


This week, the International Conference on Computer Vision (ICCV) opened in Paris, France.

As the world’s top academic conference in the field of computer vision, ICCV is held every two years.
Like CVPR, ICCV’s popularity has hit new highs.
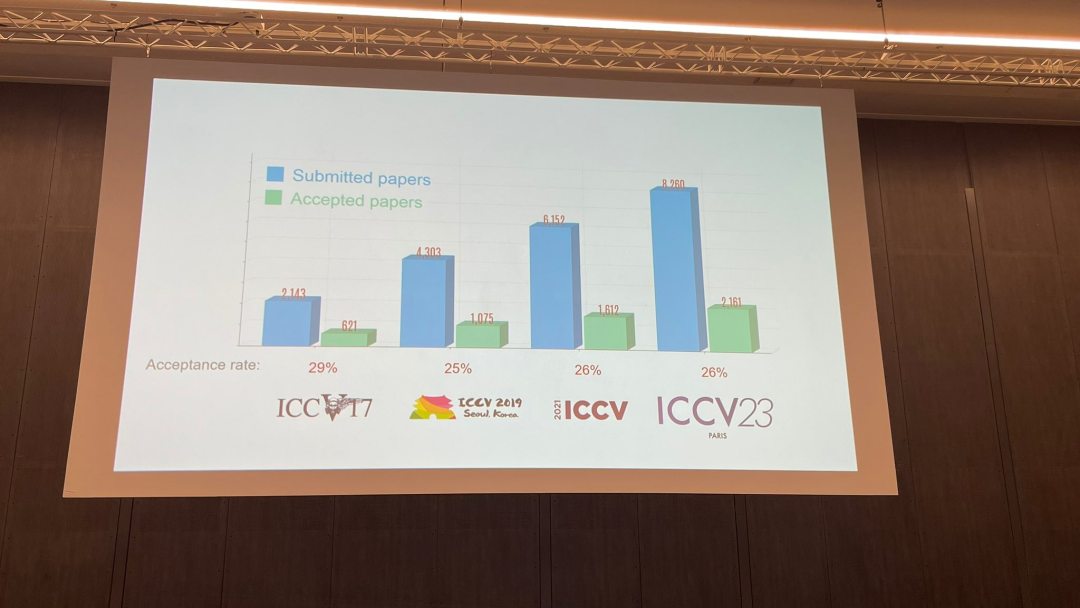
At today's opening ceremony, ICCV officially announced this year's paper data: the total number of submissions to ICCV this year reached 8,068, of which 2,160 were accepted, with an acceptance rate of 26.8%. Slightly higher than the 25.9% acceptance rate of the previous ICCV 2021
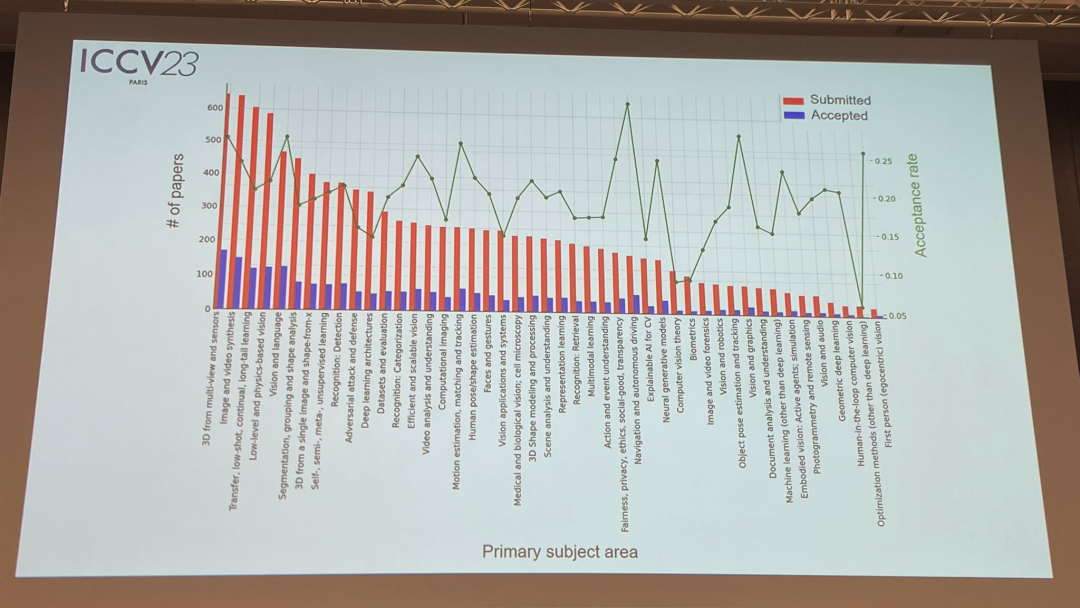
Regarding the paper topic, the official also released relevant data: multi-view and sensor 3D technology is the most popular
In today’s opening ceremony, the most important part is to announce the award-winning information. Now, let us reveal the Best Paper, Best Paper Nomination and Best Student Paper one by one
Total Two papers won this year's best paper (Marr Prize).
The first article comes from researchers at the University of Toronto.

