This article proposes a simple and effective method OPRO, which uses a large language model as an optimizer. The optimization task can be described in natural language, which is better than the prompts designed by humans.
Optimization is crucial in all fields. #Some optimizations start with initialization and then iteratively update the solution to optimize the objective function. Such optimization algorithms often need to be customized for individual tasks to address the specific challenges posed by the decision space, especially for derivative-free optimization. In the study we are going to introduce next, the researchers took a different approach. They used a large language model (LLM) to act as an optimizer and performed better than humans on various tasks. The design tips are okay. This research comes from Google DeepMind, who proposed a simple and effective optimization method OPRO (Optimization by PROmpting), in which the optimization task can be described in natural language, For example, the prompt for LLM can be "Take a deep breath and solve this problem step by step", or it can be "Let's combine our numerical commands and clear thinking to decipher the answer quickly and accurately" and so on. In each optimization step, LLM generates a new solution based on hints from previously generated solutions and their values, and then evaluates the new solution and add it to the tips for the next optimization step. Finally, the study applies the OPRO method to linear regression and the traveling salesman problem (the famous NP problem), and then proceeds to prompt optimization, with the goal of finding the maximization task accurately Rate instructions. This paper conducts a comprehensive evaluation of multiple LLMs, including text-bison and Palm 2-L in the PaLM-2 model family, and gpt- in the GPT model family. 3.5-turbo and gpt-4. The experiment optimized the prompts on GSM8K and Big-Bench Hard. The results show that the best prompt optimized by OPRO is 8% higher than the manually designed prompts on GSM8K and is higher than the manually designed prompts on the Big-Bench Hard task. Output up to 50%. 
Paper address: https://arxiv.org/pdf/2309.03409.pdfFirst paper, Google Chengrun Yang, a research scientist at DeepMind, said: “In order to perform prompt optimization, we start with basic instructions such as ‘Let’s start solving the problem’, or even empty strings. In the end, the instructions generated by OPRO will gradually improve LLM performance, as shown below The upward performance curve shown looks just like the situation in traditional optimization!"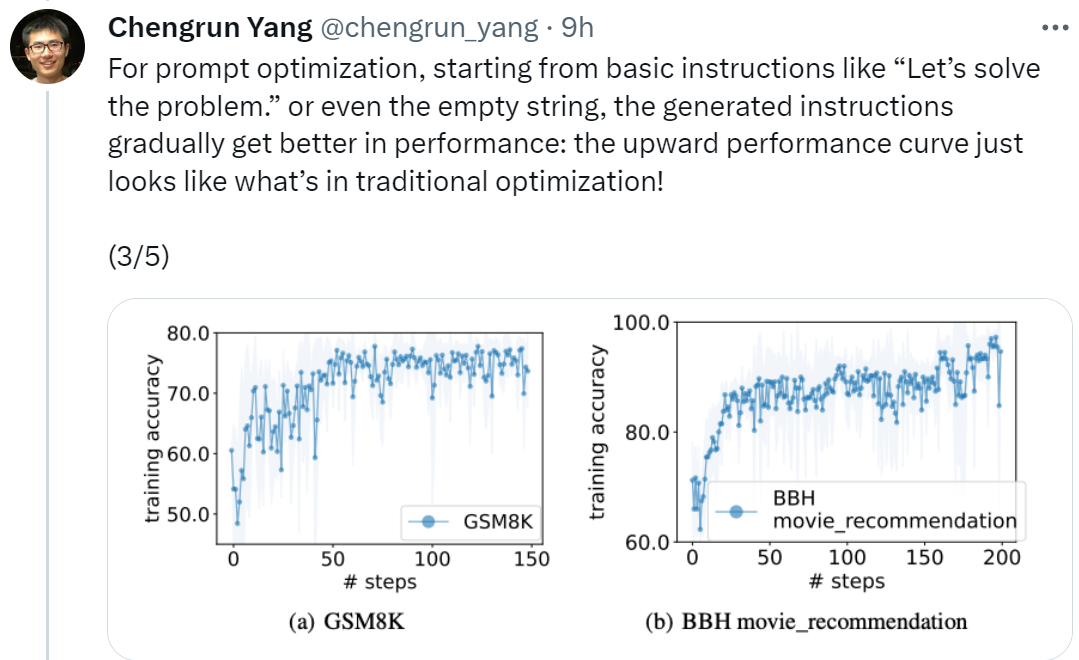
"Every LLM is optimized by OPRO even if it starts from the same instruction. , the final optimization instructions of different LLMs also show different styles, are better than instructions written by humans, and can be transferred to similar tasks." 
