


Currently, large language models (LLM) have set off a wave of changes in the field of natural language processing (NLP). We see that LLM has strong emergence capabilities and performs well on complex language understanding tasks, generation tasks and even reasoning tasks. This inspires people to further explore the potential of LLM in another subfield of machine learning - computer vision (CV).
One of the remarkable talents of LLMs is their ability to learn in context. Contextual learning does not update any parameters of the LLM, but it shows amazing results in various NLP tasks. So, can GPT solve visual tasks through contextual learning?
Recently, a paper jointly published by researchers from Google and Carnegie Mellon University (CMU) shows that as long as we can convert images (or other non-verbal modalities) Translated into a language that LLM can understand, this seems feasible.
 Picture
Picture
Paper address: https://arxiv.org/abs/2306.17842
This paper reveals the ability of PaLM or GPT in solving visual tasks through contextual learning, and proposes a new method SPAE (Semantic Pyramid AutoEncoder). This new approach enables LLM to perform image generation tasks without any parameter updates. This is also the first successful method to use contextual learning to enable LLM to generate image content.
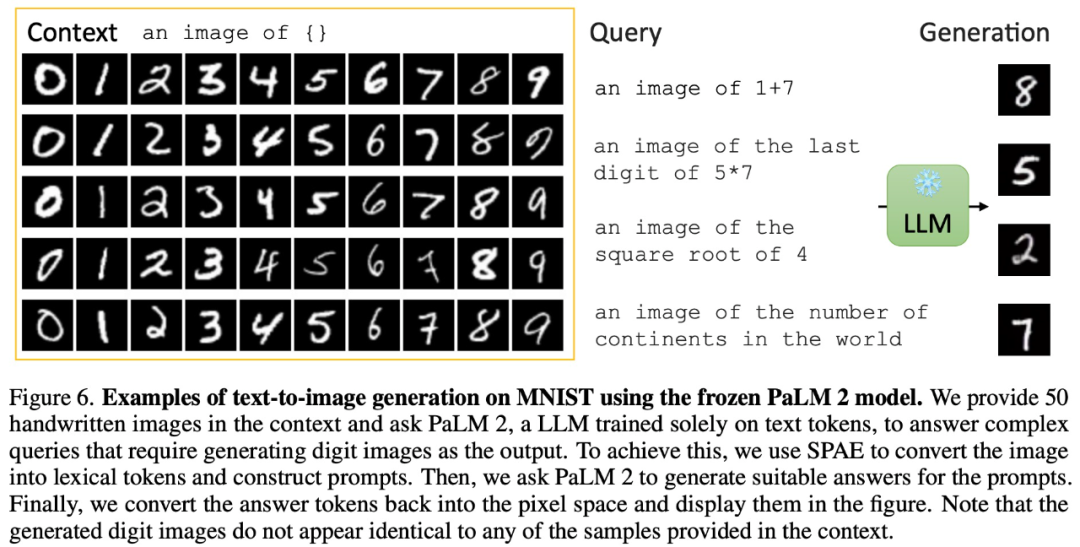
Let’s first take a look at the experimental effect of LLM on generating image content through context learning.
For example, by providing 50 images of handwriting in a given context, the paper asks PaLM 2 to answer a complex query that requires generating a digital image as output:
 Pictures
Pictures
can also generate realistic realistic images with image context input:
 Picture
Picture
In addition to generating images, through context learning, PaLM 2 can also perform image description:

# #There are also visual Q&A for image-related questions:
 Pictures
Pictures
You can even generate videos with denoising:
 Picture
Picture
In fact, convert the image into a language that LLM can understand , is a problem that has been studied in the Visual Transformer (ViT) paper. In this paper from Google and CMU, they take it to the next level — using actual words to represent images.
