



In order to deal with various complex audio and video communication scenarios, such as multi-device, multi-person, and multi-noise scenarios, streaming media communication technology has gradually become a part of people’s lives. indispensable technology. In order to achieve a better subjective experience and enable users to hear clearly and truly, the streaming audio technology solution combines traditional machine learning and AI-based voice enhancement solutions, using deep neural network technology solutions to achieve voice noise reduction and echo cancellation. , interfering voice elimination and audio encoding and decoding, etc., to protect the audio quality in real-time communication.
As the flagship international conference in the field of speech signal processing research, Interspeech has always represented the most cutting-edge research direction in the field of acoustics. Interspeech 2023 includes a number of articles related to audio signal speech enhancement algorithms, among which, ## A total of 4 research papers from the #volcanoengine streaming audio team were accepted by the conference, including speech enhancement, AI-based encoding and decoding, echo cancellation, and unsupervised adaptive speech enhancement.
It is worth mentioning that in the field of unsupervised adaptive speech enhancement, the joint team of ByteDance and NPU successfully completed the subtask of unsupervised domain adaptive conversational speech in this year’s CHiME (Computational Hearing in Multisource Environments) Challenge. Enhancement (Unsupervised domain adaptation for conversational speech enhancement, UDASE) won the championship (https://www.chimechallenge.org/current/task2/results). The CHiME Challenge is an important international competition launched in 2011 by well-known research institutions such as the French Institute of Computer Science and Automation, the University of Sheffield in the UK, and the Mitsubishi Electronics Research Laboratory in the United States. It focuses on challenging remote problems in the field of speech research. This year, it has been held for the seventh time. Participating teams in previous CHiME competitions include the University of Cambridge in the United Kingdom, Carnegie Mellon University in the United States, Johns Hopkins University, NTT in Japan, Hitachi Academia Sinica and other internationally renowned universities and research institutions, as well as Tsinghua University, University of Chinese Academy of Sciences, Chinese Academy of Sciences Institute of Acoustics, NPU, iFlytek and other top domestic universities and research institutes. This article will introduce the core scenario problems and technical solutions solved by these four papers,share the Volcano Engine streaming audio team’s progress in speech enhancement, based on AI encoder, echo cancellation and unsupervised adaptive speech enhancement Thinking and practice in the field.
Lightweight speech harmonic enhancement method based on learnable comb filter Paper address: https://www.isca-speech.org/archive/interspeech_2023/ le23_interspeech.html Background Limited by delay and computing resources, speech enhancement in real-time audio and video communication scenarios usually uses input features based on filter banks. Through filter banks such as Mel and ERB, the original spectrum is compressed into lower-dimensional sub-bands. In the sub-band domain, the output of the deep learning-based speech enhancement model is the speech gain of the sub-band, which represents the proportion of the target speech energy. However, the enhanced audio over the compressed sub-band domain is blurry due to loss of spectral detail, often requiring post-processing