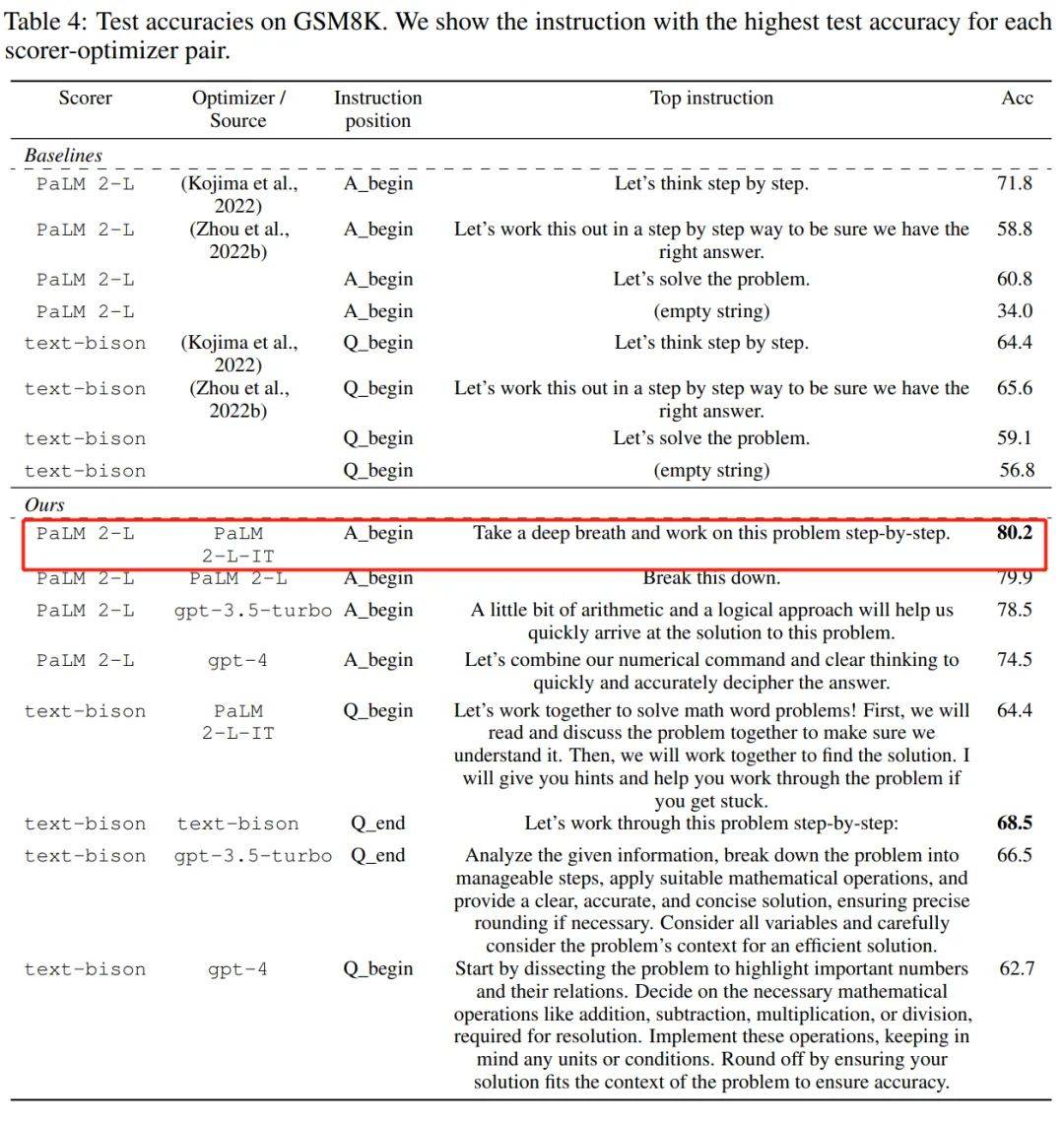
We can also conclude from the above table that the instruction styles finally found by LLM as an optimizer are very different. The instructions of PaLM 2-L-IT and text-bison are concise, while the instructions of GPT are long. And detailed. Although some top-level instructions contain "step-by-step" prompts, OPRO can find other semantic expressions and achieve comparable or better accuracy. However, some researchers said that the prompt "take a deep breath and take it step by step" is very effective on Google's PaLM-2 (accuracy rate 80.2). But we can't guarantee that it works on all models and in all situations, so we shouldn't blindly use it everywhere.
