Artificial Intelligence Feedback (AIF) is going to replace RLHF?
In the field of large models, fine-tuning is an important step to improve model performance. As the number of open source large models gradually increases, people have summarized many methods of fine-tuning, some of which have achieved good results. Recently, researchers from Meta and New York University used the "self-reward method" to allow large models to generate their own fine-tuning data, which brought something new to people. Shocking. In the new method, the author conducted three iterations of fine-tuning Llama 2 70B, and the generated model outperformed a number of existing important large-scale models in the AlpacaEval 2.0 rankings. Models, including Claude 2, Gemini Pro and GPT-4. Therefore, the paper attracted people’s attention just a few hours after it was posted on arXiv. Although the method is not yet open source, it is believed that the method used in the paper is clearly described and should not be difficult to reproduce. 
It is well known that tuning large language models (LLMs) using human preference data can greatly improve the instruction tracking performance of pre-trained models. In the GPT series, OpenAI proposed a standard method of human feedback reinforcement learning (RLHF), which allows large models to learn reward models from human preferences, and then allows the reward models to be frozen and used to train LLM using reinforcement learning. This method has gained A huge success. A new idea that has emerged recently is to avoid training reward models entirely and directly use human preferences to train LLM, such as direct preference optimization (DPO). In both cases above, tuning is bottlenecked by the size and quality of the human preference data, and in the case of RLHF, the quality of tuning is also bottlenecked by the quality of the frozen reward models trained from them. In new work in Meta, the authors propose to train a self-improving reward model that is not frozen but continuously updated during LLM adjustment to avoid this A bottleneck. The key to this approach is to develop an agent with all the capabilities required during training (rather than splitting into a reward model and a language model), and let the instructions follow the task The pre-training and multi-task training allow task transfer by training multiple tasks simultaneously. Therefore the author introduces a self-reward language model, whose agents both act as instructions to follow the model, generating responses for given prompts, and can also generate and evaluate new ones based on examples. instructions to add to their own training set. The new approach uses a framework similar to iterative DPO to train these models. Starting from a seed model, as shown in Figure 1, in each iteration there is a self-instruction creation process, where the model generates candidate responses for the newly created prompts, and rewards are then assigned by the same model. The latter is achieved through prompts from LLM-as-a-Judge, which can also be viewed as an instruction-following task. Build a preference dataset from the generated data and train the next iteration of the model through DPO. 
Self-rewarded language modelThe method proposed by the author first assumes: access to a basic pre-trained language model and a small amount of human-annotated seed data, and then build a model designed to possess both skills: Generate high-quality, helpful (and harmless) responses. #2. Self-instruction creation: Ability to generate and evaluate new instructions following examples to add to your own training set. #These skills are used to enable the model to perform self-alignment, i.e. they are the components used to iteratively train itself using Artificial Intelligence Feedback (AIF). The creation of self-instructions involves generating candidate responses and then letting the model itself judge its quality, i.e. it acts as its own reward model, thereby replacing the need for an external model. This is achieved through the LLM-as-a-Judge mechanism [Zheng et al., 2023b], i.e. by formulating response evaluation as an instruction following task. This self-created AIF preference data was used as the training set. So during the fine-tuning process, the same model is used in both roles: as a "learner" and as a "judge". Based on the emerging judge role, the model can further improve performance through contextual fine-tuning. The overall self-alignment process is an iterative process that proceeds by building a series of models, each one an improvement over the last. What’s important in this is that since the model can both improve its generative capabilities and use the same generative mechanism as its own reward model, this means that the reward model itself can improve through these iterations, which is consistent with the standard inherent in reward models. There are differences in approach. Researchers believe that this method can increase the upper limit of the potential of these learning models to improve themselves in the future and eliminate restrictive bottlenecks. Figure 1 shows an overview of the method. 
Experiment