to enhance harmonics. RNNoise and PercepNet use comb filters to enhance harmonics, but due to fundamental frequency estimation and comb filter gain calculation and model decoupling, they cannot be optimized end-to-end; DeepFilterNet uses a time-frequency domain filter to suppress inter-harmonic noise , but does not explicitly utilize the fundamental frequency information of speech. In response to the above problems, the team proposed a speech harmonic enhancement method based on a learnable comb filter. This method combines fundamental frequency estimation and comb filtering, and the gain of the comb filter can be optimized end-to-end. Experiments show that this method can achieve better harmonic enhancement with a similar amount of calculation as existing methods. Model framework structure Fundamental frequency estimator (F0 Estimator) In order to reduce the difficulty of fundamental frequency estimation and enable the entire link to run end-to-end, the to-be-estimated The target fundamental frequency range is discretized into N discrete fundamental frequencies and estimated using a classifier. 1 dimension is added to represent non-voiced frames, and the final model output is N 1-dimensional probabilities. Consistent with CREPE, the team uses Gaussian smooth features as the training target and Binary Cross Entropy as the loss function: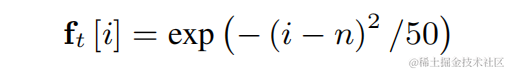
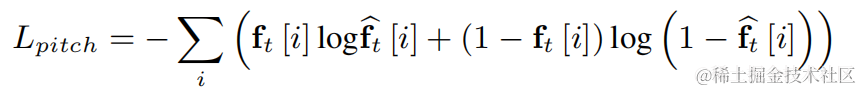
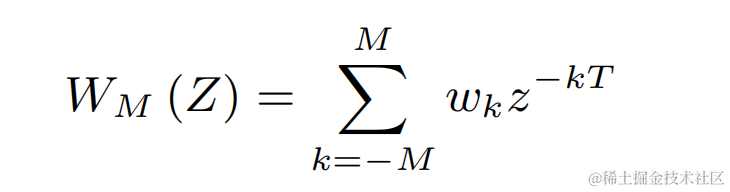
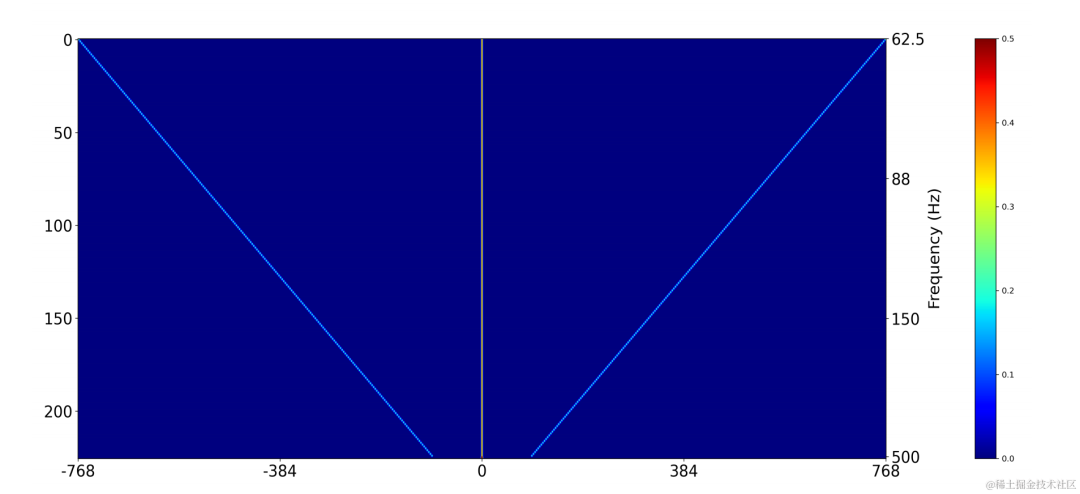
Use a two-dimensional convolution layer (Conv2D) to simultaneously calculate the filtering results of all discrete fundamental frequencies during training. The weight of the two-dimensional convolution can be expressed as the matrix in the figure below. The matrix has N 1 dimensions, and each dimension is Initialize using the above filter:
The filter result corresponding to the fundamental frequency of each frame is obtained by multiplying the one-hot label of the target fundamental frequency and the output of the two-dimensional convolution:

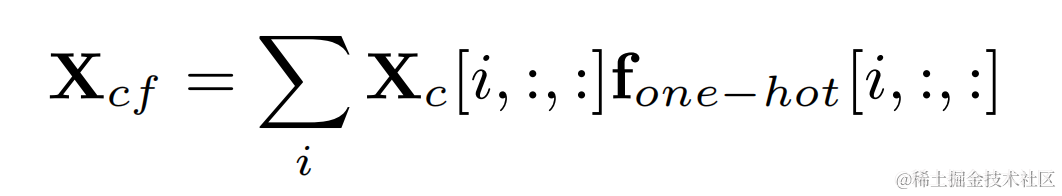
The harmonic enhanced audio will be weighted and added to the original audio, and multiplied by the sub-band gain to get the final output:
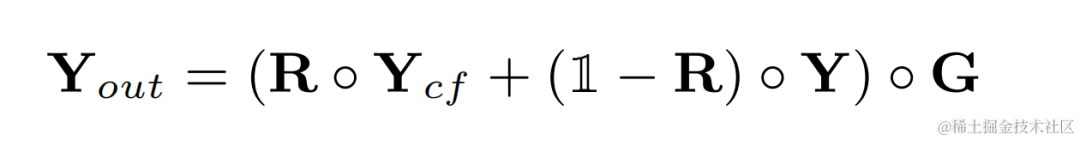
During inference, each frame only needs to calculate the filtering result of one fundamental frequency, so the calculation cost of this method is low.
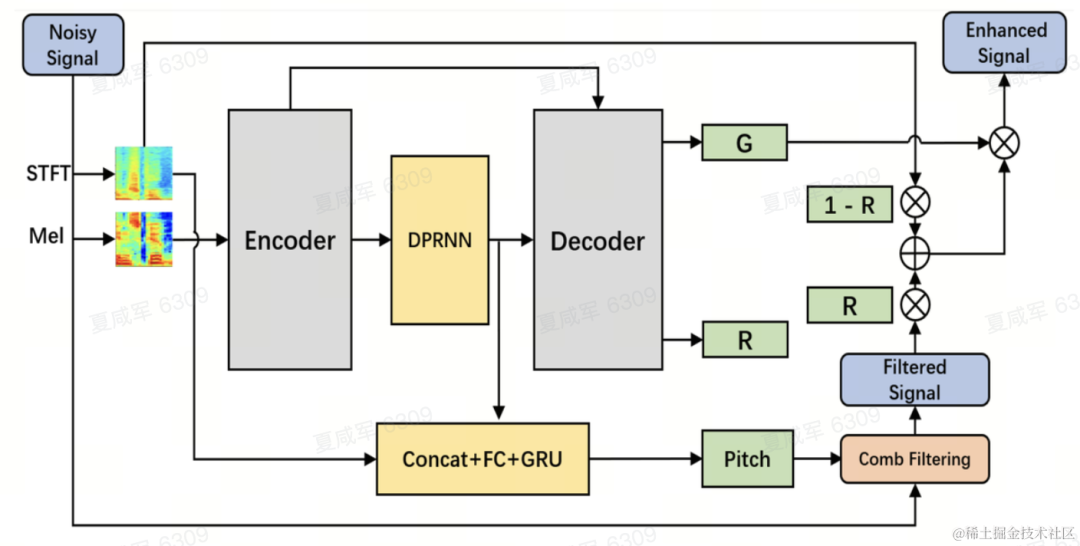
The team uses Dual-Path Convolutional Recurrent Network (DPCRN) as the backbone of the speech enhancement model, and adds fundamental frequency estimator. The Encoder and Decoder use depth-separable convolution to form a symmetric structure. The Decoder has two parallel branches that output the sub-band gain G and the weighting coefficient R respectively. The input to the fundamental frequency estimator is the output of the DPRNN module and the linear spectrum. The calculation amount of this model is about 300 M MACs, of which the comb filtering calculation amount is about 0.53M MACs.
In the experiment, the VCTK-DEMAND and DNS4 challenge datasets were used for training, and the loss functions of speech enhancement and fundamental frequency estimation were used for multi-task learning.
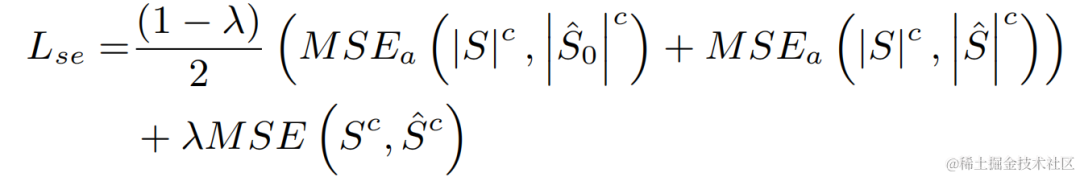
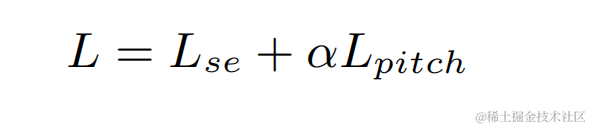
The streaming audio team combined the proposed learnable comb filtering model with comb filtering using PercepNet and DeepFilterNet. The filtering algorithm models are compared, which are called DPCRN-CF, DPCRN-PN and DPCRN-DF respectively. On the VCTK test set, the method proposed in this article shows advantages over existing methods.
