


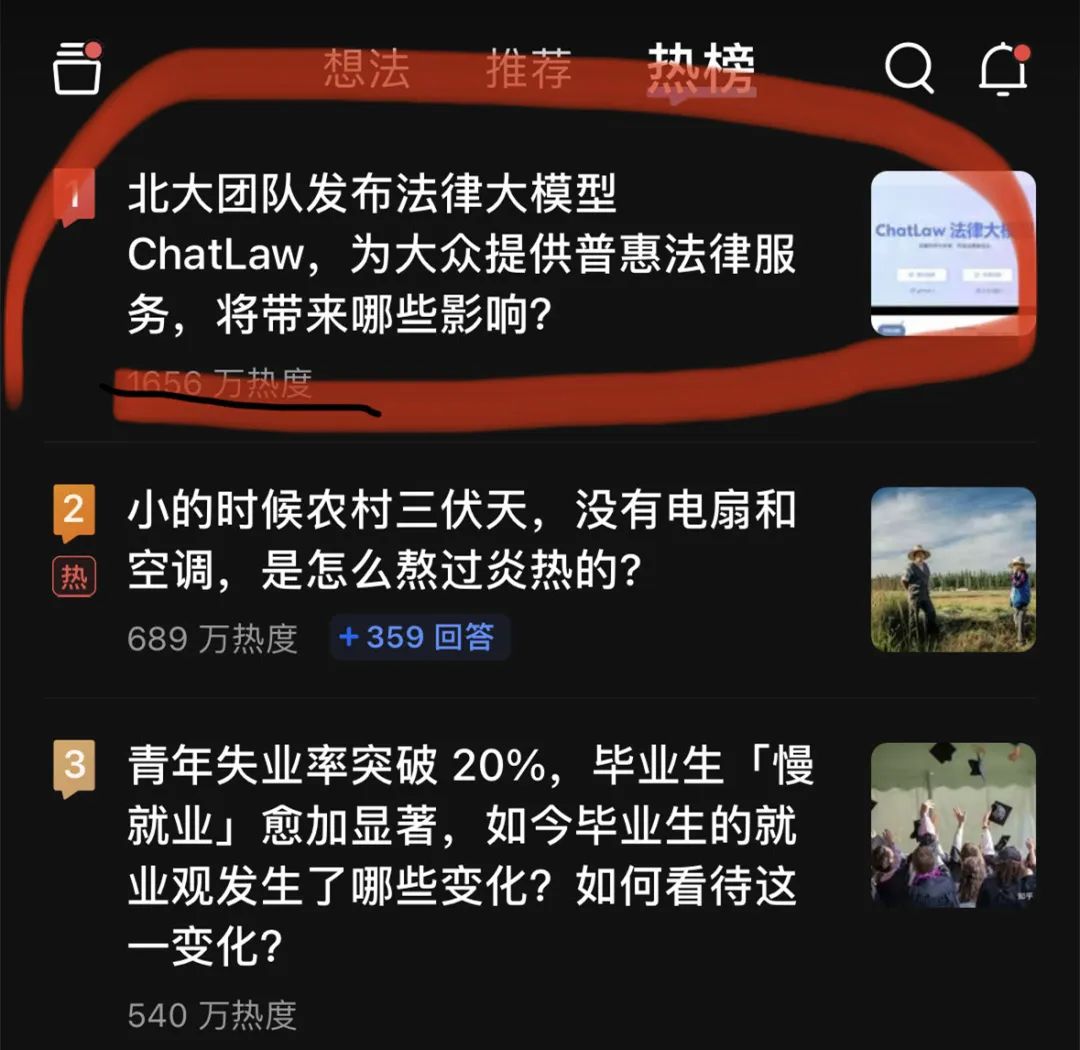
The big model "exploded" again.
Last night, a big legal model, ChatLaw, topped the Zhihu hot search list. At its peak, the popularity reached around 20 million.
