


Refreshed the industry’s best zero-shot performance in multiple benchmark tests.
A unified model that can understand different modal input contents (text, image, video, audio, IMU motion sensor data) and generate text responses. The technology is based on Llama 2 , from Meta.
Yesterday, the research on the multi-modal large model AnyMAL attracted the attention of the AI research community.
Large Language Models (LLMs) are known for their enormous size and complexity, which greatly enhance the ability of machines to understand and express human language. Advances in LLMs have enabled significant advances in the field of visual language, bridging the gap between image encoders and LLMs, combining their inference capabilities. Previous multimodal LLM research has focused on models that combine text with another modality, such as text and image models, or on proprietary language models that are not open source.
If there is a better way to achieve multi-modal functionality and embed various modalities in LLM, will this bring us a different experience?
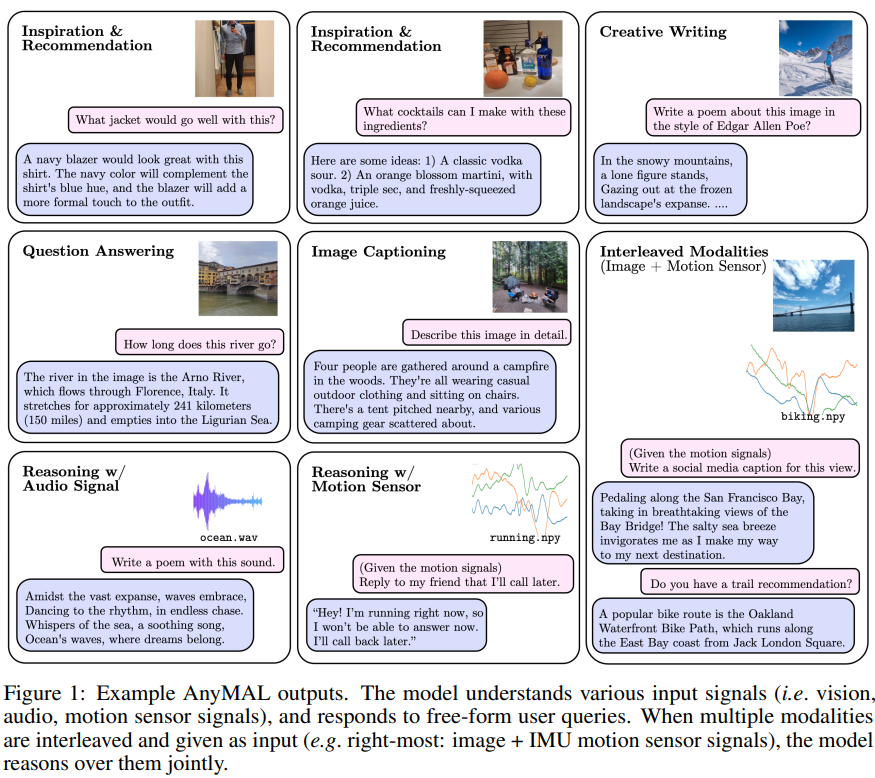
##Q output Example
This problem, researchers from META recently launched Anymal ( Any-Modality Augmented Language Model). This is a collection of multi-modal encoders trained to transform data from a variety of modalities, including images, video, audio, and IMU motion sensor data, into LLM’s text embedding space

Paper address: https://huggingface.co/papers/2309.16058
According to the description, the main contributions of this research are as follows:
Proposed an efficient and scalable solution for building multi-modal LLM. This article provides projection layers pre-trained on large datasets containing multiple modalities (e.g., 200 million images, 2.2 million audio segments, 500,000 IMU time series, 28 million video segments), all All aligned to the same large model (LLaMA-2-70B-chat), enabling interleaved multi-modal contextual cues.
