


The purpose of continuous learning is to imitate the human ability to continuously accumulate knowledge in continuous tasks. Its main challenge is how to maintain the performance of previously learned tasks after continuing to learn new tasks, that is, to avoidcatastrophic Forget(catastrophic forgetting). The difference between continuous learning and multi-task learning is that the latter can get all tasks at the same time, and the model can learn all tasks at the same time; while in continuous learning, tasks appear one by one, and the model can only Learn knowledge about a task and avoid forgetting old knowledge in the process of learning new knowledge.
The University of Southern California and Google Research have proposed a new method to solve continuous learningChannel light Channel-wise Lightweight Reprogramming [CLR]: By adding a trainable lightweight module to the fixed task-invariant backbone, the feature map of each layer channel is Reprogramming makes the reprogrammed feature map suitable for new tasks. This trainable lightweight module only accounts for 0.6% of the entire backbone. Each new task can have its own lightweight module. In theory, infinite new tasks can be continuously learned without catastrophic forgetting. The paper has been published in ICCV 2023.

Usually methods to solve continuous learning are mainly divided into three categories: based on regularization method, dynamic network method and replay method.
The CLR method proposed in this article is a dynamic network method. The figure below represents the flow of the entire process: the researchers use the task-independent immutable part as shared task-specific parameters, and add task-specific parameters to recode the channel features. At the same time, in order to minimize the training amount of recoding parameters for each task, researchers only need to adjust the size of the kernel in the model and learn a linear mapping of channels from backbone to task-specific knowledge to implement recoding. In continuous learning, each new task can be trained to obtain a lightweight model; this lightweight model requires very few training parameters. Even if there are many tasks, the total number of parameters that need to be trained is very small compared to a large model. Small, and each lightweight model can achieve good results
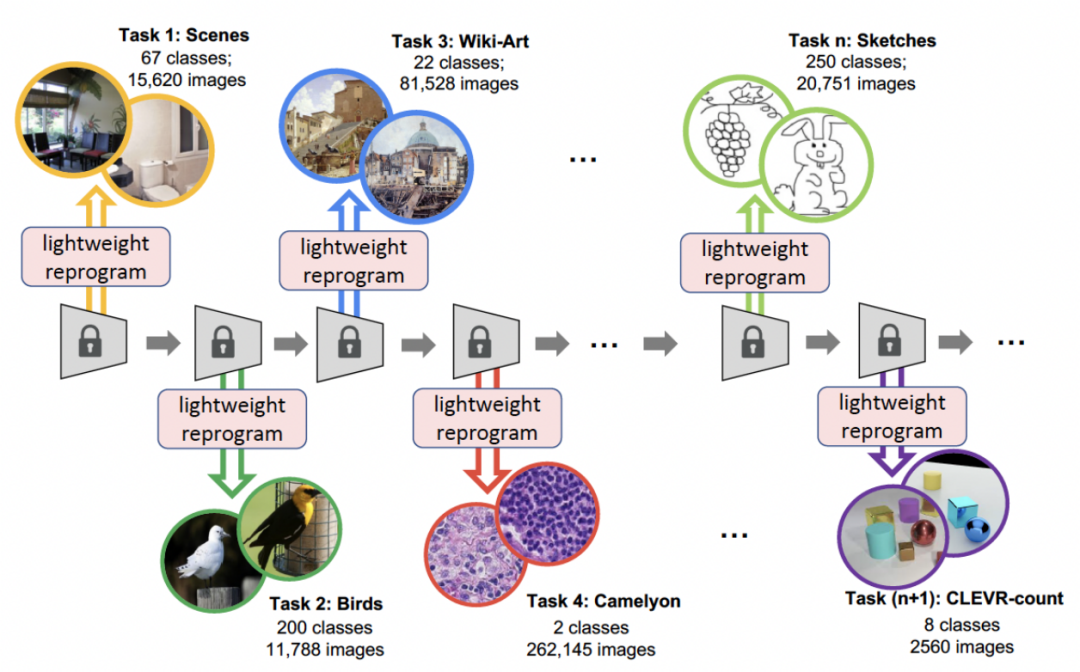
Continuous learning focuses on the problem of learning from data streams, that is, learning new tasks in a specific order, continuously expanding its acquired knowledge, while avoiding forgetting previous tasks, so how to avoid catastrophic forgetting is the main issue in continuous learning research . Researchers consider the following three aspects:
Channel lightweight recodingFirst use A fixed backbone as a task-sharing structure, which can be a pre-trained model for supervised learning on a relatively diverse dataset (ImageNet-1k, Pascal VOC), or a proxy task without semantic labels Learning self-supervised learning models (DINO, SwAV). Different from other continuous learning methods (such as SUPSUP using a randomly initialized fixed structure, CCLL and EFTs using the model learned from the first task as backbone), the pre-trained model used by CLR can provide a variety of visual features, but these visual features Features require CLR layers for recoding on other tasks. Specifically, the researchers used channel-wise linear transformation to re-encode the feature image generated by the original convolution kernel.