This ChatLaw is released by the Peking University team and is committed to providing inclusive legal services. On the one hand, there is currently a shortage of practicing lawyers across the country, and the supply is far less than the legal demand; on the other hand, ordinary people have a natural gap in legal knowledge and provisions, and are unable to use legal weapons to protect themselves.
The recent rise of large language models provides an excellent opportunity for ordinary people to consult on legal-related issues in a conversational manner.
Currently, there are three versions of ChatLaw, as follows:
According to the official demonstration, ChatLaw supports users to upload legal materials such as documents and recordings, helping them summarize and analyze, and generate visual maps, charts, etc. In addition, ChatLaw can generate legal advice and legal documents based on facts. The project has 1.1k stars on GitHub.
 Picture
Picture
Official website address: https://www.chatlaw.cloud/
Paper address: https://arxiv.org/pdf/2306.16092.pdf
This is our GitHub project link: https://github.com/PKU-YuanGroup /ChatLaw
Currently, due to the popularity of the ChatLaw project, the server temporarily crashed and the computing power has reached the upper limit. The team is working on a fix, and interested readers can deploy the beta model on GitHub.
The editor himself is still in the queue for internal testing. So here is an official conversation example provided by the ChatLaw team, about the "seven-day no-reason return" problem that you may encounter when shopping online. I have to say that ChatLaw’s answers are quite comprehensive.
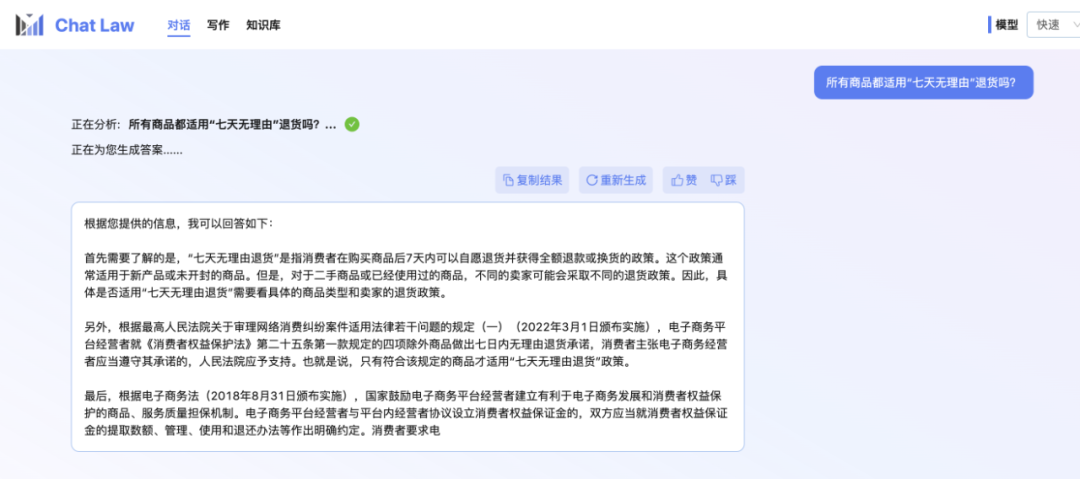 Picture
Picture
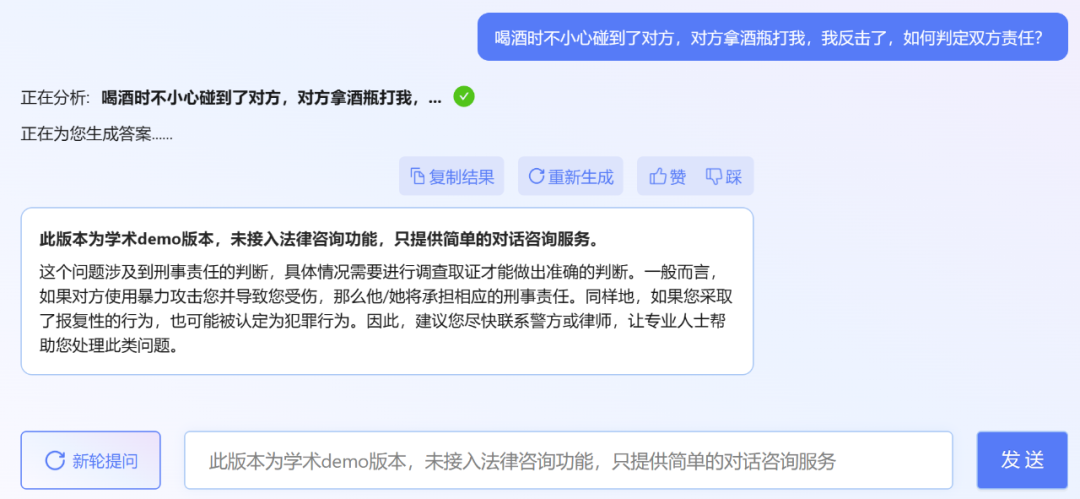
However, the editor found that the academic demo version of ChatLaw can be tried out, but unfortunately it does not have access to legal consultation function, only providing simple dialogue consultation services. Here are a few questions to try.
