


With the popularity of ChatGPT, large models have received more and more attention, and the capabilities displayed by large models are amazing.
In areas such as image generation, recommendation systems, and machine translation, large models have begun to play a role. Given some prompt words, the design drawings generated by the image generation website Midjourney have even surpassed the level of many professional designers.
Why can large models show amazing abilities? Why does the performance of the model become better as the number of parameters and capacity of the model increases?
An expert from an AI algorithm company told the author: The increase in the number of parameters of the model can be understood as an increase in the dimension of the model, which means that we can simulate the real world in a more complex way. rules. Take the simplest scenario as an example. Give a scatter plot on a plane. If we use a straight line (a one-variable function) to describe the pattern of scatter points on the plot, then no matter what the parameters are, there will always be some The point is outside this line. If we use a binary function to represent the pattern of these points, then more points will fall on this function line. As the dimension of the function increases, or the degree of freedom increases, more and more points will fall on this line, which means that the laws of these points will be fitted more accurately.
In other words, the larger the number of parameters of the model, the easier it is for the model to fit the laws of massive data.
With the emergence of ChatGPT, people have discovered that when the parameters of the model reach a certain level, the effect is not just "better performance", but "beyond expectations" good".
In the field of NLP (natural language processing), there is an exciting phenomenon that academic circles and industry cannot yet explain the specific principles of: "Emerging Ability".
What is "emergence"? "Emergence" means that when the number of parameters of the model increases linearly to a certain level, the accuracy of the model increases exponentially.
We can look at a picture. The left side of the picture below shows the Scaling Law. This is a phenomenon discovered by OpenAI researchers before 2022. That is to say, as When the model parameter size increases exponentially, the accuracy of the model will increase linearly. The model parameters in the picture on the left do not grow exponentially but linearly
By January 2022, some researchers discovered that when the parameter scale of the model exceeds a certain level, the model accuracy improves. The degree obviously exceeds the proportion curve, as shown on the right side of the figure below.
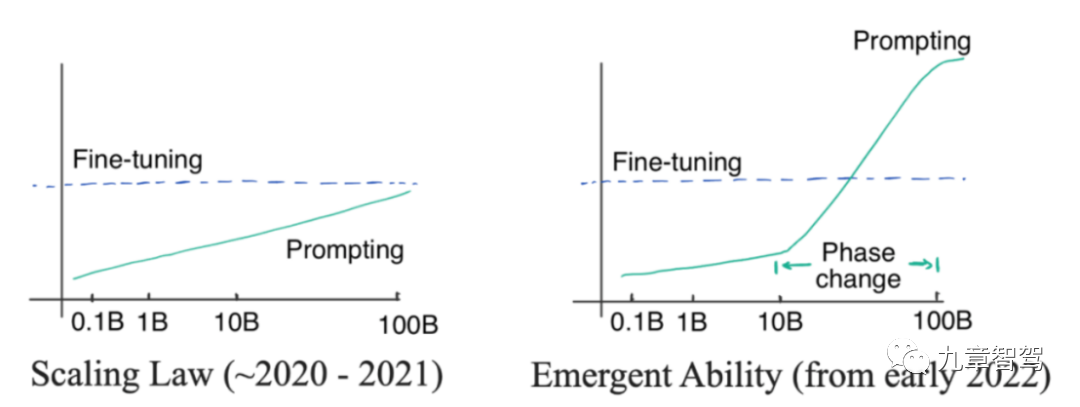
"Emergence" diagram
Implemented to the application level, we will It was found that large models can achieve some tasks that small models cannot achieve. For example, large models can do addition and subtraction, simple reasoning, etc.
What kind of model can be called a large model?
Generally speaking, we believe that models with more than 100 million parameters can be called "large models". In the field of autonomous driving, large models mainly have two meanings: one is a model with more than 100 million parameters; the other is a model composed of multiple small models superposed together. Although the number of parameters is less than 100 million, it is also called a model. as a "large model".