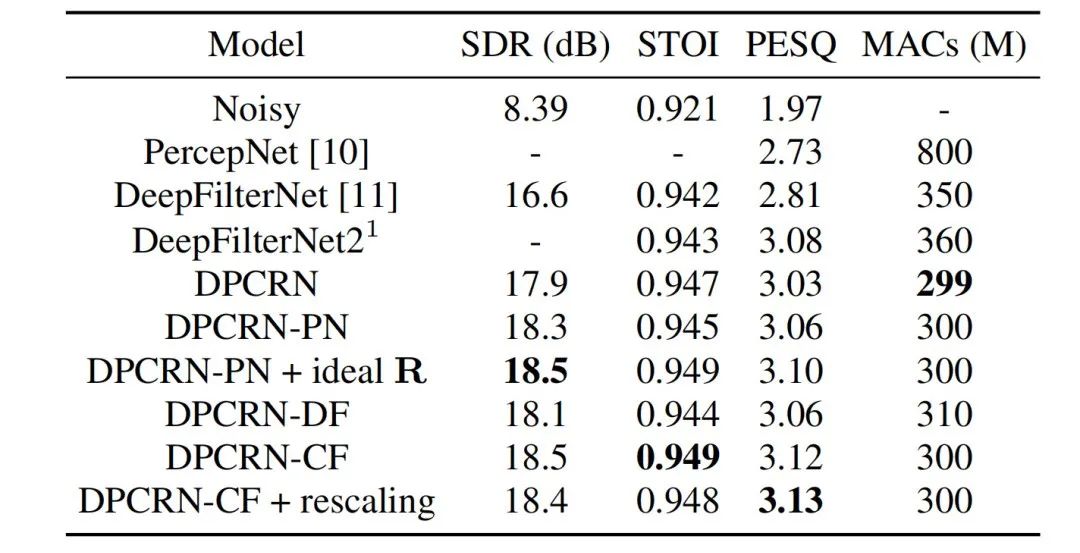
At the same time, the team conducted ablation experiments on fundamental frequency estimation and learnable filters. Experimental results show that end-to-end learning produces better results than using signal processing-based fundamental frequency estimation algorithms and filter weights.
Paper address: https://www.isca-speech .org/archive/pdfs/interspeech_2023/xu23_interspeech.pdf
In recent years, many neural network models have been used for low-bitrate speech coding tasks, however some end-to-end models failed Make full use of intra-frame related information, and the introduced quantizer has a large quantization error, resulting in low audio quality after encoding. In order to improve the quality of the end-to-end neural network audio encoder, the streaming audio team proposed an end-to-end neural speech codec, namely CBRC (Convolutional and Bidirectional Recurrent neural Codec). CBRC uses an interleaved structure of 1D-CNN (one-dimensional convolution) and Intra-BRNN (intra-frame bidirectional recurrent neural network) to more effectively utilize intra-frame correlation. In addition, the team uses the Group-wise and Beam-search Residual Vector Quantizer (GB-RVQ) in CBRC to reduce quantization noise. CBRC encodes 16kHz audio with a 20ms frame length, without additional system delay, and is suitable for real-time communication scenarios. Experimental results show that the voice quality of CBRC encoding with a bit rate of 3kbps is better than that of Opus with 12kbps.
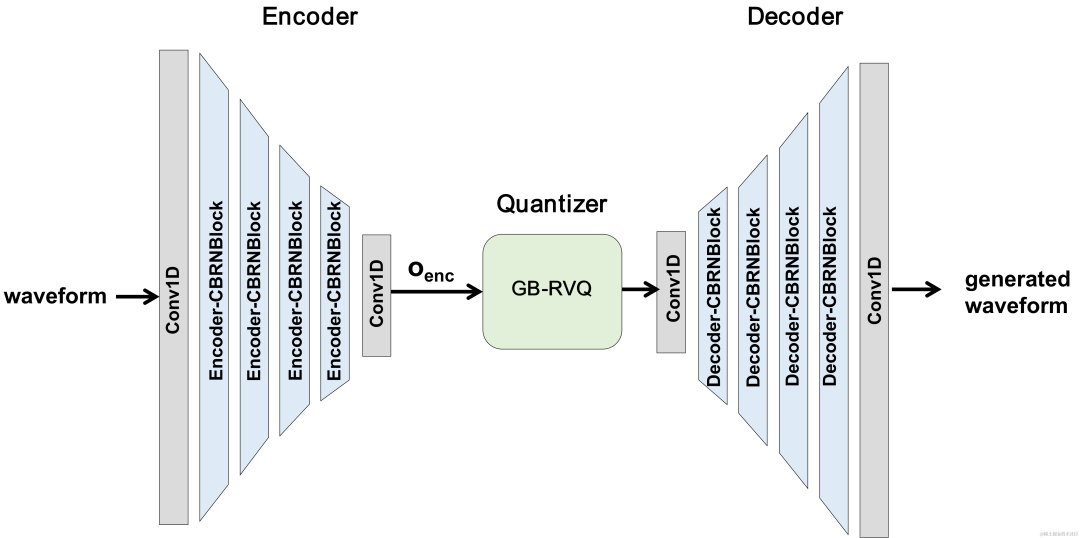
CBRC overall structure
Encoder uses 4 cascaded CBRNBlocks to extract audio features. Each CBRNBlock consists of three ResidualUnits for extracting features and a one-dimensional convolution that controls the downsampling rate. Each time the features in the Encoder are downsampled, the number of feature channels is doubled. ResidualUnit is composed of a residual convolution module and a residual bidirectional recurrent network, in which the convolution layer uses causal convolution, while the bidirectional GRU structure in Intra-BRNN only processes 20ms intra-frame audio features. The Decoder network is the mirror structure of the Encoder, using one-dimensional transposed convolution for upsampling. The interleaved structure of 1D-CNN and Intra-BRNN enables the Encoder and Decoder to make full use of the 20ms audio intra-frame correlation without introducing additional delay.
