



There have been many articles recently discussing the issue of whether to retain or retain operation and maintenance positions. The SRETalk public account I host I also posted the opinions of many operation and maintenance directors. I also personally communicated with many people in the industry. I have some small thoughts and recorded them for reference by CTOs/CIOs. As an operation and maintenance/SRE, if you think If you are confused, I also recommend that you read this article carefully.
I think this is an in-depth thinking, it may be boring, but it will be helpful for career choice and team building. This article welcomes well-founded discussions, but does not welcome arrogance. In addition, many things are not black and white. It is great if the content of the article can inspire you and bring new thinking to CXOs' decision-making.
In addition, SRETalk’s operations and maintenance director interviews will continue, and more different views will continue to be output for your reference, and my views are not necessarily correct. , also for reference only.
First let me talk about the title, "How to build operation and maintenance/SRE capabilities". Here I do not write about building a team, but building capabilities, because some goals may not be achieved. You must build your own team. From the perspective of cost, predictability of results, and long-term investment and maintenance, you need to make careful decisions. If you make the wrong decision, the future will be a mess. This will be discussed later.
Another point should be clarified in advance. The operation and maintenance/SRE team mentioned in the article all serve the business, and the success of the business is the first priority. Some operation and maintenance teams have made some products and exported them for external commercialization, which has become a business in itself. This is another matter. Moreover, based on my experience in my old employer, the operation and maintenance/SRE team’s approach (external commercialization output ) is not advisable, especially in a company that does not have ToB genes and does not have corresponding ToB organization construction.
Since everything is for business success (regardless of business, only considering whether you can be promoted or whether you can fool the boss is another matter), we will The focus is on what operation and maintenance capabilities the business requires (explained in detail later) and where these operation and maintenance capabilities need to be obtained. There are three typical acquisition methods.
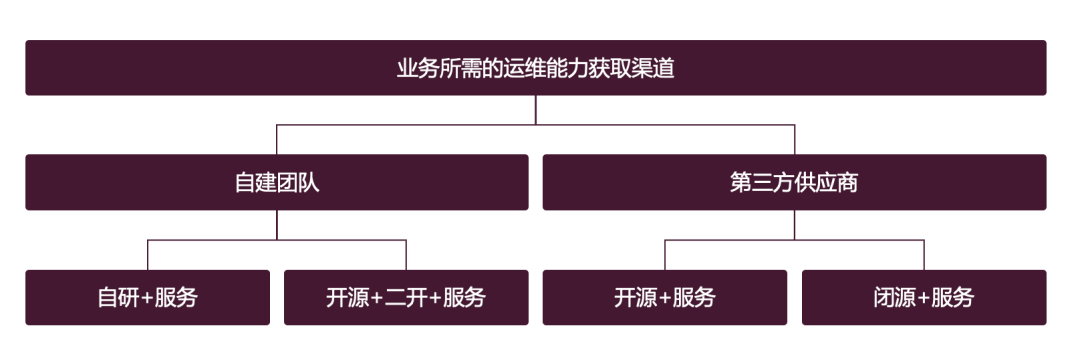
The first is to provide relevant capabilities through self-built teams. This method is the most familiar to everyone. Self-built teams Deliverables to the business usually include two parts: products and services. Let’s talk about the product first:
The second is service. The so-called service here refers to the expert experience exported to the business side. For example, if a self-built team builds a monitoring product, this team needs to output monitoring best practices to the company's internal "customers". When problems arise with the monitoring product, this team needs to quickly resolve them. In fact, the middle and back-end teams within the company need to have a strong sense of service and understand the best practices in the industry. Otherwise, they will easily be led by the business and go in the opposite direction to the best practices in the industry. It’s all a problem.
The core of service relies on people (of course, it would be great to solidify best practices into products). As a manager, if you want this team to deliver good services, you need to consider many people. Questions, such as: whether it can recruit relevant talents, whether it can retain relevant talents (development space, salary, etc.), at least two people in each direction of the self-built team can complement each other, and whether the cost can be afforded.
Obtaining operation and maintenance capabilities through third-party suppliers is another way. The supplier's deliverables obviously include two parts: products and services. Products are divided into two types: open source and closed source. What are the considerations?
