


Recently, the emergence of large language models (LLMs) and their advanced hinting strategies means that language model research has made significant progress, especially in classic natural language processing (NLP) tasks. One important innovation is the Chain of Thought (CoT) prompting technology, which is praised for its ability in multi-step problem solving. CoT technology follows human sequential reasoning and demonstrates excellent performance in a variety of challenges, including cross-domain, long-term generalization, and cross-language tasks. With its logical, step-by-step reasoning approach, CoT provides crucial interpretability in complex problem-solving scenarios.
Although CoT has made great progress, the research community has yet to reach a consensus on its specific mechanism and why it works. This knowledge gap means that improving CoT performance remains uncharted territory. Currently, trial-and-error is the main way to explore improvements in CoTs, as researchers lack a systematic methodology and can only rely on guesswork and experimentation. However, this also means that important research opportunities exist in this area: developing a deep, structured understanding of the inner workings of CoTs. Achieving this goal would not only demystify current CoT processes, but also pave the way for more reliable and efficient application of this technique in a variety of complex NLP tasks.
Research from researchers at Northwestern University, the University of Liverpool, and the New Jersey Institute of Technology further explores the relationship between the length of reasoning steps and the accuracy of conclusions to help people better Understand how to effectively solve natural language processing (NLP) problems. This study explores whether the inference step is the most critical part of the prompt that enables continuous open text (CoT) to function. In the experiment, the