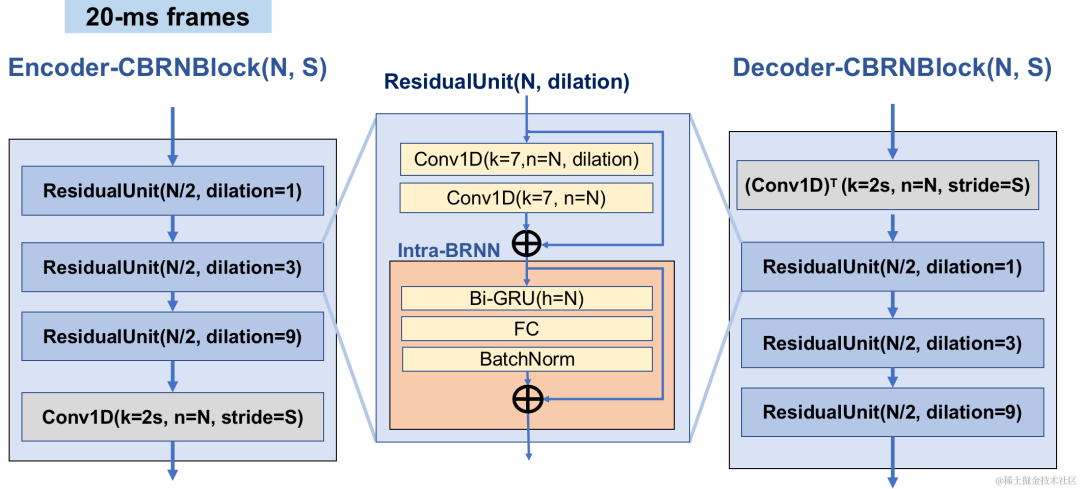
CBRNBlock structure
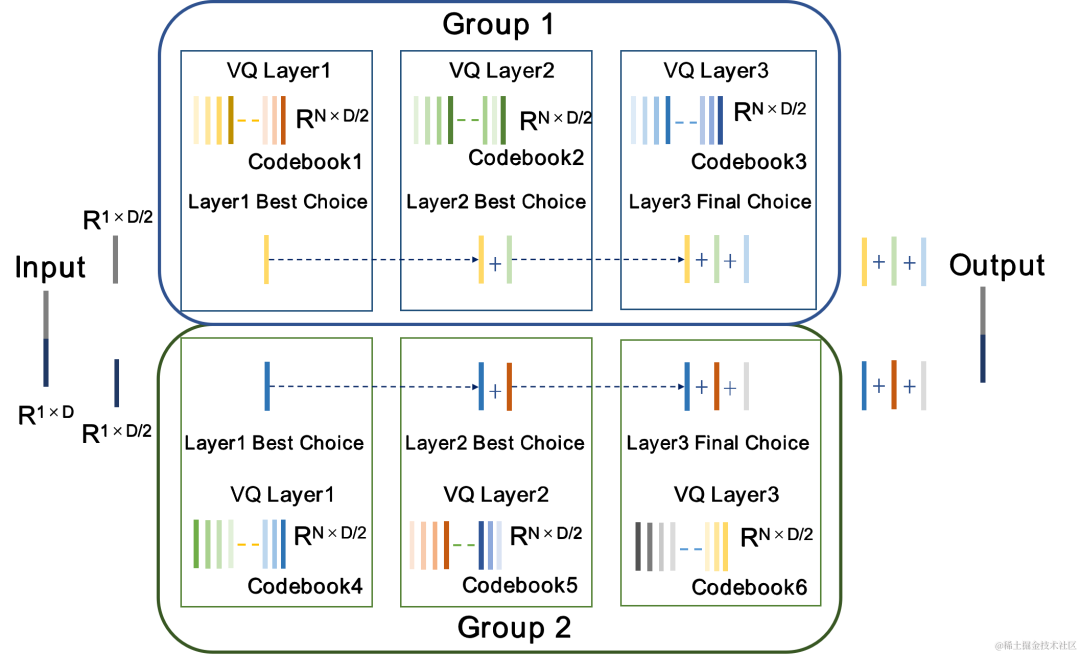
CBRC uses residual The Residual Vector Quantizer (RVQ) quantizes and compresses the output features of the encoding network to a specified bit rate. RVQ uses a multi-layer vector quantizer (VQ) cascade to compress features. Each layer of VQ quantizes the quantization residual of the previous layer of VQ, which can significantly reduce the amount of codebook parameters of a single layer of VQ at the same bit rate. The team proposed two better quantizer structures in CBRC, namely group-wise RVQ and beam-search residual vector quantizer (Beam-search RVQ).
Group-wise RVQ groups the Encoder output, and uses the grouped RVQ to independently quantify the grouped features, and then the grouped quantized output is spliced into the input Decoder. Group-wise RVQ uses group quantization to reduce the codebook parameters and computational complexity of the quantizer, while also reducing the difficulty of CBRC end-to-end training and improving the quality of CBRC encoded audio.
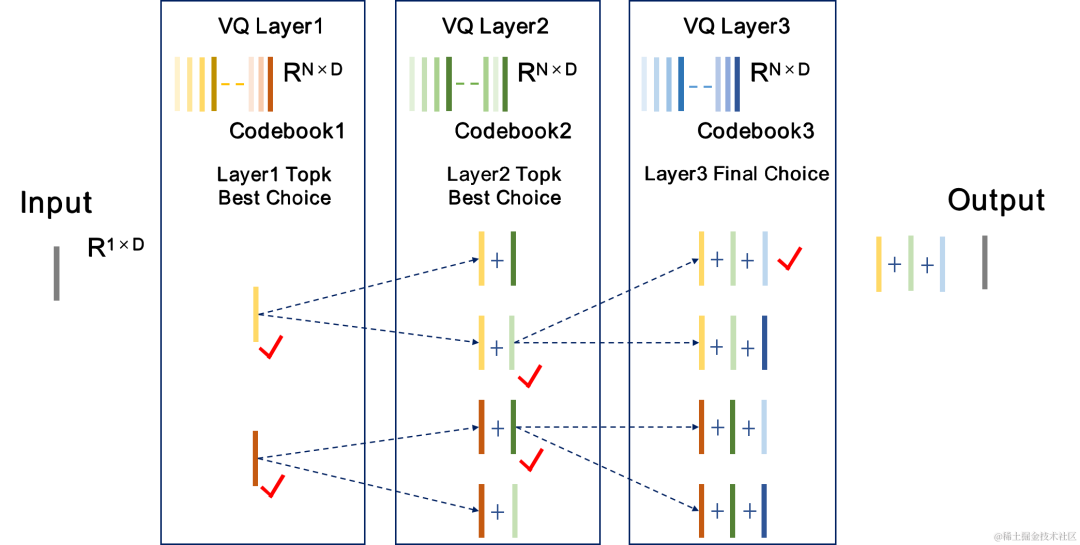
The team introduced Beam-search RVQ into the end-to-end training of the neural audio encoder, and used the Beam-search algorithm to select the codebook combination with the smallest quantization path error in RVQ to reduce the quantization error of the quantizer. The original RVQ algorithm selects the codebook with the smallest error in each layer of VQ quantization as the output, but the combination of the optimal codebooks for each layer of VQ quantization may not necessarily be the globally optimal codebook combination. The team uses Beam-search RVQ to retain k optimal quantization paths in each layer of VQ based on the minimum quantization path error criterion, enabling the selection of better codebook combinations in a larger quantization search space and reducing quantization errors.