The second is service. Suppliers usually have advantages over self-built teams. The reasons are as follows:
In addition, let’s talk about the cost issue. The supplier’s charges are most likely more cost-effective than recruiting people yourself (provided that the right people are recruited). Otherwise, the business logic will not hold. This principle is obvious and will not be repeated again.
Obtaining operation and maintenance capabilities from third-party suppliers seems to be overwhelming for self-built teams, so do you still need to read the following articles? In fact, it is not necessarily the case. For a certain operation and maintenance capability, what is more important is product capability or service capability. What you need most is product capability or service capability. It needs to be looked at case by case. Later, I will look at it from the business side. All aspects of operation and maintenance capabilities are dismantled separately.
The essence of operation and maintenance is a type of technical support capabilities, which is very similar to the infrastructure team. Some of them can be put into the operation and maintenance team, but they can be put into the infrastructure The team problem is not big. Some companies even put such people directly into the business R&D team. Let’s ignore the division of labor for the time being and first sort out what kind of technical support capabilities the business needs.
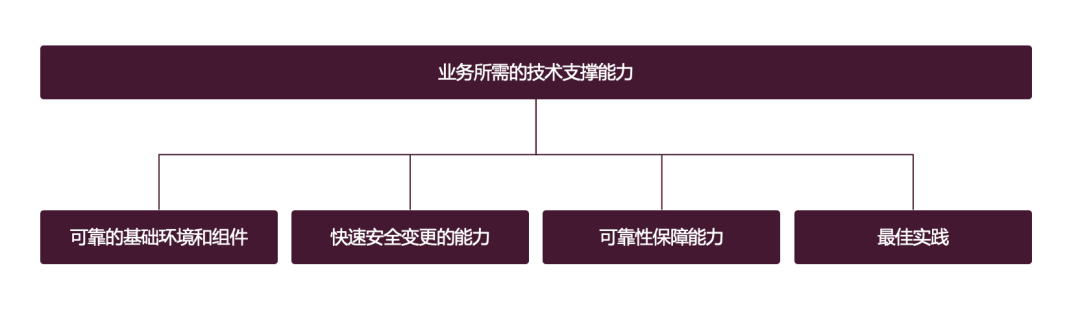
This picture actually explains the problem very well. Let me elaborate a little more:
How should the four abilities mentioned above be obtained? Now let’s break it up and break it down and talk about it.
First of all, let’s talk about the basic hardware environment. Obviously there are two options, cloud or self-built. If the policy requires that you have to toss it yourself, there is no way. The policy shall prevail. If you can choose by yourself, in this era, it is most likely to be more suitable to go to the cloud. Unless the company is very large and has a large amount of machines, building it yourself may have an advantage. Note that what I say here is only possible. When calculating costs, remember to include labor costs, not just hardware costs.
Regarding career choice: It does not seem to be good news for system operation and maintenance engineers and network operation and maintenance engineers. The emergence of the cloud has indeed taken up space for some of these positions. There is no way. The wheel of the times is rolling forward, and everyone is the dust of history.
Let’s talk about components, such as MySQL, Redis, MongoDB, Kafka, ElasticSearch, Nginx, Kubernetes, etc. There are obviously three options, use cloud PaaS products or make your own or produce your own hardware. Suppliers provide solutions and services. For each choice, we will make a comment respectively:About career choice: For experienced veterans of various components, the first choice is to work for a cloud vendor or start a business to export experience, and the second choice is to go to a large manufacturer that builds its own components. Generally speaking, It is difficult for small and medium-sized factories to have high salaries. After all, third-party expert services are very cost-effective.
The ability to change quickly and safely The most common changes made in business research and development are binary and configuration changes. Of course, there are also changes to the basic environment and components. Let’s talk about binary and configuration changes first. How can we iterate quickly and safely? It can be done in stages. When the company is still relatively small, you don’t need to pay too much attention to the construction of tools. You only need to set the specifications and processes. Standard aspects such as: which account is deployed under, which directory, how to put logs, how to host the process, any changes must be rollable, etc. In terms of processes, such as: change notification mechanism, multi-module collaborative online mechanism, and non-rollback There needs to be an approval mechanism and so on. Then, we need to have quantitative data on historical changes, such as how many changes a certain team has made in the last quarter, what is the rollback rate, and what is the failure rate. Each team has a comparison, and the team that does not do well is It will be improved in the next quarter.When the company continues to grow, it can invest manpower to build a change platform, implement standardized systems on the platform, and produce quantitative data. Because different companies have different situations, in the era of traditional physical machines and virtual machines, it is very difficult to It is rare to see commercial change systems. Of course, after the rise of Kubernetes, many of the underlying differences have been shielded. The platform for making changes based on Kubernetes has become much more versatile, and related products have begun to come out.