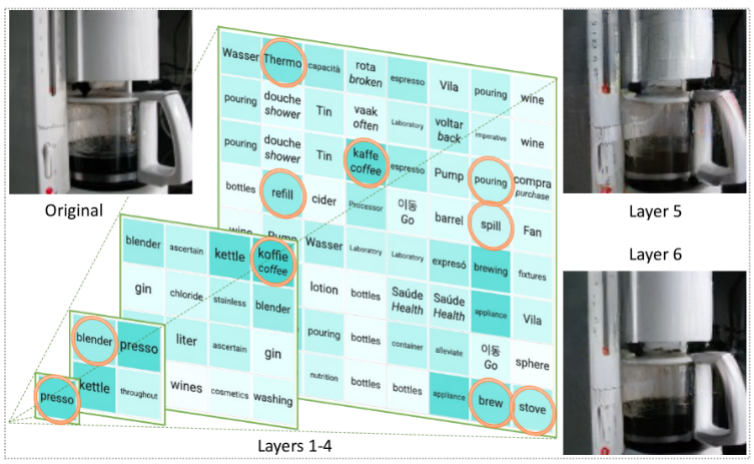
This approach is like building a tower filled with text, capturing the semantics and detail of the image. This text-filled representation allows image descriptions to be easily generated and allows LLMs to answer image-related questions and even reconstruct image pixels.
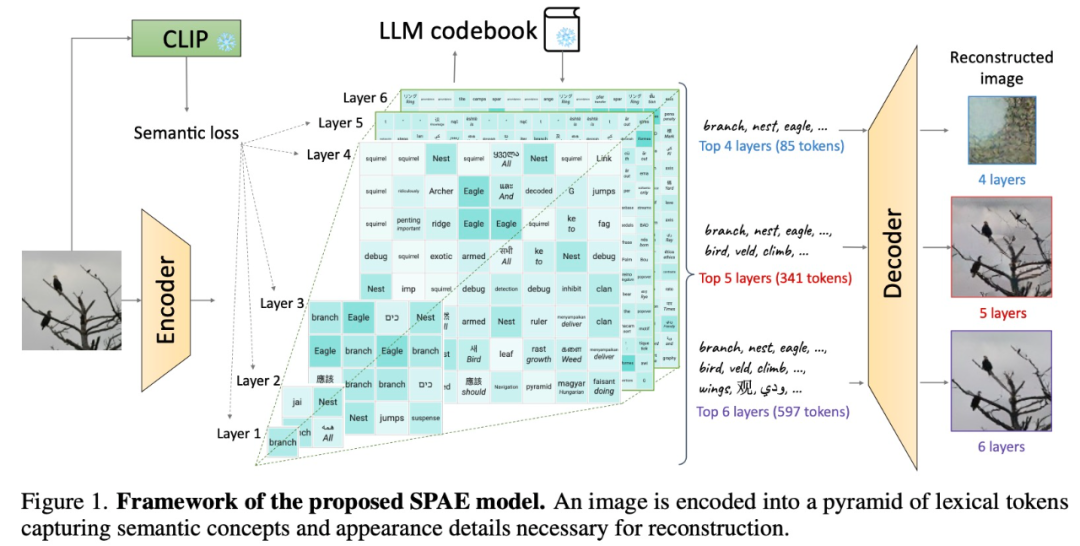
Specifically, this research proposes to use a trained encoder and CLIP model to convert the image into a token space; and then use LLM to generate a suitable lexical tokens; finally using a trained decoder to convert these tokens back to pixel space. This ingenious process converts images into a language that LLM can understand, allowing us to exploit the generative power of LLM in vision tasks.
