Activation functions play a crucial role in deep learning. They can introduce nonlinear characteristics into neural networks, allowing the network to better learn and simulate complex input-output relationships. The correct selection and use of activation functions has an important impact on the performance and training effect of neural networks
This article will introduce four commonly used activation functions: Sigmoid, Tanh, ReLU and Softmax, from the introduction, usage scenarios, advantages, The shortcomings and optimization solutions are discussed in five dimensions to provide you with a comprehensive understanding of the activation function.

##1. Sigmoid function
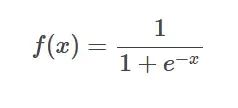 SIgmoid function formula
SIgmoid function formula
Introduction: Sigmoid function is a A commonly used nonlinear function that can map any real number to between 0 and 1.
It is often used to convert unnormalized predicted values into probability distributions.
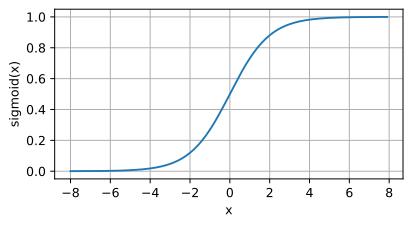 SIgmoid function image
SIgmoid function image
Application scenario:
The output is limited to between 0 and 1, indicating probability distributed. - Handle regression problems or binary classification problems.
-
The following are the advantages:
- Any range of input can be mapped to between 0-1, suitable for expressing probability.
- The range is limited, which makes calculations simpler and faster.
Disadvantages: When the input value is very large, the gradient may become very small, causing the gradient disappearance problem.
Optimization plan:
-
Use other activation functions such as ReLU: Combined Use other activation functions such as ReLU or its variants (Leaky ReLU and Parametric ReLU).
-
Use optimization techniques in deep learning frameworks: Use optimization techniques provided by deep learning frameworks such as TensorFlow or PyTorch , such as gradient clipping, learning rate adjustment, etc.
2. Tanh function
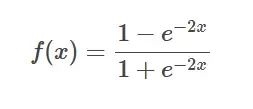 Tanh function formula
Tanh function formula
Introduction: T
anh function is Sigmoid Hyperbolic version of the function that maps any real number to between -1 and 1.
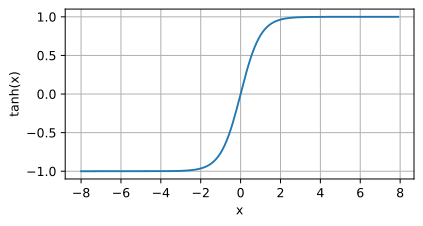 Tanh function image
Tanh function image
Application scenario: When a function steeper than Sigmoid is required, or in some cases where the range of -1 to 1 is required output in specific applications.
The following are the advantages: It provides a larger dynamic range and a steeper curve, which can speed up the convergence speed
The disadvantage of the Tanh function is that when the input is close to ±1, its derivative is rapid Close to 0, causing the problem of gradient disappearance
Optimization plan:
- ##Use other activation functions such as ReLU:Use in combination with other activation functions, such as ReLU or its variants (Leaky ReLU and Parametric ReLU).
- Use residual connection: Residual connection is an effective optimization strategy, such as ResNet (residual network).
3、
ReLU function
ReLU function formula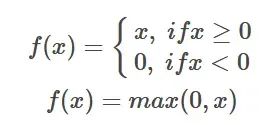 Introduction: The ReLU activation function is a simple nonlinear function, and its mathematical expression is f(x) = max(0,
Introduction: The ReLU activation function is a simple nonlinear function, and its mathematical expression is f(x) = max(0,
x). When the input value is greater than 0, the ReLU function outputs the value; when the input value is less than or equal to 0, the ReLU function outputs 0.
ReLU function image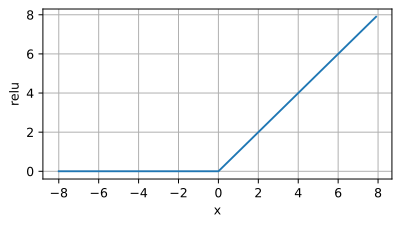 Application scenario: ReLU activation function is widely used in deep learning models, especially in convolutional neural networks (CNN) middle. Its main advantages are that it is simple to calculate, can effectively alleviate the vanishing gradient problem, and
Application scenario: ReLU activation function is widely used in deep learning models, especially in convolutional neural networks (CNN) middle. Its main advantages are that it is simple to calculate, can effectively alleviate the vanishing gradient problem, and
can accelerate model training. Therefore, ReLU is often used as the preferred activation function when training deep neural networks.
The following are the advantages:
-
Alleviating the vanishing gradient problem: Compared with activation functions such as Sigmoid and Tanh, ReLU is more efficient in the activation value When it is positive, it will not make the gradient smaller, thus avoiding the vanishing gradient problem.
-
Accelerated training: Due to ReLU’s simplicity and computational efficiency, it can significantly accelerate the model training process.