This study further fine-tuned the model using a multi-modal instruction set across three modalities (image, video and audio), covering various fields beyond simple question answering (QA). unlimited tasks. This dataset contains high-quality manually collected instruction data, so this study uses it as a benchmark for complex multi-modal reasoning tasks
The best model in this paper automatically performs various tasks and modes Compared with the models in the existing literature, the relative accuracy on VQAv2 has been improved by 7.0%, and the CIDEr on zero-error COCO image subtitles has been improved by 8.4%. Improved CIDEr by 14.5% on AudioCaps and created new SOTA
The content of pre-training modal alignment needs to be rewritten
By using paired multi-modal data (including specific modal signals and text narrative), this study pre-trained LLM to achieve multi-modal understanding capabilities, as shown in Figure 2. Specifically, we train a lightweight adapter for each modality that projects the input signal into the text token embedding space of a specific LLM. In this way, the text tag embedding space of LLM becomes a joint tag embedding space, where tags can represent text or other modalities. 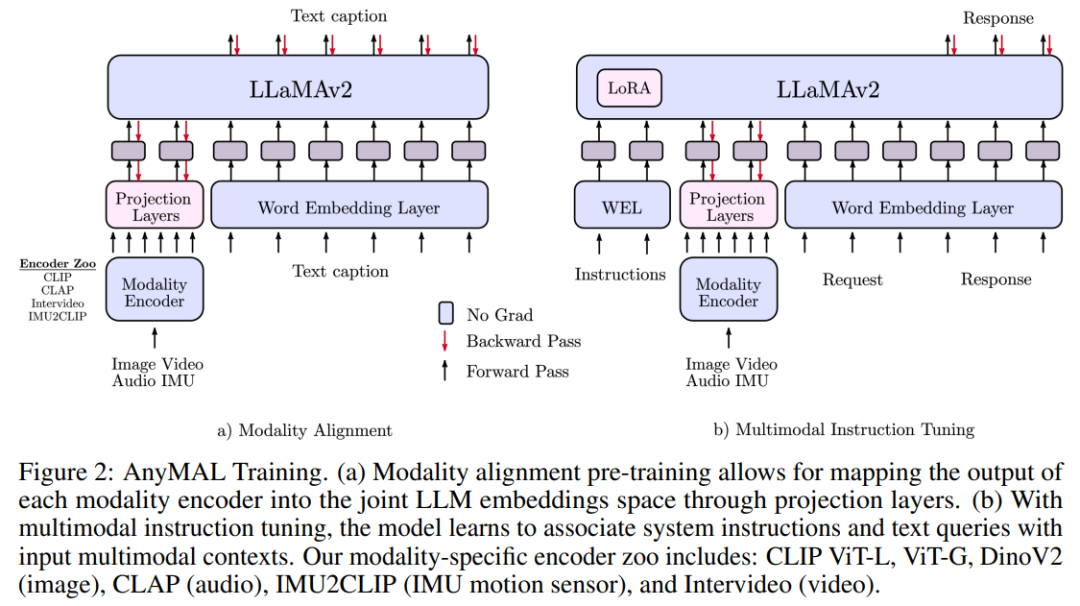 Regarding the study of image alignment, we used one of the LAION-2B dataset A clean subset was filtered using the CAT method to blur any detectable faces. For the study of audio alignment, the AudioSet (2.1M), AudioCaps (46K) and CLOTHO (5K) data sets were used. In addition, we also used the Ego4D dataset for IMU and text alignment (528K)For large datasets, scaling up pre-training to a 70B parameter model requires a lot of resources, often requiring the use of FSDP wrappers on multiple Slice the model on multiple GPUs. To effectively scale training, we implement a quantization strategy (4-bit and 8-bit) in a multi-modal setting, where the LLM part of the model is frozen and only the modal tokenizer is trainable. This approach reduces memory requirements by an order of magnitude. Therefore, 70B AnyMAL can complete training on a single 80GB VRAM GPU with a batch size of 4. Compared with FSDP, the quantization method proposed in this article only uses half of the GPU resources, but achieves the same throughput
Regarding the study of image alignment, we used one of the LAION-2B dataset A clean subset was filtered using the CAT method to blur any detectable faces. For the study of audio alignment, the AudioSet (2.1M), AudioCaps (46K) and CLOTHO (5K) data sets were used. In addition, we also used the Ego4D dataset for IMU and text alignment (528K)For large datasets, scaling up pre-training to a 70B parameter model requires a lot of resources, often requiring the use of FSDP wrappers on multiple Slice the model on multiple GPUs. To effectively scale training, we implement a quantization strategy (4-bit and 8-bit) in a multi-modal setting, where the LLM part of the model is frozen and only the modal tokenizer is trainable. This approach reduces memory requirements by an order of magnitude. Therefore, 70B AnyMAL can complete training on a single 80GB VRAM GPU with a batch size of 4. Compared with FSDP, the quantization method proposed in this article only uses half of the GPU resources, but achieves the same throughput
Using multi-modal instruction data sets for fine-tuning means using multi-modal instruction data sets for fine-tuning
In order to further To improve the model's ability to follow instructions for different input modalities, the study used the Multi-Modal Instruction Tuning (MM-IT) data set for additional fine-tuning. Specifically, we concatenate the input as [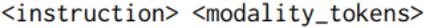 ] so that the response target is based on both the textual instruction and the modal input. Research is conducted on the following two situations: (1) training the projection layer without changing the LLM parameters; or (2) using low-level adaptation (Low-Rank Adaptation) to further adjust the LM behavior. The study uses both manually collected instruction-tuned datasets and synthetic data.
] so that the response target is based on both the textual instruction and the modal input. Research is conducted on the following two situations: (1) training the projection layer without changing the LLM parameters; or (2) using low-level adaptation (Low-Rank Adaptation) to further adjust the LM behavior. The study uses both manually collected instruction-tuned datasets and synthetic data.
