


Large language models (LLMs) are deep neural networks with large amounts of parameters and data, capable of achieving a variety of tasks in the field of natural language processing (NLP), such as text understanding and generation. In recent years, with the improvement of computing power and data scale, LLMs have made remarkable progress, such as GPT-4, BART, T5, etc., demonstrating strong generalization capabilities and creativity.
LLMs also have serious problems. When generating text, it is easy to produce content that is inconsistent with real facts or user input, that is, hallucination. This phenomenon will not only reduce system performance, but also affect user expectations and trust, and even cause some security and ethical risks. Therefore, how to detect and alleviate hallucinations in LLMs has become an important and urgent topic in the current NLP field.
On January 1, SM Towhidul Islam, several scientists from the Islamic University of Science and Technology in Bangladesh, the Artificial Intelligence Institute of the University of South Carolina in the United States, Stanford University in the United States, and the Amazon Artificial Intelligence Department in the United States Tonmoy, SM Mehedi Zaman, Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha, Amitava Das published a paper titled "A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models", aiming to introduce and classify large language models (LLMs) ) Hallucination Mitigation Techniques.

They first introduced the definition, causes and effects of hallucinations, and how to evaluate them. They then propose a detailed classification system that divides hallucination mitigation techniques into four major categories: dataset-based, task-based, feedback-based, and retrieval-based. Within each category, they further subdivide different subcategories and illustrate some representative methods.
The authors also analyze the advantages and disadvantages, challenges and limitations of these technologies, as well as future research directions. They pointed out that the current technology still has some problems, such as lack of generality, interpretability, scalability, and robustness. They suggested that future research should focus on the following aspects: developing more effective hallucination detection and quantification methods, leveraging multi-modal information and common sense knowledge, designing more flexible and customizable hallucination mitigation frameworks, and considering human participation and feedback .
In order to better understand and describe the hallucination problem in LLMs, they proposed a hallucination-based The classification system of sources, types, extents and impacts is shown in Figure 1. They believe that this system can cover all aspects of hallucinations in LLMs, help analyze the causes and characteristics of hallucinations, and assess the severity and harm of hallucinations.
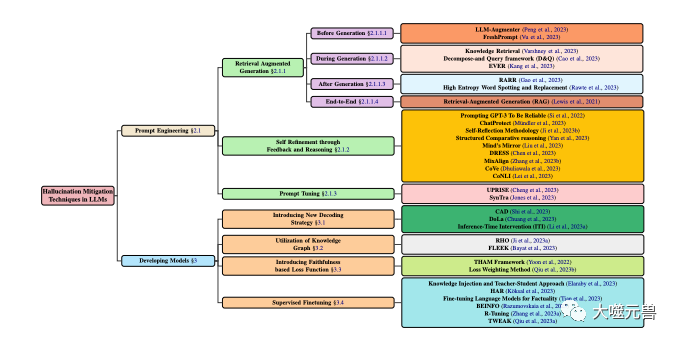 Figure 1
Figure 1
Classification of hallucination mitigation techniques in LLM, focusing on popular methods involving model development and prompting techniques. Model development is divided into various methods, including new decoding strategies, knowledge graph-based optimization, adding new loss function components, and supervised fine-tuning. Meanwhile, cue engineering can include retrieval enhancement-based methods, feedback-based strategies, or cue adjustments.
The source of hallucination is the root cause of hallucinations in LLMs, which can be summarized into the following three categories:
Parametric Knowledge: Implicit knowledge learned by LLMs from large-scale unlabeled text in the pre-training stage, such as grammar, semantics, common sense, etc. This knowledge is usually stored in the parameters of LLMs and can be invoked through activation functions and attention mechanisms. Parametric knowledge is the basis of LLMs, but it can also be a source of illusions because it may contain some inaccurate, outdated or biased information, or conflict with user-entered information.
Non-parametric Knowledge: Explicit knowledge that LLMs obtain from external annotated data during the fine-tuning or generation phase, such as facts, evidence, references, etc. This knowledge usually exists in structured or unstructured form and can be accessed through retrieval or memory mechanisms. Non-parametric knowledge is complementary to LLMs, but can also be a source of illusions, as it may contain some noise, erroneous or incomplete data, or be inconsistent with the parametric knowledge of LLMs.
