


"Is the API of large models a loss-making business?"
With the practicalization of large language model technology, many technologies The company has launched a large model API for developers to use. However, we can't help but start to wonder whether a business based on large models can be sustained, especially considering that OpenAI is burning through $700,000 a day.
This Thursday, AI startup Martian calculated it carefully for us.
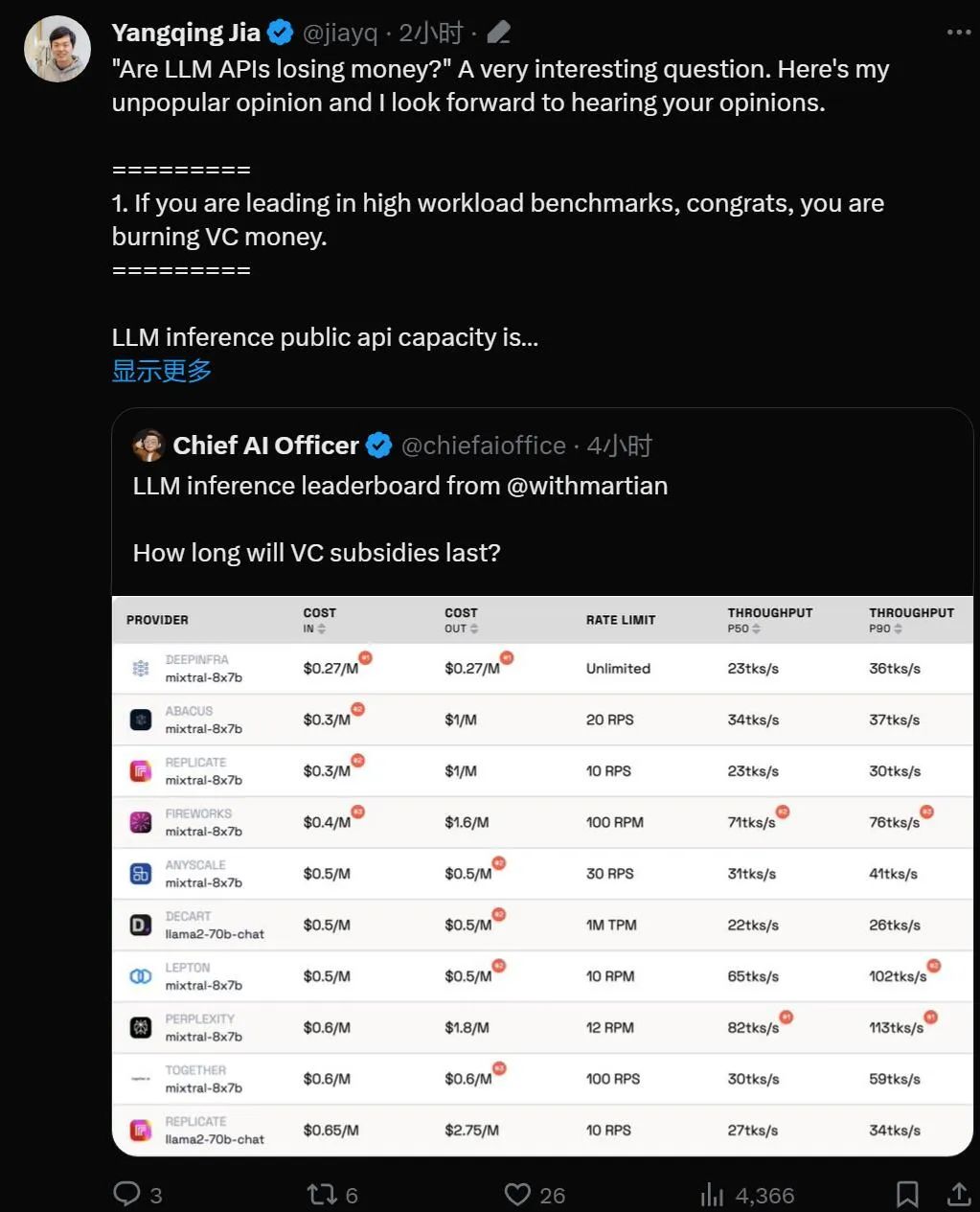
Leaderboard link: https://leaderboard.withmartian.com/
The LLM Inference Provider Leaderboard is an open-source ranking of API inference products for large models. It benchmarks the cost, rate limits, throughput, and P50 and P90 TTFT for the Mixtral-8x7B and Llama-2-70B-Chat public endpoints of each vendor.
Although they compete with each other, Martian found that there are significant differences in the cost, throughput and rate limits of each company's large model services. These differences exceed the 5x cost difference, 6x throughput difference, and even larger rate limit differences. Choosing different APIs is critical to getting the best performance, even though it's just part of doing business.
