


This year’s ICCV2023 best student paper was awarded to qianqian wang from Cornell University, who is currently a postdoctoral researcher at the University of California, Berkeley!

#In the field of video motion estimation, the author points out that traditional methods are mainly divided into two types: sparse feature tracking and Dense optical flow. While both methods have proven effective in their respective applications, neither fully captures motion in video. Paired optical flow cannot capture motion trajectories within long time windows, while sparse tracking cannot model the motion of all pixels
To bridge this gap, many studies have attempted to simultaneously estimate dense and long distances in videos pixel trajectory. The methods of these studies vary from simply linking the optical flow fields of two frames to directly predicting the trajectory of each pixel across multiple frames. However, these methods often only consider limited context when estimating motion and ignore information that is far away in time or space. This shortsightedness can lead to error accumulation in long trajectories, as well as spatiotemporal inconsistencies in motion estimation. Although some methods consider long-term context, they still operate in the 2D domain, which may lead to tracking loss in occlusion events.
Overall, dense and long-range trajectory estimation in videos is still an unsolved problem in the field. This problem involves three main challenges: 1) How to maintain trajectory accuracy in long sequences, 2) How to track the position of points under occlusion, 3) How to maintain spatiotemporal consistency
Here In this article, the author proposed a novel video motion estimation method that uses all the information in the video to jointly estimate the complete motion trajectory of each pixel. This method is called "OmniMotion" and it uses a quasi-3D representation. In this representation, a standard 3D volume is mapped to a local volume at each frame. This mapping serves as a flexible extension to dynamic multi-view geometry and can simulate camera and scene motion simultaneously. This representation not only ensures loop consistency but also keeps track of all pixels during occlusions. The authors optimize this representation for each video, providing a solution for motion throughout the video. After optimization, this representation can be queried on any continuous coordinates of the video to obtain motion trajectories spanning the entire video
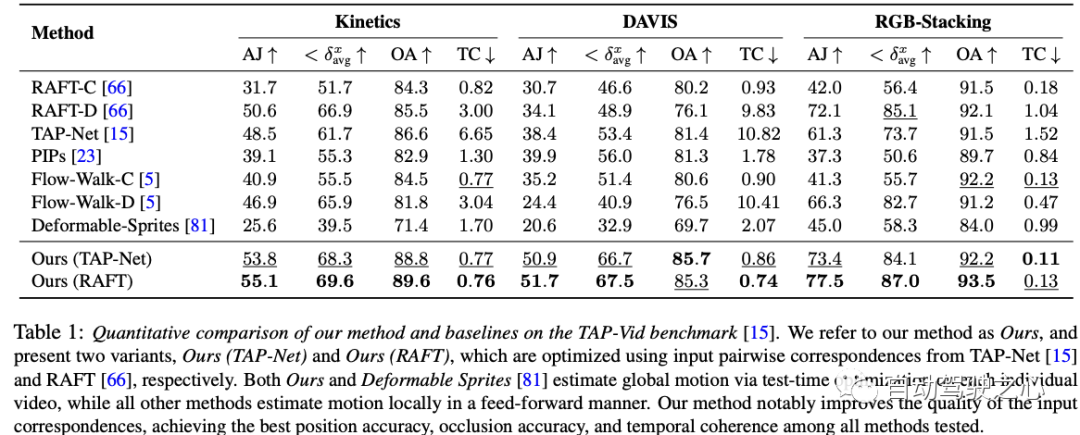
The method proposed in this article can: 1) Generate for all points in the entire video Globally consistent complete motion trajectories, 2) tracking points through occlusion, and 3) processing real videos with various camera and scene action combinations. On the TAP video tracking benchmark, the method performs well, far surpassing previous methods.
The paper proposes a method based on test-time optimization for estimating dense and long-distance motion from video sequences. First, let’s give an overview of the method proposed in the paper:
This method can provide a comprehensive and coherent video motion representation, and can effectively solve challenging problems such as occlusion. Now let’s learn more about
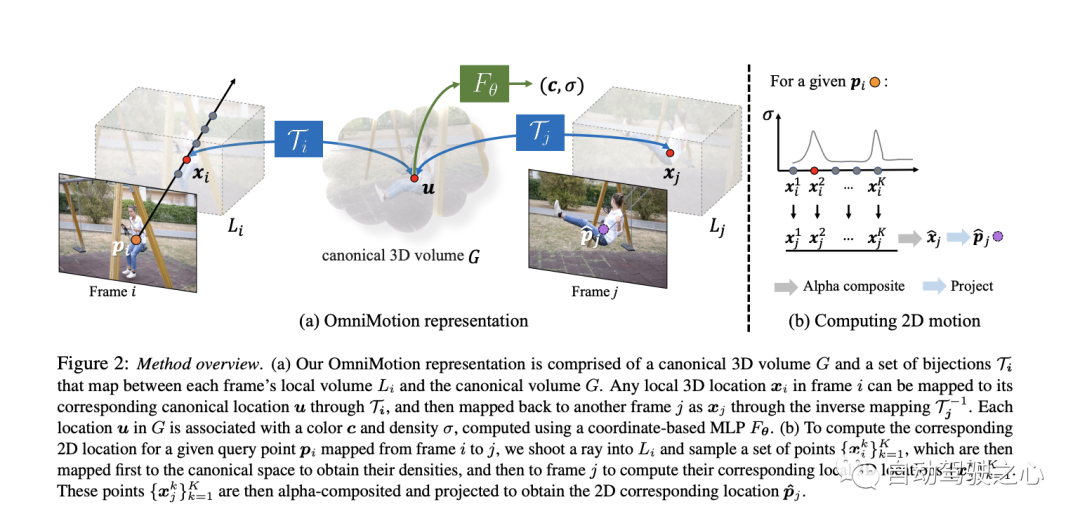
Video content is represented by a typical volume named G, which acts as a three-dimensional map of the observed scene. Similar to what was done in NeRF, they defined a coordinate-based network nerf for each typical 3D coordinate uvw## in G #Map to a density σ and color c. The densities stored in G tell us where the surface is in typical space. When combined with 3D bijections, this enables us to track surfaces over multiple frames and understand occlusion relationships. The colors stored in G allow us to calculate photometric losses during optimization.
3.2 3D bijectionsThis article introduces a continuous bijection mapping, denoted as , which converts 3D points from a local coordinate system to a canonical 3D coordinate system. This canonical coordinate serves as a consistent reference or "index" in time for a scene point or 3D trajectory. The main advantage of using bijective mappings is the periodic consistency they provide in 3D points between different frames, since they all originate from the same canonical point. The mapping equation from one local frame to a 3D point in another is: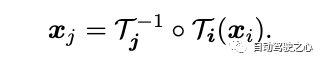
Recompute inter-frame motion
In this section, describe how to calculate 2D motion for any querypixel in frame i. Intuitively, query pixels are first "lifted" to 3D by sampling points on the ray, then these 3D points are "mapped" to target frame j using bijection mapping i and mapping j, followed by alpha compositing from different samples" These mapped 3D points are "rendered" and finally "projected" back into 2D to obtain an assumed correspondence.