researchers strictly controlled the variables, especially when introducing new reasoning steps, to ensure that no additional knowledge was introduced. In the zero-sample experiment, the researchers adjusted the initial prompt from "Please think step by step" to "Please think step by step and try to think of as many steps as possible." For the small sample problem, the researchers designed an experiment that extended the basic reasoning steps while keeping all other factors constant. Through these experiments, the researchers found a correlation between the length of the reasoning steps and the accuracy of the conclusions. More specifically, participants tended to provide more accurate conclusions when the prompt asked them to think through more steps. This shows that when solving NLP problems, the accuracy of problem solving can be improved by extending the reasoning steps. This research is of great significance for a deep understanding of how NLP problems are solved, and provides useful guidance for further optimizing and improving NLP technology.

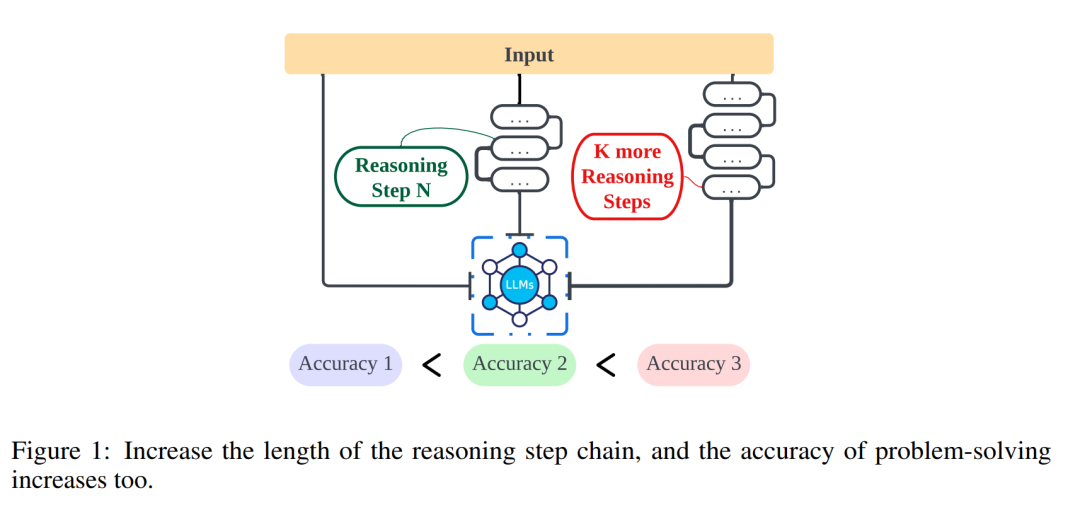
The main findings of this article are as follows:
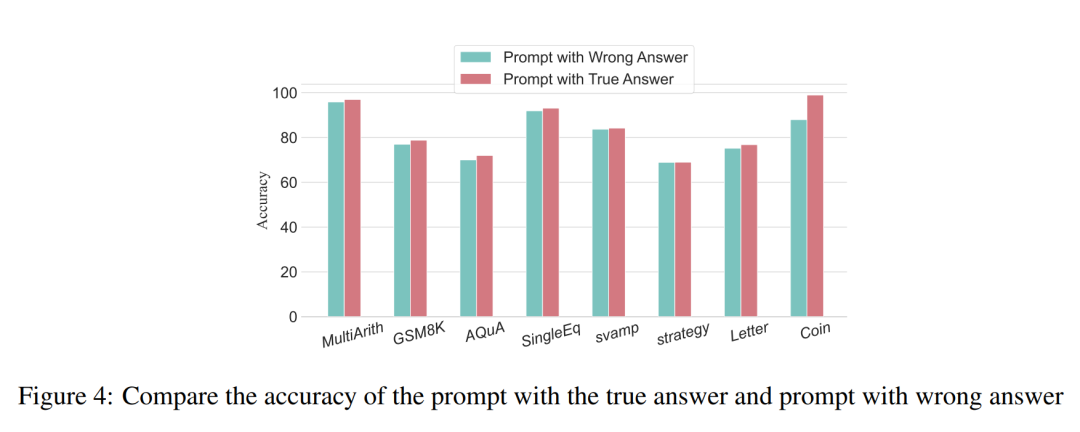
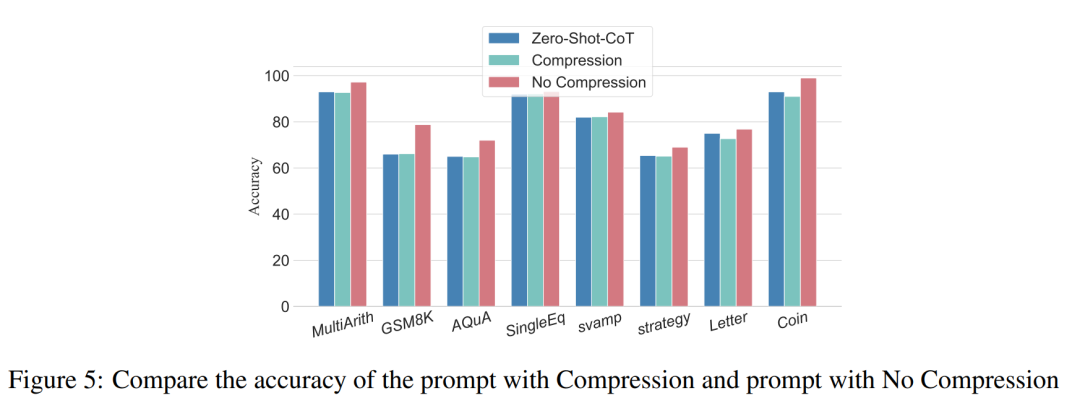
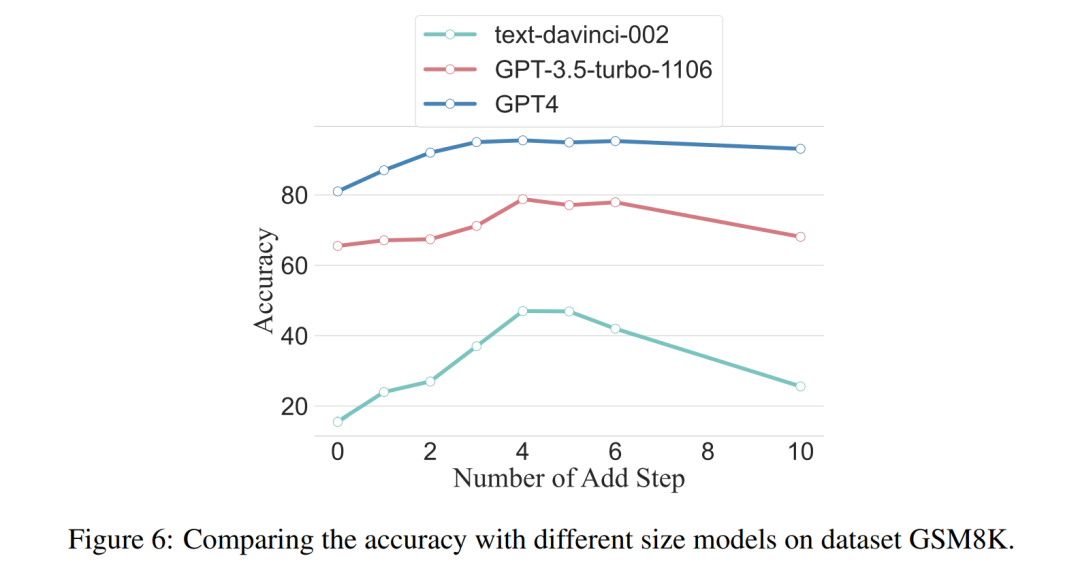
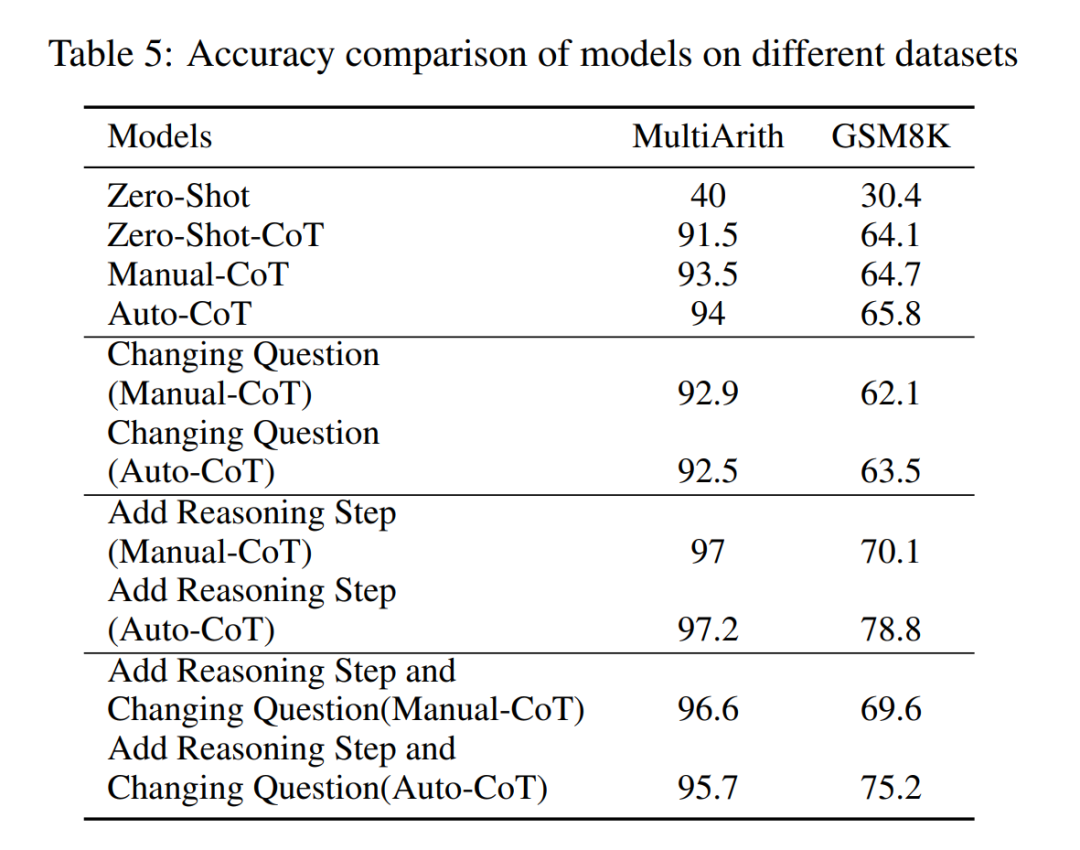
The researchers conducted analyzes to examine the relationship between reasoning steps and CoT prompt performance. The core assumption of their approach is that the serialization step is the most critical component of CoT cues during inference. These steps enable the language model to apply more logic for reasoning when generating reply content. To test this idea, the researchers designed an experiment to change the reasoning process of CoT by successively expanding and compressing the basic reasoning steps. At the same time, they held all other factors constant. Specifically, the researchers