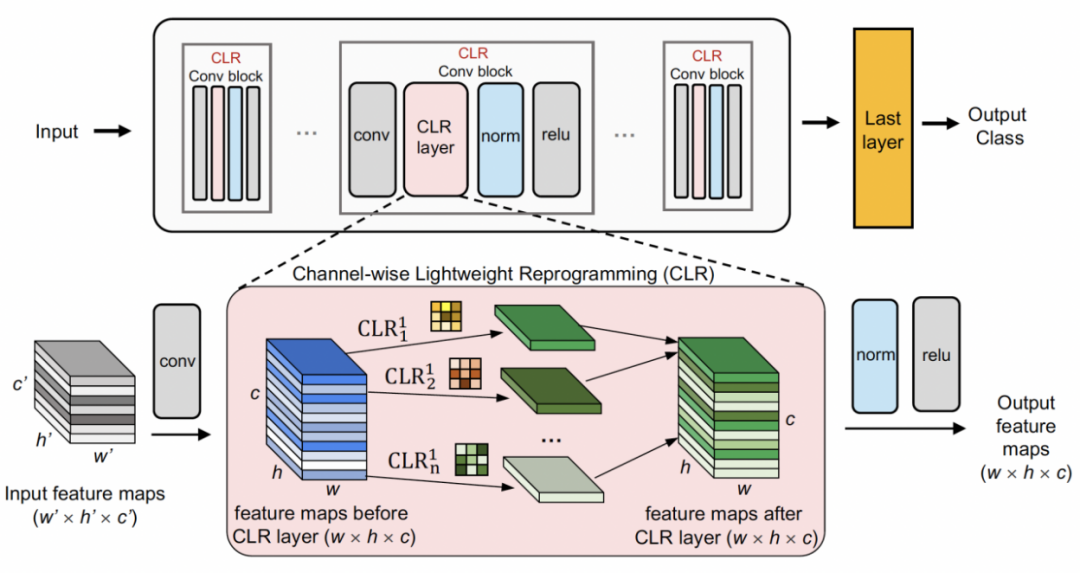
The researchers first fixed the pre-trained backbone, and then added a channel-based lightweight reprogramming layer (CLR layer) after the convolution layer in each fixed convolution block. Perform channel-like linear changes on the feature map after the fixed convolution kernel.
Given a picture X, for each convolution kernel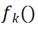 , we can get the feature map
, we can get the feature map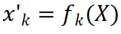 ; Then use 2D convolution kernel to linearly change each channel of X'
; Then use 2D convolution kernel to linearly change each channel of X'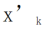 , assuming that each convolution kernel
, assuming that each convolution kernel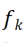 The corresponding linearly changing convolution kernel is
The corresponding linearly changing convolution kernel is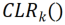 , then the re-encoded feature map
, then the re-encoded feature map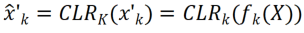 can be obtained. The researcher initializedthe CLR convolution kernel to the same change kernel (that is, for the 2D convolution kernel, only the middle parameter is 1, and the rest are 0),because this can make the original training at the beginning The features generated by the fixed backbone are the same as those generated by the model after adding the CLR layer. At the same time, in order to save parameters and prevent over-fitting, the researchers will not add a CLR layer after the convolution kernel. The CLR layer will only act after the convolution kernel. For ResNet50 after CLR, the increased trainable parameters only account for 0.59% compared to the fixed ResNet50 backbone.
can be obtained. The researcher initializedthe CLR convolution kernel to the same change kernel (that is, for the 2D convolution kernel, only the middle parameter is 1, and the rest are 0),because this can make the original training at the beginning The features generated by the fixed backbone are the same as those generated by the model after adding the CLR layer. At the same time, in order to save parameters and prevent over-fitting, the researchers will not add a CLR layer after the convolution kernel. The CLR layer will only act after the convolution kernel. For ResNet50 after CLR, the increased trainable parameters only account for 0.59% compared to the fixed ResNet50 backbone.
