Re-expressed: Research motivation
Mask modeling (MIM, MAE) has proven to be a very effective self-supervised training method. However, as shown in Figure 1, MIM works relatively better for larger models. When the model is very small (such as ViT-T 5M parameters, such a model is very important for the real world), MIM may even reduce the effect of the model to a certain extent. For example, the classification effect of ViT-L trained with MAE on ImageNet is 3.3% higher than that of the model trained with ordinary supervision, but the classification effect of ViT-T trained with MAE on ImageNet is 0.6% lower than that of the model trained with ordinary supervision. In this work we proposed TinyMIM, which uses Distillation methods transfer knowledge from large models to small models. 
- ##Paper address :https://arxiv.org/pdf/2301.01296.pdf
- Code address: https://github.com/OliverRensu/TinyMIM
We systematically studied the impact of distillation objectives, data enhancement, regularization, auxiliary loss functions, etc. on distillation. In the case of strictly using only ImageNet-1K as training data (including the Teacher model also only using ImageNet-1K training) and ViT-B as the model, our method achieves the best performance currently. As shown in the picture:
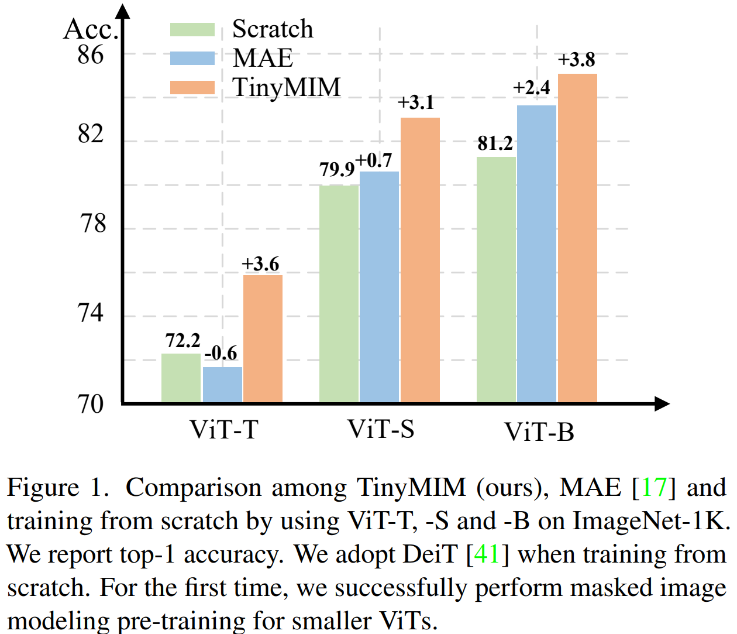
#put our The method (TinyMIM) is compared with the mask reconstruction-based method MAE, and the supervised learning method DeiT trained from scratch. MAE has significant performance improvements when the model is relatively large, but when the model is relatively small, the improvement is limited and may even harm the final effect of the model. Our method, TinyMIM, achieves substantial improvements across different model sizes.
Our contributions are as follows:
1. Distillation targets: 1) Distillation token The relationship between them is more effective than distilling class tokens or feature maps alone; 2) It is more effective to use the middle layer as the target of distillation. 2. Data enhancement and model regularization (Data and network regularization): 1) The effect of using masked images is worse; 2) The student model requires a drop path, but the teacher model does not. 3. Auxiliary losses: MIM is meaningless as an auxiliary loss function. 4. Macro distillation strategy: We found that serialized distillation (ViT-B -> ViT-S -> ViT-T) works best. 2. Method
# #
We systematically investigated the distillation goals, input images, and distillation target modules. 2.1 Factors affecting the distillation effecta. Intermediate block features and output features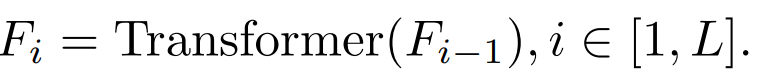
##When i=L, it refers to the characteristics of the Transformer output layer. When i
b. Attention (Attention) features and feed-forward layer (FFN) layer features
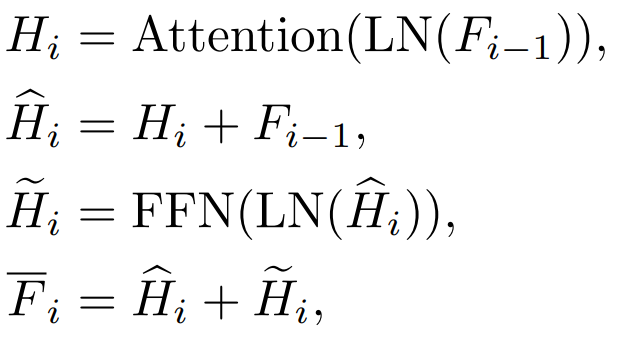
Transformer Each block has an Attention layer and a FFN layer. Different distillation layers will have different effects.
