


Recently, large language models have made significant breakthroughs in various natural language processing tasks, especially in mathematical problems that require complex chain of thought (CoT) reasoning
For example, in the data sets of difficult mathematical tasks such as GSM8K and MATH, proprietary models including GPT-4 and PaLM-2 have achieved remarkable results. In this regard, open source large models still have considerable room for improvement. To further improve the CoT inference capabilities of open source large models for mathematical tasks, a common approach is to fine-tune these models using annotated/generated question-inference data pairs (CoT data) that directly teach the model how to perform tasks on these Perform CoT inference during the task.
Recently, researchers from Xi'an Jiaotong University, Microsoft and Peking University explored an improvement idea in a paper, that is, through the reverse learning process (i.e., learning from the mistakes of LLM ) to further improve his reasoning ability
Just like a student who starts learning mathematics, he will first improve his understanding by studying the knowledge points and examples in the textbook. But at the same time, he also does exercises to consolidate what he has learned. When he encounters difficulties or fails in solving a problem, he will realize what mistakes he has made and learn how to correct them, thus forming a "wrong problem book". It is by learning from mistakes that his reasoning ability is further improved
Inspired by this process, this work explores how LLM's reasoning ability can be improved from understanding and correcting errors benefit from.

Paper address: https://arxiv.org/pdf/2310.20689.pdf
Specific Specifically, the researchers first generated error-correction data pairs (called correction data) and then used the correction data to fine-tune the LLM. When generating correction data: what needed to be rewritten, they used multiple LLMs (including LLaMA and the GPT family of models) to collect inaccurate inference paths (i.e., the final answer was incorrect), and subsequently used GPT-4 as " Corrector", which generates corrections for these inaccurate reasoning paths
The generated correction contains three pieces of information: (1) the incorrect step in the original solution; (2) an explanation that the step was incorrect Correct reasons; (3) How to revise the original solution to arrive at the correct final answer. After filtering out corrections with incorrect final answers, manual evaluation showed that the correction data showed sufficient quality for the subsequent fine-tuning phase. The researchers used QLoRA to fine-tune the LLM on the CoT data and correction data, thereby performing "Learning from Errors" (LEMA).
Research shows that the current LLM can use a step-by-step approach to solve problems, but this multi-step generation process does not mean that the LLM itself has strong reasoning capabilities. This is because they may only imitate the surface behavior of human reasoning without truly understanding the underlying logic and rules required
