

This article will introduce the microservice architecture and related components, introduce what they are and why to use the microservice architecture and these components. This article focuses on concisely expressing the overall picture of microservice architecture, so it will not go into details such as how to use components.
To understand microservices, you must first understand those that are not microservices. Usually the opposite of microservices is a monolithic application, which is an application that packages all functions into an independent unit. Going from a monolithic application to microservices does not happen overnight. It is a gradual evolutionary process. This article will take an online supermarket application as an example to illustrate this process.
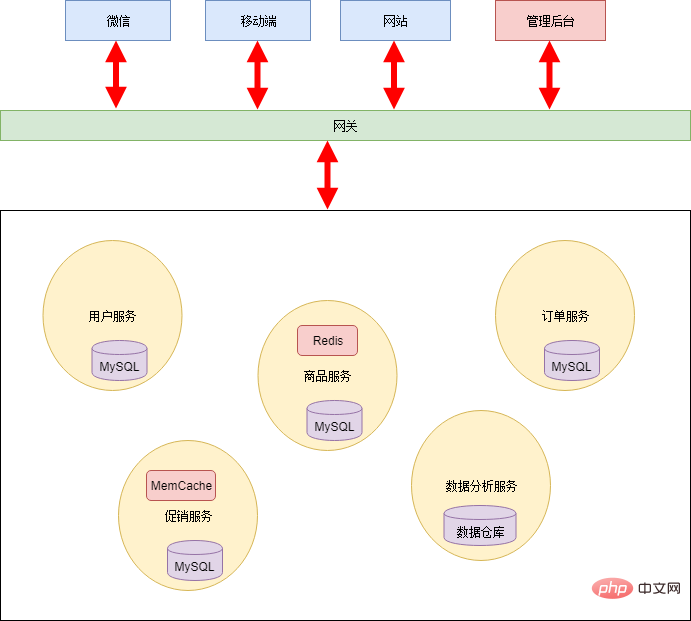
A few years ago, Xiao Ming and Xiao Pi started an online supermarket together. Xiao Ming is responsible for program development, and Xiao Pi is responsible for other matters. At that time, the Internet was not yet developed, and online supermarkets were still a blue ocean. As long as the function is implemented, you can make money at will. So their needs are very simple. They only need a website on the public network where users can browse and purchase products. They also need a management backend that can manage products, users, and order data.
Let’s sort out the function list:
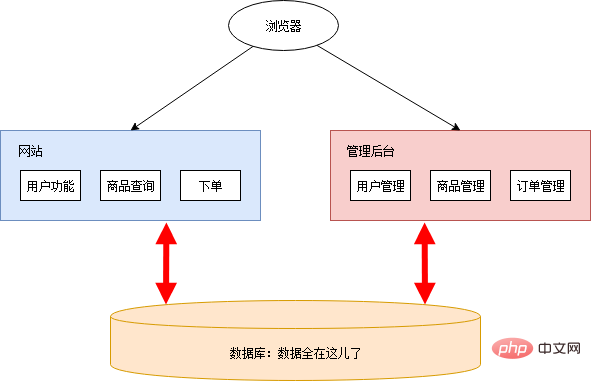
Xiao Ming waved his hand, found a cloud service to deploy, and the website was online. After being launched online, it received rave reviews and was loved by all kinds of fat houses. Xiao Ming and Xiao Pi happily began to lie down and collect the money.
The good times did not last long. Within a few days, various online supermarkets sprang up, causing great harm to Xiao Ming and Xiaopi. A strong impact.
Under the pressure of competition, Xiao Ming Xiaopi decided to carry out some marketing methods:
These activities require the support of program development. Xiao Ming roped in his classmate Xiao Hong to join the team. Xiaohong is responsible for data analysis and mobile terminal related development. Xiao Ming is responsible for the development of functions related to promotional activities.
Because the development tasks were relatively urgent, Xiao Ming and Xiao Hong did not plan the architecture of the entire system carefully. They just patted their heads and decided to put promotion management and data analysis in the management background, and WeChat and mobile APPs were built separately. After working all night for a few days, the new functions and new applications are basically completed. At this time, the architecture diagram is as follows:
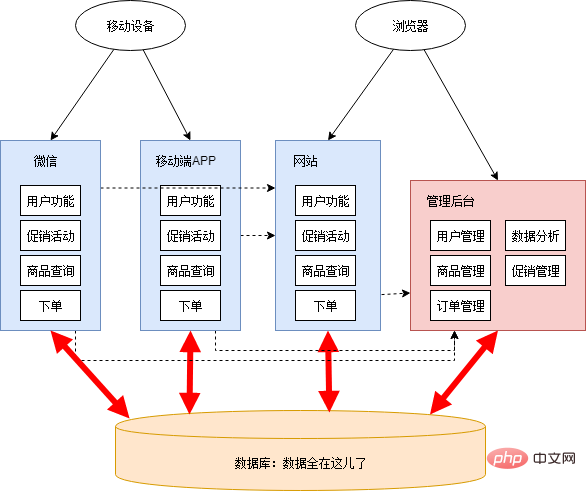
There are many unreasonable things at this stage:
Although there are many problems, the results of this stage cannot be denied: the system was quickly built according to business changes. However, urgent and heavy tasks can easily cause people to fall into partial and short-term thinking and make compromised decisions. In this kind of structure, everyone only focuses on their own one-third of an acre, lacking an overall and long-term design. If things go on like this, system construction will become increasingly difficult, and may even fall into a cycle of constant overthrow and reconstruction.