According to this definition, large models have begun to be widely used in the field of autonomous driving. In the cloud, we can take advantage of the capacity advantages brought by the increased number of model parameters and use large models to complete some tasks such as data mining and data annotation. On the car side, we can merge multiple small models responsible for different subtasks into one "large model", which can save reasoning time in the car side calculation and increase safety.
Specifically, how can large models come into play? According to the information the author communicated with industry experts, the industry currently mainly uses large models in the field of perception. Next, we will introduce how large models enable perception tasks in the cloud and on the car side respectively.
1.1.1 Automatic data annotation
Automatic annotation can be achieved by using large model pre-training. Taking video clip annotation as an example, you can first use massive unlabeled clip data to pre-train a large model through self-supervision, and then use a small amount of manually labeled clip data to fine-tune the model so that the model has detection capabilities. The model can automatically annotate clip data.
The higher the labeling accuracy of the model, the higher the degree of replacement of people.
Currently, many companies are studying how to improve the accuracy of automatic labeling of large models, with a view to achieving completely unmanned automatic labeling after the accuracy reaches the standard.
Leo, director of intelligent driving products at SenseTime, told the author: We have done evaluations and found that for common targets on the road, the automatic labeling accuracy of SenseTime’s large models can reach more than 98%. In this way, the subsequent manual review process can be very streamlined.
In the development process of intelligent driving products, SenseTime Jueying has introduced automatic pre-annotation of large models for most of the perception tasks. Compared with the past, the same amount of data can be obtained. Samples, labeling cycles and labeling costs can be reduced by more than dozens of times, significantly improving development efficiency.
Generally speaking, everyone’s expectations for annotation tasks mainly include high efficiency of the annotation process, high accuracy and high consistency of the annotation results. High efficiency and high accuracy are easy to understand. What does high consistency mean? In the BEV algorithm for 3D recognition, engineers need to use joint annotation of lidar and vision, and need to jointly process point cloud and image data. In this kind of processing link, engineers may also need to make some annotations at the timing level, so that the results of the previous and next frames cannot be too different.
If manual annotation is used, the annotation effect depends on the annotation level of the annotator. The uneven level of annotators may lead to inconsistency in the annotation results, and there may be annotations in one picture. The frame is larger and the next one is smaller. The annotation results of the large model are generally more consistent.
However, some industry experts have reported that there will be some difficulties in implementing automatic annotation using large models into practical applications, especially in the connection between autonomous driving companies and annotation companies—— Many autonomous driving companies will outsource part of the labeling work to labeling companies. Some companies do not have an internal labeling team and all labeling work is outsourced.
Currently, the targets that are annotated using the large model pre-annotation method are mainly dynamic 3D targets. The autonomous driving company will first use the large model to do inference on the video that needs to be annotated, and then Give the result of inference - the 3D box generated by the model to the annotation company. When pre-annotating a large model first, and then handing the pre-annotated results to an annotation company, there are two main problems involved: one is that the annotation platforms of some annotation companies may not necessarily support loading pre-annotated results; Another is that the annotation company is not necessarily willing to make modifications to the pre-annotated results.
If an annotation company wants to load pre-annotated results, it needs a software platform that supports loading of 3D frames generated by large models. However, some annotation companies may mainly use manual annotation, and they do not have a software platform that supports loading model pre-annotation results. If they get pre-annotated model results when connecting with customers, they have no way to accept it.
In addition, from the perspective of annotation companies, only if the pre-annotation effect is good enough can they truly "save effort", otherwise they may be increasing their workload.
If the pre-labeling effect is not good enough, the labeling company still needs to do a lot of work in the future, such as labeling missing boxes, deleting incorrectly labeled boxes, and adjusting the size of the boxes. Uniformity etc. Then, using pre-annotation may not really help them reduce their workload.
Therefore, in practical applications, whether to use a large model for pre-annotation needs to be weighed by both the autonomous driving company and the annotation company.
Of course, the current cost of manual annotation is relatively high - if the annotation company is allowed to start from scratch, the cost of manual annotation of 1,000 frames of video data may reach 10,000 yuan. Therefore, autonomous driving companies still hope to improve the accuracy of large model pre-labeling as much as possible and reduce the workload of manual labeling as much as possible, thereby reducing labeling costs.