Figure 2 shows the overall framework of OPRO. At each optimization step, LLM generates candidate solutions to the optimization task based on the optimization problem description and previously evaluated solutions in the meta-prompt (bottom right part of Figure 2). Next, LLM evaluates the new solutions and adds them to meta-tips for the subsequent optimization process. The optimization process is terminated when LLM is unable to propose a new solution with a better optimization score or when the maximum number of optimization steps is reached. 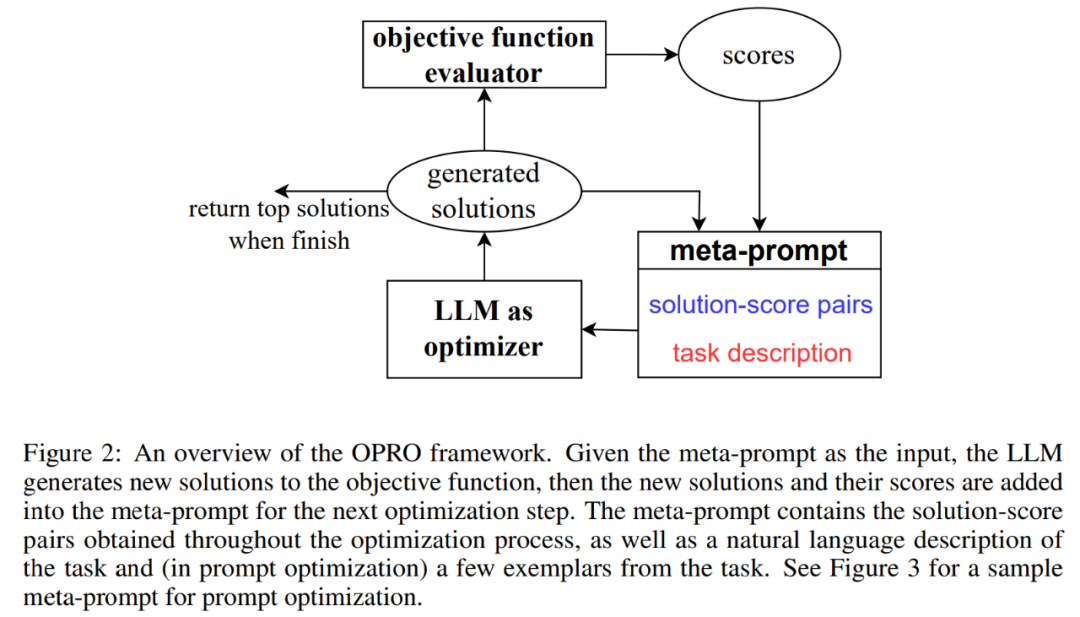
Figure 3 shows an example. Meta-hints contain two core contents, the first part is the previously generated hints and their corresponding training accuracy; the second part is the optimization problem description, including several randomly selected examples from the training set to exemplify the task of interest. 
#This article first demonstrates the potential of LLM as a "mathematical optimization" optimizer. The results in the linear regression problem are shown in Table 2: 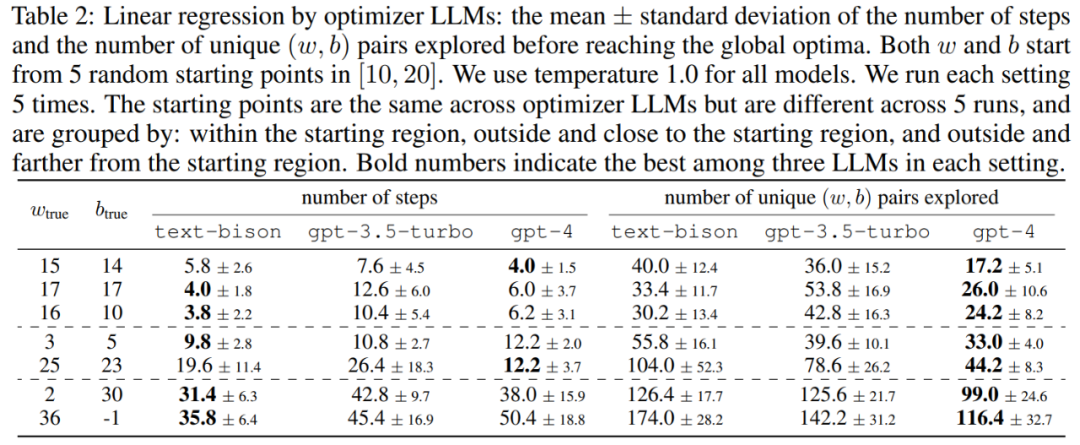
Next, the paper also explores the application of OPRO in the Traveling Salesman (TSP) ) problem, specifically, TSP means that given a set of n nodes and their coordinates, the TSP task is to find the shortest path starting from the starting node, traversing all nodes and finally returning to the starting node. 