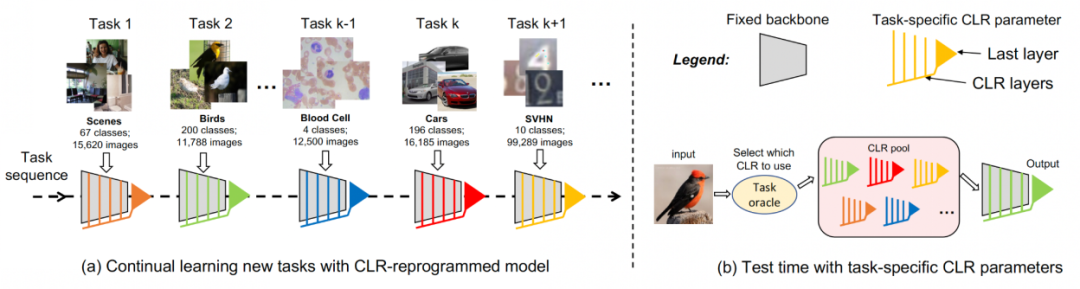
For continuous learning, a model that adds trainable CLR parameters and untrainable backbone can learn each task in turn. When testing, the researchers assume that there is a task predictor that can tell the model which task the test image belongs to, and then the fixed backbone and corresponding task-specific CLR parameters can make the final prediction. Since CLR has the characteristic of absolute parameter isolation (the CLR layer parameters corresponding to each task are different, but the shared backbone will not change), the CLR will not be affected by the number of tasks
Data set: The researcher used image classification as the main task. The laboratory collected 53 image classification data sets, with approximately 1.8 million images and 1584 categories. These 53 datasets contain 5 different classification goals: object recognition, style classification, scene classification, counting and medical diagnosis.
The researcher selected 13 baselines, which can be roughly divided into 3 categories
There are also some baselines that are not continuous learning, such as SGD and SGD-LL. SGD learns each task by fine-tuning the entire network; SGD-LL is a variant that uses a fixed backbone for all tasks and a learnable shared layer whose length is equal to the maximum number of categories for all tasks.
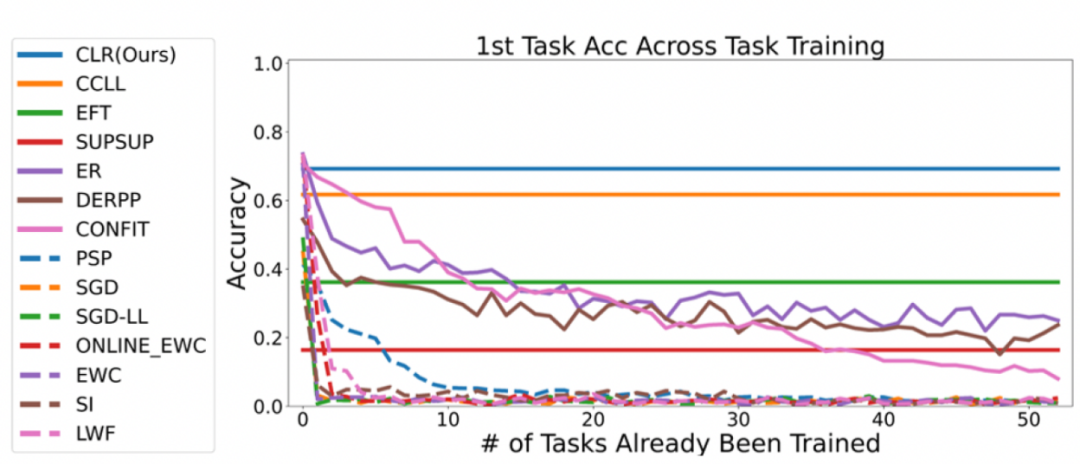
Experiment 1: Accuracy of the first task
To evaluate all methods In their ability to overcome catastrophic forgetting, the researchers tracked accuracy on each task after learning the new task. If a method suffers from catastrophic forgetting, the accuracy on the same task will quickly drop after learning a new task. A good continuous learning algorithm can maintain its original performance after learning new tasks, which means that old tasks should be minimally affected by new tasks. The figure below shows the accuracy of the first task after learning the first to 53rd tasks of this method. Overall, this method can maintain the highest accuracy. More importantly, it avoids catastrophic forgetting and maintains the same accuracy as the original training method no matter how many tasks are continuously learned.