Fortunately, Xiao Ming and Xiao Hong are good young people with pursuits and ideals. After realizing the problem, Xiao Ming and Xiao Hong freed up some energy from trivial business needs, began to sort out the overall structure, and prepared to transform the problem.
To do transformation, you first need to have enough energy and resources. If your demand side (business staff, project manager, boss, etc.) is so strong in pursuing demand progress that you cannot allocate extra energy and resources, then you may not be able to do anything...
In the world of programming, the most important thing is abstract ability. The process of microservice transformation is actually an abstract process. Xiao Ming and Xiao Hong sorted out the business logic of the online supermarket, abstracted common business capabilities, and created several public services:
Each application background only needs to obtain the required data from these services, thereby deleting a large amount of redundant code, leaving only a thin control layer and front end. The architecture of this stage is as follows:
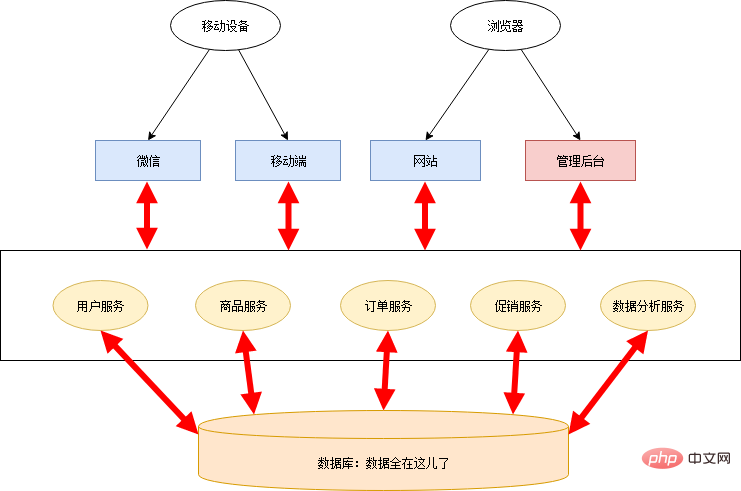
This stage only separates the services, and the database is still shared, so some shortcomings of the chimney system still exist:
If you always maintain the shared database model, the entire architecture will become more and more rigid and lose the meaning of the microservice architecture. Therefore, Xiao Ming and Xiao Hong worked together to split the database. All persistence layers are isolated from each other and are the responsibility of each service. In addition, in order to improve the real-time performance of the system, a message queue mechanism is added. The architecture is as follows:
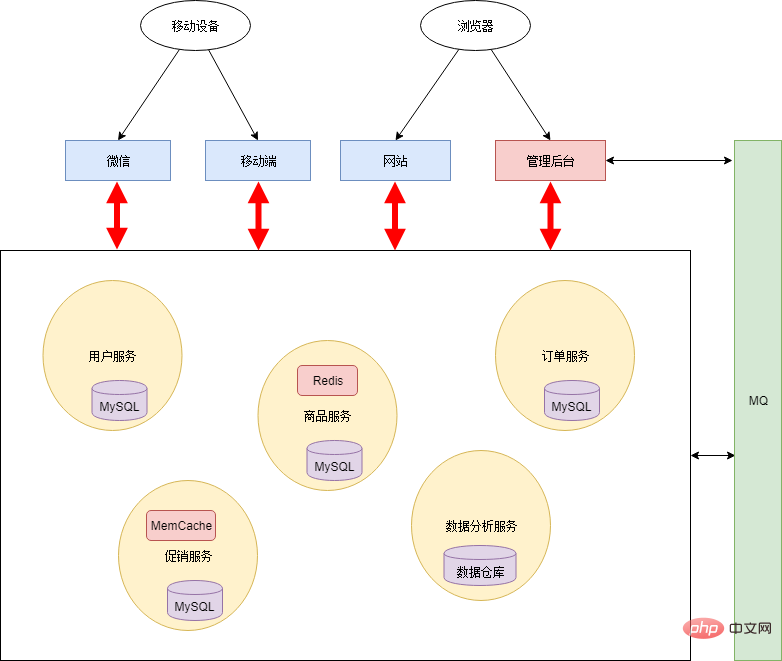
#After complete splitting, each service can use heterogeneous technologies. For example, data analysis services can use data warehouses as the persistence layer to efficiently do some statistical calculations; commodity services and promotional services are accessed more frequently, so a caching mechanism is added.