In the experiment, The researchers used Llama 2 70B as the basic pre-training model. They found that self-reward LLM alignment not only improved instruction following performance but also improved reward modeling capabilities compared to the baseline seed model. This means that in iterative training, the model is able to provide itself with a better quality preference data set in a given iteration than in the previous iteration. While this effect tends to saturate in the real world, it offers the interesting possibility that the resulting reward model (and thus the LLM) is better than a model trained solely from raw seed data written by humans. In terms of command following ability, the experimental results are shown in Figure 3:
The researchers evaluated the self-reward on the AlpacaEval 2 ranking list model, the results are shown in Table 1. They observed the same conclusion as the head-to-head evaluation, that is, the winning rate of training iterations was higher than that of GPT4-Turbo, from 9.94% in iteration 1, to 15.38% in iteration 2, to 20.44% in iteration 3. Meanwhile, the Iteration 3 model outperforms many existing models, including Claude 2, Gemini Pro, and GPT4 0613. 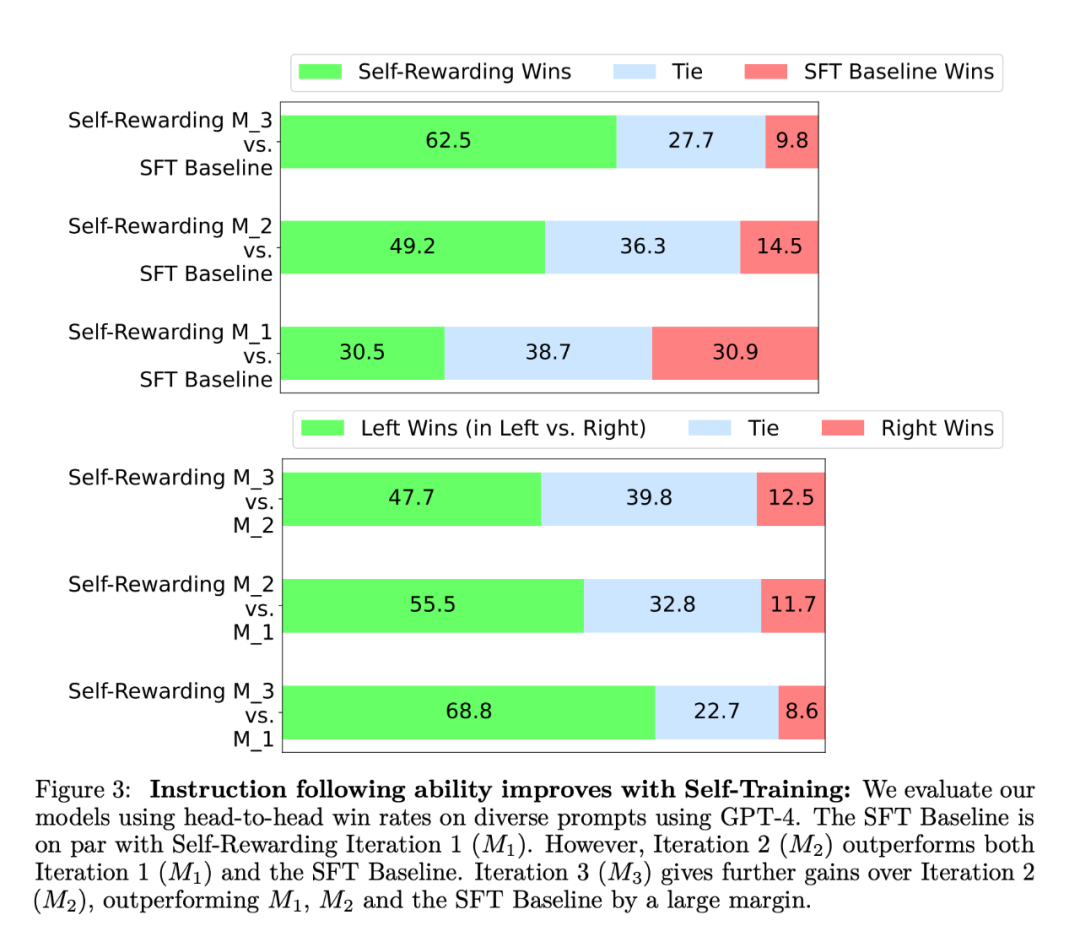 The reward modeling evaluation results are shown in Table 2. The conclusions include:
The reward modeling evaluation results are shown in Table 2. The conclusions include:

EFT has improved on the SFT baseline, using IFT EFT improved all five measurements compared to IFT alone. For example, the pairwise accuracy agreement with humans increased from 65.1% to 78.7%.
- Improve reward modeling capabilities through self-training. After a round of self-reward training, the model's ability to provide self-rewards for the next iteration is improved, and its ability to follow instructions is also improved.
- LLMas-a-Judge Importance of Tips. The researchers used various prompt formats and found that LLMas-a-Judge prompts had higher pairwise accuracy when using the SFT baseline.
The author believes that the self-reward training method not only improves the model's instruction tracking ability, but also improves the model's reward modeling ability in iterations. Although this is only a preliminary study, it appears to be an exciting direction for such models to better allocate rewards in future iterations. , to improve instruction compliance and achieve a virtuous cycle. This method also opens up certain possibilities for more complex judgment methods. For example, large models can verify the accuracy of their answers by searching a database, resulting in more accurate and reliable output. Reference content: https://www.reddit.com/r/MachineLearning/comments/19atnu0/r_selfrewarding_language_models_meta_2024/ The above is the detailed content of Large models under self-reward: Llama2 optimizes itself through Meta learning, surpassing the performance of GPT-4. For more information, please follow other related articles on the PHP Chinese website!




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