Disadvantages:
-
"Dead neuron" problem: When the input value is less than or When equal to 0, the output of ReLU is 0, causing the neuron to fail. This phenomenon is called "dead neuron".
-
Asymmetry: The output range of ReLU is [0, ∞), and when the input value is a negative number, the output is 0. This This results in an asymmetric distribution of ReLU outputs, limiting the diversity of generation.
Optimization plan:
-
Leaky ReLU: Leaky ReLU When the input is less than or equal to 0, the output has a smaller slope, avoiding the complete "dead neuron" problem.
-
Parametric ReLU (PReLU): Different from Leaky ReLU, the slope of PReLU is not fixed, but can be adjusted based on the data Learn to optimize.
4. Softmax function
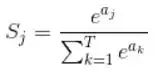 Softmax function formula
Softmax function formula
Introduction : Softmax is a commonly used activation function, mainly used in multi-classification problems, which can convert input neurons into probability distributions. Its main feature is that the output value range is between 0-1, and the sum of all output values is 1.
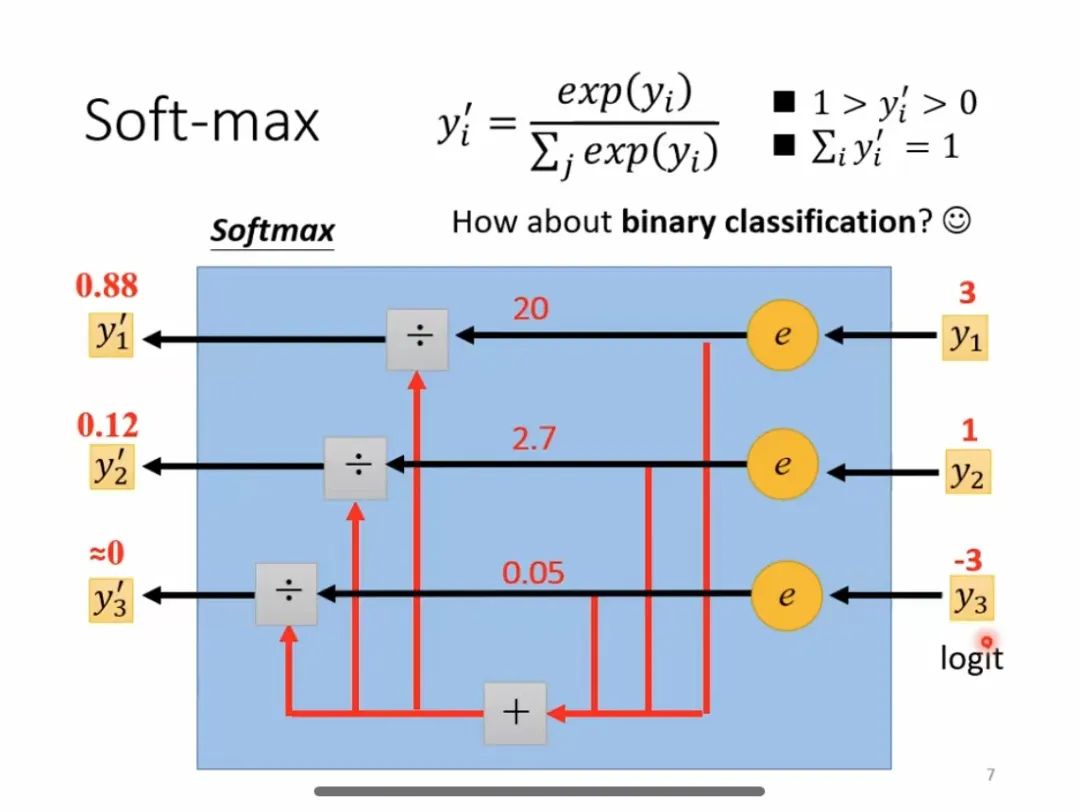 Softmax calculation process
Softmax calculation process
Application scenarios:
- In multi-classification tasks, used Convert the output of the neural network into a probability distribution.
- It is widely used in natural language processing, image classification, speech recognition and other fields.
The following are the advantages: In multi-classification problems, a relative probability value can be provided for each category to facilitate subsequent decision-making and classification.
Disadvantages: There will be gradient disappearance or gradient explosion problems.
Optimization scheme:
-
Use other activation functions such as ReLU: Use other activation functions in combination, such as ReLU or other Variants (Leaky ReLU and Parametric ReLU).
- Use optimization techniques in deep learning frameworks: Use optimization techniques provided by deep learning frameworks (such as TensorFlow or PyTorch), such as batch normalization, weight decay, etc.
The above is the detailed content of Analysis of commonly used AI activation functions: deep learning practice of Sigmoid, Tanh, ReLU and Softmax. For more information, please follow other related articles on the PHP Chinese website!
































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



