


Process scheduling is one of the core functions of the operating system. It determines which processes can get CPU execution time and how much time they get. In Linux systems, there are many process scheduling algorithms, the most important and commonly used one is Completely Fair Scheduling Algorithm (CFS), which was introduced from Linux version 2.6.23. The goal of CFS is to allow each process to obtain a reasonable and fair allocation of CPU time according to its own weight and needs, thereby improving the overall performance and response speed of the system. This article will introduce the basic principles, data structure, implementation details, advantages and disadvantages of CFS, and help you deeply understand the complete fairness of Linux process scheduling.
A brief history of the Linux scheduler
Early Linux schedulers used a minimalist design that clearly wasn't focused on large architectures with many processors, let alone hyper-threading. 1.2 The Linux scheduler uses a ring queue for runnable task management and uses a round-robin scheduling strategy. This scheduler adds and removes processes very efficiently (with locks protecting the structure). In short, the scheduler is not complex but simple and fast.
Linux version 2.2 introduced the concept of scheduling classes, allowing scheduling strategies for real-time tasks, non-preemptive tasks, and non-real-time tasks. The 2.2 scheduler also includes symmetric multiprocessing (SMP) support.
The 2.4 kernel includes a relatively simple scheduler that runs at O(N) intervals (it iterates over each task during the scheduling event). 2.4 The scheduler divides time into epochs. In each epoch, each task is allowed to execute until its time slice is exhausted. If a task does not use all of its time slices, then half of the remaining time slices will be added to the new time slice so that it can execute longer in the next epoch. The scheduler simply iterates over tasks and applies a goodness function (metric) to decide which task to execute next. Although this method is relatively simple, it is inefficient, lacks scalability and is not suitable for use in real-time systems. It also lacks the ability to take advantage of new hardware architectures, such as multi-core processors.
The early 2.6 scheduler, called the O(1) scheduler, was designed to solve a problem with the 2.4 scheduler - the scheduler did not need to iterate through the entire list of tasks to determine the next task to schedule (hence the name O(1) , which means it is more efficient and scalable). The O(1) scheduler keeps track of runnable tasks in the run queue (actually, there are two run queues per priority level - one for active tasks and one for expired tasks), which means determining which tasks to execute next task, the scheduler simply takes the next task off the run queue of a specific activity by priority). The O(1) scheduler scales better and includes interactivity, providing a wealth of insights for determining whether a task is I/O bound or processor bound. But the O(1) scheduler is clumsy in the kernel. Requires a lot of code to compute revelations, is difficult to manage, and for purists fails to capture the essence of the algorithm.
To solve the problems faced by the O(1) scheduler and to deal with other external pressures, something needs to be changed. This change comes from Con Kolivas's kernel patch, which includes his Rotating Staircase Deadline Scheduler (RSDL), which incorporates his early work on the staircase scheduler. The result of this work is a simply designed scheduler that incorporates fairness and bounded latency. Kolivas' scheduler has attracted a lot of attention (and many are calling for it to be included in the current 2.6.21 mainstream kernel), and it's clear that scheduler changes are coming. Ingo Molnar, the creator of the O(1) scheduler, then developed a CFS-based scheduler around some of Kolivas' ideas. Let’s dissect CFS and see how it operates at a high level.
————————————————————————————————————————
The main idea behind CFS is to maintain balance (fairness) in terms of providing processor time to tasks. This means that the process should be allocated a significant number of processors. When the time allotted to a task is out of balance (meaning that one or more tasks are not given a significant amount of time relative to other tasks), the out-of-balance task should be given time to execute.
To achieve balance, CFS maintains the amount of time provided to a task in what is called a virtual runtime. The smaller the virtual runtime of a task, the shorter the time the task is allowed to access the server - the higher the demand on the processor. CFS also includes the concept of sleep fairness to ensure that tasks that are not currently running (for example, waiting for I/O) get a fair share of the processor when they eventually need it.