1.1.2 Data Mining
Large models have strong generalization , suitable for mining long-tail data.
An expert from WeRide told the author: If the traditional tag-based method is used to mine long-tail scenes, the model can generally only distinguish known image categories. In 2021, OpenAI released the CLIP model (a text-image multi-modal model that can correspond text and images after unsupervised pre-training, thereby classifying images based on text instead of relying only on the labels of the images) ), we can also adopt such a text-image multi-modal model and use text descriptions to retrieve image data in the drive log. For example, long-tail scenes such as ‘construction vehicles dragging cargo’ and ‘traffic lights with two light bulbs on at the same time’.
In addition, large models can better extract features from the data and then find targets with similar features.
Suppose we want to find pictures containing sanitation workers from many pictures. We do not need to specifically label the pictures first. We can pre-train the large model with a large number of pictures containing sanitation workers. , the large model can extract some characteristics of sanitation workers. Then, samples that match the characteristics of sanitation workers are found from the pictures, thereby mining out almost all pictures containing sanitation workers.
1.1.3 Use knowledge distillation to "teach" small models
Big Models can also use knowledge distillation to “teach” small models.
What is knowledge distillation? To explain it in the most popular terms, the large model first learns some knowledge from the data, or extracts some information, and then uses the learned knowledge to "teach" the small model.
In practice, we can first learn the images that need to be labeled by the large model, and the large model can label these images. In this way, we have labeled images. Pictures, using these pictures to train small models is the simplest way of knowledge distillation.
Of course, we can also use more complex methods, such as first using a large model to extract features from massive data, and these extracted features can be used to train small models. In other words, we can also design a more complex model and add a medium model between the large model and the small model. The features extracted by the large model first train the medium model, and then use the trained medium model to extract features and give them to the small model. use. Engineers can choose the design method according to their own needs.
The author learned from Xiaoma.ai that based on the distillation and finetune of features extracted from large models, small models such as pedestrian attention and pedestrian intention recognition can be obtained. Moreover, due to the feature extraction stage By sharing a large model, the amount of calculation can be reduced.
1.1.4 Performance upper limit of the test vehicle model
Large models are okay Used to test the performance upper limit of the car-side model. When some companies consider which model to deploy on the car end, they will first test several alternative models in the cloud to see which model has the best effect and to what extent the best performance can be achieved after increasing the number of parameters.
Then, use the best-performing model as the basic model, then tailor and optimize the basic model before deploying it to the vehicle.
1.1.5 Reconstruction and data generation of autonomous driving scenarios
Haimo Zhixing is here It was mentioned on AI DAY in January 2023: “Using NeRF technology, we can implicitly store the scene in the neural network, and then learn the implicit parameters of the scene through supervised learning of rendered pictures, and then automatically Reconstruction of the driving scene."
For example, we can input pictures, corresponding poses, and colored scene dense point clouds into the network, and based on the point grid network, the colored point clouds will be displayed at different resolutions according to the pose of the input picture. Perform rasterization to generate neural descriptors at multiple scales, and then fuse features at different scales through the network.
Then, the descriptor, position, corresponding camera parameters and image exposure parameters of the generated dense point cloud are input into the subsequent network for fine-tuned tone mapping, and then the synthesis can be performed Produce pictures with consistent color and exposure.
In this way, we can reconstruct the scene. Then, we can generate various high-reality data by changing the perspective, changing the lighting, and changing the texture material. For example, by changing the perspective, we can simulate various main vehicle behaviors such as lane changes, detours, U-turns, etc., and even simulate some impending collisions. high-risk scenario data.
1.2.1 Merge small models used to detect different tasks
The main form of using large models on the car side is to merge small models that handle different subtasks to form a "big model", and then do joint reasoning. The "large model" here does not mean a large number of parameters in the traditional sense - for example, a large model with over 100 million parameters. Of course, the combined model will be much larger than the small model that handles different subtasks.