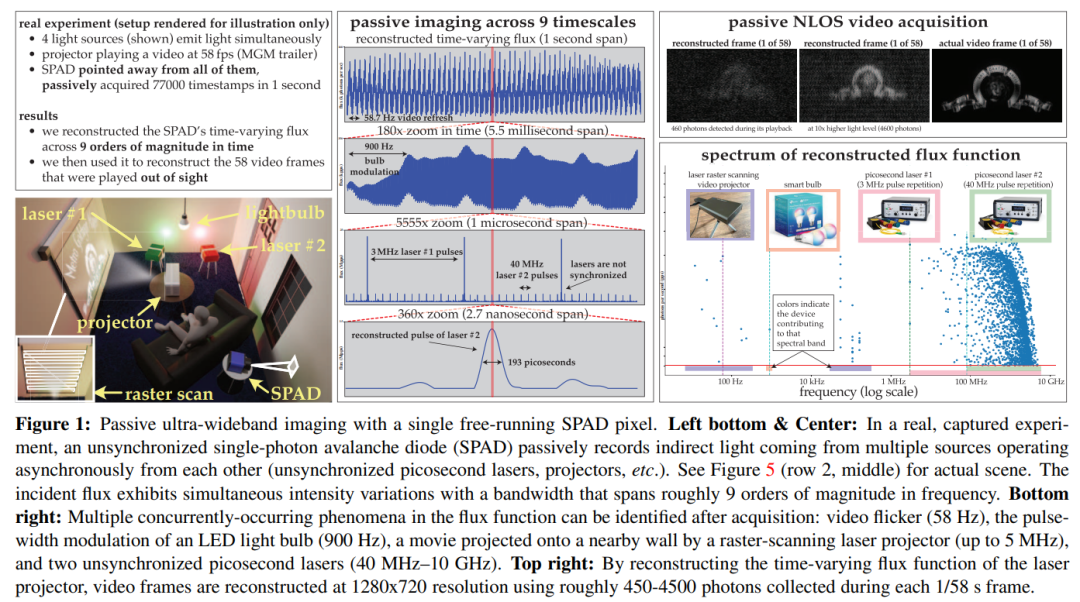
Abstract: This paper considers the problem of imaging dynamic scenes simultaneously at extreme time scales (seconds to picoseconds), and Imaging is done passively, without much light and without any timing signals from the light source that emits it. Since existing flux estimation techniques for single-photon cameras fail in this case, we develop a flux detection theory that draws insights from stochastic calculus to enable the Time-varying flux of reconstructed pixels in a stream of photon detection timestamps.
This paper uses this theory to show that passive free-running SPAD cameras have an achievable frequency bandwidth under low-flux conditions that spans the entire DC to 31 GHz range. At the same time, this paper also derives a novel Fourier domain flux reconstruction algorithm and ensures that the noise model of this algorithm is still effective under very low photon counts or non-negligible dead time
The potential of this asynchronous imaging mechanism is experimentally demonstrated: (1) No synchronization is required for imaging scenes illuminated simultaneously by light sources (such as light bulbs, projectors, multiple pulsed lasers) operating at different speeds; (2) Achieve passive non-line-of-sight video collection; (3) Record ultra-wideband video and later play it back at 30 Hz to show daily movement, or play it back a billion times slower to show the propagation of light itself
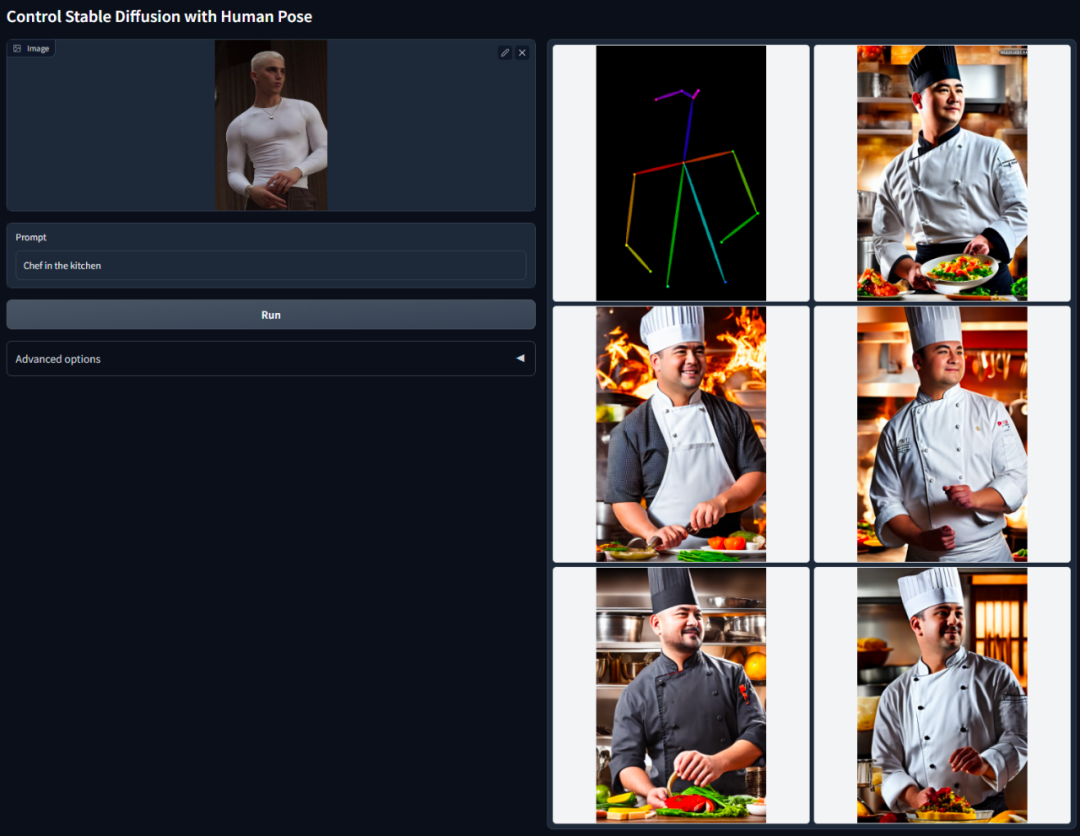
#The second article is what we know as ControNet.