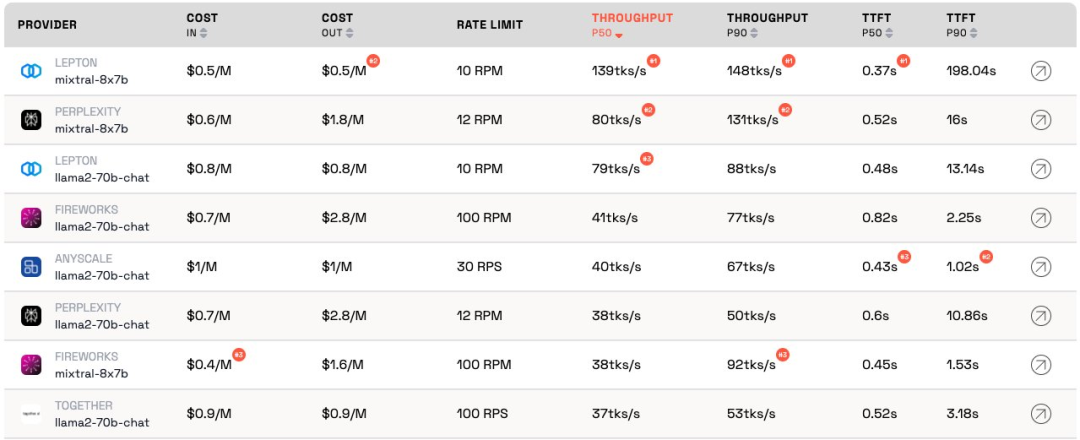
According to the current ranking, the service provided by Anyscale has the best throughput under the medium service load of Llama-2-70B. For large service loads, Together AI performed best with P50 and P90 throughput on Llama-2-70B and Mixtral-8x7B.
Additionally, Jia Yangqing’s LeptonAI showed the best throughput when handling small task loads with short input and long output cues. Its P50 throughput of 130 tks/s is the fastest among the models currently provided by all manufacturers on the market.
Well-known AI scholar and Lepton AI founder Jia Yangqing commented immediately after the rankings were released. Let’s see what he said.

Jia Yangqing first explained the current status of the industry in the field of artificial intelligence, then affirmed the significance of benchmark testing, and finally pointed out that LeptonAI will help users find the best AI Basic strategy.
1. Big model API is "burning money"
If the model is in high workload benchmark test Leading position, then congratulations, it is "burning money."
LLM Reasoning about the capacity of a public API is like running a restaurant: you have a chef and you need to estimate customer traffic. Hiring a chef costs money. Latency and throughput can be understood as "how fast you can cook for customers." For a reasonable business, you need a "reasonable" number of chefs. In other words, you want to have capacity that can handle normal traffic, not sudden bursts of traffic that occur in a matter of seconds. A surge in traffic means waiting; otherwise, the "cook" will have nothing to do.
In the world of artificial intelligence, GPU plays the role of "chef". Baseline loads are bursty. Under low workloads, the baseline load is blended into normal traffic, and the measurements provide an accurate representation of how the service performs under current workloads.
The high service load scenario is interesting because it will cause interruptions. The benchmark only runs a few times per day/week, so it's not the regular traffic one should expect. Imagine having 100 people flock to your local restaurant to check out how quickly the chef is cooking. The results would be great. To borrow the terminology of quantum physics, this is called the "observer effect." The stronger the interference (i.e. the larger the burst load), the lower the accuracy. In other words: if you put a sudden high load on a service and see that the service responds very quickly, you know that the service has quite a bit of idle capacity. As an investor, when you see this situation, you should ask: Is this way of burning money responsible?
2. The model will eventually achieve similar performance
The field of artificial intelligence is very fond of competitive competitions, which is indeed interesting. Everyone quickly converges on the same solution, and Nvidia always wins in the end because of the GPU. This is thanks to great open source projects, vLLM is a great example. This means that, as a provider, if your model performs much worse than others, you can easily catch up by looking at open source solutions and applying good engineering.
3. "As a customer, I don't care about the provider's cost"
For artificial intelligence application building For developers, we are lucky: there are always API providers willing to "burn money". The AI industry is burning money to gain traffic, and the next step is to worry about profits.
Benchmarking is a tedious and error-prone task. For better or worse, it usually happens that winners praise you and losers blame you. Such was the case with the last round of convolutional neural network benchmarks. It’s not an easy task, but benchmarking will help us achieve the next 10x in AI infrastructure.
Based on the artificial intelligence framework and cloud infrastructure, LeptonAI will help users find the best AI basic strategy.
The above is the detailed content of The large-scale inference cost rankings led by Jia Yangqing's high efficiency are released. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



