative positions of objects, and estimate distances and sizes, without the need for complex thought processes or mental calculations.
This proficiency in direct spatial reasoning tasks contrasts with the limitations of the capabilities of current visual language models and raises a compelling research question: whether it is possible to empower visual language Does the model resemble human spatial reasoning abilities?
Recently, Google proposed a visual language model with spatial reasoning capabilities: SpatialVLM.

The researcher believes that the current visual language model is in space Limitations in inference capabilities may not come from limitations in its architecture, but more likely from limitations in the common datasets used for training. Many visual language models are trained on large-scale image-text pair datasets that contain limited spatial information. Obtaining spatially information-rich embodied data or performing high-quality human annotation is a challenging task. To solve this problem, automatic data generation and enhancement techniques are proposed. However, previous research mostly focuses on generating photorealistic images with real semantic annotations, while ignoring the richness of objects and 3D relationships. Therefore, future research could explore how to improve the model's understanding of spatial information through automatic generation techniques, for example by introducing more embodied data or focusing on modeling of objects and 3D relationships. This will help improve the performance of visual language models in spatial reasoning, making them more suitable for real-world application scenarios.
In contrast, this research focuses on directly extracting spatial information using real-world data to show the diversity and complexity of the real 3D world. This method is inspired by the latest visual modeling technology and can automatically generate 3D spatial annotations from 2D images.
A key function of the SpatialVLM system is to process large-scale densely annotated real-world data using techniques such as object detection, depth estimation, semantic segmentation and object center description models to enhance Spatial reasoning capabilities of visual language models. The SpatialVLM system achieves the goals of data generation and training of visual language models by converting data generated by visual models into a hybrid data format that can be used for description, VQA, and spatial reasoning. The researchers' efforts have enabled this system to better understand and process visual information, thereby improving its performance in complex spatial reasoning tasks. This approach helps train visual language models to better understand and process the relationship between images and text, thereby improving their accuracy and efficiency in various visual tasks.
Research shows that the visual language model proposed in this article exhibits satisfactory capabilities in multiple fields. First, it shows significant improvements in handling qualitative spatial problems. Second, the model is able to reliably produce quantitative estimates even in the presence of noise in the training data. This ability not only equips it with commonsense knowledge about target size, but also makes it useful in handling rearrangement tasks and open-vocabulary reward annotation. Finally, combined with a powerful large-scale language model, the spatial visual language model can perform spatial reasoning chains and solve complex spatial reasoning tasks based on natural language interfaces.
In order to enable the visual language model to have qualitative and quantitative spatial reasoning capabilities, the researchers proposed to generate a large-scale spatial VQA data set for training vision. Language model. Specifically, it is to design a comprehensive data generation framework that first utilizes off-the-shelf computer vision models, including open vocabulary detection, metric depth estimation, semantic segmentation and target-centered description models, to extract target-centered background information, A template-based approach is then adopted to generate large-scale spatial VQA data with reasonable quality. In this paper, the researchers used the generated data set to train SpatialVLM to learn direct spatial reasoning capabilities, and then combined it with the high-level common sense reasoning embedded in LLMs to unlock the spatial reasoning of chain thinking.

Spatial datum of 2D image
The researchers designed a process for generating VQA data containing spatial reasoning questions. The specific process is shown in Figure 2.

1. Semantic filtering: In the data synthesis process of this article, the first step is to use an open vocabulary based on CLIP The classification model classifies all images and excludes unsuitable images.
2. 2D image extraction target-centered background: This step obtains target-centered entities consisting of pixel clusters and open vocabulary descriptions.
3. 2D background information to 3D background information: After depth estimation, the 2D pixels of a single eye are upgraded to a metric-scale 3D point cloud. This paper is the first to upscale internet-scale images to object-centered 3D point clouds and use them to synthesize VQA data with 3D spatial inference supervision.
4. Disambiguation: Sometimes there may be multiple objects of similar categories in an image, resulting in ambiguity in their description labels. Therefore, before asking questions about these goals, you need to ensure that the reference expression does not contain ambiguity.
Large-scale spatial reasoning VQA data set
The researchers used synthetic data for pre-training to "intuitively ” spatial reasoning capabilities are integrated into VLM. Therefore, synthesis involves spatial reasoning question-answer pairs of no more than two objects (denoted A and B) in the image. The following two types of questions are mainly considered here:
1. Qualitative questions: asking about the judgment of certain spatial relationships. For example, "Given two objects A and B, which one is further to the left?"
2. Quantitative questions: Ask for more detailed answers, including numbers and units. For example, "How much to the left is object A relative to object B?", "How far is object A from B?"
Here, the researcher specified 38 different types of qualitative and quantitative spatial reasoning questions, each containing approximately 20 question templates and 10 answer templates.
Figure 3 shows an example of the synthetic question-answer pairs obtained in this article. The researchers created a massive dataset of 10 million images and 2 billion direct spatial reasoning question-answer pairs (50% qualitative, 50% quantitative).