But unlike the previous Linux scheduler, which did not maintain tasks in a run queue, CFS maintained a time-ordered red-black tree (see Figure 1). A red-black tree is a tree with many interesting and useful properties. First, it is self-balancing, meaning that no path in the tree is more than twice as long as any other path. Second, running on the tree occurs in O(log n) time (where n is the number of nodes in the tree). This means you can insert or delete tasks quickly and efficiently.
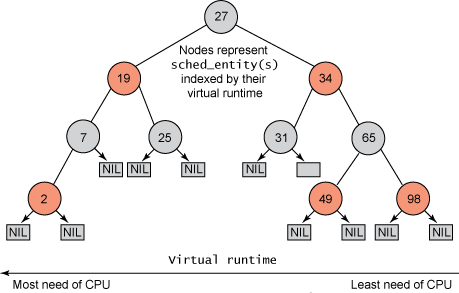
Tasks are stored in a time-ordered red-black tree (represented bysched_entityobjects), with the most processor-demanding tasks (lowest virtual runtime) stored on the left side of the tree , the tasks with the least processor requirements (highest virtual runtime) are stored on the right side of the tree. For fairness, the scheduler then selects the leftmost node of the red-black tree to be scheduled next to maintain fairness. A task accounts for its CPU time by adding its running time to the virtual runtime, and then, if runnable, inserted back into the tree. This way, tasks on the left side of the tree are given time to run, and the contents of the tree are migrated from the right to the left to maintain fairness. Therefore, each runnable task catches up with other tasks to maintain execution balance across the entire set of runnable tasks.
————————————————————————————————————————
All tasks within Linux are represented by a task structure calledtask_struct. This structure (and other related content) completely describes the task and includes the current state of the task, its stack, process identity, priority (static and dynamic), and so on. You can find these and related structures in ./linux/include/linux/sched.h. But because not all tasks are runnable, you won't find any CFS-related fields intask_struct. Instead, a new structure namedsched_entityis created to track scheduling information (see Figure 2).
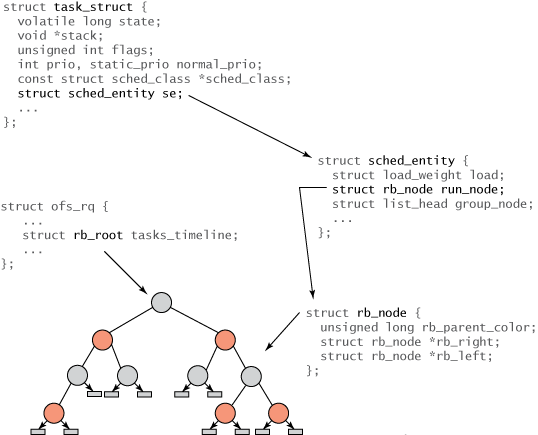
The relationship between various structures is shown in Figure 2. The root of the tree is referenced through thecfs_rqstructure (in ./kernel/sched.c) through therb_rootelement. The leaves of a red-black tree contain no information, but the internal nodes represent one or more runnable tasks. Each node of a red-black tree is represented byrb_node, which contains only the child reference and the color of the parent object.rb_nodeis contained within thesched_entitystructure, which containsrb_nodereferences, load weights, and various statistics. Most importantly,sched_entitycontainsvruntime(64-bit field), which represents the amount of time the task has been running and serves as an index into the red-black tree. Finally,task_structis at the top, which fully describes the task and contains thesched_entitystructure.
As far as the CFS part is concerned, the scheduling function is very simple. In ./kernel/sched.c you'll see the genericschedule()function, which preempts the currently running task (unless it preempts itself viayield()code ). Note that CFS has no real concept of time slicing for preemption because preemption time is variable. The currently running task (the one that is now preempted) is returned to the red-black tree by a call toput_prev_task(via the scheduling class). When theschedulefunction begins to determine the next task to be scheduled, it calls thepick_next_taskfunction. This function is also generic (in ./kernel/sched.c), but it calls the CFS scheduler through the scheduler class. Thepick_next_taskfunction in CFS can be found in ./kernel/sched_fair.c (calledpick_next_task_fair()). This function simply gets the leftmost task from the red-black tree and returns the associatedsched_entity. From this reference, a simpletask_of()call determines the returnedtask_structreference. The universal scheduler finally provides the processor for this task.