only systematically changed the number of reasoning steps without introducing new reasoning content or deleting existing reasoning content. Below they evaluate zero- and few-shot CoT cues. The entire experimental process is shown in Figure 2. Through this controlled variable analysis approach, the researchers elucidated how CoT affects LLM's ability to generate logically sound responses. ##Zero-sample CoT analysis In the zero-sample scenario, research The author changed the initial prompt from "Please think step by step" to "Please think step by step and think of as many steps as possible." This change was made because unlike the few-shot CoT environment, users cannot introduce additional inference steps during use. By changing the initial prompt, the researchers guided LLM to think more broadly. The importance of this approach lies in its ability to improve model accuracy without requiring incremental training or additional example-driven optimization methods that are typical in few-shot scenarios. This refinement strategy ensures a more comprehensive and detailed inference process, significantly improving the model's performance under zero-sample conditions. Small sample CoT analysis This section will modify the inference chain in CoT by adding or compressing inference steps . The aim is to study how changes in reasoning structure affect LLM decisions. During the expansion of the inference step, researchers need to avoid introducing any new task-relevant information. In this way, the reasoning step became the only study variable. To this end, the researchers designed the following research strategies to extend the inference steps of different LLM applications. People often have fixed patterns in the way they think about problems, such as repeating the problem over and over to gain a deeper understanding, creating mathematical equations to reduce memory load, analyzing the meaning of words