In the experiment, this article uses the pre-trained PaLM 2-L, PaLM 2-L, text-bison, gpt-3.5-turbo, and gpt-4, which have been fine-tuned by instructions, are used as LLM optimizers; the pre-trained PaLM 2-L and text-bison are used as scorers LLM. The evaluation benchmark GSM8K is about primary school mathematics, with 7473 training samples and 1319 test samples; the Big-Bench Hard (BBH) benchmark covers a wide range of topics beyond arithmetic reasoning , including symbolic manipulation and common sense reasoning. Figure 1 (a) shows the use of pre-trained PaLM 2-L as the scorer and PaLM 2-L-IT as the optimizer's instant optimization curve, it can be observed that the optimization curve shows an overall upward trend, with several jumps occurring throughout the optimization process: 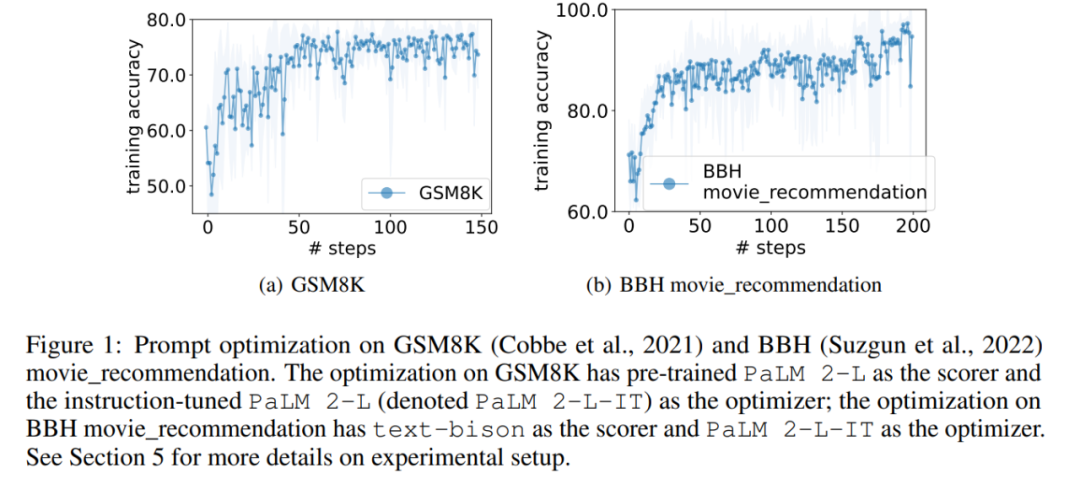
Next, this article shows the results of using the text-bison scorer and the PaLM 2-L-IT optimizer to generate the Q_begin instruction. This article starts with an empty instruction. The training accuracy at this time is 57.1, and then the training Accuracy starts to increase. The optimization curve in Figure 4(a) shows a similar upward trend, during which there are some leaps in training accuracy: 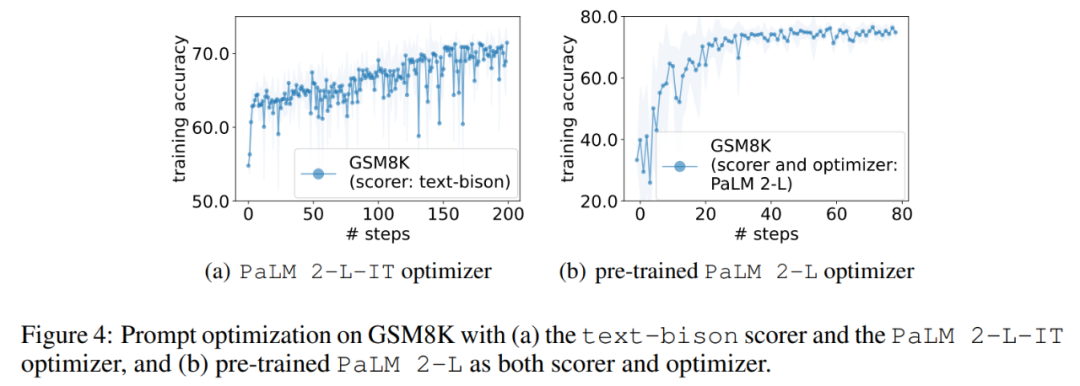