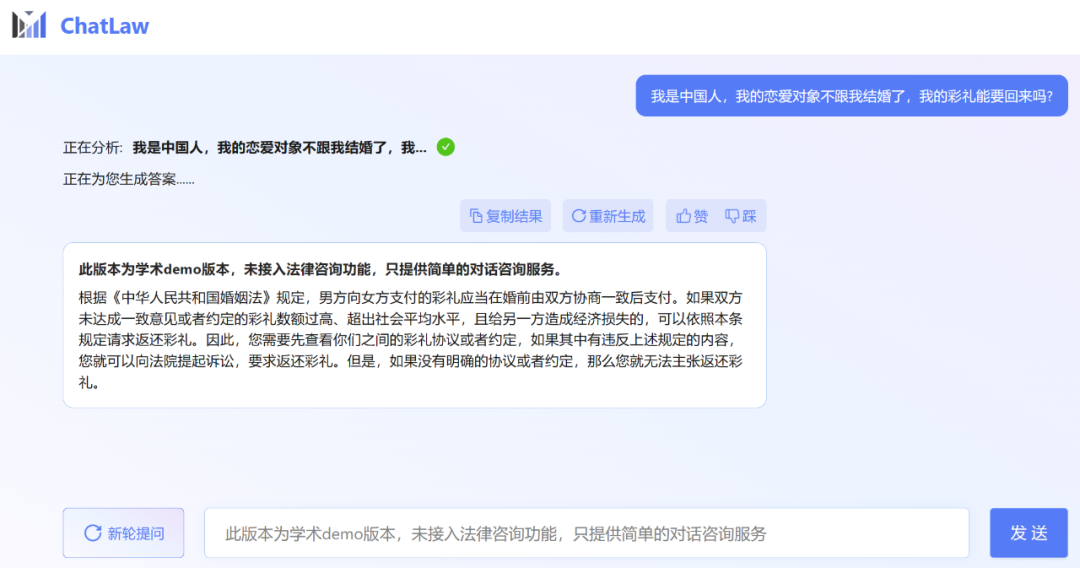 Picture
Picture
ChatLaw’s data source and training framework
data composition. ChatLaw data mainly consists of forums, news, legal provisions, judicial interpretations, legal consultations, legal examination questions, and judgment documents. The conversation data is then constructed through cleaning, data enhancement, etc. At the same time, by cooperating with Peking University School of International Law and well-known industry law firms, the ChatLaw team can ensure that the knowledge base can be updated in a timely manner while ensuring the professionalism and reliability of the data. Let’s look at specific examples below.
Construction examples based on laws, regulations and judicial interpretations:
Example of capturing real legal consultation data:

Example of constructing multiple-choice questions for the bar exam:
 Picture
Picture
Then comes the model level. To train ChatLAW, the research team fine-tuned it using Low-Rank Adaptation (LoRA) based on Ziya-LLaMA-13B. In addition, this study also introduces the self-suggestion role to alleviate the problem of model hallucinations. The training process is performed on multiple A100 GPUs, with deepspeed further reducing training costs.
