


Outline
1. Log file system
2. Advantages of ext3
3. Three log modes of ext3
4. Select log mode
1. Log file system
Usually when the file content is written while the system is running, the metadata of the file (such as permissions, owner, creation and access time) is not written. If the file content is written after the file content is written and before the file metadata is written, During the time difference, the system shuts down abnormally, and the file system in the writing process will be unloaded abnormally, and the file system will be in an inconsistent state. When rebooting, Linux will run the fsck program, scanning the entire file system to ensure that all file blocks are correctly allocated or used, finding damaged directory entries and trying to repair them. However, fsck does not guarantee that damage will be repaired. When this happens, inconsistent metadata in the file will fill up the space of the lost file, and the file entries in the directory entry may be lost, resulting in the loss of the file.
In order to minimize the inconsistency of the file system and shorten the startup time of the operating system, the file system needs to track records that cause system changes. These records are stored in a place separate from the file system, usually we call it a "log". Once these log records are safely written, the log file system can use them to clean up the records that caused the system change, and organize them into a set that caused the file system change, placing them in the database transaction and keeping them in the state. The normal operation of valid data does not conflict with the performance of the entire system. In the event of any system crash or need to be restarted, the data is restored following the information recorded in the log file. Since there are regular checkpoints in the log files, they are usually very tidy. The design of the file system mainly considers efficiency and performance issues.
Linux can support many log file systems, including FAT, VFAT, HPFS (OS/2), NTFS (Windows NT), UFS, XFS, JFS, ReiserFS, ext2, ext3, etc.
2. Advantages of ext3
Why do you need to migrate from ext2 to ext3? Here are four main reasons: availability, data integrity, speed, ease of migration.
Availability
After an abnormal crash (power outage, system crash), the ext2 file system can be mounted and used only after consistency verification through e2fsck. The time to run e2fsck mainly depends on the size of the ext2 file system. Verifying slightly larger file systems (tens of gigabytes) takes a long time. If there are many files on the file system, the verification will take longer. Verifying a file system of several hundred gigabytes can take an hour or more. This greatly limits usability. In contrast, unless a hardware failure occurs, ext3 does not require file system verification even if it is shut down abnormally. This is because data is written to disk in a manner that is consistent across the file system. After an abnormal shutdown, the time to restore an ext3 file system does not depend on the size of the file system or the number of files, but on the size of the "log" required to maintain consistency. With default log settings, recovery time is only one second (depending on hardware speed).
Data integrity
Using the ext3 file system, data integrity performance is reliably guaranteed during abnormal shutdown. You can choose the type and level of data protection. You can choose to keep the file system consistent, but allow the data on the file system to be damaged during an abnormal shutdown; this can provide some speed improvements in some situations (but not all situations). You can also choose to keep data reliability consistent with the file system; this means that after a crash, you won't see any data garbage in newly written files. This safe option, which maintains data integrity consistent with the file system, is the default setting.
speed
Although ext3 writes data more times than ext2, ext3 is often faster than ext2 (high data flow). This is because the logging function of ext3 optimizes the rotation of the hard disk heads. You can choose from 1 of 3 logging modes to optimize speed, selectively sacrificing some data integrity. The first mode, data=writeback, provides limited data integrity and allows old data to exist in the file after a crash. This mode can improve speed in certain situations. (In most journaling file systems, this mode is the default setting. This mode provides limited data integrity for the ext2 file system, and is more to avoid long file system verification when the system starts) Second This mode, data = orderd (the default), keeps data reliability consistent with the file system; this means that after a crash, you won't see any junk data in newly written files. The third mode, data=journal, requires a larger journal to ensure moderate speed in most cases. It also takes longer to recover after a crash. But it will be faster in some database operations. Under normal circumstances, it is recommended to use the default mode. If you need to change the mode, please add the data=mode option to the corresponding file system in the /etc/fstab file. For details, please refer to the man page online manual of the mount command (execute man mount).
Easy to migrate
You can easily migrate from ext2 to ext3 without reformatting the hard disk and enjoy the benefits of a reliable journaling file system. Yes, you can experience the advantages of ext3 without doing the long, boring, and potentially error-prone "backup-reformat-restore" operation. There are two migration methods:
If you upgrade your system, the Red Hat Linux installer will assist with the migration. All you need to do is click the Select button for each file system.
Use the tune2fs program to add logging functionality to an existing ext2 file system. If the file system has been mounted during the conversion process, the file ".journal" will appear in the root directory; if the file system has not been mounted, the file will not appear in the file system. To convert the file system, just run tune2fs -j /dev/hda1 (or any device name where the file system you want to convert is located), and change ext2 in the file /etc/fstab to ext3. If you want to convert your own root file system, you must use initrd to boot. Run the program according to the manual description of mkinitrd, and confirm that initrd is loaded in your LILO or GRUB configuration (if it does not succeed, the system can still start, but the root file system will be loaded as ext2 instead of ext3. You can use the command cat / proc/mounts to confirm this.) For details, see the man page online manual for the tune2fs command (execute man tune2fs).