Generation Strategy: refers to some technologies or methods used by LLMs when generating text, such as decoding algorithms, control codes, prompts, etc. These strategies are tools for LLMs, but they can also be a source of illusions, as they may cause LLMs to over-rely on or ignore certain knowledge, or introduce some bias or noise into the generation process.
Types of hallucinations refer to the specific manifestations of hallucinations generated by LLMs, which can be divided into the following four categories:
Grammatical Hallucination: refers to the text generated by LLMs that contains grammatical errors or irregularities, such as spelling errors, punctuation errors, word order errors, tense errors, subject-verb inconsistency, etc. This illusion is usually caused by LLMs' incomplete grasp of language rules or overfitting to noisy data.
Semantic Hallucination (Semantic Hallucination): refers to the semantic errors or unreasonableness in the text generated by LLMs, such as word meaning errors, reference errors, logical errors, ambiguities, contradictions, etc. This illusion is often caused by LLMs' inadequate understanding of the meaning of language or insufficient processing of complex data.
Knowledge Hallucination (Knowledge Hallucination): refers to the text generated by LLMs that contains errors or inconsistencies in knowledge, such as factual errors, evidence errors, citation errors, mismatch with input or context, etc. This illusion is usually caused by LLMs' incorrect acquisition or inappropriate use of knowledge.
Creative Hallucination (Creative Hallucination): refers to the text generated by LLMs that has creative errors or inappropriateness, such as style errors, emotional errors, wrong viewpoints, incompatibility with tasks or goals, etc. . This illusion is often caused by LLMs' unreasonable control over creation or inadequate evaluation.
The degree of hallucination refers to the quantity and quality of hallucinations generated by LLMs, which can be divided into the following three categories:
Mild Hallucination: The hallucination is less and lighter and does not affect the overall readability and understandability of the text, nor does it damage the main message and purpose of the text. For example, LLMs generate some minor grammatical errors, or some semantic ambiguities, or some detailed knowledge errors, or some creative subtle differences.
Moderate Hallucination: There are many and heavy hallucinations, which affects part of the readability and understandability of the text, and also damages the secondary information and purpose of the text. Usually LLMs generate some big grammatical errors, or some semantic irrationality.
Severe Hallucination (Severe Hallucination): The hallucinations are very numerous and very heavy, affecting the overall readability and understandability of the text, and also destroying the main message and purpose of the text.
The impact of hallucination refers to the potential consequences of LLMs generating hallucinations on users and systems, which can be divided into the following three categories:
Harmless Hallucination: It does not have any negative impact on users and the system, and may even have some positive impacts, such as increasing fun, creativity, diversity, etc. For example, LLMs generate some content that is not related to the task or goal, or some content that is consistent with the user's preferences or expectations, or some content that is consistent with the user's mood or attitude, or some content that is helpful for the user's communication or interaction. content.
Harmful Hallucination: It has some negative impacts on users and the system, such as reducing efficiency, accuracy, credibility, satisfaction, etc. For example, LLMs generate some content that is inconsistent with the tasks or goals, or some content that is inconsistent with the user's preferences or expectations, or some content that is inconsistent with the user's mood or attitude, or some content that hinders the user's communication or interaction. Content.
Hazardous Hallucination: It has a serious negative impact on users and the system, such as causing misunderstandings, conflicts, disputes, injuries, etc. For example, LLMs generate some content that is contrary to facts or evidence, or some content that conflicts with morality or law, or some content that conflicts with human rights or dignity, or some content that threatens safety or health.
In order to better solve the problem of hallucinations in LLMs, we need to conduct an in-depth analysis of the causes of hallucinations . According to the sources of hallucinations mentioned above, the author divides the causes of hallucinations into the following three categories:
Insufficient or excess parameter knowledge: In the pre-training stage, LLMs usually use a large amount of unlabeled text to learn language rules and knowledge, thereby forming parameter knowledge. However, this kind of knowledge may have some problems, such as incomplete, inaccurate, not updated, inconsistent, irrelevant, etc., resulting in the inability of LLMs to fully understand and utilize the input information when generating text, or the inability to correctly distinguish and select the output information. , thereby producing hallucinations. On the other hand, parameter knowledge may also be too rich or powerful, causing LLMs to overly rely on or prefer their own knowledge when generating text, while ignoring or conflicting with the input information, thus creating hallucinations.
