


The development of artificial intelligence has made rapid progress, but problems frequently arise. OpenAI's new GPT vision API is amazing for its front end, but it's also hard to complain about for its back end due to hallucination issues.
Illusion has always been the fatal flaw of large models. Due to the complexity of the data set, it is inevitable that there will be outdated and erroneous information, causing the output quality to face severe challenges. Too much repeated information can also bias large models, which is also a type of illusion. But hallucinations are not unanswerable propositions. During the development process, careful use of data sets, strict filtering, construction of high-quality data sets, and optimization of model structure and training methods can alleviate the hallucination problem to a certain extent.
There are so many popular large-scale models, how effective are they in alleviating hallucinations? Here is a ranking that clearly compares their differences
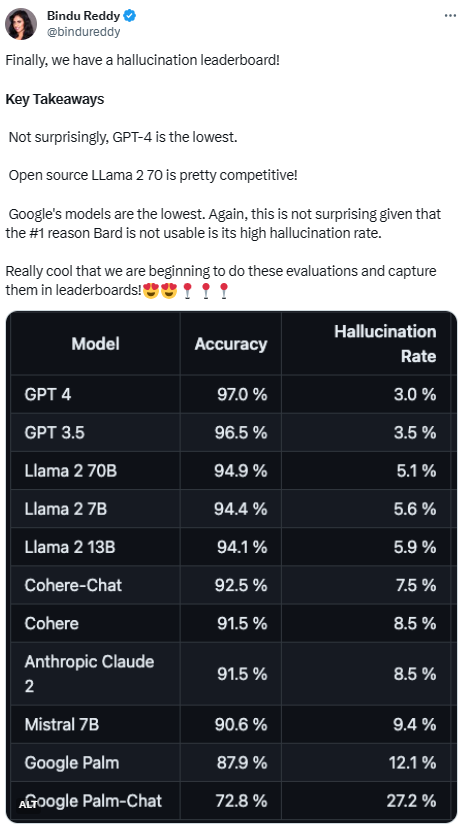
##The Vectara platform released this ranking, which focuses on artificial intelligence intelligent. The update date of the rankings is November 1, 2023. Vectara stated that they will continue to follow up on the hallucination evaluation in order to update the rankings as the model is updated
Project address: https ://github.com/vectara/hallucination-leaderboard
To determine this leaderboard, Vectara conducted a factual consistency study and trained a model to detect hallucinations in LLM output . They used a comparable SOTA model and provided each LLM with 1,000 short documents via a public API and asked them to summarize each document using only the facts presented in the document. Among these 1000 documents, only 831 documents were summarized by each model, and the remaining documents were rejected by at least one model due to content restrictions. Using these 831 documents, Vectara calculated the overall accuracy and illusion rate for each model. The rate at which each model refuses to respond to prompts is detailed in the "Answer Rate" column. None of the content sent to the model contains illegal or unsafe content, but contains enough trigger words to trigger certain content filters. These documents are mainly from the CNN/Daily Mail corpus
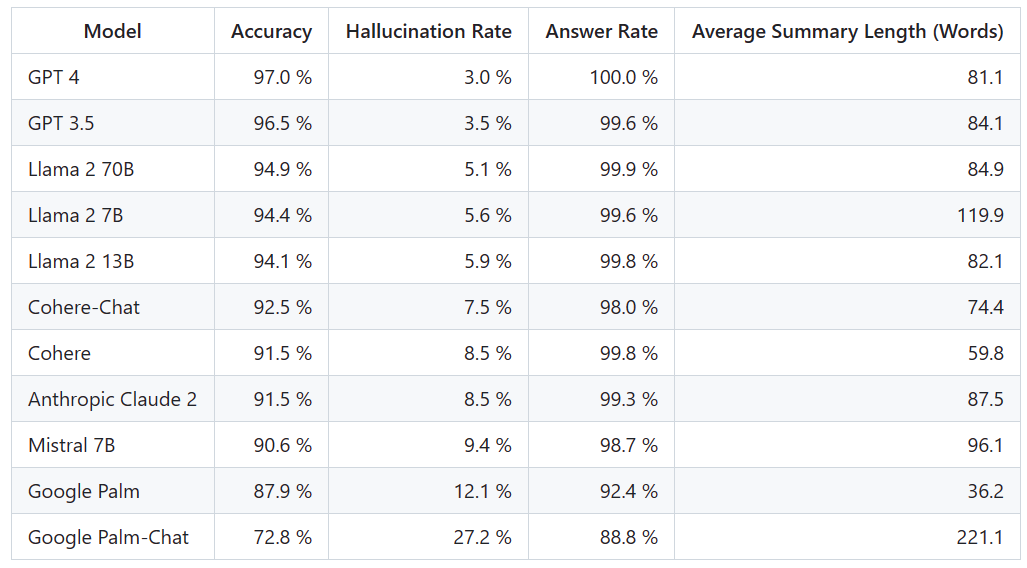
The detection address of the hallucination model is: https://huggingface.co/vectara/hallucination_evaluation_model
In addition, more and more LLM Used in RAG (Retrieval Augmented Generation) pipelines to answer user queries, such as Bing Chat and Google Chat integration. In the RAG system, the model is deployed as an aggregator of search results, so this ranking is also a good indicator of the accuracy of the model when used in the RAG system
Given that GPT-4 has been It seems unsurprising that it has the lowest rate of hallucinations, given its stellar performance. However, some netizens expressed that they were surprised that there was not a big gap between GPT-3.5 and GPT-4


OpenAI launched GPT-4 Turbo. No, some netizens immediately suggested updating it in the rankings.

#We will wait and see what the next ranking will look like and whether there will be major changes.
The above is the detailed content of Large model hallucination rate ranking: GPT-4 is the lowest at 3%, and Google Palm is as high as 27.2%. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