Changes to the production environment are not the same as changes to the test environment and joint debugging environment. The production environment has stricter stability requirements, while the test environment and joint debugging environment have relatively low requirements. The so-called CI/CD systems are mostly designed for test environments and joint debugging environments. There are only a handful of companies that can implement CD for production environments.
Focus: The CI/CD system for testing and joint debugging environments is more about speeding up R&D efficiency; the change system for the production environment is more about ensuring stability and implementation. normative system. The company is small in the early stage, so it is enough to rely on rules and regulations. Later, it will need a collaborative effort through changes in rules and regulations and a platform.
The formulation of specifications is actually in the early stages. The specifications may already be in place before the operation and maintenance team exists. Therefore, it is most likely that the CTO and the subordinate Core team will formulate them. If it has not been formulated before, the operation and maintenance director (Operation and maintenance director is here) can take the lead in formulating it, and the Core team under the CTO will review it (everyone has participation), and finally the CTO will make the decision. Publish (top-down) and everyone executes.
It is relatively appropriate for the development of the change platform to be developed by the operation and maintenance team. Later, we will introduce some other platforms and set up a dedicated operation and maintenance team (there is no difference between the operation and maintenance I am talking about here and SRE. You can also call this team the SRE team) is appropriate. Changing the platform requires implementing the company's specifications, so there are relatively few cases of outsourcing. After the company reaches a certain scale, self-research and accumulation based on open source things is a high probability choice.
About career selection: Change management is an important part of an enterprise and also serves the stability of the system. This is a typical DevOps position, and the ceiling is about the P7 level (purely a personal opinion, for reference only).
The other is the change of basic components and environment, typically such as MySQL table structure, Nginx configuration, DNS, VIP, etc. Such changes can be internalized into the component management and control platform, so that The component capability provider provides change entry and management control capabilities.
This capability is very important. SRE is the abbreviation of Site Reliability Engineering, that is, site reliability engineering. From the CTO's perspective, when software is deployed to the production environment, various problems may occur in the future. We hope to have an engineering system to ensure reliability. This is a huge topic, and this article won’t go into detail, just clarify what is and who is responsible for it.
The so-called reliability is the process of fighting against failures. Therefore, we still look at the life cycle of failures, starting from each link of the life cycle, to defeat the failure, or even kill it directly. In the cradle.
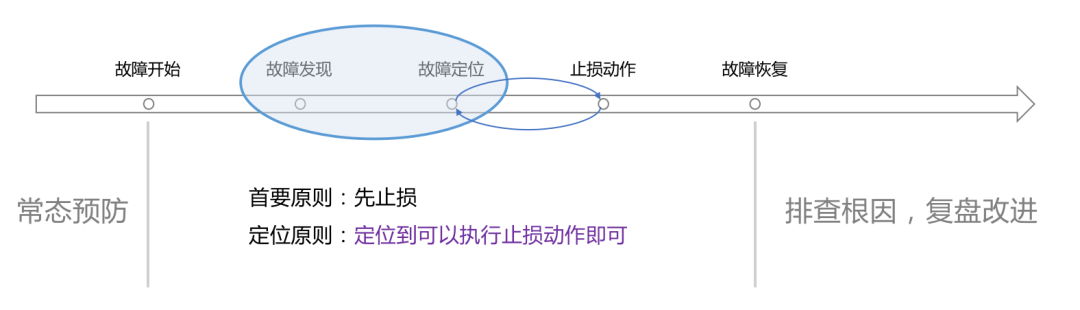
For example: formulate alarm completeness standards and make quantitative assessments of each business line; formulate positioning principles and processes as well as standards for fault grading and responsibility; sort out the correspondence between the core functions and service modules of each business in advance, and establish a global stability view or The war room is used to quickly identify faulty modules or interfaces; optimize the architecture; sort out failure plans and conduct regular drills to keep them fresh, which is the mess of chaos engineering; and so on.