Lack or error of non-parametric knowledge: In the fine-tuning or generation phase, LLMs usually use some external annotated data to obtain or supplement language knowledge, thereby forming non-parametric knowledge. This kind of knowledge may have some problems, such as scarcity, noise, errors, incompleteness, inconsistency, irrelevance, etc., resulting in the inability of LLMs to effectively retrieve and fuse input information when generating text, or to accurately verify and correct the output. information, thereby producing hallucinations. Non-parametric knowledge may also be too complex or diverse, making it difficult for LLMs to balance and coordinate different information sources when generating text, or to adapt and meet different task requirements, thus creating illusions.
Inappropriate or insufficient generation strategy: When LLMs generate text, they usually use some technologies or methods to control or optimize the generation process and results, thereby forming a generation strategy. These strategies may have some problems, such as inappropriate, insufficient, unstable, unexplainable, untrustworthy, etc., resulting in the inability of LLMs to effectively regulate and guide the direction and quality of generation when generating text, or the inability to discover and correct it in a timely manner. generated errors, thus creating hallucinations. The generation strategy may also be too complex or changeable, making it difficult for LLMs to maintain and ensure the consistency and reliability of generation when generating text, or it is difficult to evaluate and give feedback on the effects of generation, thus creating hallucinations.
In order to better solve the problem of hallucinations in LLMs, we need to effectively detect and evaluating the hallucinations generated by LLMs. According to the types of hallucinations mentioned above, the author divides the detection methods of hallucinations into the following four categories:
Detection methods of grammatical hallucinations: Use some grammar checking tools or rules to identify and correct them Grammatical errors or irregularities in text generated by LLMs. For example, some tools or rules such as spelling check, punctuation check, word order check, tense check, subject-verb agreement check, etc. can be used to detect and correct grammatical illusions in texts generated by LLMs.
Detection method of semantic illusion: Use some semantic analysis tools or models to understand and evaluate semantic errors or unreasonableness in the text generated by LLMs. For example, some tools or models such as word meaning analysis, reference resolution, logical reasoning, ambiguity elimination, and contradiction detection can be used to detect and correct semantic illusions in texts generated by LLMs.
Detection method of knowledge illusion: Use some knowledge retrieval or verification tools or models to obtain and compare knowledge errors or inconsistencies in texts generated by LLMs. For example, some tools or models such as knowledge graphs, search engines, fact checking, evidence checking, citation checking, etc. can be used to detect and correct knowledge illusions in texts generated by LLMs.
Detection method of creation illusion: Use some creation evaluation or feedback tools or models to detect and evaluate creation errors or inappropriateness in the text generated by LLMs. For example, some tools or models such as style analysis, sentiment analysis, creation evaluation, opinion analysis, goal analysis, etc. can be used to detect and correct creation illusions in texts generated by LLMs.
According to the degree and impact of the hallucinations mentioned above, we can divide the evaluation criteria of hallucinations into the following four categories:
Grammatical correctness (Grammational Correctness): Refers to whether the text generated by LLMs conforms to the rules and habits of the language grammatically, such as spelling, punctuation, word order, tense, subject-verb agreement, etc. This standard can be evaluated through some automatic or manual grammar checking tools or methods, such as BLEU, ROUGE, BERTScore, etc.
Semantic Reasonableness: Refers to whether the text generated by LLMs semantically conforms to the meaning and logic of the language, such as word meaning, reference, logic, ambiguity, contradiction, etc. This standard can be evaluated through some automatic or manual semantic analysis tools or methods, such as METEOR, MoverScore, BERTScore, etc.
Knowledge Consistency: Refers to whether the text generated by LLMs is intellectually consistent with real facts or evidence, or whether it is consistent with input or contextual information, such as facts, evidence, references, matching, etc. This standard can be evaluated through some automatic or manual knowledge retrieval or verification tools or methods, such as FEVER, FactCC, BARTScore, etc.
Creative Appropriateness: Refers to whether the text generated by LLMs creatively meets the requirements of the task or goal, or is consistent with the user's preferences or expectations, or is consistent with the user's Whether the mood or attitude is harmonious, or whether the communication or interaction with the user is helpful, such as style, emotion, opinion, goal, etc. This standard can be evaluated through some automatic or manual creation assessment or feedback tools or methods, such as BLEURT, BARTScore, SARI, etc.