Group Residual Vector Quantizer Group-wise RVQ |
Beam-search residual vector quantizer Beam-search RVQ |
|
|
In the experiment, 245 hours of 16kHz speech in the LibriTTS data set were used for training, and the speech amplitude was multiplied by a random gain and entered into the model. The loss function in training consists of spectrum reconstruction multi-scale loss, discriminator adversarial loss and feature loss, VQ quantization loss and perceptual loss.
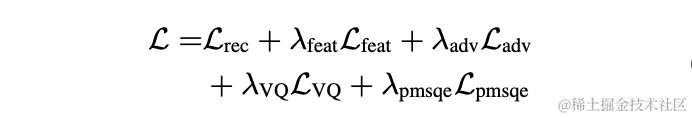
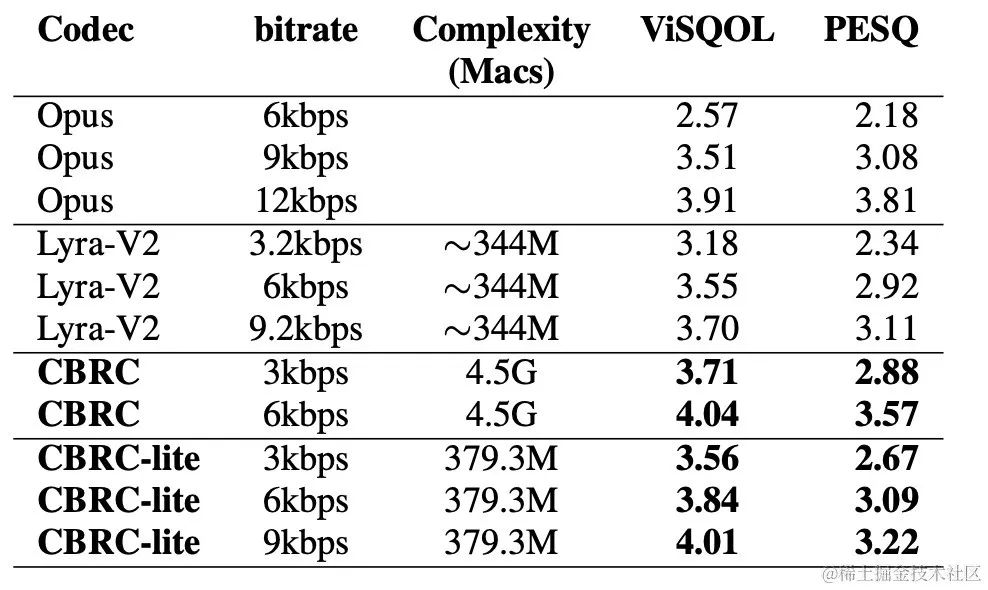
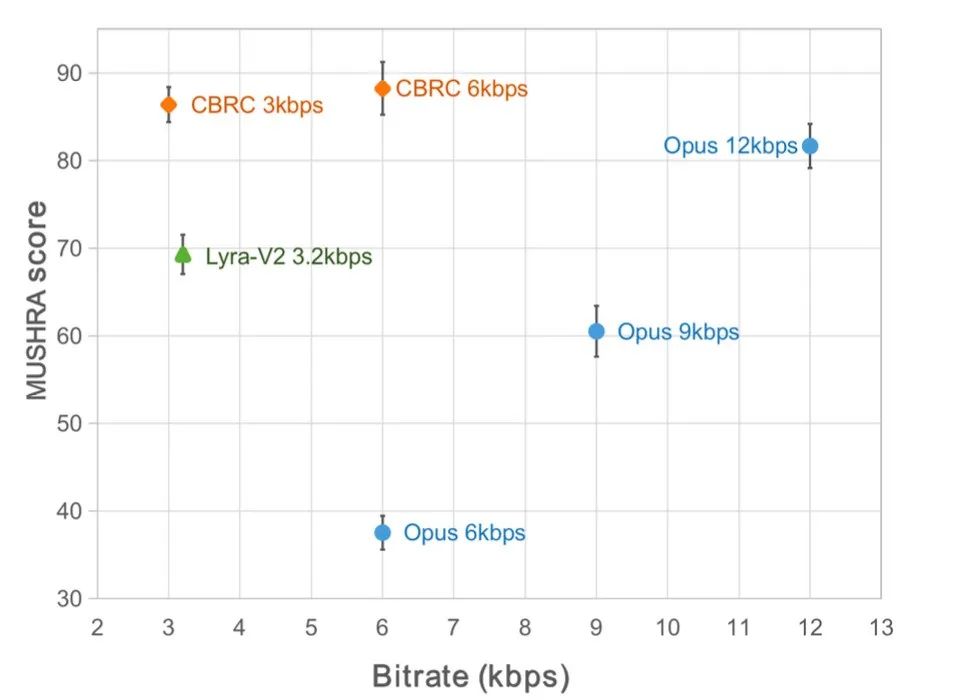
In order to evaluate the CBRC encoded speech quality, 10 multilingual audio comparison sets were constructed. This comparison set compares to other audio codecs. In order to reduce the impact of computational complexity, the team designed lightweight CBRC-lite, whose computational complexity is slightly higher than Lyra-V2. From the subjective listening comparison results, it can be seen that the voice quality of CBRC at 3kbps exceeds that of Opus at 12kbps and also exceeds Lyra-V2 at 3.2kbps, which shows the effectiveness of the proposed method. CBRC encoded audio samples are provided at https://bytedance.feishu.cn/docx/OqtjdQNhZoAbNoxMuntcErcInmb.