This lack of understanding can lead to errors in the reasoning process, so The help of a "world model" is needed, because the "world model" has a priori awareness of the logic and rules of the real world. From this perspective, the LEMA framework in this article can be seen as using GPT-4 as a "world model" to teach smaller models to follow these logics and rules, rather than just imitating step-by-step behavior.
Now, let’s take a look at the specific implementation steps of this study
Please look at Figure 1 (left) below, which shows the overall process of LEMA, including the two main stages of generating correction data: content that needs to be rewritten and fine-tuning LLM. Figure 1 (right) shows the performance of LEMA on GSM8K and MATH data sets
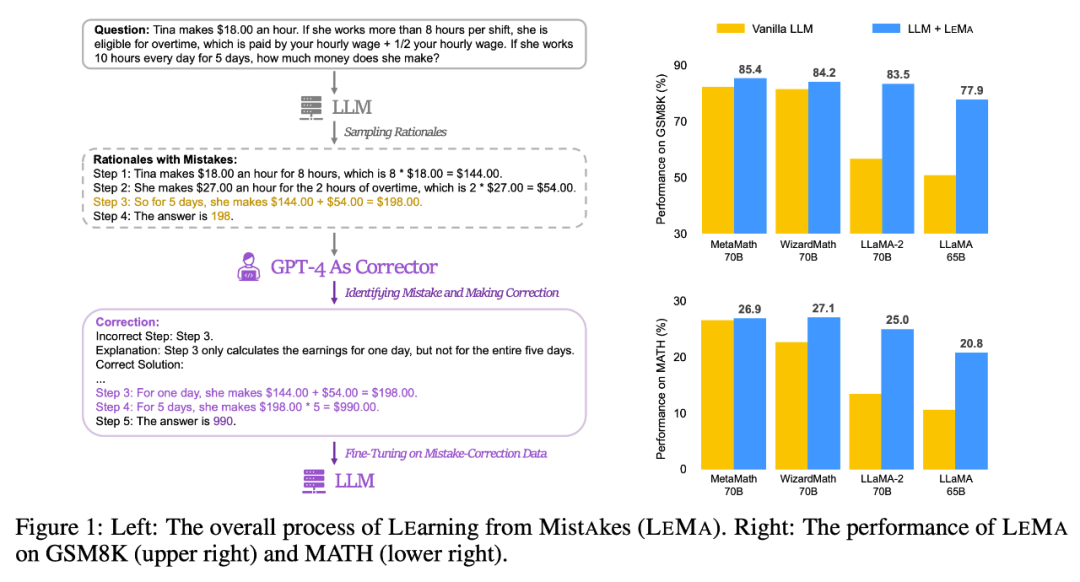
Generate corrected data: re-processing is required. What is written
Given a question and answer example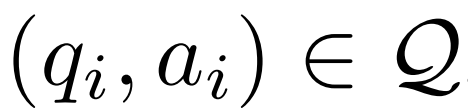 , a corrector model M_c and an inference model M_r, the researcher generated error correction data pairs
, a corrector model M_c and an inference model M_r, the researcher generated error correction data pairs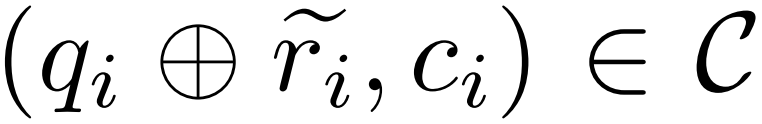 , Among them,
, Among them,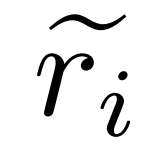 represents the inaccurate reasoning path of question q_i, and c_i represents the correction to
represents the inaccurate reasoning path of question q_i, and c_i represents the correction to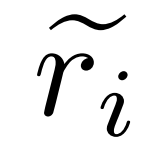 .
.
Correction of inaccurate reasoning path. The researcher first uses the inference model M_r to sample multiple inference paths for each question q_i, and then only retains those paths that ultimately do not lead to the correct answer a_i, as shown in the following formula (1).
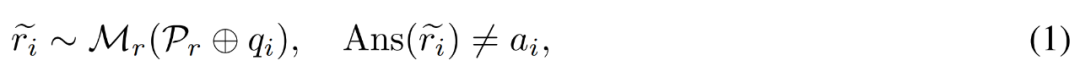
Generate fixfor errors. For question q_i and inaccurate reasoning path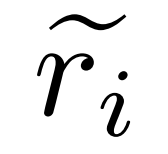 , the researcher uses the corrector model M_c to generate a correction, and then checks the correct answer in the correction, as shown in equation (2) below.
, the researcher uses the corrector model M_c to generate a correction, and then checks the correct answer in the correction, as shown in equation (2) below.
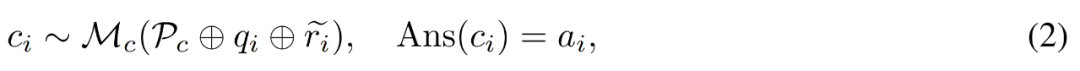
P_c here includes four annotated error correction examples to guide the corrector model on which types to include in the generated corrections The information
Specifically, the annotated correction includes the following three categories of information:
Please take a look at the picture below. Figure 1 briefly shows the prompts used to generate the correction

Generate corrected human evaluation. Before generating larger data, we first manually evaluated the quality of the generated corrections. They used LLaMA-2-70B as M_r and GPT-4 as M_c, and generated 50 error-corrected data pairs based on the GSM8K training set.