In order to better solve the problem of hallucinations in LLMs, we need to effectively alleviate and reduce LLMs Generated hallucinations. According to different levels and angles, the author divides hallucination relief methods into the following categories:
Post-generation refinement is to perform some checks and corrections on the text after LLMs generate it to eliminate or reduce illusions. The advantage of this type of method is that it does not require retraining or adjustment of LLMs and can be directly applied to any LLMs. The disadvantages of this type of approach are that the illusion may not be completely eliminated, or new illusions may be introduced, or some of the information or creativity of the original text may be lost. Representatives of this type of method are:
RARR (Refinement with Attribution and Retrieved References): (Chrysostomou and Aletras, 2021) proposed a refinement method based on attribution and retrieval, Used to improve the fidelity of text generated by LLMs. An attribution model is used to identify whether each word in the text generated by LLMs comes from the input information, the parameter knowledge of the LLMs, or the generation strategy of the LLMs. Use a retrieval model to retrieve some reference texts related to the input information from external knowledge sources. Finally, a refinement model is used to modify the text generated by LLMs based on the attribution results and retrieval results to improve its consistency and credibility with the input information.
High Entropy Word Spotting and Replacement (HEWSR): (Zhang et al., 2021) proposed an entropy-based thinning method for reducing hallucinations in texts generated by LLMs. First, an entropy calculation model is used to identify high-entropy words in texts generated by LLMs, that is, those words with higher uncertainty when generated. Then a replacement model is used to select a more appropriate word from the input information or external knowledge source to replace the high-entropy word. Finally, a smoothing model is used to make some adjustments to the replaced text to maintain its grammatical and semantic coherence.
ChatProtect (Chat Protection with Self-Contradiction Detection): (Wang et al., 2021) proposed a refinement method based on self-contradiction detection to improve chat conversations generated by LLMs security. First, a contradiction detection model is used to identify self-contradictions in the dialogue generated by LLMs, that is, those contents that conflict with the previous dialogue content. A replacement model is then used to replace the self-contradictory reply with a more appropriate one from some predefined safe replies. Finally, an evaluation model is used to give some scores to the replaced dialogue to measure its safety and fluency.
Self-improvement with Feedback and Reasoning is generated in LLMs In the process, some evaluation and adjustments are made to the text to eliminate or reduce the illusion. The advantage of this type of method is that it can monitor and correct hallucinations in real time, and can improve the self-learning and self-regulation capabilities of LLMs. The disadvantage of this type of approach is that it may require some additional training or adjustment of the LLMs, or it may require some external information or resources. Representatives of this type of method are:
Self-Reflection Methodology (SRM): (Iyer et al., 2021) proposed a perfect method based on self-feedback to improve the performance of LLMs generated Reliability of medical questions and answers. The method first uses a generative model to generate an initial answer based on the input question and context. A feedback model is then used to generate a feedback question based on the input question and context, which is used to detect potential hallucinations in the initial answer. Then use an answer model to generate an answer based on the feedback question to verify the correctness of the initial answer. Finally, a correction model is used to correct the initial answer based on the answer results to improve its reliability and accuracy.
Structured Comparative (SC) reasoning: (Yan et al., 2021) proposed a reasoning method based on structured comparison to improve the consistency of text preference predictions generated by LLMs. This method uses a generative model to generate a structured comparison based on the input text pairs, that is, comparing and evaluating the text pairs in different aspects. Use an inference model to generate a prediction of text preference based on structured comparisons, that is, which text pair is preferred. Use an evaluation model to evaluate the generated comparisons against the predicted results to improve their consistency and credibility.
Think While Effectively Articulating Knowledge (TWEAK): (Qiu et al., 2021a) proposes a reasoning method based on hypothesis verification to improve the fidelity of knowledge generated by LLMs to text . This method uses a generative model to generate an initial text based on input knowledge. Then use a hypothesis model to generate some hypotheses based on the initial text, that is, predict the future text of the text under different aspects. Then use a verification model to verify the correctness of each hypothesis based on the input knowledge. Finally, an adjustment model is used to adjust the initial text based on the verification results to improve its consistency and credibility with the input knowledge.