Another way to abstract public logic is to make these public logic into a public framework library. This method can reduce the performance loss of service calls. However, the management cost of this method is very high, and it is difficult to ensure the consistency of all application versions.
Database splitting also has some problems and challenges: such as the need for cross-database cascading, the granularity of data query through services, etc. But these problems can be solved through reasonable design. Overall, database splitting has more pros than cons.
The microservice architecture also has a non-technical benefit. It makes the division of labor in the entire system clearer and the responsibilities clearer. Everyone is responsible for providing better services to others. In the era of monolithic applications, public business functions often do not have clear ownership. In the end, either everyone does their own thing and everyone implements it again; or a random person (usually a more capable or enthusiastic person) implements the application he is responsible for. In the latter case, in addition to being responsible for his own application, this person is also responsible for providing these public functions to others - and this function is originally not responsible for anyone, just because he is more capable/enthusiastic. Inexplicably taking the blame (this situation is also euphemistically called "the capable do the hard work"). In the end, no one was willing to provide public functions. Over time, people in the team gradually became independent and no longer cared about the overall architecture design. Follow the official account Java Journey to receive e-books.
From this perspective, using microservice architecture also requires corresponding adjustments to the organizational structure. Therefore, microservice transformation requires the support of managers.
After the transformation was completed, Xiao Ming and Xiao Hong clearly divided their respective roles. The two of them were very satisfied, everything was as beautiful and perfect as Maxwell's equations.
However...
Spring is here, everything is recovering, and it’s the annual shopping carnival again. Seeing the number of daily orders rising steadily, Xiaopi, Xiaoming and Xiaohong smiled happily. Unfortunately, the good times did not last long. Extreme joy brought sorrow. Suddenly, the system crashed.
In the past, troubleshooting for single applications usually involved looking at logs, studying error messages and call stacks. In the microservice architecture, the entire application is dispersed into multiple services, making it very difficult to locate the fault point. Xiao Ming checked the logs one by one and manually called each service. After more than ten minutes of searching, Xiao Ming finally located the fault point: the promotion service stopped responding due to the large number of requests it received. Other services directly or indirectly call the promotion service, so they also go down. In a microservice architecture, a service failure may produce an avalanche effect, causing the entire system to fail. In fact, before the holiday, Xiao Ming and Xiao Hong conducted a request volume assessment. According to estimates, the server resources are sufficient to support the number of requests during the holiday, so there must be something wrong. However, the situation was urgent, and every minute and every second passed was wasted money. Therefore, Xiao Ming had no time to troubleshoot the problem. He immediately made a decision to create several new virtual machines on the cloud, and then deployed new promotional services one by one. node. After a few minutes of operation, the system finally returned to normal. It is estimated that hundreds of thousands of sales were lost during the entire failure period, and the three people's hearts were bleeding...
Afterwards, Xiao Ming simply wrote a log analysis tool (the volume was so large that it was almost impossible to open it with a text editor and could not be seen with the naked eye), and counted the access logs of the promotional service, and found that during the failure, the product Due to code issues, the service will initiate a large number of requests for promotional services in certain scenarios. This problem is not complicated. Xiao Ming fixed this bug worth hundreds of thousands with a flick of his finger.
The problem has been solved, but no one can guarantee that other similar problems will not occur again. Although the microservice architecture seems to be perfect in logical design, it is like a gorgeous palace built of building blocks and cannot withstand the wind and waves. Although the microservice architecture solves old problems, it also introduces new ones:
Xiao Ming and Xiao Hong learned from the experience and determined to solve these problems. Troubleshooting generally involves two aspects: on the one hand, we try to reduce the probability of a fault, and on the other hand, we reduce the impact of the fault.
In high-concurrency distributed scenarios, failures often occur suddenly It exploded like an avalanche. Therefore, a complete monitoring system must be established to detect signs of failure as much as possible.
