


The main content of this article is a discussion on generative text summarization methods, focusing on the latest training paradigm using contrastive learning and large models. It mainly involves two articles, one is BRIO: Bringing Order to Abstractive Summarization (2022), which uses contrastive learning to introduce ranking tasks in generative models; the other is On Learning to Summarize with Large Language Models as References (2023), in Based on BRIO, large models are further introduced to generate high-quality training data.
The training of generative text summary generally uses maximum similarity estimation. First, an Encoder is used to encode the document, and then a Decoder is used to recursively predict each text in the summary. The fitting target is an artificially constructed summary standard answer. The goal of generating text at each position that is closest to the standard answer is represented by an optimization function:
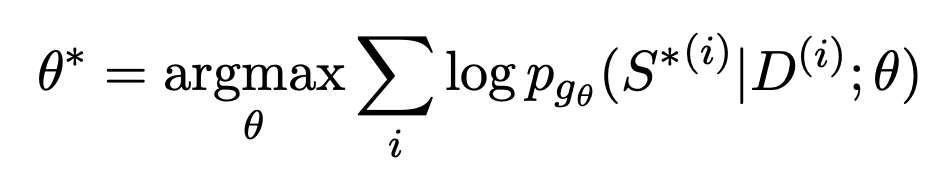
The problem with this approach is that, Training and downstream actual tasks are not consistent. Multiple summaries can be generated for a document, and they may be of good or poor quality. MLE requires that the target of fitting must be the only standard answer. This gap also makes it difficult for text summarization models to effectively compare the advantages and disadvantages of two summaries of different quality. For example, an experiment was conducted in the BRIO paper. The general text summary model has very poor results when judging the relative order of two summaries with different qualities.
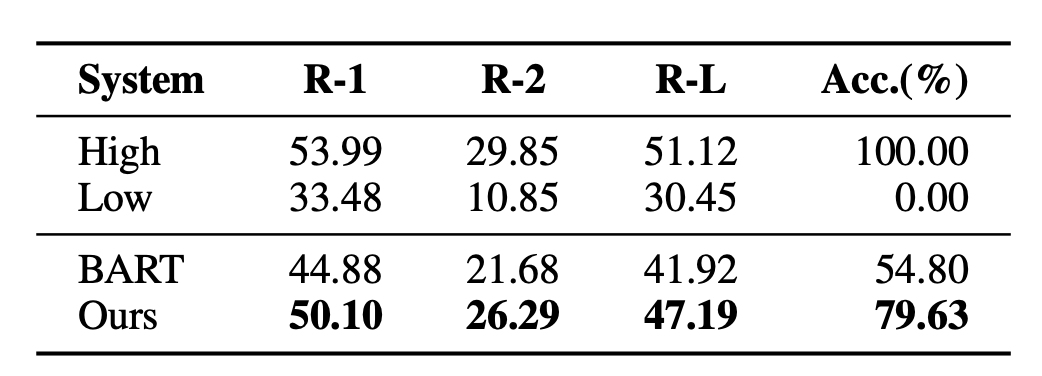
In order to solve the problems existing in the traditional generative text summary model, BRIO: Bringing Order to Abstractive Summarization (2022) proposes to further introduce contrastive learning tasks into the generative model to improve the model's ability to sort summaries of different qualities.
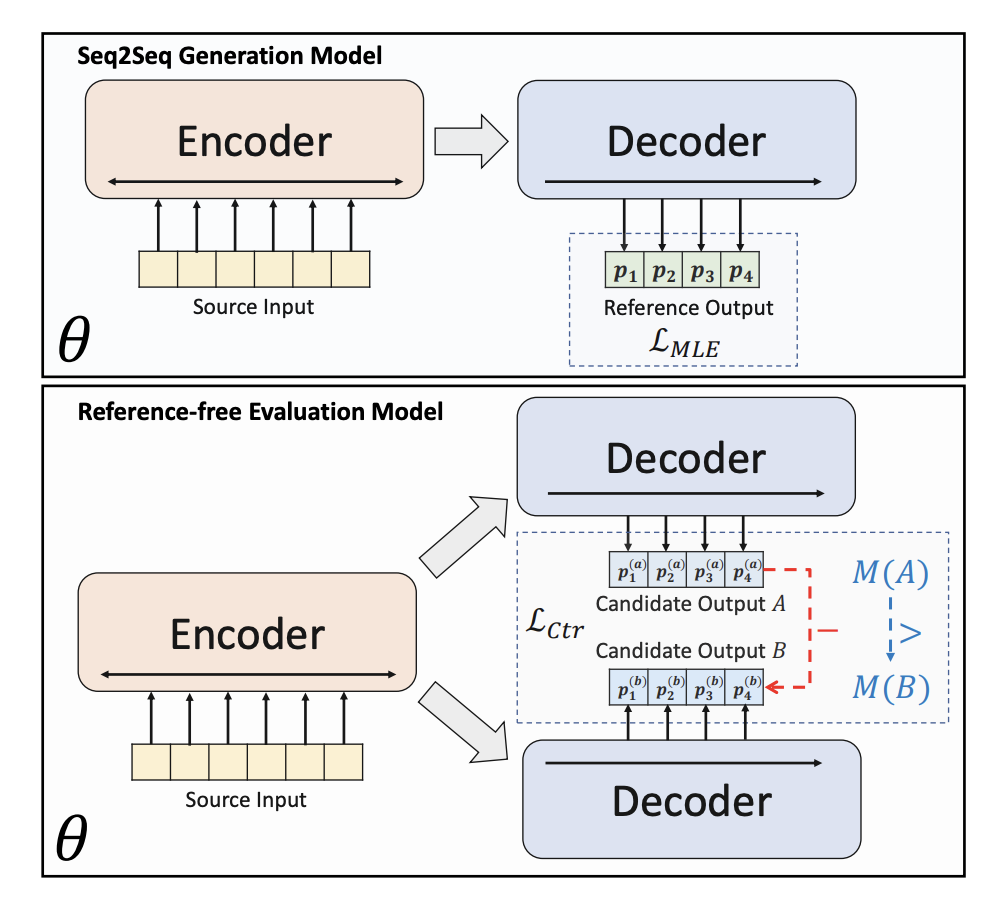
BRIO uses multi-task training. The first task adopts the same method as traditional generative models, that is, fitting standard answers through MLE. The second task is a contrastive learning task, where a pre-trained text summary model uses beam search to generate two different results, and ROUGE is used to evaluate which one is better between the two generated results and the standard answer to determine which of the two Sorting of abstracts. The two summary results are input into the Decoder to obtain the probabilities of the two summaries. Through comparative learning loss, the model can give higher scores to high-quality summaries. The calculation method of comparative learning loss in this part is as follows:
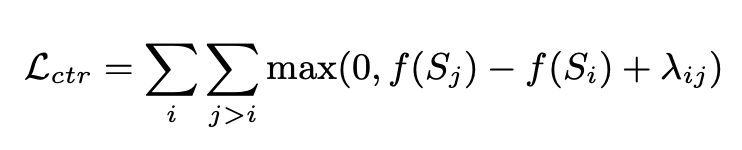
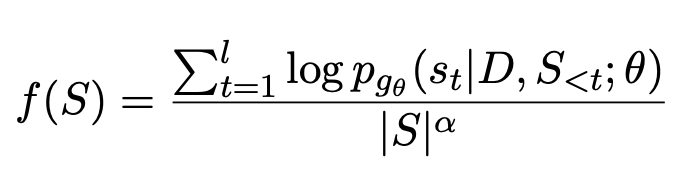
It has been found that the quality of summaries generated using large models such as GPT is even better than that generated by humans, so such large models are becoming increasingly popular. In this case, using artificially generated standard answers limits the ceiling of model effectiveness. Therefore, On Learning to Summarize with Large Language Models as References (2023) proposes to use large models such as GPT to generate training data to guide summary model learning.
This article proposes 3 ways to use large models to generate training samples.
The first is to directly use the summary generated by the large model to replace the manually generated summary, which is equivalent to directly fitting the summary generation capability of the large model with the downstream model. The training method is still MLE.
The second method is GPTScore, which mainly uses a pre-trained large model to score the generated summary, uses this score as a basis for evaluating the quality of the summary, and then uses a method similar to BRIO for comparative learning training. GPTScore is a method proposed in Gptscore: Evaluate as you desire (2023) to evaluate the quality of generated text based on a large model.

The third method is GPTRank. This method allows the large model to sort each summary instead of directly scoring, and let the large model sort the summaries. Logic explanations to obtain more reasonable sorting results.

The ability of large models in summary generation has been increasingly recognized. Therefore, using large models as a generator of summary model fitting targets to replace manual annotation results will become a future trend. development trend. At the same time, using ranking contrast learning to train summary generation allows the summary model to perceive the summary quality and surpass the original point fitting, which is also crucial to improving the effect of the summary model.
The above is the detailed content of Using large models to create a new paradigm for text summary training. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