The researchers classified revisions into three quality levels: excellent, good and bad. Below is an example of three levels



##The evaluation results found that, Of the 50 build fixes, 35 were of excellent quality, 11 were good, and 4 were poor. Based on this evaluation, the researchers concluded that the overall quality of the corrections generated using GPT-4 was sufficient for further fine-tuning stages. Therefore, they generated more large-scale corrections and used all the corrections that ultimately led to the correct answer to the LLM that required fine-tuning.
It is LLM that needs fine-tuning
After generating correction data: what needed to be rewritten, the researchers fine-tuned the LLM to evaluate whether the models could learn from their mistakes. They mainly perform performance comparisons under the following two fine-tuning settings.
The first is to fine-tuneon theChain of Thought (CoT) data. Researchers fine-tune the model only on question-rationale data. Although there is annotated data in each task, they additionally employ CoT data augmentation. The researchers used GPT-4 to generate more reasoning paths for each question in the training set and filter out paths with incorrect final answers. They leverage CoT data augmentation to build a robust fine-tuning baseline that uses only CoT data and facilitates ablation studies on the data size that controls fine-tuning.
The second is tofine-tunethe CoT data correction data. In addition to CoT data, the researchers also generated error correction data for fine-tuning (i.e., LEMA). They also conducted ablation experiments with controlled data size to reduce the impact of increments on data size.