The new decoding strategy is to determine the probability of the text in the process of LLMs generating text. The distribution undergoes some changes or optimizations to eliminate or reduce the illusion. The advantage of this type of method is that it can directly affect the generated results and can improve the flexibility and efficiency of LLMs. The disadvantage of this type of approach is that it may require some additional training or adjustment of the LLMs, or it may require some external information or resources. Representatives of this type of method are:
Context-Aware Decoding (CAD): (Shi et al., 2021) proposed a contrast-based decoding strategy for reducing text generated by LLMs knowledge conflicts. This strategy uses a contrastive model to calculate the difference in the probability distribution of the output of LLMs when using and not using input information. Then an amplification model is used to amplify this difference, so that the probability of output that is consistent with the input information is higher, and the probability of output that conflicts with the input information is lower. Finally, a generative model is used to generate text based on the amplified probability distribution to improve its consistency and credibility with the input information.
Decoding by Contrasting Layers (DoLa): (Chuang et al., 2021) proposed a layer contrast-based decoding strategy for reducing knowledge illusions in texts generated by LLMs. First, a layer selection model is used to select certain layers in LLMs as knowledge layers, that is, those layers that contain more factual knowledge. A layer contrast model is then used to calculate the logarithmic difference between the knowledge layer and other layers in the vocabulary space. Finally, a generative model is used to generate text based on the probability distribution after layer comparison to improve its consistency and credibility with factual knowledge.
The utilization of knowledge graph is to use some structures in the process of LLMs generating text. The knowledge graph is used to provide or supplement some knowledge related to the input information to eliminate or reduce illusions. The advantage of this type of method is that it can effectively acquire and integrate external knowledge, and can improve the knowledge coverage and knowledge consistency of LLMs. The disadvantage of this type of approach is that some additional training or tuning of LLMs may be required, or some high-quality knowledge graphs may be required. Representatives of this type of method are:
RHO (Representation of linked entities and relation predicates from a Knowledge Graph): (Ji et al., 2021a) proposed a representation method based on knowledge graph , used to improve the fidelity of dialogue responses generated by LLMs. First, a knowledge retrieval model is used to retrieve some subgraphs related to the input dialogue from a knowledge graph, that is, a graph containing some entities and relationships. Then a knowledge encoding model is used to encode entities and relationships in the subgraph to obtain their vector representations. Then a knowledge fusion model is used to fuse the vector representation of knowledge into the vector representation of dialogue to obtain an enhanced dialogue representation. Finally, a knowledge generation model is used to generate a faithful dialogue reply based on the enhanced dialogue representation.
FLEEK (FactuaL Error detection and correction with Evidence Retrieved from external Knowledge): (Bayat et al., 2021) proposed a verification and correction method based on knowledge graphs to improve the factuality of text generated by LLMs . The method first uses a fact recognition model to identify potentially verifiable facts in the text generated by LLMs, that is, those facts for which evidence can be found in the knowledge graph. A question generation model is then used to generate a question for each fact for querying the knowledge graph. Then use a knowledge retrieval model to retrieve some evidence related to the problem from the knowledge graph. Finally, a fact verification and correction model is used to verify and correct the facts in the text generated by LLMs based on evidence to improve its factuality and accuracy.
Faithfulness-based loss function is trained or fine-tuned on LLMs In the process, some metrics that measure the consistency between the generated text and the input information or real labels are used as part of the loss function to eliminate or reduce the illusion. The advantage of this type of method is that it can directly affect the parameter optimization of LLMs and improve the fidelity and accuracy of LLMs. The disadvantage of this type of approach is that some additional training or tuning of LLMs may be required, or some high-quality annotated data may be required. Representatives of this type of method are:
Text Hallucination Mitigating (THAM) Framework: (Yoon et al., 2022) proposed a loss function based on information theory to reduce videos generated by LLMs Illusions in conversation. First, a dialogue language model is used to calculate the probability distribution of the dialogue. An hallucination language model is then used to calculate the probability distribution of hallucinations, that is, the probability distribution of information that cannot be obtained from the input video. Then a mutual information model is used to calculate the mutual information between the dialogue and the illusion, that is, the mutual information about the degree of illusion contained in the dialogue. Finally, a cross-entropy model is used to calculate the cross-entropy of the dialogue and the real label, that is, the accuracy of the dialogue. The goal of this loss function is to minimize the sum of mutual information and cross-entropy, thereby reducing illusions and errors in dialogue.