In traditional car-side perception models, models that handle different subtasks do inference independently. For example, one model is responsible for the lane line detection task, and another model is responsible for the traffic light detection task. As the perception tasks increase, engineers will correspondingly add models for perceiving specific targets in the system.
The previous automatic driving system had fewer functions and the perception tasks were relatively easy. However, with the upgrade of the functions of the automatic driving system, there are more and more perception tasks. If different tasks are still used separately If the small model responsible for the corresponding task is used for independent reasoning, the system delay will be too large and there will be security risks.
Juefei Technology’s BEV multi-task perception framework combines small single-task perception models of different targets to form a system that can output static information at the same time - including lane lines, ground Arrows, intersection zebra crossings, stop lines, etc., as well as dynamic information - including the location, size, orientation, etc. of traffic participants. The BEV multi-task perception algorithm framework of Juefei Technology is shown in the figure below:
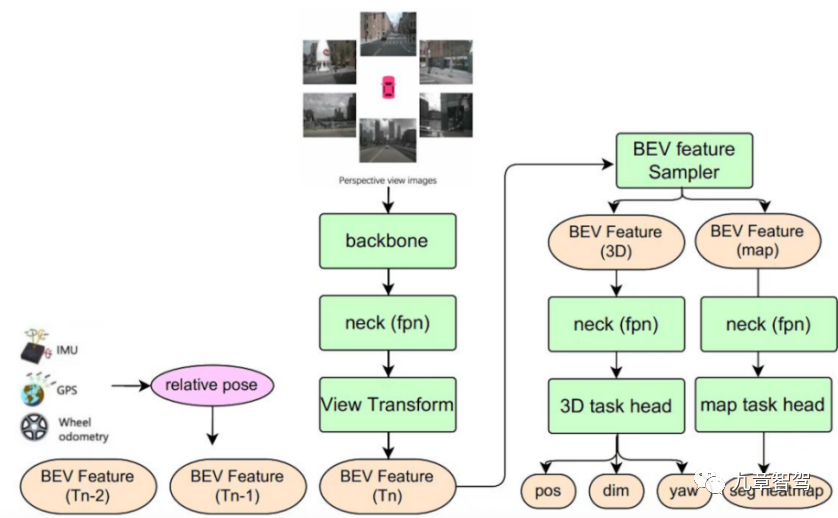
## Juefei Technology BEV Multi- Schematic diagram of task awareness algorithm framework
This multi-task awareness model realizes the temporal fusion of features - storing BEV features at historical moments in the feature queue, and during the inference phase, based on the current The self-vehicle coordinate system at the time is used as the benchmark, and the BEV features at the historical time are spatio-temporally aligned (including feature rotation and translation) according to the self-vehicle motion state, and then the aligned BEV features at the historical time are spliced with the BEV features at the current time.
In autonomous driving scenarios, timing fusion can improve the accuracy of the perception algorithm and make up for the limitations of single-frame perception to a certain extent. Taking the 3D target detection subtask shown in the figure as an example, with temporal fusion, the perception model can detect some targets that cannot be detected by the single-frame perception model (such as targets that are occluded at the current moment), and can also judge the target more accurately. movement speed, and assist downstream tasks in target trajectory prediction.
Dr. Qi Yuhan, head of BEV sensing technology at Juefei Technology, told the author: Using such a model architecture, when sensing tasks become more and more complex, the multi-task joint sensing framework can It ensures real-time perception and can also output more and more accurate perception results for downstream use of the autonomous driving system.
However, the merging of multi-task small models will also bring some problems. From an algorithmic level, the performance of the merged model on different subtasks may be "rolled back" - that is, the performance of model detection is lower than that of the independent single-task model. Although the network structure of a large model formed by merging different small models can still be very sophisticated, the combined model needs to solve the problem of multi-task joint training.
In multi-task joint training, each sub-task may not be able to achieve simultaneous and synchronous convergence, and each task will be affected by "negative transfer", and the combined model will Accuracy "rollback" occurs on certain tasks. The algorithm team needs to optimize the merged model structure as much as possible, adjust the joint training strategy, and reduce the impact of the "negative transfer" phenomenon.