in the problem to help understand the topic, summarizing the current state to simplify A description of the topic. Based on the inspiration of zero-sample CoT and Auto-CoT, researchers expect the CoT process to become a standardized model and obtain correct results by limiting the direction of CoT thinking in the prompt part. The core of this method is to simulate the process of human thinking and reshape the thinking chain. Five common prompt strategies are given in Table 6. Overall, the real-time strategies in this article are reflected in the model. What is shown in Table 1 is one example, and examples of the other four strategies can be viewed in the original paper. ##The relationship between reasoning steps and accuracy Table 2 compares the accuracy using GPT-3.5-turbo-1106 on eight datasets for three-class inference tasks. Thanks to the researchers' ability to standardize the thinking chain process, we can then quantify the impact of adding steps to the basic process of CoT on accuracy. degree of improvement. The results of this experiment can answer the question posed earlier: What is the relationship between inference steps and CoT performance? This experiment is based on the GPT-3.5-turbo-1106 model. The researchers found that an effective CoT process, such as adding up to six additional steps of thought process to the CoT process, will improve the reasoning ability of large language models, and this is reflected in all data sets. In other words, the researchers found a certain linear relationship between accuracy and CoT complexity. The impact of wrong answers The inference step affects LLM performance The only factor? The researchers made the following attempts. Change one step in prompt to an incorrect description and see if it affects the thought chain. For this experiment, we added an error to all prompts. See Table 3 for specific examples. For arithmetic type problems, even