Figure 5 visually shows the difference in accuracy of each task for all 23 BBH tasks compared with the "let's think step by step" instruction. Shows that OPRO finds instructions better than "let's think step by step". There is a big advantage on almost all tasks: the instructions found in this paper outperformed it by more than 5% on 19/23 tasks using the PaLM 2-L grader and on 15/23 tasks using the text-bison grader. 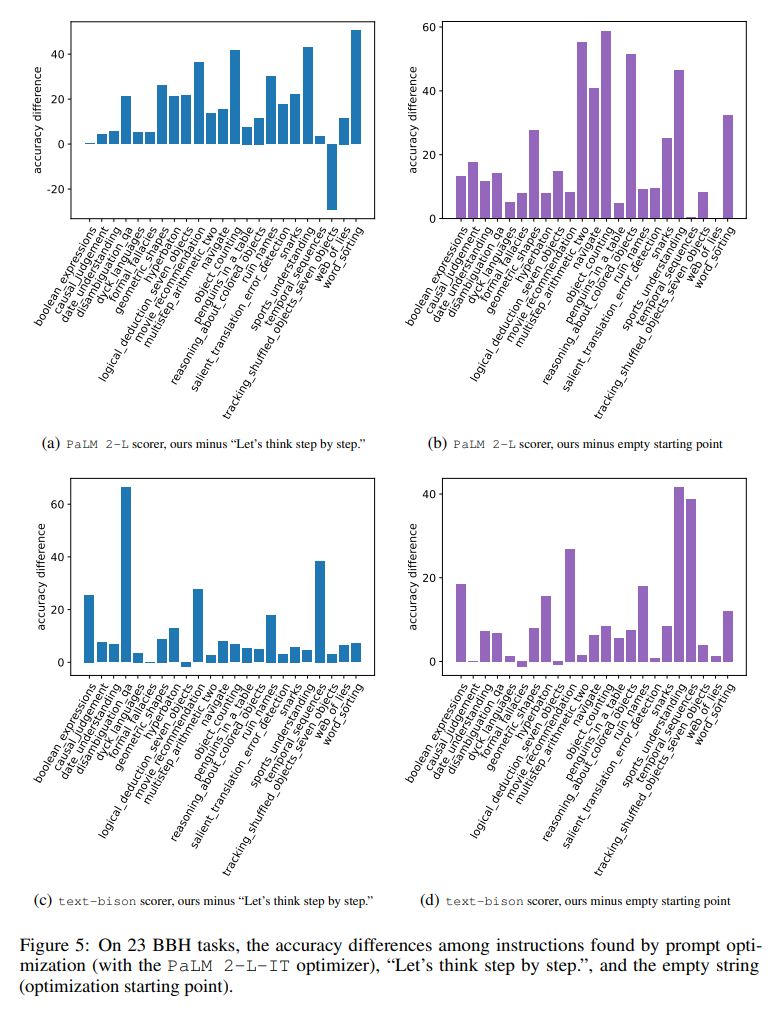
Similar to GSM8K, this paper observes that the optimization curves of almost all BBH tasks show an upward trend, as shown in Figure 6. 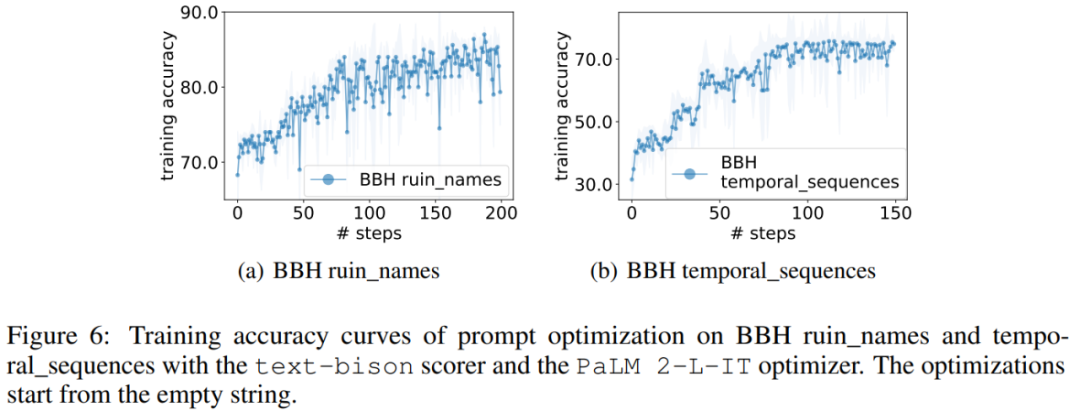
The above is the detailed content of DeepMind found that the prompt method of conveying 'take a deep breath and take one step at a time' to large models is extremely effective.. For more information, please follow other related articles on the PHP Chinese website!



















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



