


In recent years, image generation technology has made many key breakthroughs. Especially since the release of large models such as DALLE2 and Stable Diffusion, text generation image technology has gradually matured, and high-quality image generation has broad practical scenarios. However, detailed editing of existing images is still a difficult problem
On the one hand, due to the limitations oftext descriptions,existing high-quality textual image models , only text can be used to edit pictures descriptively, and for some specific effects, text is difficult to describe; on the other hand, in actual application scenarios,image refinement editing tasks often only have a small number of reference pictures ,This makes it difficult for many solutions that require a large amount of data for training to work when there is a small amount of data, especially when there is only one reference image.
Recently, researchers from NetEase Interactive Entertainment AI Lab proposed animage-to-image editing solution based on single image guidance. Given a single reference image, Transfer objects or styles in the reference image to the source image without changing the overall structure of the source image.The research paper has been accepted by ICCV 2023, and the relevant code has been open source.
Let us first look at a set of pictures to feel its effect .

Thesis renderings: The upper left corner of each set of pictures is the source picture, the lower left corner is the reference picture, and the right side is the generated result picture
The author of the paper proposed an image editing framework based onInversion-Fusion (Inversion-Fusion) - VCT (visual concept translator, visual concept converter).As shown in the figure below, the overall framework of VCT includes two processes: content-concept inversion process (Content-concept Inversion) and content-concept fusion process (Content-concept Fusion). The content-concept inversion process uses two different inversion algorithms to learn and represent the latent vectors of the structural information of the original image and the semantic information of the reference image respectively; the content-concept fusion process uses the latent vectors of the structural information and semantic information. Fusion to generate the final result.
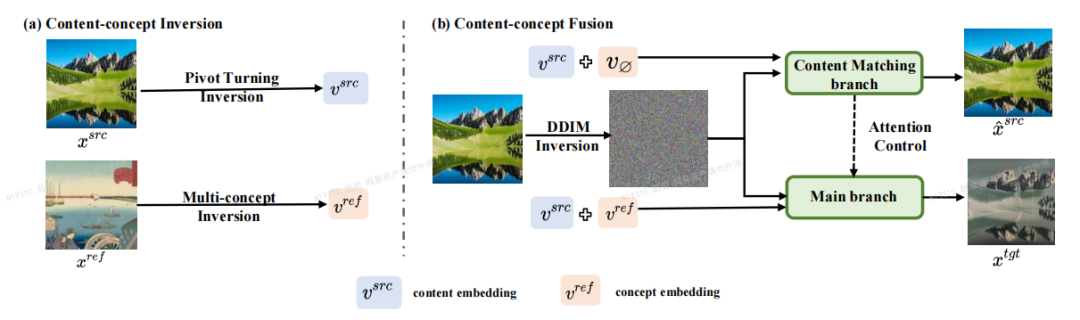
The content that needs to be rewritten is: the main framework of the paper
It is worth mentioning that in In recent years, inversion methods have been widely used in the field of Generative Adversarial Networks (GAN) and have achieved remarkable results in many image generation tasks [1]. When GAN rewrites content, the original text needs to be rewritten into Chinese. The original sentence does not need to appear. A picture can be mapped to the hidden space of the trained GAN generator, and the purpose of editing can be achieved by controlling the hidden space. This inversion scheme can fully exploit the generative power of pre-trained generative models. This study actually rewrites the content with GAN. The original text needs to be rewritten into Chinese, and the original sentence does not need to appear. It is applied to image editing tasks based on image guidance with the diffusion model as a priori.
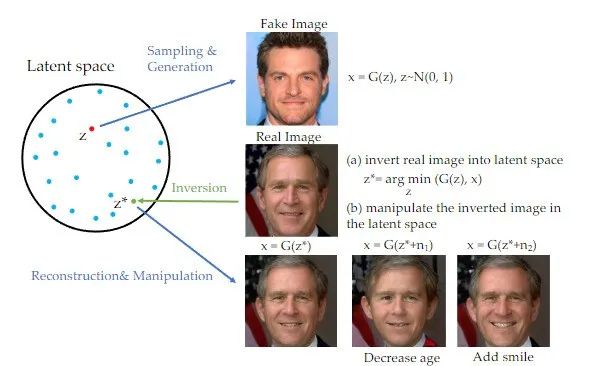
When rewriting the content, the original text needs to be rewritten into Chinese, and the original sentence does not need to appear
Based on the idea of inversion, VCT designed a two-branch diffusion process, which includes a branch B* for content reconstruction and a main branch B for editing. They start from the same noise xT obtained from DDIM Inversion【2】, an algorithm that uses diffusion models to calculate noise from images. , respectively for content reconstruction and content editing. The pre-training model used in this paper is Latent Diffusion Models (LDM). The diffusion process occurs in the latent vector space z space. The double-branch process can be expressed as:
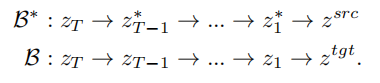
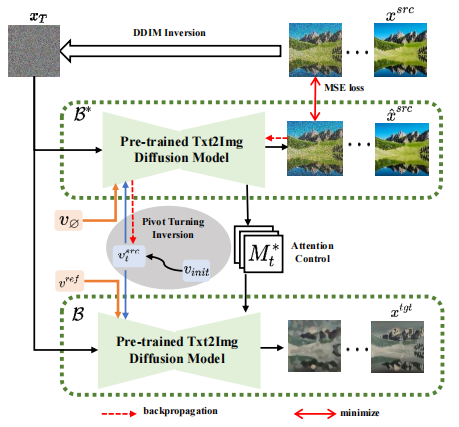
Double-branch diffusion process
Content reconstruction branch B* learns T content feature vectors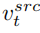 , used to restore the structure of the original image information, and pass the structural information to the editing main branch B through the soft attention control scheme. The soft attention control scheme draws on Google's prompt2prompt[3] work. The formula is:
, used to restore the structure of the original image information, and pass the structural information to the editing main branch B through the soft attention control scheme. The soft attention control scheme draws on Google's prompt2prompt[3] work. The formula is:
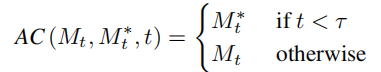
That is, when the number of steps of the diffusion model is within a certain range , replace the attention feature map of the editing main branch with the feature map of the content reconstruction branch to achieve structural control of the generated images. The editing main branch B combines the content feature vector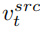 learned from the original image and the concept feature vector
learned from the original image and the concept feature vector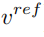 learned from the reference image to generate the edited picture.
learned from the reference image to generate the edited picture.
Noise space (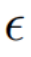 space) fusion
space) fusion
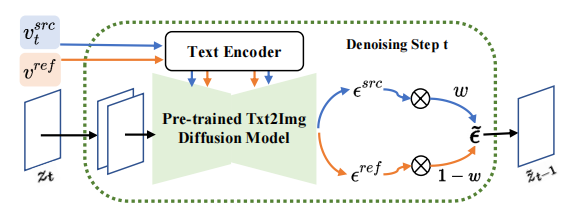
is diffusing At each step of the model, the fusion of feature vectors occurs in the noise space, which is a weighting of the noise predicted after the feature vectors are input into the diffusion model. The feature mixing of the content reconstruction branch occurs on the content feature vector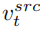 and the empty text vector, which is consistent with the form of classifier-free diffusion guidance [4]:
and the empty text vector, which is consistent with the form of classifier-free diffusion guidance [4]:
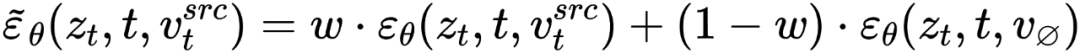
The mixture of the edit main branch is a mixture of the content feature vector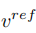 and the concept feature vector
and the concept feature vector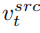 , which is
, which is
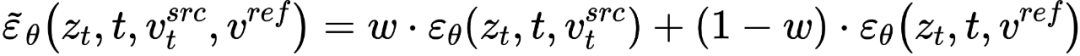
At this point, the key to the research is how to obtain the feature vector of structural information from a single source image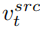 , and Obtain the feature vector of concept information
, and Obtain the feature vector of concept information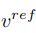 from a single reference image. The article achieves this purpose through two different inversion schemes.
from a single reference image. The article achieves this purpose through two different inversion schemes.
In order to restore the source image, the article refers to the NULL-text[5] optimization scheme and learns the feature vectors of T stages to match the fitted source image. But unlike NULL-text, which optimizes the empty text vector to fit the DDIM path, this article directly fits the estimated clean feature vector by optimizing the source image feature vector. The fitting formula is:
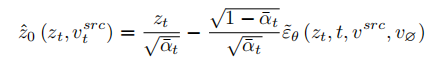
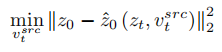
Different from learning structural information, the concept information in the reference image needs to be represented by a single highly generalized feature vector. The T stages of the diffusion model share a concept feature vector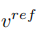 . The article optimizes the existing inversion schemes Textual Inversion [6] and DreamArtist [7]. It uses a multi-concept feature vector to represent the content of the reference image. The loss function includes a noise estimation term of the diffusion model and an estimated reconstruction loss term in the latent vector space:
. The article optimizes the existing inversion schemes Textual Inversion [6] and DreamArtist [7]. It uses a multi-concept feature vector to represent the content of the reference image. The loss function includes a noise estimation term of the diffusion model and an estimated reconstruction loss term in the latent vector space:
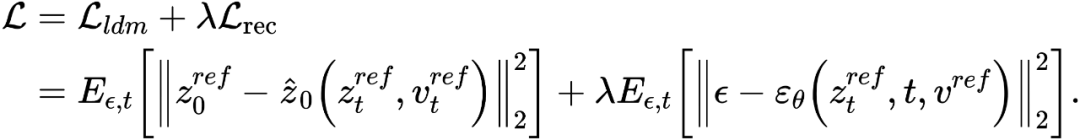
The article is on the subject replacement and stylization tasks Experiments were conducted to transform the content into the main body or style of the reference image while better maintaining the structural information of the source image.