if one of the prompt results is deviated, the impact on the chain of thinking in the reasoning process will be minimal, so the researcher It is argued that when solving arithmetic-type problems, large language models learn more about chains of thought patterns in prompts than single computations. For logical problems like coin data, a deviation in the prompt result will often cause the entire thinking chain to fragment. The researchers also used GPT-3.5-turbo-1106 to complete this experiment and guaranteed performance based on the optimal number of steps for each data set obtained from previous experiments. The results are shown in Figure 4. Compression reasoning steps Previous experiments have demonstrated that adding inference steps can improve the accuracy of LLM inference. So does compressing the underlying inference steps hurt the performance of LLM in small sample problems? To this end, the researchers conducted an inference step compression experiment and used the techniques outlined in the experimental setup to condense the inference process into Auto CoT and Few-Shot-CoT to reduce the number of inference steps. The results are shown in Figure 5. The results show that the performance of the model drops significantly, returning to a level that is basically equivalent to the zero-sample method. This result further demonstrates that increasing CoT inference steps can improve CoT performance and vice versa. Performance comparison of models with different specifications The researchers also asked whether we can observe the scaling phenomenon. That is, the required inference steps are related to the size of the LLM? The researchers studied the average number of inference steps used in various models, including text-davinci-002, GPT-3.5-turbo-1106, and GPT-4. The average inference steps required for each model to reach peak performance were calculated through experiments on GSM8K. Among