There are some things here that require business research and development, such as architecture optimization. For the rest, my suggestion is:Let the operation and maintenance team take the lead and cooperate with R&D. For example, the Core team under the CTO will most likely have both an operation and maintenance position and a technical position for each business. In name, the CTO will make the decision, authorizing the operation and maintenance position to take the lead, and the R&D position for each business to cooperate. Of course, when it comes to actual operations, the No. 1 operation and maintenance position may find a capable person to do the actual operation in the future, and each business line may also have people who rely on the No. 1 technical position to provide interface support.
Except for architecture optimization, these other things are all horizontal matters. There can be some methodologies and best practices to bring everyone together and help share these methodologies and best practices. best practices. Of course, some people will have questions: Can we directly find someone from the R&D team to form such a stable virtual organization and jointly promote this matter? In fact, you can try it. However, there will be a few problems:
Focus on: prevention and risk management in advance For control, please CXO ask the operation and maintenance director for the results, but you must provide great cooperation and push it from top to bottom. For the SRE engineer role to solve this problem, it seems that a very professional high-level person is required. There is a high probability that the cognitive skills cannot keep up within 5 years of working. Perhaps, recruiting SRE from the senior R&D team is a good choice. CXOs can Give it a try.
Once a failure occurs, our primary goal becomes to reduce the impact. The relevant teams immediately collaborated to quickly locate the direct cause, stop the loss quickly, and then slowly investigate the root cause afterwards. The following work content will be involved here:
OK, the above is eloquent, but back to the question, for this work content, who should the CTO ask for results? My suggestion is: SRE team (the words operation and maintenance and SRE appear many times in this article, and they basically mean the same thing in this article. Operation and maintenance here is not just Operations). Obviously SRE cannot solve all faults. It should be said that most faults have to rely on people from other teams, but the CTO can't always go to team A and team B. Therefore,SRE must carry the CTO’s Sword of Shang Fang and take the lead in overall stability construction. Each business needs the best cooperation from the export interface. The so-called stability construction includes preventive risk control beforehand and overall planning and coordination during the event. , and the subsequent review is promoted, which is also the greatest value of SRE to the company.
This contains a lot of content, such as which model package is more suitable, what networking method is more suitable, and which components companies have better Control, can you get better support (whether it is an internal team or a third-party supplier), what are the programming languages and frameworks recommended or even required by the company, and what are the access layer solutions recommended by the industry? What is the change plan? How to do observability? Etc., etc.
It is undeniable that these practical methods of a great business R&D team are clear, but it is also undeniable that after there are more business lines, the level will be mixed, and a team with a poor level will inevitably need someone with a coaching role, which cannot always be achieved Go to the CTO for everything. As a horizontal technical team, the SRE team is particularly suitable for taking charge of this matter. But obviously, this is a high-end position that cannot be filled by newcomers. Recruiting high-level people to do business as BP is an effective means to promote the unification of the technology stack. If the CTO does not use this starting point well, the technology will The system will bloom, but behind it will be various governance dilemmas.The above four supporting capabilities, how should the business side obtain them, how should the CTO coordinate, how should the various teams cooperate, that's all. Let us make two more summaries below.
Summary 1: How does the CTO help the business line obtain these supporting capabilities?
Another addition to the topic of FinOps, FinOps is also a horizontal capability. Should it also be left to SRE? This is not necessarily the case. I think it’s good to let the business close the loop. The business itself is responsible for profits and losses. IT expenditures are the majority of expenditures. The business GM should be very concerned about it. The CEO presses KPIs related to revenue and net profit to the business GM. The business GM can Self-closing loops do a good job of compromise.
Summary 2: Operation and Maintenance/SRE Career Suggestions
The author of this article
", public account The manager of SRETalk and the entrepreneurial partner of Kuaimao Nebula. The direction of entrepreneurship is to ensure stability. If you have any needs, please feel free to contact me for communication.
The above is the detailed content of From a CTO perspective: How to build operation and maintenance/SRE capabilities. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