Factual Error Correction with Evidence Retrieved from external Knowledge (FECK): (Ji et al., 2021b) proposed a loss function based on knowledge evidence to improve the accuracy of text generated by LLMs Factuality. First, a knowledge retrieval model is used to retrieve some subgraphs related to the input text from a knowledge graph, that is, a graph containing some entities and relationships. Then a knowledge encoding model is used to encode entities and relationships in the subgraph to obtain their vector representations. Then a knowledge alignment model is used to align the entities and relationships in the text generated by LLMs with the entities and relationships in the knowledge graph to obtain their matching degree. Finally, the loss function uses a knowledge loss model to calculate the distance between the entities and relationships in the text generated by LLMs and the entities and relationships in the knowledge graph, that is, the deviation from the fact. The goal of this loss function is to minimize the knowledge loss, thereby improving the factuality and accuracy of the text generated by LLMs.
Prompt fine-tuning is to use some specific text or symbols in the process of LLMs generating text, as part of the input to control or guide the generative behavior of LLMs to eliminate or reduce hallucinations. The advantage of this type of method is that it can effectively adjust and guide the parameter knowledge of LLMs, and can improve the adaptability and flexibility of LLMs. The disadvantage of this type of approach is that it may require some additional training or tuning of the LLMs, or it may require some high-quality prompts. Representatives of this type of method are:
UPRISE (Universal Prompt-based Refinement for Improving Semantic Equivalence): (Chen et al., 2021) proposed a fine-tuning method based on universal prompts, using To improve the semantic equivalence of texts generated by LLMs. First, a prompt generation model is used to generate a general prompt based on the input text, that is, some text or symbols used to guide LLMs to generate semantically equivalent text. Then a hint fine-tuning model is used to fine-tune the parameters of LLMs based on the input text and hints, making it more inclined to generate text that is semantically equivalent to the input text. Finally, the method uses a hint generation model to generate a semantically equivalent text based on the parameters of fine-tuned LLMs.
SynTra (Synthetic Task for Hallucination Mitigation in Abstractive Summarization): (Wang et al., 2021) proposed a synthetic task-based fine-tuning method for reducing hallucinations in summaries generated by LLMs. First, a synthetic task generation model is used to generate a synthetic task based on the input text, that is, a problem for detecting hallucinations in summaries. A synthetic task fine-tuning model is then used to fine-tune the parameters of the LLMs based on the input text and task, making it more inclined to generate summaries that are consistent with the input text. Finally, a synthetic task generation model is used to generate a consistent summary based on the parameters of the fine-tuned LLMs.
Although some progress has been made in hallucination relief technology in LLMs, there are still some Challenges and limitations require further research and exploration. The following are some of the main challenges and limitations:
Definition and measurement of hallucinations: Without a unified and clear definition and measurement, different studies may use different standards and indicators to Judging and evaluating illusions in text generated by LLMs. This leads to some inconsistent and incomparable results, and also affects the understanding and resolution of hallucination problems in LLMs. Therefore, there is a need to establish a common and reliable definition and measurement of hallucinations to facilitate effective detection and assessment of hallucinations in LLMs.
Data and resources for hallucinations: There is a lack of some high-quality and large-scale data and resources to support the research and development of hallucinations in LLMs. For example, there is a lack of some data sets containing hallucination annotations to train and test hallucination detection and mitigation methods in LLMs; there is a lack of some knowledge sources containing real facts and evidence to provide and verify the knowledge in texts generated by LLMs; there is a lack of some data sets containing hallucinations. A platform for user feedback and reviews to collect and analyze the impact of hallucinations in text generated by LLMs. Therefore, some high-quality and large-scale data and resources need to be constructed to facilitate effective research and development on hallucinations in LLMs.
Causes and mechanisms of hallucinations: There is no in-depth and comprehensive analysis of the causes and mechanisms to reveal and explain why LLMs produce hallucinations, and how hallucinations are formed and propagated in LLMs of. For example, it is unclear how parametric knowledge, non-parametric knowledge, and generative strategies in LLMs influence and interact with each other, and how they lead to illusions of different types, degrees, and effects. Therefore, some in-depth and comprehensive analysis of the causes and mechanisms are needed to facilitate effective prevention and control of hallucinations in LLMs.
Solution and optimization of hallucinations: There is no perfect and universal solution and optimization solution to eliminate or reduce hallucinations in texts generated by LLMs, and to improve the quality of texts generated by LLMs and effect. For example, it is unclear how to improve the fidelity and accuracy of LLMs without losing their generalization ability and creativity. Therefore, some complete and universal solutions and optimization solutions need to be designed to improve the quality and effect of text generated by LLMs.
The above is the detailed content of A comprehensive study of hallucination mitigation techniques in large-scale machine learning. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