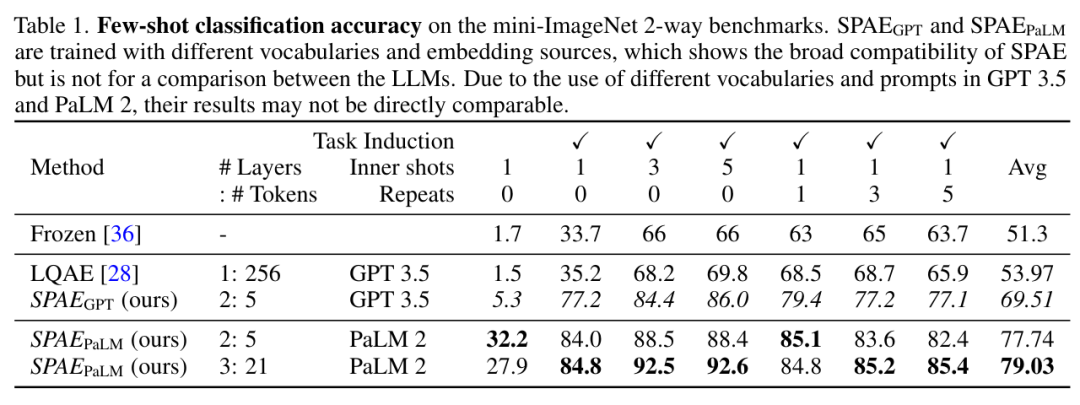
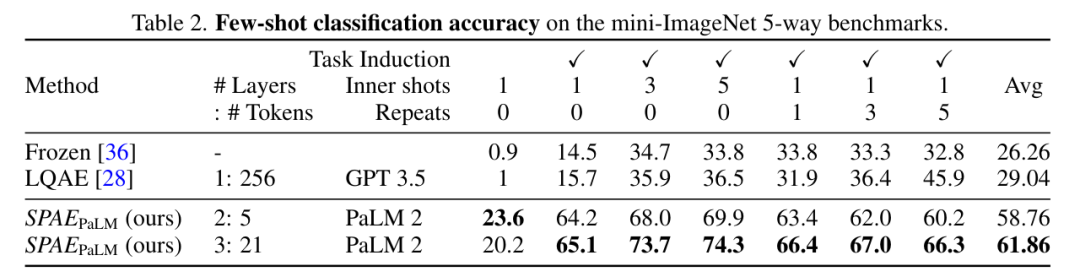
This study experimentally compared SPAE with SOTA methods Frozen and LQAE, and the results are shown in Table 1 below. SPAEGPT outperforms LQAE on all tasks while using only 2% of tokens.
 Picture
Picture
Overall, testing on the mini-ImageNet benchmark shows that the SPAE method outperforms the previous SOTA The method improves performance by 25%.
 Picture
Picture
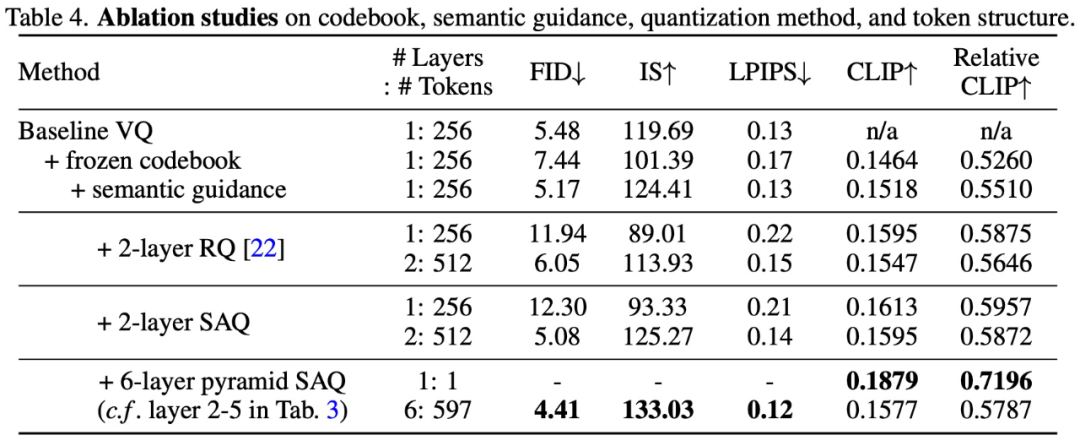
In order to verify the effectiveness of the SPAE design method, this study conducted an ablation experiment. The experimental results are as follows Table 4 and Shown in Figure 10:
 Picture
Picture
 Picture
Picture
Feeling Interested readers can read the original text of the paper to learn more about the research content.
The above is the detailed content of The visual talent of large language models: GPT can also solve visual tasks through contextual learning. For more information, please follow other related articles on the PHP Chinese website!
 Laravel Tutorial
Laravel Tutorial
 Introduction to the three core components of hadoop
Introduction to the three core components of hadoop
 How to define variables in golang
How to define variables in golang
 What are the development tools?
What are the development tools?
 The difference between concat and push in JS
The difference between concat and push in JS
 BigDecimal method to compare sizes
BigDecimal method to compare sizes
 How to set offline status on Douyin
How to set offline status on Douyin
 How to solve the problem of slow server domain name transfer
How to solve the problem of slow server domain name transfer





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