Learn spatial reasoning
Direct space Inference: The visual language model receives an image I and a query Q about a spatial task as input and outputs an answer A presented in text format without the need to use external tools or interact with other large models. This article adopts the same architecture and training process as PaLM-E, except that the backbone of PaLM is replaced by PaLM 2-S. Model training was then performed using a mixture of the original PaLM-E dataset and the authors' dataset, with 5% of the tokens used for the spatial inference task.
Chained Thinking Spatial Reasoning: SpatialVLM provides a natural language interface that can be used to query questions with underlying concepts, and when combined with a powerful LLM, can perform complex spatial reasoning.
Similar to the methods in Socratic Models and LLM coordinator, this article uses LLM (text-davinci-003) to coordinate communication with SpatialVLM and solve complex problems in a chain thinking prompt. The problem is shown in Figure 4.

The researcher proved and answered the following questions through experiments:
Question 1: Does the spatial VQA data generation and training process designed in this article improve the general spatial reasoning ability of VLM? And how does it perform?
Question 2: What impact does synthetic spatial VQA data full of noisy data and different training strategies have on learning performance?
Question 3: Can a VLM equipped with "direct" spatial reasoning capabilities unlock new capabilities such as chain thinking reasoning and embodied planning?
The researchers trained the model by using a mixture of the PaLM-E training set and the spatial VQA data set designed in this article. To verify whether the limitation of VLM in spatial reasoning is a data problem, they selected the current state-of-the-art visual language model as a baseline. The semantic description task occupies a considerable proportion in the training process of these models, rather than using the spatial VQA data set of this article for training.
Spatial VQA performance
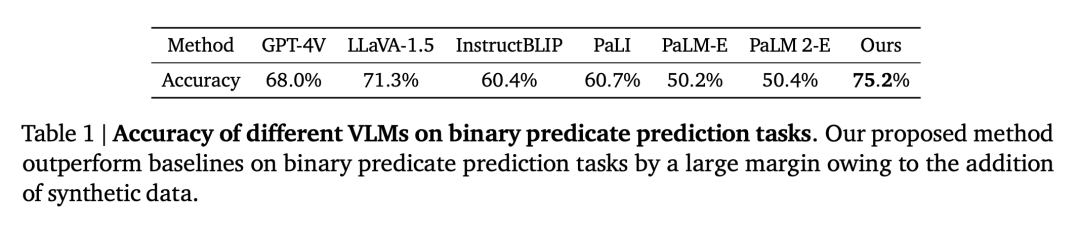
Qualitative spatial VQA. For this question, both the human-annotated answers and the VLM output are free-form natural language. Therefore, to evaluate the performance of VLMs, we used human raters to determine whether the answers were correct, and the success rates for each VLM are shown in Table 1.
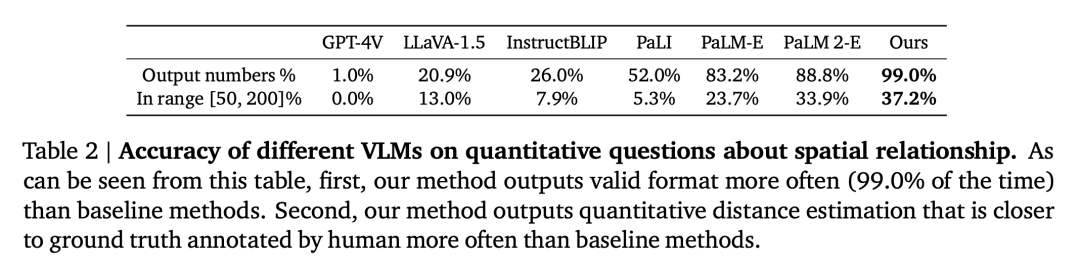
Quantitative spatial VQA. As shown in Table 2, our model performs better than the baseline on both metrics and is far ahead.
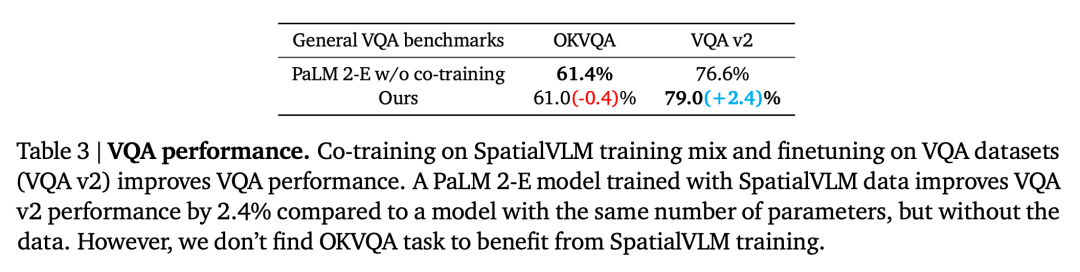
##The impact of spatial VQA data on general VQA
The second question is whether the performance of VLM on other tasks will be reduced due to co-training with a large amount of spatial VQA data. By comparing our model with the basic PaLM 2-E trained on the general VQA benchmark without using spatial VQA data, as summarized in Table 3, our model achieves comparable performance to PaLM 2-E on the OKVQA benchmark. Performance, which includes limited spatial inference problems, is slightly better on the VQA-v2 test-dev benchmark, which includes spatial inference problems.
Impact of ViT Encoder in Spatial Reasoning
Does Frozen ViT (trained on contrasting targets) encode enough information for spatial reasoning? To explore this, the researchers' experiments started at training step 110,000 and were divided into two training runs, one Frozen ViT and the other Unfrozen ViT. By training both models for 70,000 steps, the evaluation results are shown in Table 4.