The following figure is the architecture diagram of ChatLAW. This research injects legal data into the model and performs special processing and enhancement of this knowledge; at the same time, they also introduce multiple modules during reasoning , integrating general model, professional model and knowledge base.
This study also constrained the model during inference, so as to ensure that the model generates correct laws and regulations and reduce model illusions as much as possible.
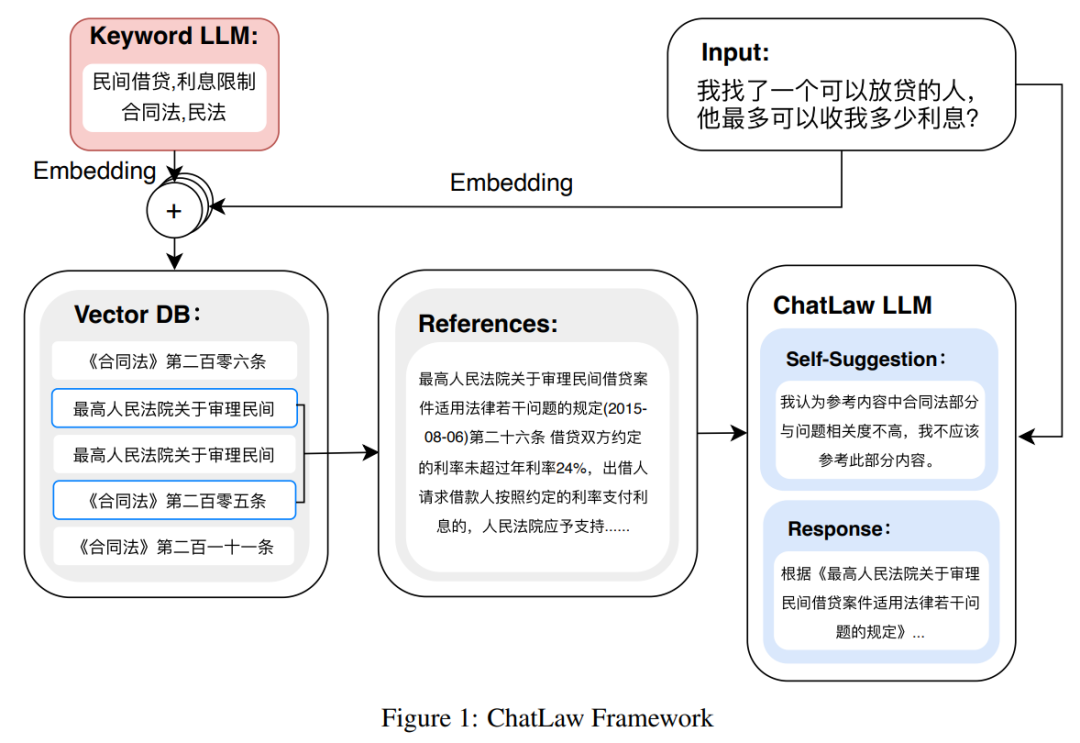 Picture
Picture
At first, the research team tried traditional software development methods, such as using MySQL and Elasticsearch for retrieval, but the results were inconsistent. As expected. Therefore, this research began by trying to pre-train the BERT model for embedding, and then use methods such as Faiss to calculate cosine similarity and extract the top k laws and regulations related to the user query.
This approach often produces suboptimal results when the user's question is unclear. Therefore, researchers extract key information from user queries and design algorithms using vector embedding of this information to improve matching accuracy.
Since large models have significant advantages in understanding user queries, this study fine-tuned the LLM to extract keywords from user queries. After obtaining multiple keywords, the study used Algorithm 1 to retrieve relevant legal provisions.
 Picture
Picture
This study collected more than ten years of For the National Judicial Examination questions, a test data set containing 2,000 questions and their standard answers was compiled to measure the model's ability to handle legal multiple-choice questions.