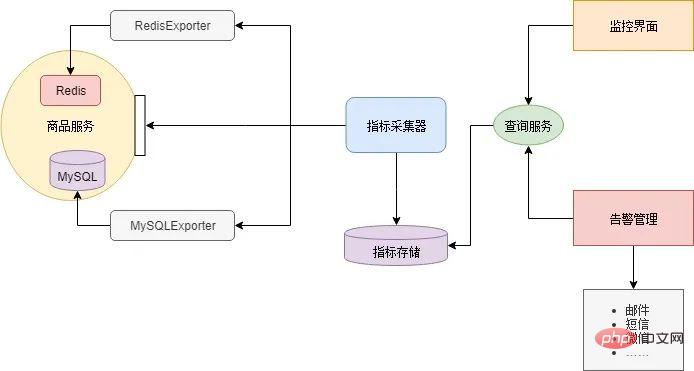
There are many components in the microservice architecture, and each component needs to monitor different indicators. For example, the Redis cache generally monitors the memory occupied value and network traffic, the database monitors the number of connections and disk space, and the business service monitors the number of concurrencies, response delays, error rates, etc. Therefore, it is unrealistic to build a large and comprehensive monitoring system to monitor each component, and the scalability will be very poor. The general approach is to let each component provide an interface (metrics interface) for reporting its current status. The data format output by this interface should be consistent. Then deploy an indicator collector component to regularly obtain and maintain component status from these interfaces, while providing query services. Finally, a UI is needed to query various indicators from the indicator collector, draw a monitoring interface, or issue alarms based on thresholds.
Most components do not need to be developed by yourself, there are open source components on the Internet. Xiao Ming downloaded RedisExporter and MySQLExporter. These two components provide indicator interfaces for Redis cache and MySQL database respectively. Microservices implement customized indicator interfaces based on the business logic of each service. Then Xiao Ming uses Prometheus as the indicator collector, and Grafana configures the monitoring interface and email alerts. Such a microservice monitoring system is built:
In the micro service Under the service architecture, a user's request often involves multiple internal service calls. In order to facilitate problem locating, it is necessary to be able to record how many service calls are generated within the microservice when each user requests it, and their calling relationships. This is called link tracking.
Let’s use a link tracking example in the Istio document to see the effect:
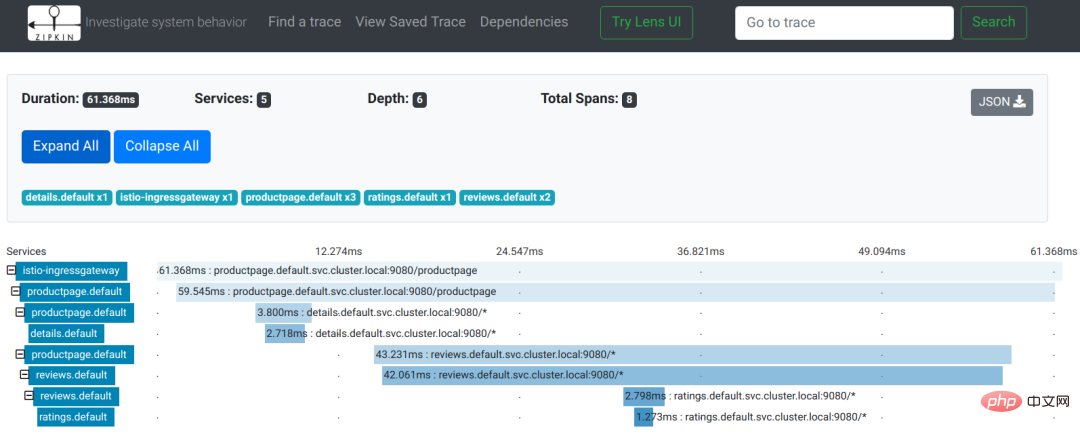
The picture comes from the Istio document
As you can see from the picture, this is a user request to access the productpage page. During the request process, the productpage service sequentially calls the interfaces of the details and reviews services. The reviews service calls the ratings interface during the response process. The record of the entire link tracking is a tree:
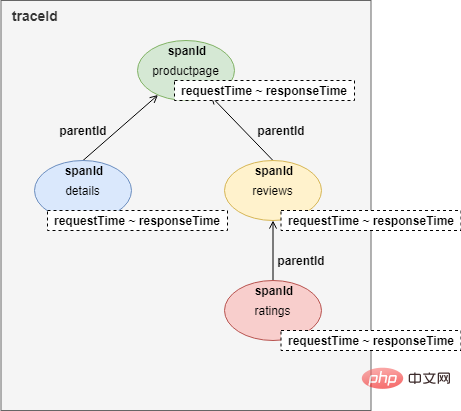
#To implement link tracking, each service call will record at least four records in the HTTP HEADERS Data:
In addition, you also need to call components for log collection and storage, as well as UI components for displaying link calls.
The above is just a minimalist explanation. For details about the theoretical basis of link tracking, please see Google’s Dapper
After understanding the theoretical basis, Xiao Ming chose Zipkin, an open source implementation of Dapper. Then with a flick of his finger, I wrote an HTTP request interceptor, generated these data and injected them into HEADERS for each HTTP request, and at the same time sent the call log asynchronously to Zipkin's log collector. An additional mention here is that the HTTP request interceptor can be implemented in the code of the microservice, or it can be implemented using a network proxy component (but in this case, each microservice needs to add a layer of proxy).