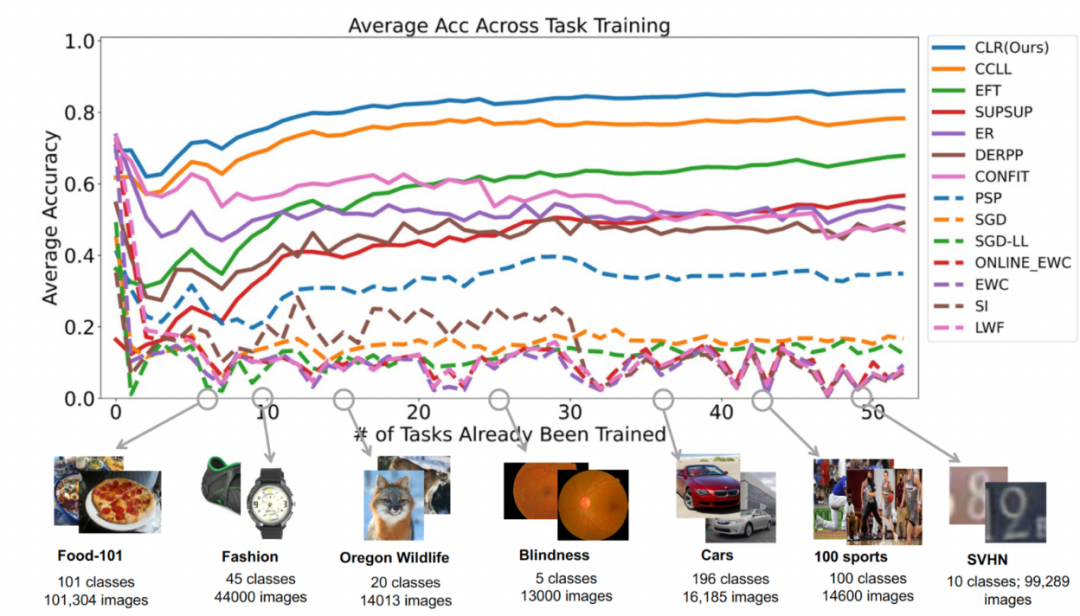
Second experiment: average accuracy learning after completing all tasks
The figure below shows the average accuracy of all methods after learning all tasks. The average accuracy reflects the overall performance of the continuous learning method. Because each task has different levels of difficulty, when a new task is added, the average accuracy across all tasks may rise or fall, depending on whether the added task is easy or difficult.
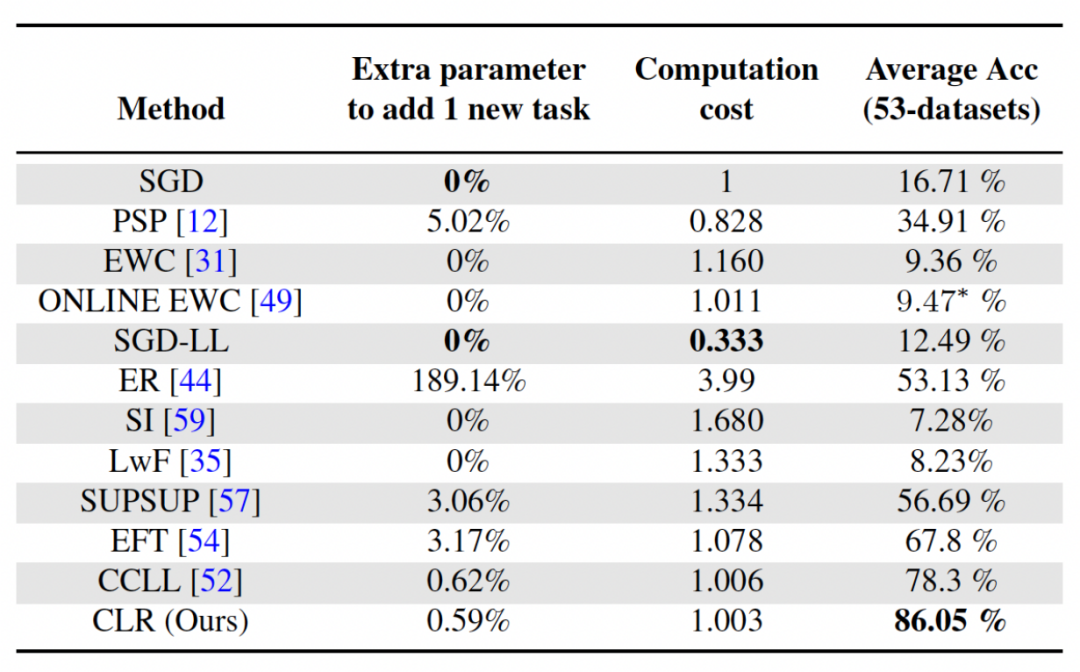
First, let’s analyze the parameters and calculation costs
For continuous learning, while it is important to achieve higher average accuracy, a good algorithm also hopes to minimize the requirements for additional network parameters and computational costs. "Add extra parameters for a new task" represents a percentage of the original backbone parameter amount. This article uses the calculation cost of SGD as the unit, and the calculation costs of other methods are normalized according to the cost of SGD.
Rewritten content: Analysis of the impact of different backbone networks
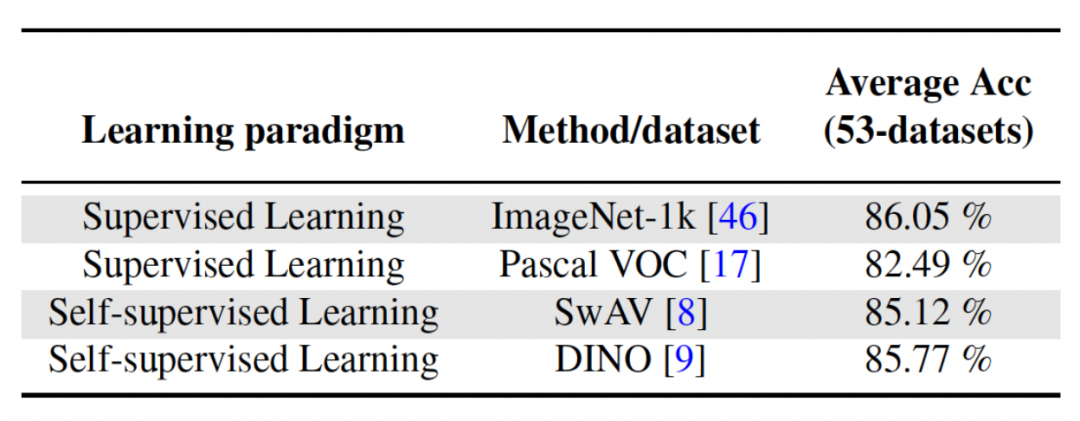
This article The method uses supervised learning or self-supervised learning methods to train on relatively diverse data sets to obtain a pre-trained model, which serves as an invariant parameter that is independent of the task. In order to explore the impact of different pre-training methods, this paper selected four different, task-independent pre-training models trained using different data sets and tasks. For supervised learning, the researchers used pre-trained models on ImageNet-1k and Pascal-VOC for image classification; for self-supervised learning, the researchers used pre-trained models obtained by two different methods, DINO and SwAV. The following table shows the average accuracy of the pre-trained model using four different methods. It can be seen that the final results of any method are very high (Note: Pascal-VOC is a relatively small data set, so the accuracy is relatively low. point) and is robust to different pre-trained backbones.
The above is the detailed content of Optimize learning efficiency: transfer old models to new tasks with 0.6% additional parameters. For more information, please follow other related articles on the PHP Chinese website!
 python programming computer configuration requirements
python programming computer configuration requirements How to open two WeChat accounts on Huawei mobile phone
How to open two WeChat accounts on Huawei mobile phone Introduction to Java special effects implementation methods
Introduction to Java special effects implementation methods linux packet capture command
linux packet capture command The difference between null and NULL in c language
The difference between null and NULL in c language fil currency price real-time price
fil currency price real-time price How to set dreamweaver font
How to set dreamweaver font excel vlookup function usage
excel vlookup function usage




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