# Overall, the results of this ablation experiment show that although each component has a certain improvement in performance, reversibility may be the most important component, because without it, the performance loss will be very serious

The DAVIS dataset used in this work The ablation experiments performed provided us with valuable insights into the critical role of each component on the overall system performance. From the experimental results, we can clearly see that the reversibility component plays a crucial role in the overall framework. When this critical component is missing, system performance drops significantly. This further emphasizes the importance of considering reversibility in dynamic video analysis. At the same time, although the loss of the photometric component also leads to performance degradation, it does not seem to have as big an impact on performance as reversibility. In addition, although the unified sampling strategy has a certain impact on performance, its impact is relatively small compared with the first two. Finally, the complete approach integrates all these components and shows us the best performance achievable under all considerations. Overall, this work provides a valuable opportunity to gain insights into how the various components in video analytics interact with each other and their specific contribution to overall performance, thereby emphasizing the need for an integrated approach when designing and optimizing video processing algorithms. Importance
However, like many motion estimation methods, our method faces difficulties in handling fast and highly non-rigid motions as well as small structures. In these scenarios, pairwise correspondence methods may not provide enough reliable correspondence for our method to compute accurate global motion. Additionally, due to the highly non-convex nature of the underlying optimization problem, we observe that for certain difficult videos, our optimization process can be very sensitive to initialization. This can lead to suboptimal local minima, for example, incorrect surface ordering or duplicate objects in the canonical space, which are sometimes difficult to correct through optimization.
Finally, our method can be computationally expensive in its current form. First, the flow collection process involves comprehensive calculation of all pairwise flows, which grows quadratically with the sequence length. But we believe that the scalability of this process can be improved by exploring more efficient matching methods, such as vocabulary trees or keyframe-based matching, and taking inspiration from the structural motion and SLAM literature. Second, like other methods using neural implicit representations, our method involves a relatively long optimization process. Recent research in this area may help accelerate this process and further extend it to longer sequences
This paper proposes a new A test-time optimization method for estimating complete and globally consistent motion across videos. A new video motion representation called OmniMotion is introduced, which consists of a quasi-3D standard volume and local-canonical bijections for each frame. OmniMotion can process ordinary video with different camera settings and scene dynamics and produce accurate and smooth long-distance motion through occlusion. Significant improvements are achieved over previous state-of-the-art methods, both qualitatively and quantitatively.

The content that needs to be rewritten is: Original link: https://mp.weixin.qq.com/s/HOIi5y9j-JwUImhpHPYgkg
The above is the detailed content of Title rewrite: ICCV 2023 excellent student paper tracking, Github has obtained 1.6K stars, comprehensive information like magic!. For more information, please follow other related articles on the PHP Chinese website!
 Common website vulnerability detection methods
Common website vulnerability detection methods
 The difference between threads and processes
The difference between threads and processes
 How to solve the problem that Apple cannot download more than 200 files
How to solve the problem that Apple cannot download more than 200 files
 Laptop sound card driver
Laptop sound card driver
 Solution to failed connection between wsus and Microsoft server
Solution to failed connection between wsus and Microsoft server
 What element is li?
What element is li?
 What are the methods for restarting applications in Android?
What are the methods for restarting applications in Android?
 What currency is STAKE?
What currency is STAKE?





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