However, research has found that the accuracy of each model is generally low. In this case, comparing accuracy alone doesn't mean much. Therefore, this study draws on the ELO matching mechanism of League of Legends and creates a model-confrontational ELO mechanism to more effectively evaluate the ability of each model to handle legal multiple-choice questions. The following are ELO scores and winning rate charts respectively:
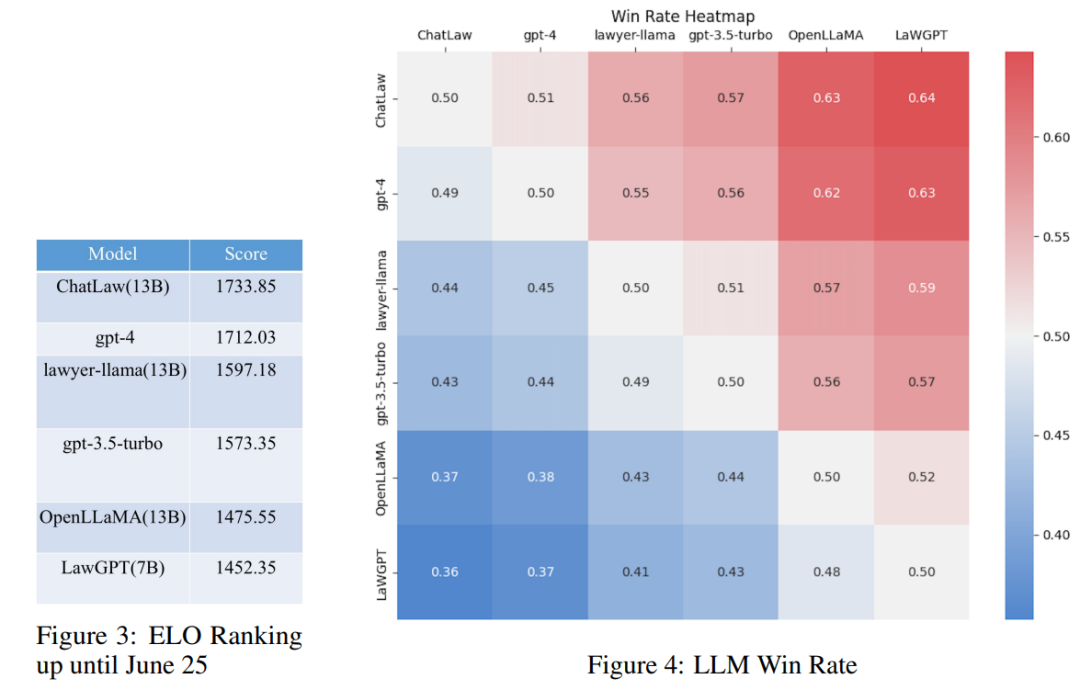 Picture
Picture
Through the analysis of the above experimental results, we can draw the following Observation results
(1) Introducing data from law-related questions and answers and regulatory provisions can improve the performance of the model on multiple-choice questions to a certain extent;
(2) Add data for specific types of tasks for training, and the model’s performance on this type of tasks will be significantly improved. For example, the reason why the ChatLaw model is better than GPT-4 is that a large number of multiple-choice questions are used as training data in the article;
(3) Legal multiple-choice questions require complex logical reasoning, therefore, Models with a larger number of parameters usually perform better.
Reference Zhihu link:
https://www.zhihu.com/question/610072848
Other reference links:
https://mp.weixin.qq.com/s/bXAFALFY6GQkL30j1sYCEQ
The above is the detailed content of The server is overcrowded, Peking University's big legal model ChatLaw is popular: tell you directly how Zhang San was sentenced. For more information, please follow other related articles on the PHP Chinese website!
 what is index
what is index How to completely delete mongodb if the installation fails
How to completely delete mongodb if the installation fails Usage of qsort function
Usage of qsort function How to solve the problem of missing steam_api.dll
How to solve the problem of missing steam_api.dll Tutorial on adjusting line spacing in word documents
Tutorial on adjusting line spacing in word documents postgresql common commands
postgresql common commands The specific process of connecting to wifi in win7 system
The specific process of connecting to wifi in win7 system linux scheduled shutdown command
linux scheduled shutdown command




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