| #Beam-search RVQ algorithm brief process: |
|
The team designed ablation experiments for Intra-BRNN, Group-wise RVQ and Beam-search RVQ. Experimental results show that using Intra-BRNN in both Encoder and Decoder can significantly improve speech quality. In addition, the team counted the frequency of codebook usage in RVQ and calculated entropy decoding to compare codebook usage rates under different network structures. Compared with the fully convolutional structure, CBRC using Intra-BRNN increases the potential encoding bit rate from 4.94kbps to 5.13kbps. Similarly, using Group-wise RVQ and Beam-search RVQ in CBRC can significantly improve the quality of encoded speech, and compared with the computational complexity of the neural network itself, the increase in complexity brought by GB-RVQ is almost negligible.


Original audio
arctic_a0023_16k, Bytedance technical team, 5 seconds
es01_l_16k, Bytedance technical team, 10 seconds
CBRC 3kbps
##arctic_a0023_16k_CBRC_3kbps, ByteDance technical team, 5 seconds
es01_l_16k_CBRC_3kbps, ByteDance technical team, 10 seconds
##CBRC-lite 3kbps
arctic_a0023_16k_CBRC_lite_3kbps, ByteDance technical team, 5 seconds
, Bytedance technical team, 10 secondsEcho cancellation method based on two-stage progressive neural network
In order to avoid suboptimal solutions caused by independently optimizing the model of each stage, this article uses the form of cascade optimization to simultaneously optimize the coarse-stage and fine-stage, while relaxing the constraints on the coarse-stage to avoid the near-end Speech causes damage. In addition, in order to enable the model to have the ability to perceive near-end speech, the present invention introduces the VAD task for multi-task learning, and adds VAD's Loss to the loss function. The final loss function is:
whererepresents the complex spectrum of the target near-end signal, the near-end signal complex spectrum estimated by coarse-stage and fine-stage respectively; represents the near-end signal complex spectrum estimated by coarse-stage respectively. End voice active status, near end voice activity detection label;is a control scalar, mainly used to adjust the degree of attention to different stages in the training phase. The present invention restrictsto relax the constraints on the coarse-stage, and effectively avoids damage to the proximal end of the coarse-stage.
The two-stage echo cancellation system proposed by the Volcano Engine streaming audio team has also been compared with other methods. The experimental results show that the proposed system can Achieve better results than other mainstream methods.
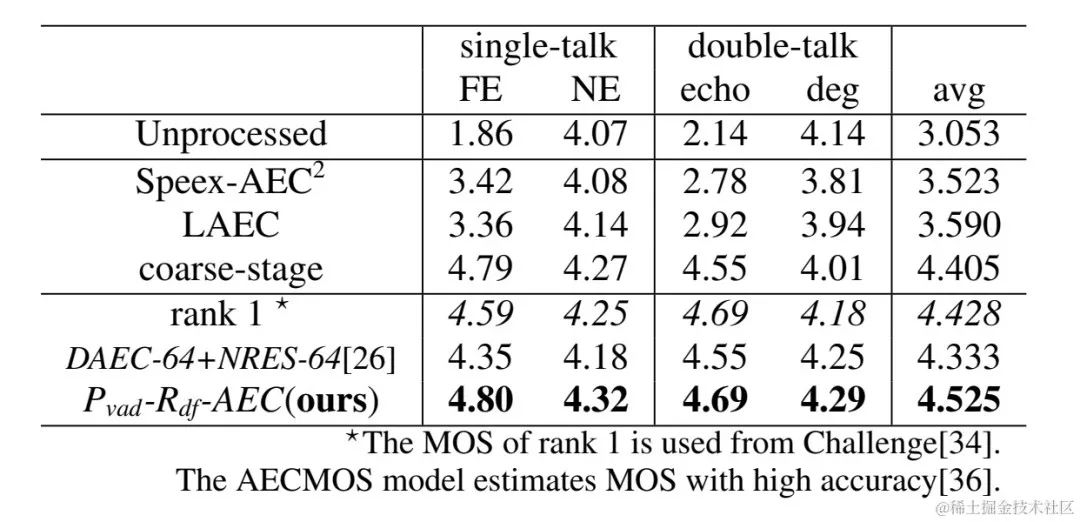
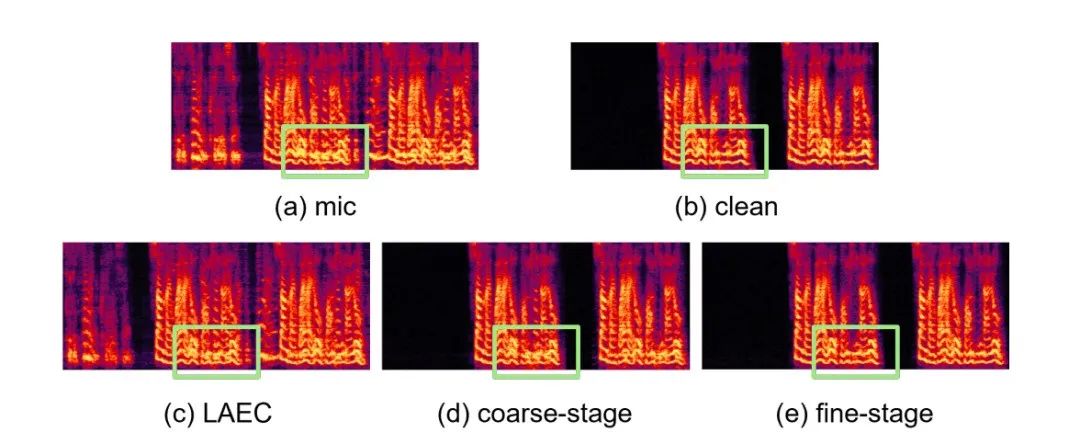
Paper address: https: //www.chimechallenge.org/current/task2/documents/Zhang_NB.pdf
In recent years, with the development of neural networks and data-driven deep learning technology, speech enhancement Technology research is gradually turning to methods based on deep learning, and more and more speech enhancement models based on deep neural networks have been proposed. However, most of these models are based on supervised learning and require a large amount of paired data for training. However, in actual scenarios, it is impossible to simultaneously capture the speech in noisy scenes and the paired clean speech tags without interference. Data simulation is usually used to collect clean speech and various noises separately, and then combine them according to a certain The signal-to-noise ratio mixes to produce noisy frequencies. This leads to a mismatch between training scenarios and actual application scenarios, and model performance declines in actual applications.