Link tracking can only locate which service has a problem and cannot provide specific error information. The ability to find specific error information needs to be provided by the log analysis component.
The log analysis component should have been widely used before the rise of microservices. Even with a single application architecture, when the number of accesses increases or the size of the server increases, the size of the log files will expand to the point where it is difficult to access with a text editor. What is worse is that they are scattered across multiple servers. To troubleshoot a problem, you need to log in to each server to obtain the log files, and search for the desired log information one by one (and opening and searching are very slow).
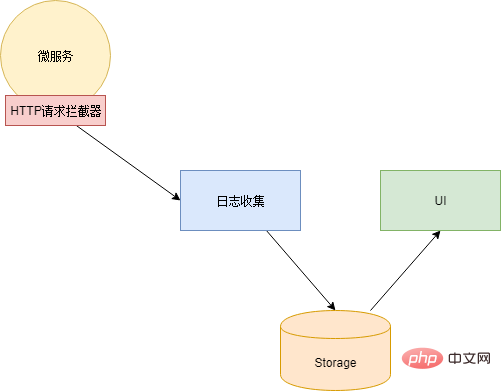
Therefore, when the application scale becomes larger, we need a log "Search engine". So that you can accurately find the log you want. In addition, the data source side also needs components to collect logs and UI components to display results:
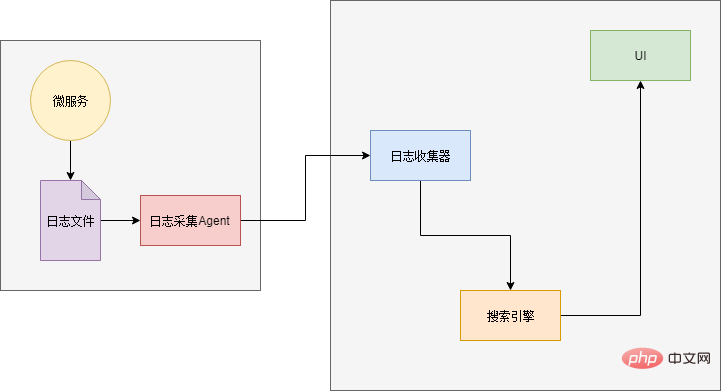
Xiao Ming investigated and used the famous ELK log analysis component . ELK is the abbreviation of three components: Elasticsearch, Logstash and Kibana.
Finally there is a small problem is how to send logs to Logstash. One solution is to directly call the Logstash interface to send the log when outputting the log. In this way, the code needs to be modified again (Hey, why use "and")... So Xiao Ming chose another solution: the logs are still output to files, and an Agent is deployed in each service to scan the log files and then output them to Logstash. .
Advertising break:Follow the public account:Java Study Guide, Get more technical articles.
After splitting into microservices, a large number of services and interfaces appeared, making the entire calling relationship messy . Often during the development process, while writing and writing, I suddenly can’t remember which service should be called for a certain data. Or it was written crookedly, calling a service that shouldn't be called, and a read-only function ended up modifying the data...
In order to deal with these situations, the call of microservices needs a checker, that is, a gateway. Add a layer of gateway between the caller and the callee, and perform permission verification every time it is called. In addition, the gateway can also be used as a platform to provide service interface documents.
One problem with using a gateway is to decide how granular it should be used: the most coarse-grained solution is a gateway for the entire microservice. The outside of the microservice accesses the microservice through the gateway, and the inside of the microservice calls directly; The granularity is that all calls, whether they are internal calls to the microservice or calls from the outside, must go through the gateway. A compromise solution is to divide microservices into several areas according to business areas, call them directly within the area, and call them through the gateway.
Since the number of services in the entire online supermarket is not particularly large, Xiao Ming adopted the coarsest-grained solution:
The previous components are all designed to reduce the possibility of failure. However, failures will always occur, so another aspect that needs to be studied is how to reduce the impact of failures.
The crudest (and most commonly used) fault handling strategy is redundancy. Generally speaking, a service will deploy multiple instances, so that it can share the pressure and improve performance, and secondly, even if one instance fails, other instances can still respond.
One problem with redundancy is how many redundancies are used? There is no definite answer to this question on the timeline. Depending on the service function and time period, different numbers of instances are required. For example, on weekdays, 4 instances may be enough; during promotions, when traffic increases significantly, 40 instances may be needed. Therefore, the amount of redundancy is not a fixed value, but can be adjusted in real time as needed. Generally speaking, the operation of adding a new instance is:
The solution to this problem is automatic service registration and discovery. First, you need to deploy a service discovery service that provides address information for all registered services. DNS can also be regarded as a service discovery service. Then each application service automatically registers itself with the service discovery service when it starts. And after the application service is started, the address list of each application service will be synchronized from the service discovery service to the local in real time (regularly). The service discovery service will also regularly check the health status of application services and remove unhealthy instance addresses. In this way, when adding an instance, you only need to deploy the new instance. When the instance goes offline, you can directly shut down the service. Service discovery will automatically check the increase or decrease of service instances.