c.QKV Features
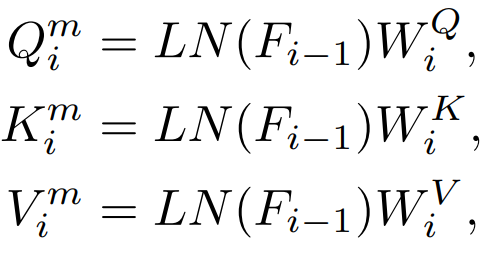
##There will be Q, K, and V features in the Attention layer. These features are used to calculate the attention mechanism. We have also investigated direct distillation of these features. 
##Q, K, V are used to calculate the attention map, and the relationship between these features can also be used as the target of knowledge distillation.
#3) Input: whether to mask
Traditional knowledge distillation is to directly input the complete image. Our method is to explore the distillation mask modeling model, so we also explore whether masked images are suitable as input for knowledge distillation.
2.2 Comparison of knowledge distillation methods1) Class Token distillation:
The simplest method is to directly distill the class token of the MAE pre-trained model similar to DeiT:
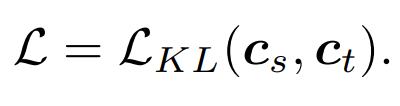
where
refers to the class token of the student model, and refers to the class token of the teacher model.
2) Feature distillation: We directly refer to feature distillation [1] as a comparison
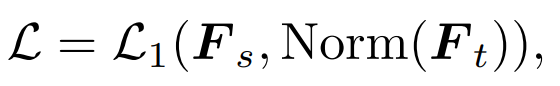
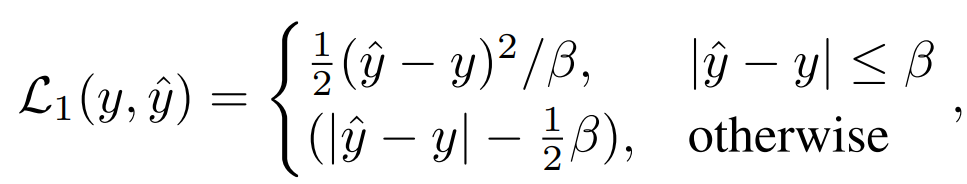
##3) Relational Distillation: We proposed also The default distillation strategy of this article
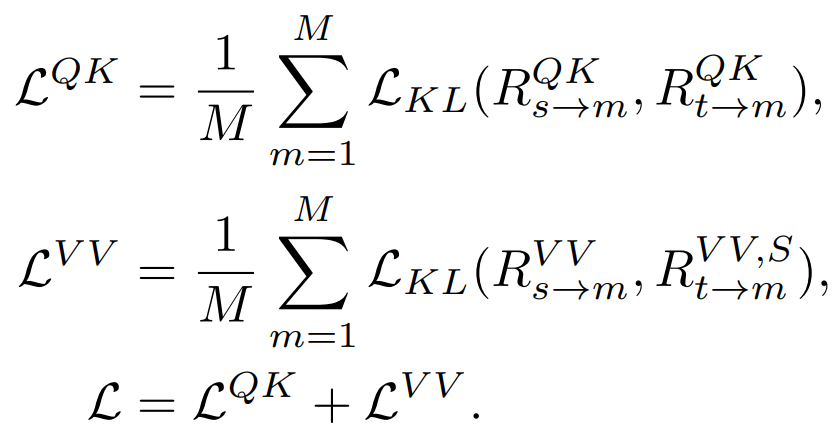
## 3. Experiment
3.1 Main experimental results