In order to better solve the above domain mismatch problem, unsupervised and self-supervised speech enhancement technology is proposed using a large amount of unlabeled data in real scenes. CHiME Challenge Track 2 aims to use unlabeled data to overcome the performance degradation problem of speech enhancement models trained on artificially generated labeled data due to the mismatch between training data and actual application scenarios. The focus of the research is how to use the target The unlabeled data of the domain and the labeled data outside the set are used to improve the enhancement results of the target domain.
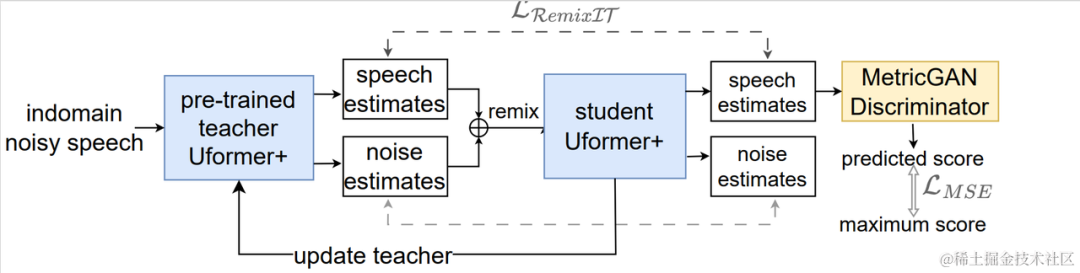
Unsupervised domain adaptive speech enhancement system flow chart
As shown in the figure above, the proposed framework is A teacher-student network. First, use voice activity detection, UNA-GAN, simulated room impulse response, dynamic noise and other technologies on the data in the domain to generate a labeled data set closest to the target domain, and pre-train the teacher noise reduction network Uformer on the labeled data set outside the domain. . Then, the student network is updated with the help of this framework on the unlabeled data in the domain, that is, the pre-trained teacher network is used to estimate clean speech and noise as pseudo labels from the noisy audio, and they are shuffled and remixed as training data input to the student network. Supervised training of student networks using pseudo-labels. The clean speech quality score generated by the student network is estimated using the pre-trained MetricGAN discriminator and the loss is calculated with the highest score to guide the student network to generate higher quality clean audio. After each training step, the parameters of the student network are updated to the teacher network with a certain weight to obtain higher quality supervised learning pseudo labels, and so on.
Uformer is improved by adding MetricGAN based on the Uformer network. Uformer is a complex real number dual-path converter network based on the Unet structure. It has two parallel branches, the amplitude spectrum branch and the complex spectrum branch. The network structure is shown in the figure below. The amplitude branch is used for the main noise suppression function and can effectively suppress most noise. The complex branch serves as an auxiliary to compensate for losses such as spectral detail and phase deviation. The main idea of MetricGAN is to use neural networks to simulate non-differentiable speech quality evaluation indicators so that they can be used in network training to reduce errors caused by inconsistent evaluation indicators during training and actual application. Here the team uses Perceptual Speech Quality Evaluation (PESQ) as the target for MetricGAN network estimation.
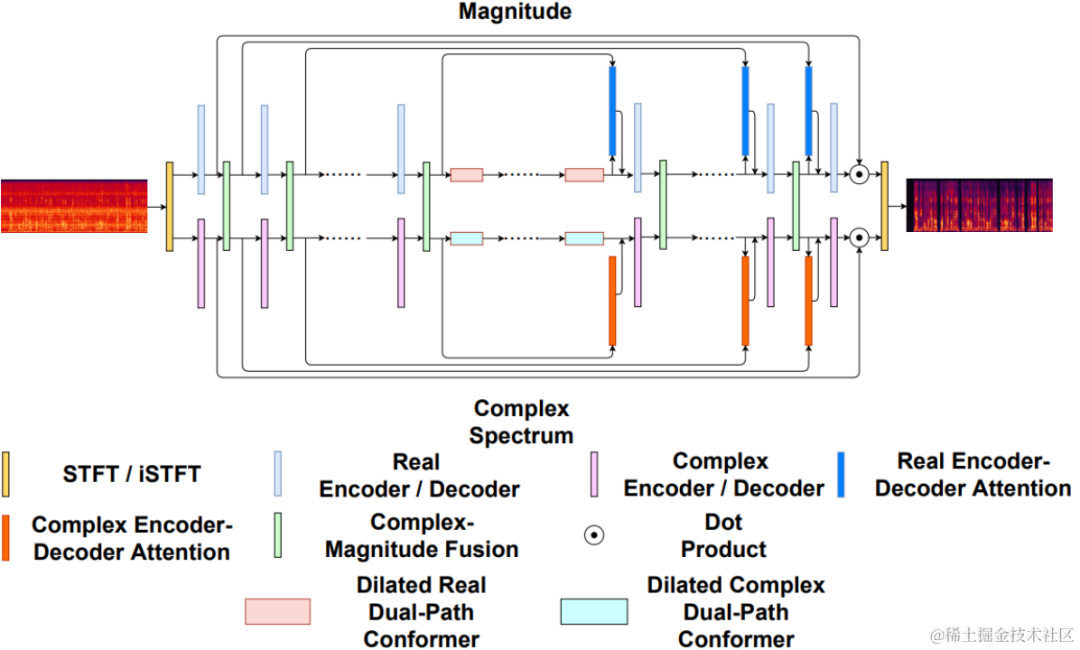
Uformer network structure diagram
RemixIT-G is a teacher-student network that is first pre-trained on labeled data outside the domain Teacher Uformer model, use this pre-trained teacher model to decode noisy audio in the domain and estimate noise and speech. Next, the order of the estimated noise and speech is scrambled within the same batch, and the noise and speech are remixed in the scrambled order into noisy audio, which is used as the input for training the student network. Noise and speech estimated by the teacher network as pseudo labels. The student network decodes the remixed noisy audio, estimates the noise and speech, computes losses with pseudo labels, and updates the student network parameters. The speech estimated by the student network is fed into the pre-trained MetricGAN discriminator to predict PESQ, and the loss is calculated with the maximum value of PESQ to update the student network parameters.