Experiments and results
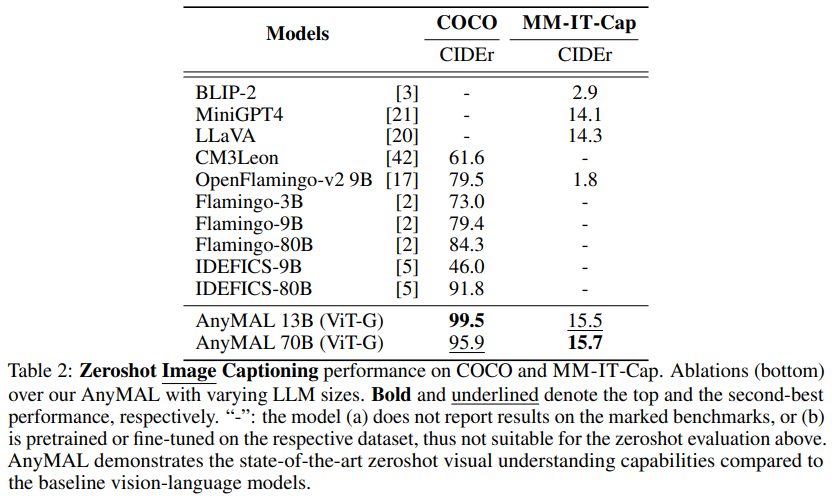
Image title generation is an artificial intelligence technology used to automatically generate corresponding titles for images. This technology combines computer vision and natural language processing methods to generate descriptive captions related to the image by analyzing the content and characteristics of the image, as well as understanding the semantics and syntax. Image caption generation has wide applications in many fields, including image search, image annotation, image retrieval, etc. By automatically generating titles, the understandability of images and the accuracy of search engines can be improved, providing users with a better image retrieval and browsing experience. Description" Zero-shot image caption generation performance on a subset of the MM-IT dataset for the task (MM-IT-Cap). As can be seen, the AnyMAL variant performs significantly better than the baseline on both datasets. Notably, there is no significant gap in performance between the AnyMAL-13B and AnyMAL-70B variants. This result demonstrates that the underlying LLM capability for image caption generation is an artificial intelligence technique used to automatically generate corresponding captions for images. This technology combines computer vision and natural language processing methods to generate descriptive captions related to the image by analyzing the content and characteristics of the image, as well as understanding the semantics and syntax. Image caption generation has wide applications in many fields, including image search, image annotation, image retrieval, etc. By automating caption generation, image understandability and search engine accuracy can be improved, providing users with a better image retrieval and browsing experience. The task is less impactful, but depends heavily on data size and registration method. .
 The rewrite required is: Human evaluation on multi-modal inference tasks
The rewrite required is: Human evaluation on multi-modal inference tasks
Figure 3 shows that, compared with the baseline ( Compared with LLaVA: 34.4% winning rate and MiniGPT4: 27.0% winning rate), AnyMAL performs strongly and has a smaller gap with the actual manually labeled samples (41.1% winning rate). Notably, models fine-tuned with the full instruction set showed the highest priority winning rate, showing visual understanding and reasoning capabilities comparable to human-annotated responses. It is also worth noting that BLIP-2 and InstructBLIP perform poorly on these open queries (4.1% and 16.7% priority win rate, respectively), although they perform well on the public VQA benchmark (see Table 4) .