The impact of noisy quantitative spatial answers
The researchers used the robot operation data set to train the visual language model and found that the model was able to perform fine distance estimation in the operation field (Figure 5), further proving the accuracy of the data.
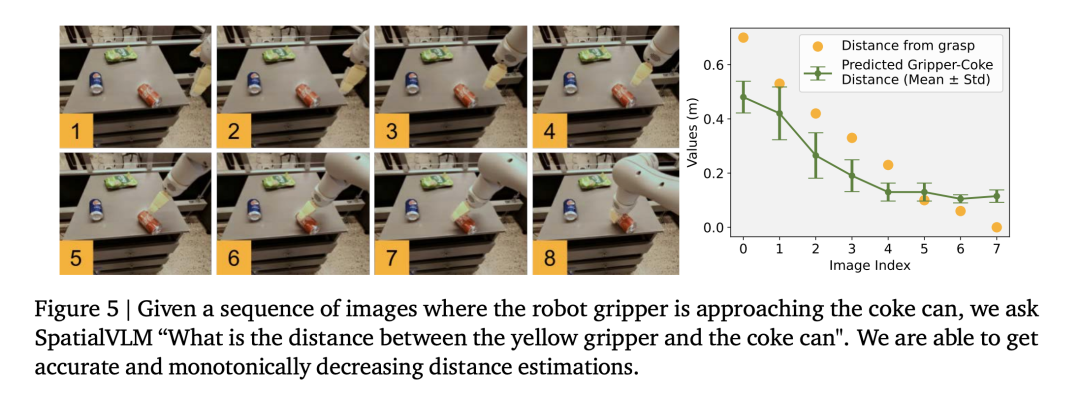
Table 5 compares the impact of different Gaussian noise standard deviations on overall VLM performance in quantitative spatial VQA.

1. Vision Language models as dense reward annotators
Visual language models have an important application in the field of robotics. Recent research has shown that visual language models and large language models can serve as general open vocabulary reward annotators and success detectors for robotic tasks, which can be used to develop effective control strategies. However, VLM's reward labeling capabilities are often limited by insufficient spatial awareness. SpatialVLM is uniquely suited as a dense reward annotator due to its ability to quantitatively estimate distances or dimensions from images. The authors conduct a real-world robotics experiment, specify a task in natural language, and ask SpatialVLM to annotate rewards for each frame in the trajectory.
Each dot in Figure 6 represents the location of a target, and their color represents the annotated reward. As the robot progresses towards a given goal, rewards are seen to increase monotonically, demonstrating SpatialVLM's capabilities as a dense reward annotator.

2. Chain thinking space reasoning
The researchers also investigated whether SpatialVLM can be used to perform tasks requiring multi-step reasoning, given its enhanced ability to answer basic spatial questions. The authors show some examples in Figures 1 and 4. When the large language model (GPT-4) is equipped with SpatialVLM as the spatial reasoning sub-module, it can perform complex spatial reasoning tasks, such as answering whether 3 objects in the environment can form an "isosceles triangle".
For more technical details and experimental results, please refer to the original paper.
The above is the detailed content of Let the visual language model do spatial reasoning, and Google is new again. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