————————————————————————————————————————
CFS does not use priority directly but uses it as a decay factor for the time a task is allowed to execute. Low-priority tasks have a higher decay coefficient, while high-priority tasks have a lower decay coefficient. This means that the time allowed for task execution consumes faster for low-priority tasks than for high-priority tasks. This is a neat solution to avoid maintaining a priority-scheduled run queue.
Another interesting aspect of CFS is the group scheduling concept (introduced in the 2.6.24 kernel). Group scheduling is another way to bring fairness to scheduling, especially when dealing with tasks that spawn many other tasks. Suppose a server that spawns many tasks wants to parallelize incoming connections (a typical architecture for HTTP servers). Not all tasks are treated uniformly and fairly, and CFS introduces groups to handle this behavior. The server processes that spawn tasks share their virtual runtimes across the group (in a hierarchy), while individual tasks maintain their own independent virtual runtimes. This way individual tasks receive approximately the same scheduling time as the group. You'll find that the /proc interface is used to manage the process hierarchy, giving you complete control over how groups are formed. Using this configuration, you can distribute fairness across users, processes, or variations thereof.
Introduced together with CFS is the concept of scheduling class (can be reviewed in Figure 2). Each task belongs to a scheduling class, which determines how the task will be scheduled. The scheduling class defines a common set of functions (viasched_class) that define the behavior of the scheduler. For example, each scheduler provides a way to add tasks to be scheduled, call out the next task to run, provide it to the scheduler, and so on. Each scheduler class is connected to each other in a one-to-one connected list, allowing the classes to be iterated over (for example, to enable the disabling of a given processor). The general structure is shown in Figure 3. Note that enqueuing or dequeuing a task function simply adds or removes the task from a specific scheduling structure. Functionpick_next_taskSelects the next task to be executed (depending on the specific strategy of the scheduling class).

But don’t forget that the scheduling class is part of the task structure itself (see Figure 2). This simplifies the operation of tasks regardless of their scheduling class. For example, the following function uses the new task in ./kernel/sched.c to preempt the currently running task (wherecurrdefines the current running task,rqrepresents the CFS red-black tree andpis the next task to be scheduled):
static inline void check_preempt( struct rq *rq, struct task_struct *p ) { rq->curr->sched_class->check_preempt_curr( rq, p ); }
If this task is using the fair scheduling class,check_preempt_curr()will resolve tocheck_preempt_wakeup(). You can view these relationships in ./kernel/sched_rt.c, ./kernel/sched_fair.c and ./kernel/sched_idle.c.
Scheduling classes are another interesting place where scheduling changes, but as the scheduling domain increases, so does the functionality. These domains allow you to hierarchically group one or more processors for load balancing and isolation purposes. One or more processors can share a scheduling policy (and maintain load balancing among them) or implement independent scheduling policies to intentionally isolate tasks.
Continue to study scheduling and you will find schedulers under development that will push the boundaries of performance and scalability. Undeterred by his Linux experience, Con Kolivas developed another Linux scheduler, abbreviated as: BFS. The scheduler is said to have better performance on NUMA systems and mobile devices, and was introduced in a derivative of the Android operating system.
Through this article, you should have a basic understanding of CFS. It is one of the most advanced and efficient process scheduling algorithms in Linux systems. It uses red-black trees to store runnable process queues and calculates virtual The running time is used to measure the fairness of the process, and the response speed of the interactive process is improved by implementing the wake-up preemption feature, thereby achieving complete fairness in process scheduling. Of course, CFS is not perfect. It has some potential problems and limitations, such as over-compensation of active sleep processes, insufficient support for real-time processes, underutilization of multi-core processors, etc., which need to be addressed in future versions. Make improvements and optimizations. In short, CFS is an indispensable component in the Linux system and is worthy of your in-depth study and mastery.
The above is the detailed content of Linux CFS: How to achieve complete fairness in process scheduling. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