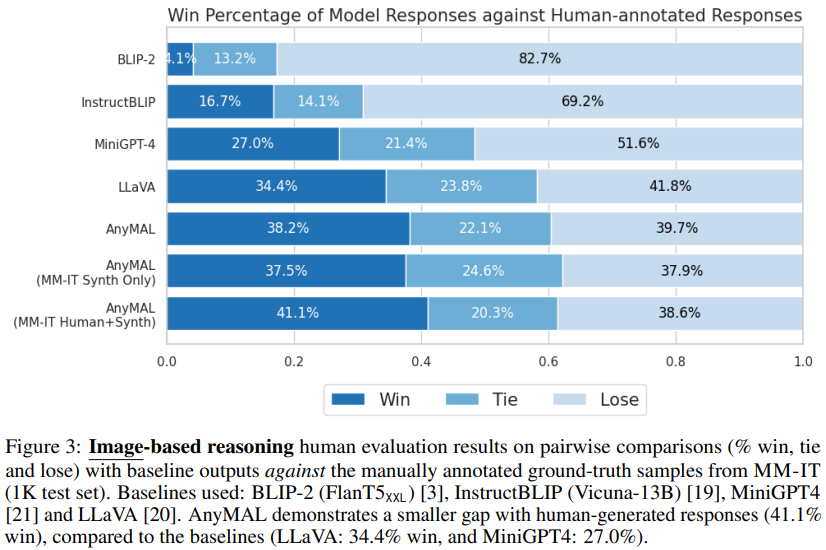 VQA Benchmark
VQA Benchmark
In Table 4, we show the performance of the Hateful Meme dataset, VQAv2 , TextVQA, ScienceQA, VizWiz and OKVQA, and compared with zero-shot results on the respective benchmarks reported in the literature. Our research focuses on zero-shot evaluation to most accurately estimate model performance on open queries at inference time
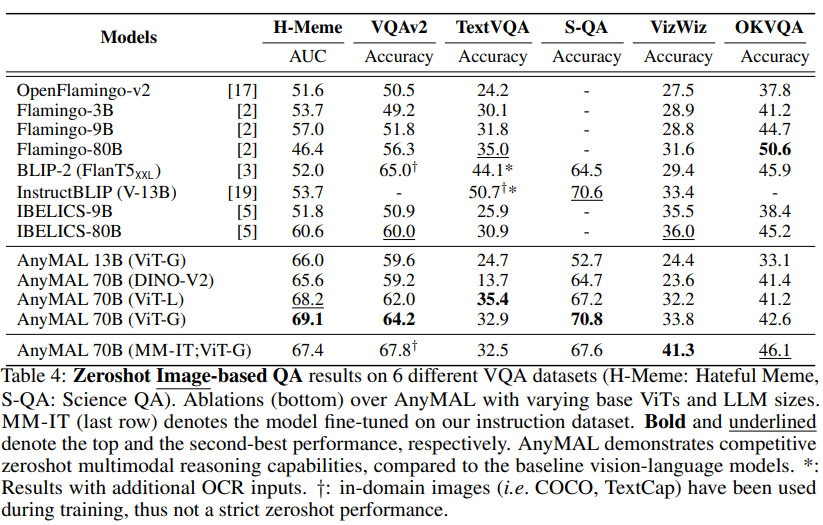 Video QA Benchmark
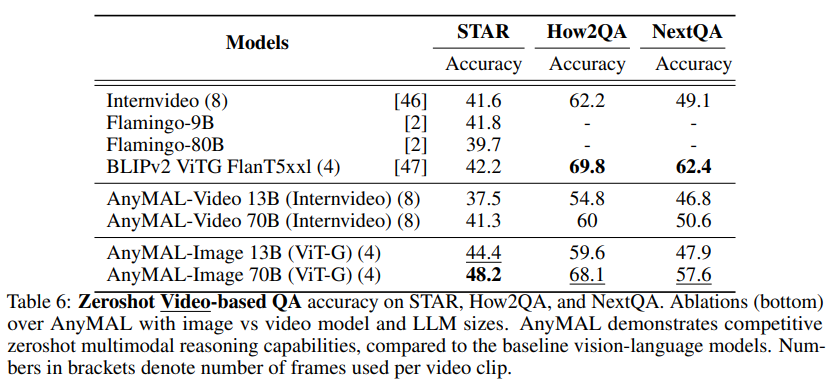
Video QA Benchmark
As shown in Table 6, the study evaluated the model on three challenging video QA benchmarks.
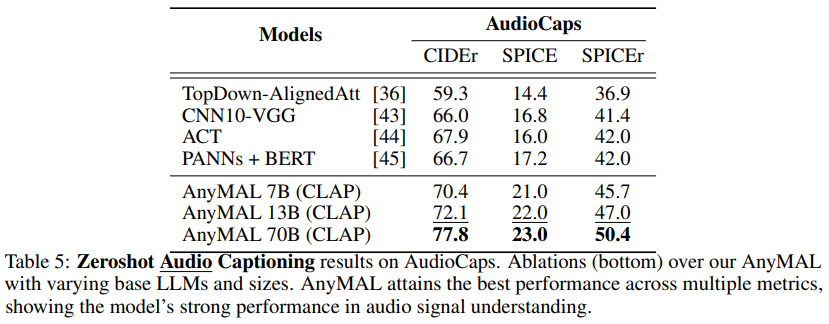
 Regenerate audio subtitles
Regenerate audio subtitles
Table 5 shows the results of regenerating audio subtitles on the AudioCaps benchmark dataset. AnyMAL significantly outperforms other state-of-the-art audio subtitle models in the literature (e.g., CIDEr 10.9pp, SPICE 5.8pp), indicating that the proposed method is not only applicable to vision but also to various modalities. The text 70B model shows clear advantages compared to the 7B and 13B variants.
Interestingly, based on the method, type, and timing of the AnyMAL paper submission, Meta seems to be planning to collect multi-modal data through its newly launched mixed reality/metaverse headset. These research results may be integrated into Meta’s Metaverse product line, or may soon be used in consumer applications
Please read the original article for more details.
The above is the detailed content of Multi-modal version Llama2 is online, Meta releases AnyMAL. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