Example 5 and Example 6 in Appendix A show the input-output formats of CoT data and correction data for fine-tuning respectively

The researchers demonstrated the effectiveness of LEMA on five open source LLMs and two challenging mathematical reasoning tasks through experimental results
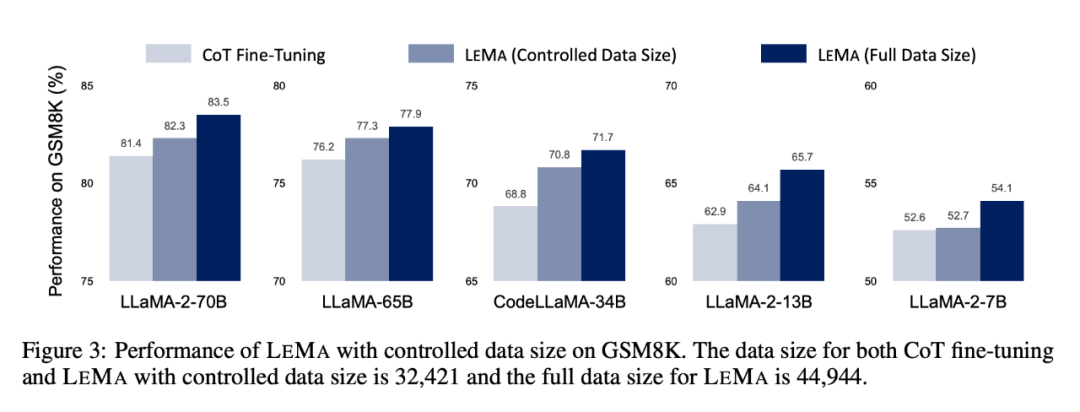
LEMA consistently improves performance across a variety of LLMs and tasks, compared to just fine-tuning on CoT data. For example, LEMA using LLaMA-2-70B achieved 83.5% and 25.0% on GSM8K and MATH respectively, while fine-tuning only on CoT data achieved 81.4% and 23.6% respectively
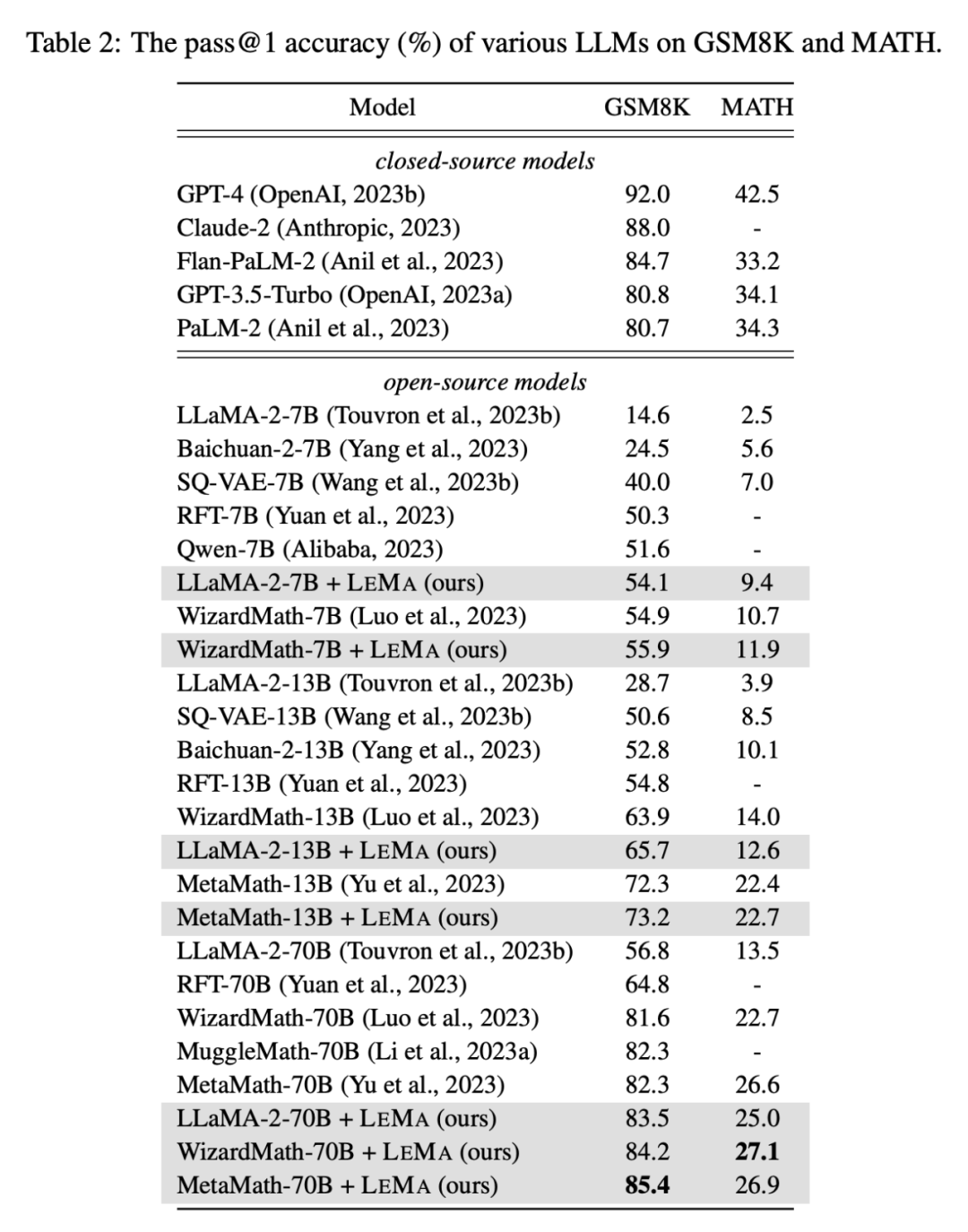
Additionally, LEMA is compatible with proprietary LLM: LEMA with WizardMath-70B/MetaMath-70B achieves 84.2%/85.4% pass@1 on GSM8K Accuracy, achieving a pass@1 accuracy of 27.1%/26.9% on MATH, exceeding the SOTA performance achieved by many open source models on these challenging tasks.
Subsequent ablation studies show that LEMA still outperforms CoT-alone fine-tuning with the same amount of data. This suggests that CoT data and corrected data are not equally effective, as combining both data sources yields more improvement than using a single data source. These experimental results and analyzes highlight the potential of learning from errors to enhance LLM inference capabilities.
For more research details, please see the original paper
The above is the detailed content of GPT-4 makes a 'world model', allowing LLM to learn from 'wrong questions' and significantly improve its reasoning ability. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