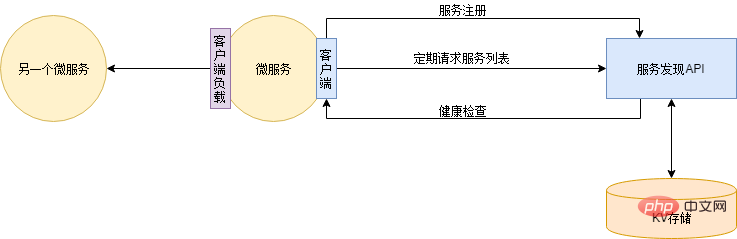
There are many components to choose from for service discovery, such as Zookeeper, Eureka, Consul, Etcd, etc. However, Xiao Ming felt that he was good at it and wanted to show off his skills, so he wrote one based on Redis...
When a service stops responding for various reasons, the caller usually Wait for a while, then time out or receive an error return. If the calling link is relatively long, requests may accumulate, and the entire link takes up a lot of resources and waits for downstream responses. Therefore, when accessing a service multiple times fails, the circuit breaker should be broken, marking the service as having stopped working, and returning an error directly. Wait until the service returns to normal before re-establishing the connection.
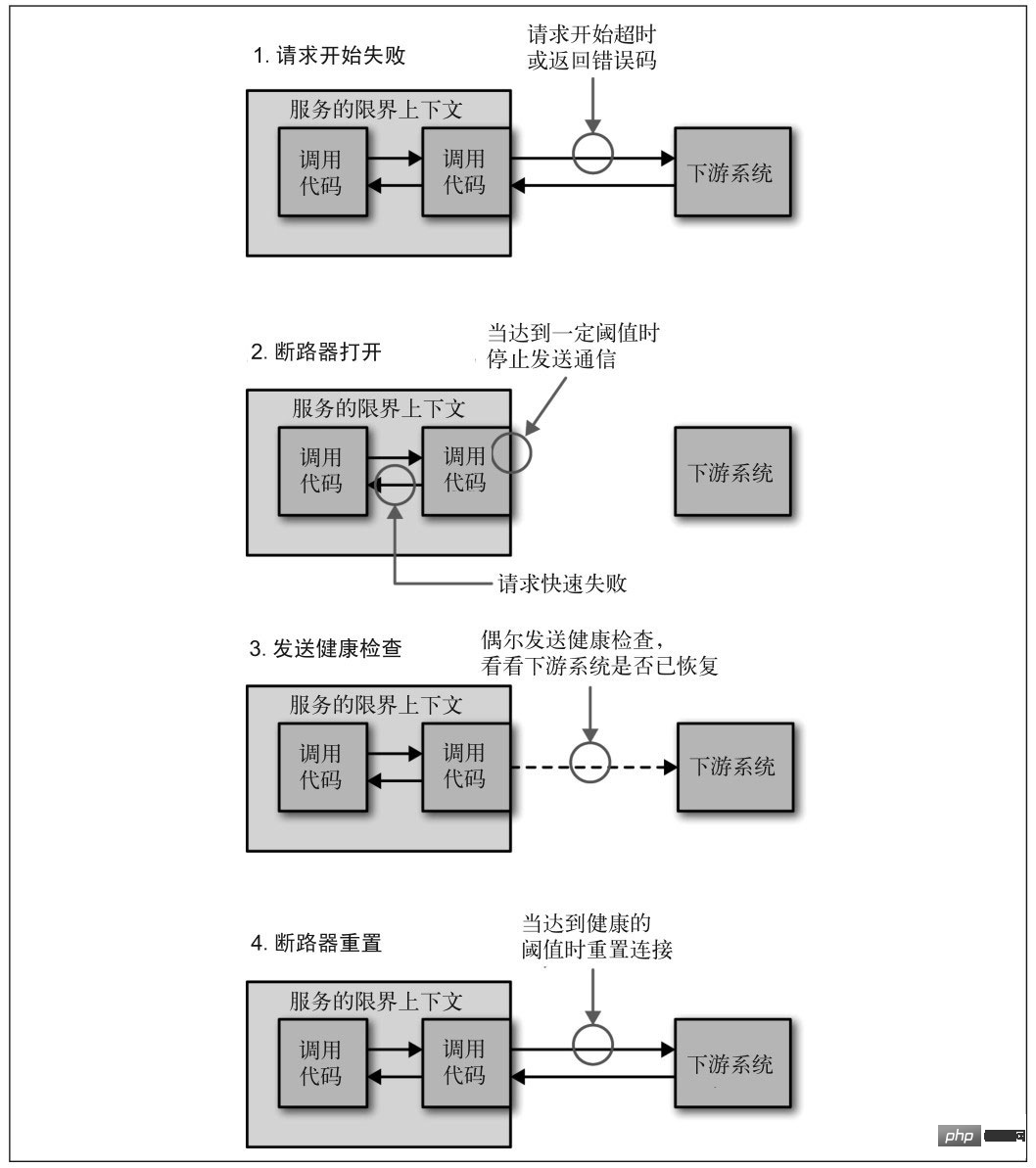
Picture from "Microservice Design"
When the downstream service stops working, if the service is not the core business, the upstream service should be downgraded to ensure that the core business is not interrupted. For example, the online supermarket ordering interface has a function to collect orders for recommended products. When the recommendation module is down, the ordering function cannot be down at the same time. You only need to temporarily turn off the recommendation function.