3. Three log modes of ext3
ext3 provides multiple log modes, that is, whether changing the metadata of the file system or changing the data of the file system (including changes to the file itself), the ext3 file system can support it. The following is when booting the /etc/fstab file Three different logging modes activated:
data=journal log mode
The log records include all data and metadata that changed the file system. It is the slowest of the three ext3 journaling modes, but it minimizes the chance of errors. Using "data=journal" mode requires ext3 to write each change to the file system twice and to the journal once, which will reduce the overall performance of the file system. All new data is written to the log first and then located. After an accident occurs, the logs can be replayed to bring the data and metadata back to a consistent state. Since metadata and data updates in ext3 are recorded, these logs will take effect when a system is restarted.
data=ordered log mode (default)
Only the metadata of the changed file system is recorded, and the overflow file data must be added to the disk. This is the default ext3 logging mode. This mode reduces the redundancy between writing to the file system and writing to the log, so it is faster. Although changes in file data are not recorded in the log, they must be done and are controlled by the ext3 daemon program. Executed before the related file system metadata changes, that is, the file system data must be modified before recording the metadata. This will slightly reduce the performance (speed) of the system, but it can ensure that the file data in the file system is consistent with that of the corresponding file system. Metadata synchronization.
data=writeback log mode
Only record the metadata of the changed file system, but according to the standard file system, the writing program still needs to record the changes in file data on the disk to maintain file system consistency. This is the fastest ext3 journaling mode. Because it only records metadata changes without waiting for updates related to file data such as file size, directory information, etc., the update of file data and the recording of metadata changes can be asynchronous, that is, ext3 supports asynchronous logs. The flaw is that when the system is shut down, the updated data is inconsistent because it cannot be written to the disk. This problem cannot be solved yet.
There are differences between different log modes, but the setting method is the same and convenient. Log mode can be specified using the ext3 file system, which is done at startup by /etc/fstab. For example, if you select data=writeback log mode, you can make the following settings:
/dev/hda5 /opt ext3 data=writeback 1 0
In general, the data=ordered log mode is the default mode of the ext3 file system.
To specify the logging method, you can use the following method:
1 Add the appropriate string to the options field of /etc/fstab such as data=journal
# /dev/sda3 /var ext3 defaults,data=writeback 1 2
2 Directly specify the -o data=journal command line option when calling mount.
# mount -o data=journal /dev/sdb1 /mnt
If we want to check the log mode of a certain file system, how should we query it? Here we can use the dmesg command:
# dmesg | grep -B 1 "mounted filesystem"
kjournald starting. Commit interval 5 seconds
EXT3-fs: mounted filesystem with ordered data mode.
--
EXT3 FS on sda1, internal journal
EXT3-fs: mounted filesystem with ordered data mode.
--
EXT3 FS on sdb1, internal journal
EXT3-fs: mounted filesystem with journal data mode.
--
EXT3 FS on sdb1, internal journal
EXT3-fs: mounted filesystem with writeback data mode.
4. Select log mode
speed
In some typical cases, using the option data=writeback can significantly increase the speed, but at the same time it will reduce the protection of data consistency. In these cases, data consistency protection is essentially the same as for the ext2 file system, except that during normal operation, the system continuously maintains the integrity of the file system (this is the journaling mode used by other journaling file systems). This includes frequent shared write operations, but also frequent creation and deletion of large numbers of small files, such as sending large numbers of small email messages. If you switch from ext2 to ext3 and find that application performance drops significantly, the option data=writeback may help you improve performance. Even if you don't get expensive data consistency protection measures, you can still enjoy the benefits of ext3 (the file system is always consistent). Red Hat is still doing work to improve some aspects of ext3 performance, so some aspects of ext3 performance can be improved in the future. This also means that even if you choose data=writeback now, you need to retest future versions with the default value of data=journal to determine whether the changes in the new version are relevant to your work.
Data integrity
In most cases, users write data at the end of the file. Only in some cases (such as databases) do users write data in the middle of an existing file. Even overwriting an existing file is accomplished by first truncating the file and then writing data from the end of the file. In data=ordered mode, if the system crashes while a file is being written, the data block may be partially overwritten, but the writing process is not completed, so the system has incomplete data blocks that do not belong to any file. In data=ordered mode, the only situation where unordered data blocks remain after a crash is if a program is rewriting a file during the crash. In this case, there is no absolute guarantee of write order unless the program uses fsync() and O_SYNC to force writes to occur in a specific order.
The ext3 file system also involves how to flush the data in the cache to the hard disk. It implements regular flushing through the kupdate process. The default is to check once every 5 seconds and flush dirty data that exceeds 30 seconds to the hard disk .
In as 3.0, the purpose can be achieved by modifying /proc/sys/vm/bdflush. In as 4.0, the purpose can be achieved by modifying /proc/sys/vm/dirty_writeback_centisecs and /proc/sys/vm/dirty_expire_centisecs.