After all training data completes one iteration, the parameters of the teacher network are updated according to the following formula:, where are the parameters of the K-th round of training the teacher network,are the parameters of the K-th round of the student network. That is, the parameters of the student network are added to the teacher network with a certain weight.
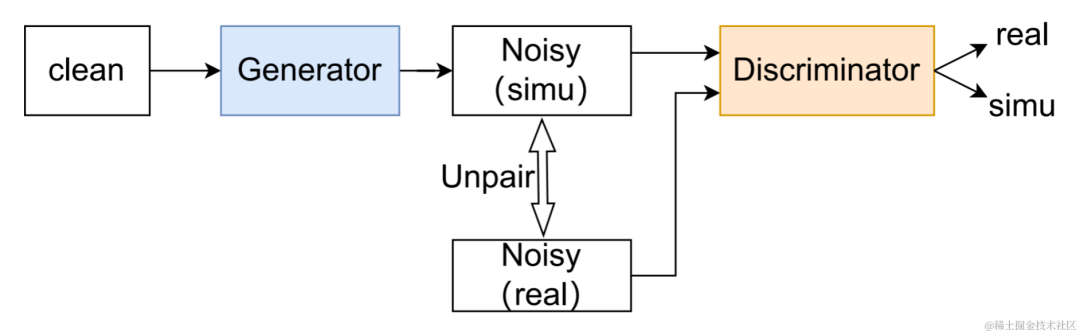
UNA-GAN structure diagram
Unsupervised noise adaptive data The augmented network UNA-GAN is a noisy audio generation model based on a generative adversarial network. Its purpose is to directly convert clean speech into noisy audio with intra-domain noise using only noisy audio within the domain when independent noise data cannot be obtained. The generator inputs clean speech and outputs simulated noisy audio. The discriminator inputs the generated noisy audio or the real noisy audio in the domain, and determines whether the input audio comes from a real scene or is generated by simulation. The discriminator mainly distinguishes sources based on the distribution of background noise, and in this process, human speech is treated as invalid information. By performing the above adversarial training process, the generator attempts to add in-domain noise directly to the input clean audio to confuse the discriminator; the discriminator tries to distinguish the source of the noisy audio. To avoid the generator adding too much noise, covering up human speech in the input audio, contrastive learning is used. Sample 256 blocks at positions corresponding to the generated noisy audio and the input clean speech. Pairings of blocks at the same position are considered positive examples, and pairs of blocks at different positions are considered negative examples. Compute cross-entropy loss using positive and negative examples.
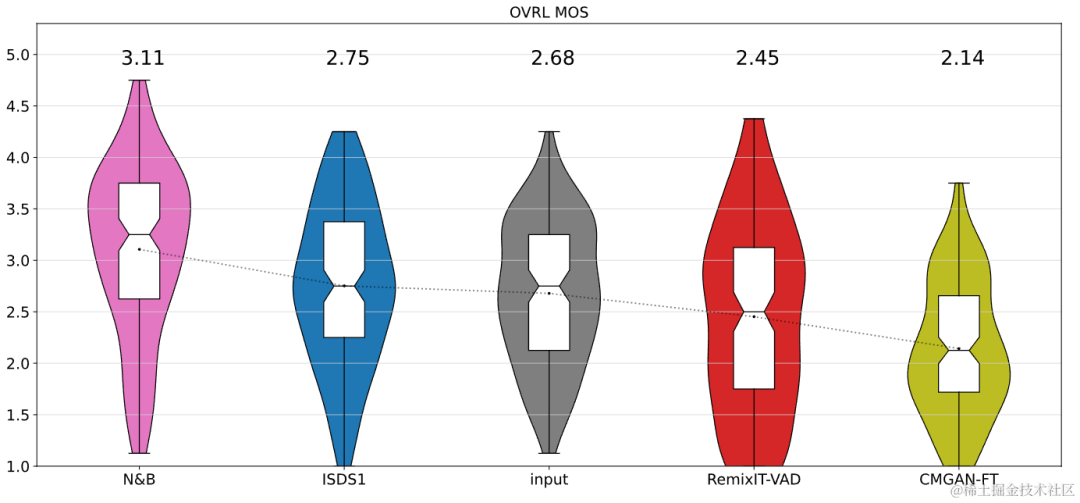
The results show that the proposed Uformer has stronger performance than the baseline Sudo rm-rf, and the data augmentation method UNA-GAN also has the ability to generate noisy frequencies in the domain. The domain adaptation framework RemixIT baseline has achieved great improvements in SI-SDR, but has poor performance on DNS-MOS. The improvement RemixIT-G proposed by the team has achieved effective improvements in both indicators at the same time, and achieved the highest subjective listening MOS score in the competition blind test set. The final listening test results are shown in the figure below.
The above introduces the Volcano Engine streaming audio team’s deep learning based on speaker-specific noise reduction, AI encoder, echo cancellation and Some solutions and effects have been made in the direction of unsupervised adaptive speech enhancement. Future scenarios still face challenges in many directions, such as how to deploy and run lightweight and low-complexity models on various terminals and achieve multi-device effect robustness. These challenges will also be the focus of subsequent research directions for the streaming audio team.
| ##Objective score |
Subjective listening experience Score |
|
|
The above is the detailed content of Interspeech 2023 | Volcano Engine Streaming Audio Technology Speech Enhancement and AI Audio Coding. For more information, please follow other related articles on the PHP Chinese website!






























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