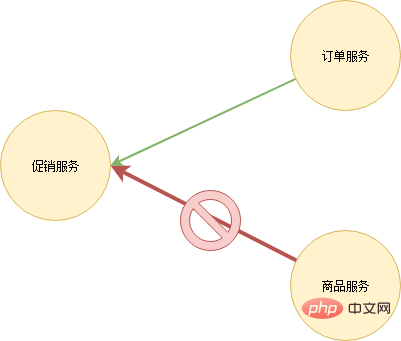
After a service hangs up, the upstream service or user will usually retry the access habitually. This means that once the service returns to normal, it is likely to hang up immediately due to excessive network traffic and repeat sit-ups in the coffin. Therefore the service needs to be able to protect itself - limit traffic. There are many current limiting strategies. The simplest one is to discard excess requests when there are too many requests per unit time. In addition, partition current limiting can also be considered. Only deny requests from services that generate a large number of requests. For example, both the product service and the order service need to access the promotion service. The product service initiates a large number of requests due to code problems. The promotion service only limits requests from the product service, and requests from the order service respond normally.
Under the microservice architecture, testing is divided into three levels:
The ease of implementation of the three tests increases from top to bottom, but the test effect decreases. End-to-end testing is the most time-consuming and labor-intensive, but after passing the test we have the most confidence in the system. Unit testing is the easiest to implement and the most efficient, but there is no guarantee that the entire system will be problem-free after testing.
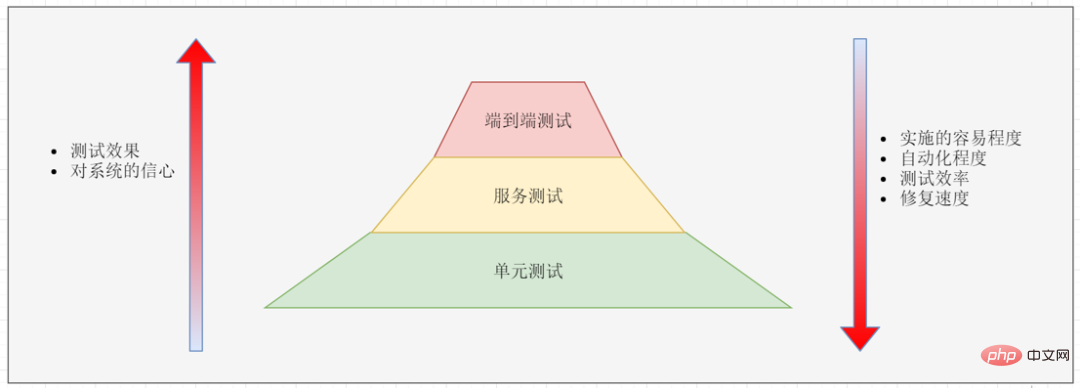
Because end-to-end testing is difficult to implement, end-to-end testing is generally only done on core functions. Once an end-to-end test fails, it needs to be broken down into unit tests: then the reason for the failure is analyzed, and then unit tests are written to reproduce the problem so that we can catch the same error faster in the future.