Since the default is ordered mode, in this mode, if an IO writes the data file first, then writes the log file. If the system crashes after writing the data file and before writing the log file, this part of the data will be lost. This is absolutely not allowed in the database, whether it is Oracle or MySQL. So For database writes, each write operation will be written to the pagecache first, and then the kernelthread will be notified to flush the buffers to the hard disk, and then the metadata will be written to the log, and finally the successful write operation will be returned. In this way, writing operations to the database are obviously not as fast as writing to bare devices.
So when using Ext3 to run the database, set the log mode to journal mode, the performance should be improved (it has not been tested, the theoretical analysis should be like this). Because for a write operation in the database in journal mode, the data and file system changes are first written directly to the log (direct writing bypasses the cache, which has better performance), then the data is written to the cache, and then the kupdate process refreshes the data. to the hard drive. In contrast, for DB, its performance should be faster than the previous one.
In addition, here is the sync_binlog parameter in MySQL. If this parameter is set to 1, it means that every time the binlog file is written, it will be flushed to the hard disk at the same time, just like Oracle's writing IO. If this parameter is turned off, it will be managed by the OS, that is, it will be checked every 5 seconds. If old data from 30 seconds ago is found, it will be flushed to the hard disk. The innodb_flush_log_at_trx_commit parameter also involves the issue of flushing the hard disk.
As an enhanced version of ext2, ext3 is almost identical to the superblock, inode, group descriptor and other data structures used by ext2, so ext3 is forward compatible with ext2. Without backing up ext2 file system data, you can use:
1
# tune2fs –j/dev/sd1
Directly convert the ext2 file system to the ext3 file system without unmounting the partition.
Suppose that when we are editing a file, there is a sudden power outage, or the system is locked and forced to restart, what will be the consequences? At worst, part of the file content is lost, at worst, the entire file content is messed up, and even worse, the file system crashes directly. What a terrible thing this would be. When Linux shuts down normally, we will see a print message of uninstalling the file system. Abnormal shutdown will lead to inconsistencies in the file system. This inconsistency will be discovered when the file system is mounted during the system restart phase, and then it will try to repair it. it. Unfortunately, as the capacity of storage devices increases, the time required for such repairs becomes increasingly prohibitive.
The biggest feature of Ext3 is that it adds a log function based on ext2, so the ext3 file system is often called a log file system, but the log file system is not only ext3, but also JFS, reiserFS and XFS, and NTFS that we often see on Windows.
The logging feature of Ext3 mainly relies on an intermediate device named "Journaling Block Device Layer" underneath it, called JBD (Journaling Block Device layer, JBD for short). JBD is not part of the file system specification. It has nothing to do with the ext3 file system specification. JBD is the basis for the implementation of the file system transaction processing function. In short, JBD is designed to implement the special purpose of logging on any block device (the more abstract it becomes, what is a transaction? ⊙﹏⊙….)
Regarding transactions, students who have experience in database development or data operation and maintenance will definitely be familiar with it. We will not stick to concepts here, nor will we stick to academic definitions. As long as everyone knows that the main function of transactions is to ensure the atomicity of operations. How to understand this sentence? For example, in the financial system, X yuan needs to be transferred from account A to account B. This business must ensure that X yuan is successfully transferred from account A, and then X yuan is successfully added to account B. Only if these two operations succeed at the same time can the transfer be successful. If either operation fails, the business must be terminated. If the transfer of X yuan from account A is successful and an error occurs when writing to account B, then the X yuan transferred from account A must be returned to account A. A more extreme situation is that the data of account A collapses due to various reasons. Then the transaction mechanism of the database must ensure that the X yuan of account A will not be lost. This is the atomicity of database business operations. In the log file system, the atomicity of file data operations is guaranteed by JBD. Ext3 implements its logging function by "hooking in" JBD's API. Although the JBD layer itself does not have much code, it is a very complex software part. We will not talk about it here, and we will play with it when we have the opportunity.
The log file system must of course record logs, and logs also require storage space. Therefore, the log file system opens up a special area on the storage medium specifically for storing log information:
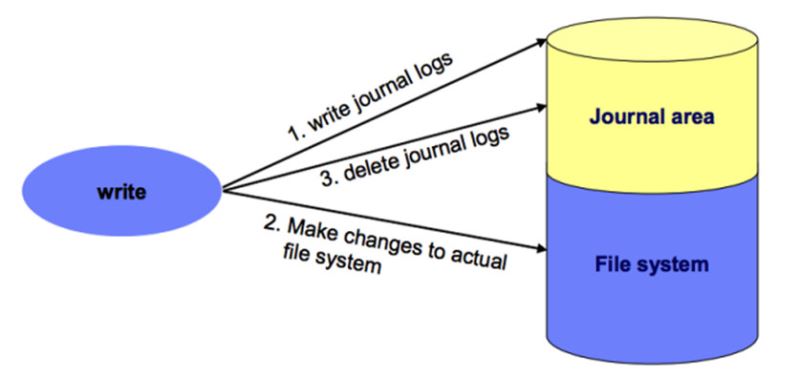
We use a picture to briefly describe the underlying layout of ext3:
The above is the detailed content of A deep dive into the journaling file system ext3 in CentOS. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