Rewritten content: Paper on experimental effects
Compared with previous solutions, the VCT framework proposed in this article has the following advantages:
##(1)Application generalization:Compared with previous image editing tasks based on image guidance, VCT does not require a large amount of data for training, and has better generation quality and generalization. It is based on the idea of inversion and is based on high-quality Vincentian graph models pre-trained on open world data. In actual application, only one input image and one reference image are needed to achieve better image editing effects.
(2) Visual accuracy:Compared with recent text editing solutions for images, VCT uses pictures for reference guidance. Picture reference allows you to edit pictures more accurately than text descriptions. The following figure shows the comparison results between VCT and other solutions:

Comparison of the effects of the subject replacement task

Comparison effect of style transfer task
(3) No additional information is required:Comparison For some recent solutions that require adding additional control information (such as mask maps or depth maps) for guidance control, VCT directly learns structural information and semantic information from the source image and reference image for fusion generation. The following figure is Some comparison results. Among them, Paint-by-example replaces the corresponding objects with objects in the reference image by providing a mask map of the source image; Controlnet controls the generated results through line drawings, depth maps, etc.; and VCT directly draws from the source image. and reference images, learning structural information and content information to be fused into target images without additional restrictions.

Comparative effect of image editing scheme based on image guidance
NetEase Interactive Entertainment AI Laboratory was established in 2017. It is affiliated to NetEase Interactive Entertainment Business Group and is the leading artificial intelligence laboratory in the game industry. The laboratory focuses on the research and application of computer vision, speech and natural language processing, and reinforcement learning in game scenarios. It aims to improve the technical level of NetEase Interactive Entertainment’s popular games and products through AI technology. At present, this technology has been used in many popular games, such as "Fantasy Westward Journey", "Harry Potter: Magic Awakening", "Onmyoji", "Westward Journey", etc.
The above is the detailed content of Various styles of VCT guidance, all with one picture, allowing you to easily implement it. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