Our method is Pre-trained on ImageNet-1K, and the teacher model is also pre-trained on ImageNet-1K. We then fine-tuned our pre-trained model on downstream tasks (classification, semantic segmentation). The model performance is as shown in the figure: Our method significantly outperforms previous MAE-based methods, especially for small models. Specifically, for the ultra-small model ViT-T, our method achieves a classification accuracy of 75.8%, an improvement of 4.2 compared to the MAE baseline model. For the small model ViT-S, we achieve 83.0% classification accuracy, an improvement of 1.4 over the previous best method. For Base-sized models, our method outperforms the MAE baseline model and the previous best model by CAE 4.1 and 2.0, respectively. At the same time, we also tested the robustness of the model, as shown in the figure: 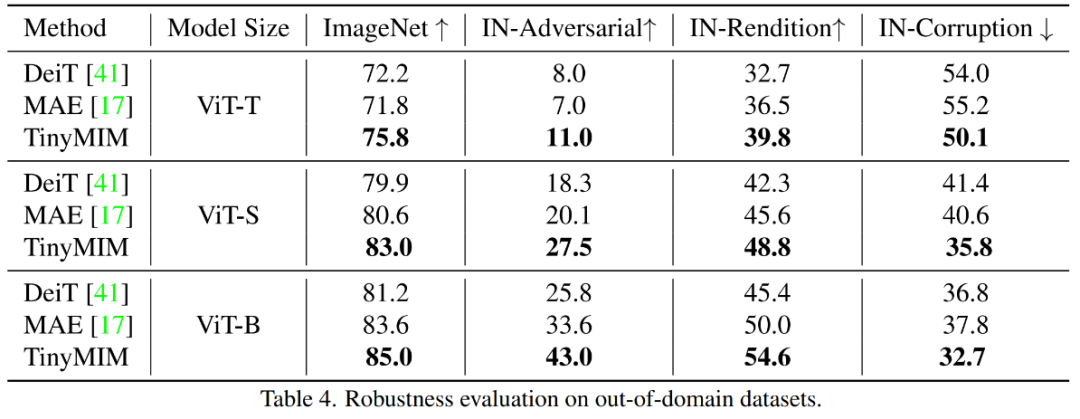
Compared with MAE-B, TinyMIM-B improved by 6.4 and 4.6 in ImageNet-A and ImageNet-R respectively. 1) Distillation of different relationships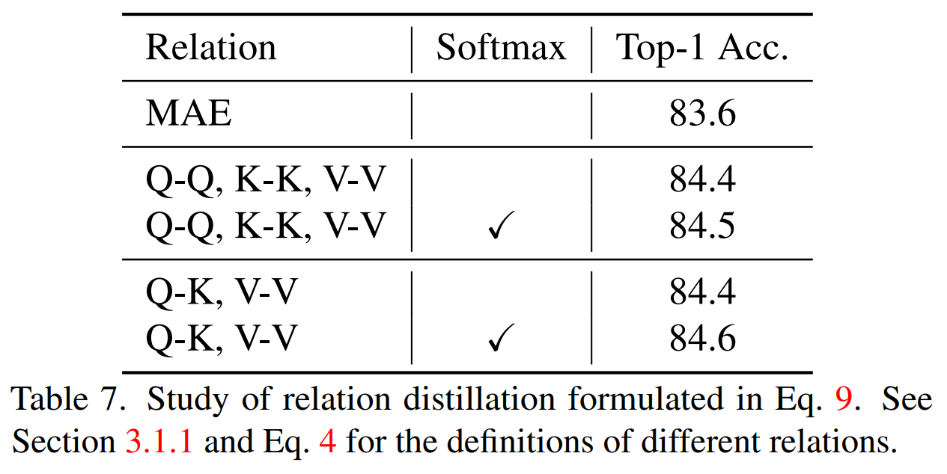
## Distills the QK, VV relationship at the same time and has Softmax when calculating the relationship Achieved the best results. 2) Different distillation strategies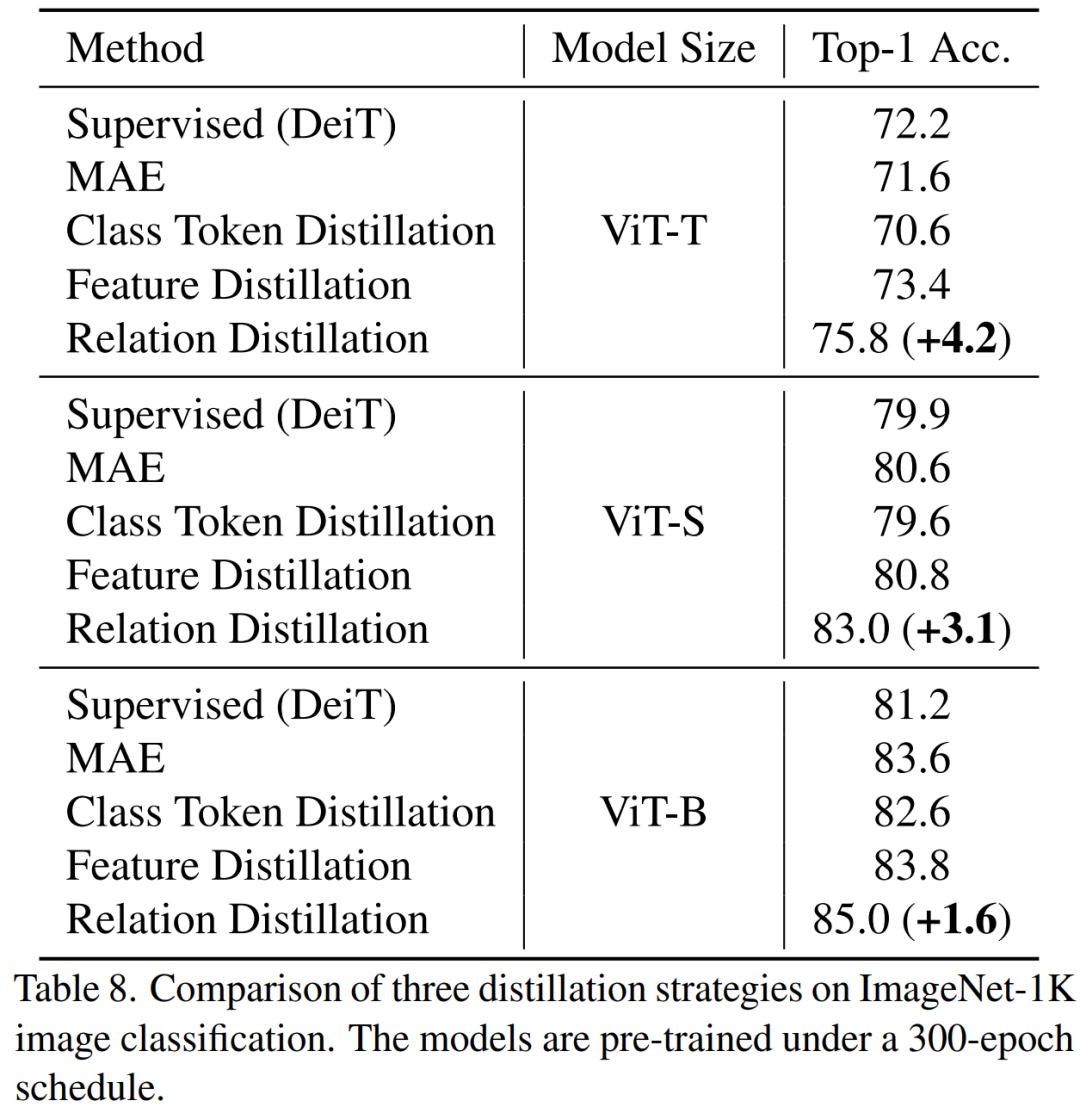
TinyMIM This method of distilling relationships achieves better results than the MAE baseline model, class token distillation, and feature map distillation, and this is true for models of various sizes. . 3) Distillation middle layer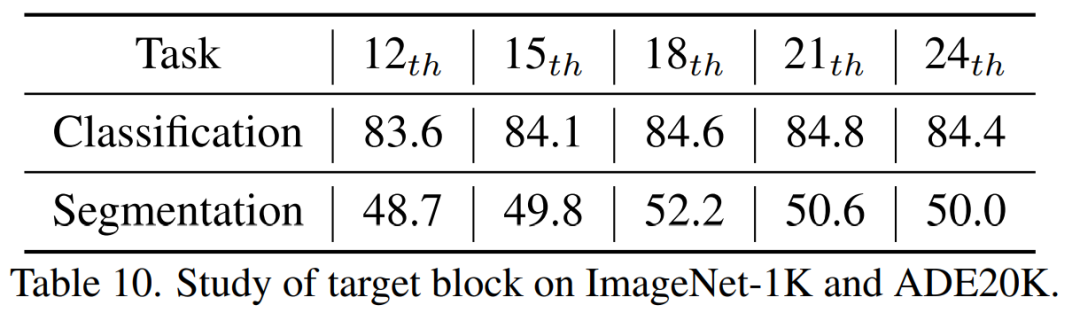
We found that the eighteenth layer of distillation achieved the best results. In this article, we proposed TinyMIM, which is The first model to successfully enable small models to benefit from mask reconstruction modeling (MIM) pre-training. Instead of adopting mask reconstruction as the task, we pre-train the small model by training the small model to simulate the relationships of the large model in a knowledge distillation manner. TinyMIM's success can be attributed to a comprehensive study of various factors that may affect TinyMIM pre-training, including distillation targets, distillation inputs, and intermediate layers. Through extensive experiments, we conclude that relation distillation is superior to feature distillation and class label distillation, etc. With its simplicity and powerful performance, we hope that our method will provide a solid foundation for future research. [1] Wei, Y., Hu, H., Xie, Z., Zhang, Z., Cao, Y., Bao, J. , ... & Guo, B. (2022). Contrastive learning rivals masked image modeling in fine-tuning via feature distillation. arXiv preprint arXiv:2205.14141.The above is the detailed content of Microsoft Research Asia launches TinyMIM: improving the performance of small ViT through knowledge distillation. For more information, please follow other related articles on the PHP Chinese website!



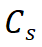
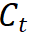





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