The difficulty of service testing is that services often depend on other services. This problem can be solved through Mock Server:
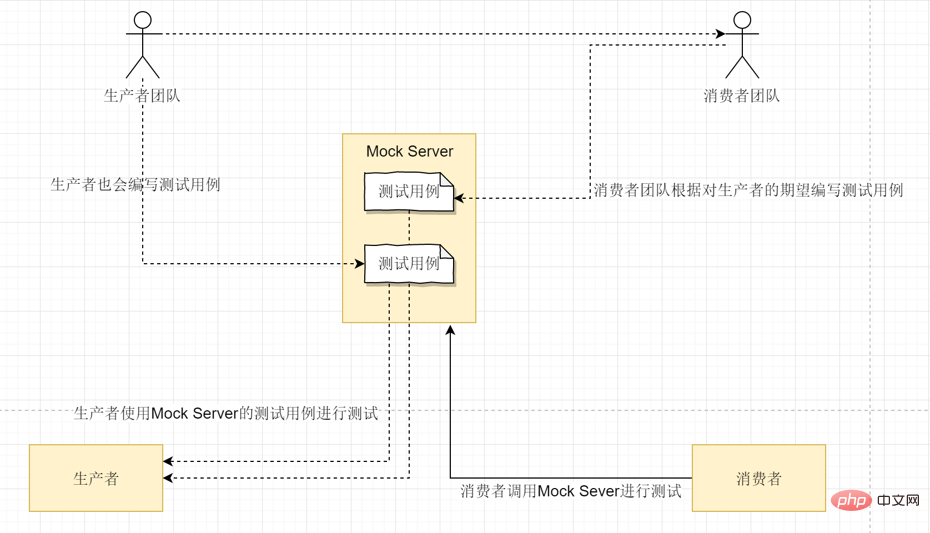
Everyone is familiar with unit testing. We generally write a large number of unit tests (including regression tests) to try to cover all code.
Indicator interface, link tracking injection, log diversion, service registration discovery, routing rules and other components as well as circuit breaker, current limiting and other functions all need to be on the application service Add some docking code. It would be very time-consuming and labor-intensive to implement each application service by itself. Based on the principle of DRY, Xiao Ming developed a microservice framework, extracting the code that interfaces with each component and other public codes into the framework, and all application services are developed using this framework.
Many customized functions can be achieved using the microservice framework. You can even inject program call stack information into link tracking to achieve code-level link tracking. Or output the status information of the thread pool and connection pool, and monitor the underlying status of the service in real time.
There is a serious problem with using a unified microservice framework: the cost of updating the framework is very high. Every time the framework is upgraded, all application services need to cooperate with the upgrade. Of course, a compatibility solution is generally used, allowing a period of parallel time to wait for all application services to be upgraded. However, if there are many application services, the upgrade time may be very long. And there are some very stable application services that are rarely updated, and the person in charge may refuse to upgrade... Therefore, using a unified microservice framework requires complete version management methods and development management specifications.
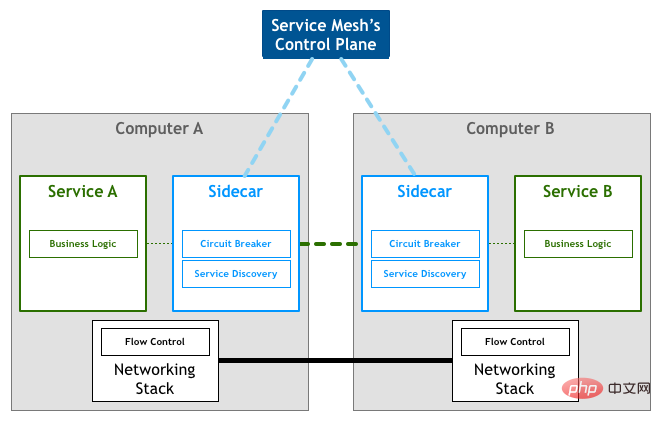
Another way to abstract common code is to abstract this code directly into a reverse proxy component. Each service additionally deploys this proxy component, and all outbound and inbound traffic is processed and forwarded through this component. This component is called Sidecar.
Sidecar will not incur additional network costs. Sidecar will be deployed on the same host as the microservice node and share the same virtual network card. Therefore, the communication between sidecar and microservice nodes is actually only realized through memory copy.
Picture from: Pattern: Service Mesh
Sidecar is only responsible for network communication. A component is also needed to uniformly manage the configuration of all sidecars. In Service Mesh, the part responsible for network communication is called the data plane, and the part responsible for configuration management is called the control plane. The data plane and control plane constitute the basic architecture of Service Mesh.
Picture from: Pattern: Service Mesh
The advantage of Service Mesh compared to the microservice framework is that it does not Intrusive code makes upgrades and maintenance more convenient. It is often criticized for performance issues. Even though the loopback network does not generate actual network requests, there is still the additional cost of the memory copy. In addition, some centralized traffic processing will also affect performance.
Microservices are not the end of architectural evolution. Going further, there are Serverless, FaaS and other directions. On the other hand, there are also people who are singing that the chorus must be separated for a long time and must be reunited for a long time, and rediscover the monolithic architecture...
In any case, the transformation of the microservice architecture has come to an end for the time being. Xiao Ming patted his increasingly smooth head with satisfaction and planned to take a break this weekend and meet Xiao Hong for a cup of coffee.
The above is the detailed content of This may be the best detailed article on microservice architecture you have ever read.. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