the 8 datasets, this dataset has the largest performance difference with text-davinci-002, GPT-3.5-turbo-1106, and GPT-4. It can be seen that in the text-davinci-002 model with the worst initial performance, the strategy proposed in this article has the highest improvement effect. The results are shown in Figure 6. Impact of problems in collaborative working examples Issues on LLM reasoning What is the impact of capabilities? The researchers wanted to explore whether changing the CoT's reasoning would affect the performance of the CoT. Since this article mainly studies the impact of the inference step on performance, the researcher needs to confirm that the problem itself has no impact on performance. Therefore, the researchers chose the datasets MultiArith and GSM8K and two CoT methods (auto-CoT and few-shot-CoT) to conduct experiments in GPT-3.5-turbo-1106. The experimental approach of this paper involves deliberate modifications to the sample problems in these mathematical data sets, such as changing the content of the questions in Table 4 . It is worth noting that preliminary observations show that the impact of these modifications to the problem itself on performance is the smallest among several factors, as shown in the table 5 shown. #This preliminary finding shows that the length of steps in the reasoning process is the most important factor affecting the reasoning ability of large models, and the influence of the problem itself is not Not the biggest. For more details, please read the original paper.
Research Methodology
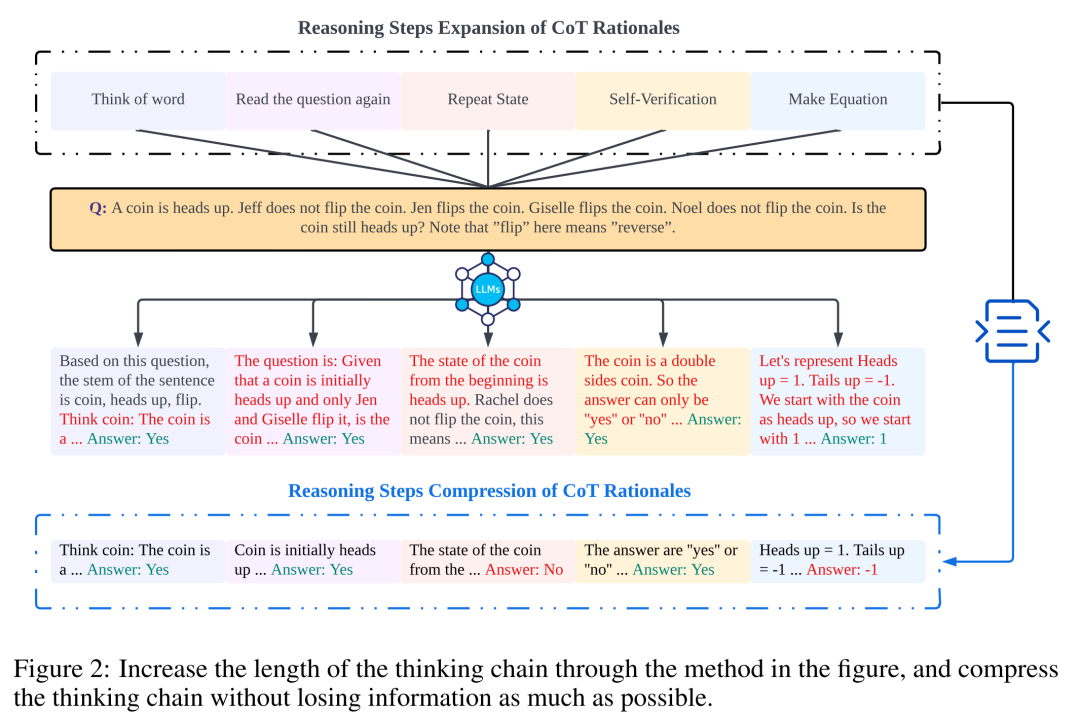


Experiments and results
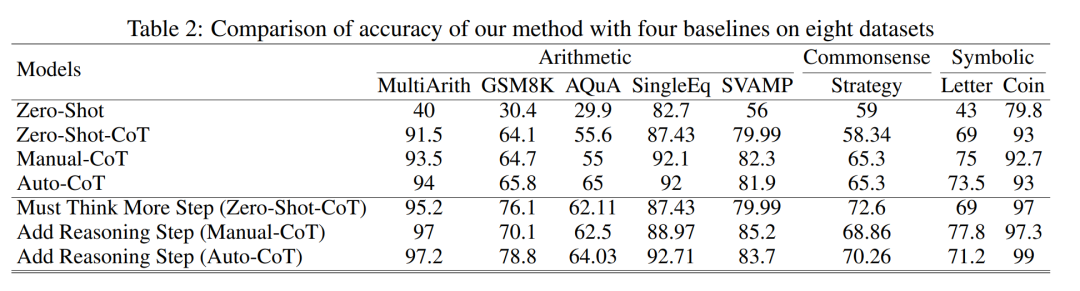
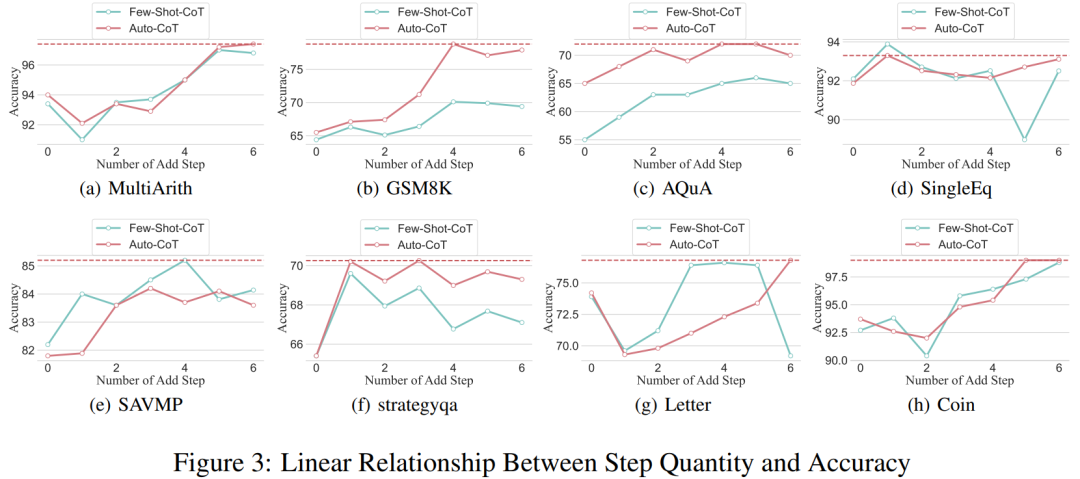


The above is the detailed content of More useful models require deeper 'step-by-step thinking' rather than just 'step-by-step thinking' that is not enough. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