Abstract: This study proposes a An end-to-end neural network architecture called ControlNet. This architecture improves image generation by adding additional conditions to control the diffusion model (such as stable diffusion). At the same time, ControlNet can generate full-color images from line drawings, generate images with the same depth structure, and optimize hand generation effects through hand key points.
The core idea of ControlNet is to add some additional conditions to the text description to control the diffusion model (such as Stable Diffusion), thereby better controlling the character pose, depth, picture structure and other information of the generated image.
The additional conditions here are input in the form of an image. The model can perform Canny edge detection, depth detection, semantic segmentation, Hough transform line detection, and overall nesting based on this input image. edge detection (HED), human pose recognition, etc., and then retain this information in the generated image. Using this model, we can directly convert line drawings or graffiti into full-color images, generate images with the same depth structure, etc., and optimize the generation of character hands through hand key points.
Please refer to Heart of the Machine's report "AI dimensionality reduction hits human painters, Vincentian graphs are introduced into ControlNet, and depth and edge information are fully reused" to Get a more detailed introduction
In April of this year, Meta released a paper called "Separate Everything (SAM) ” artificial intelligence model, which can generate masks for objects in any image or video, which shocked researchers in the field of computer vision. Some even said that “computer vision no longer exists”
Now, this high-profile paper is nominated for the best paper.

Rewritten content: Before solving the segmentation problem, there are usually two methods. The first is interactive segmentation, which can be used to segment any class of objects but requires a human to guide the method by iteratively refining the mask. The second is automatic segmentation, which can be used to segment predefined specific object categories (such as cats or chairs), but requires a large number of manually annotated objects for training (such as thousands or even tens of thousands of examples of segmented cats). However, neither of these two methods provides a universal, fully automatic segmentation method
The SAM proposed by Meta nicely generalizes these two methods. It is a single model that can easily perform interactive segmentation and automatic segmentation. The model's promptable interface allows users to use it in a flexible way, enabling a wide range of segmentation tasks to be accomplished simply by designing the right prompts (clicks, box selections, text, etc.) for the model
To summarize, these features enable SAM to adapt to new tasks and domains. This flexibility is unique in the field of image segmentation
For details, please refer to the Heart of the Machine report: "CV Doesn't Exist?" Meta releases “split everything” AI model, CV may usher in GPT-3 moment》
The research was conducted by It was jointly completed by researchers from Cornell University, Google Research and UC Berkeley. The first work was Qianqian Wang, a doctoral student from Cornell Tech. They jointly proposed OmniMotion, a complete and globally consistent motion representation, and proposed a new test-time optimization method to perform accurate and complete motion estimation for every pixel in the video.

The OmniMotion proposed in this research uses a quasi-3D canonical volume to characterize the video and tracks each pixel through a bijection between local space and canonical space. This representation enables global consistency, enables motion tracking even when objects are occluded, and models any combination of camera and object motion. This study experimentally demonstrates that the proposed method significantly outperforms existing SOTA methods.
Please refer to the Heart of Machine report "The "track everything" video algorithm that tracks every pixel anytime, anywhere, and is not afraid of occlusion is here" for a more detailed introduction
In addition to these award-winning papers, this year’s ICCV also has many other outstanding papers worthy of everyone’s attention. The following is an initial list of the 17 winning papers

The above is the detailed content of ICCV 2023 announced the winners of popular papers such as ControlNet and 'Split Everything'. For more information, please follow other related articles on the PHP Chinese website!
 Can BAGS coins be held for a long time?
Can BAGS coins be held for a long time? How to deal with garbled Chinese characters in Linux
How to deal with garbled Chinese characters in Linux What data does redis cache generally store?
What data does redis cache generally store? Mini program path acquisition
Mini program path acquisition Introduction to service providers with cost-effective cloud server prices
Introduction to service providers with cost-effective cloud server prices Compressed file encryption
Compressed file encryption what is python range
what is python range What should I do if the docker container cannot access the external network?
What should I do if the docker container cannot access the external network?




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