1.2.2 Object Detection
An industry expert told the author: Some real Objects with relatively fixed values are suitable for detection with large models.
So, what is an object whose truth value is relatively fixed?
The so-called objects with fixed truth values are objects whose true value will not be affected by factors such as weather and time, such as lane lines, pillars, lamp posts, traffic lights, zebra crossings, and basements. Parking lines, parking spaces, etc. The existence and location of these objects are fixed and will not change due to factors such as rain or darkness. As long as the vehicle passes through the corresponding area, their positions are fixed. Such objects are suitable for detection with large models.
1.2.3 Lane topology prediction
An autonomous driving company’s AI in the company DAY mentioned: "Based on the BEV feature map, we use the standard map as guidance information, and use the autoregressive encoding and decoding network to decode the BEV features into a structured topological point sequence to achieve lane topology prediction."
With the trend of open source in the industry, the basic model framework is no longer a secret . Many times, what determines whether a company can make a good product is its engineering capabilities.
Engineering capabilities determine whether we can quickly verify the feasibility of the idea when we think of some methods that may be effective in improving system capabilities. The big thing that Tesla and Open AI have in common is that both companies have strong engineering capabilities. They can test the reliability of an idea as quickly as possible and then apply large-scale data to the selected model.
To fully utilize the capabilities of large models in practice, the company's engineering capabilities are very important. Next, we will explain what kind of engineering capabilities are needed to make good use of large models according to the model development process.
The large model has a large number of parameters. Correspondingly, the data used to train the large model The portion is also huge. For example, Tesla’s algorithm team used approximately 1.4 billion images to train the 3D-occupancy network that the team talked about at AI Day last year.
In fact, the initial value of the number of images will probably be dozens or hundreds of times the actual number used, because we need to first filter out the valuable ones for model training from the massive data. Data, therefore, since the pictures used for model training are 1.4 billion, the number of original pictures must be much greater than 1.4 billion.
So, how to store tens of billions or even hundreds of billions of image data? This is a huge challenge for both file reading systems and data storage systems. In particular, the current autonomous driving data is in the form of clips, and the number of files is large, which requires high efficiency in the immediate storage of small files.
In order to cope with such challenges, some companies in the industry use slice storage methods for data, and then use distributed architecture to support multi-user and multi-concurrent access. The data throughput bandwidth can be Reaching 100G/s, I/O latency can be as low as 2 milliseconds. The so-called multi-user refers to many users accessing a certain data file at the same time; multi-concurrency refers to the need to access a certain data file in multiple threads. For example, when engineers train a model, they use multi-threading. Each thread All require the use of a certain data file.
With big data, how to ensure that the model abstracts the data information better? This requires the model to have a network architecture suitable for the corresponding tasks, so that the advantage of the large number of parameters of the model can be fully utilized, so that the model has strong information extraction capabilities.
Lucas, senior manager of large model R&D at SenseTime, told the author: We have a standardized, industrial-grade semi-automatic very large model design system. We rely on this system to design the network architecture of very large models. At this time, you can use a neural network search system as a base to find the most suitable network architecture for learning large-scale data.
When designing small models, we mainly rely on manual design, tuning, and iteration to finally obtain a model with satisfactory results. Although this model is not necessarily optimal, But after iteration, it can basically meet the requirements.
When faced with large models, because the network structure of large models is very complex, if manual design, tuning and iteration are used, it will consume a lot of computing power, and accordingly Land costs are also high. So, how to quickly and efficiently design a network architecture that is good enough for training with limited resources is a problem that needs to be solved.
Lucas explained that we have a set of operator libraries, and the network structure of the model can be viewed as the permutation and combination of this set of operators. This industrial-grade search system can calculate how to arrange and combine operators by setting basic parameters, including how many layers of networks and how large the parameters are, to achieve better model effects.
The model performance can be evaluated based on some criteria, including the prediction accuracy for certain data sets, the memory used by the model when running, and the time required for model execution. wait. By giving these metrics appropriate weights, we can continue to iterate until we find a satisfactory model. Of course, in the search stage, we will first try to use some small scenes to initially evaluate the effect of the model.
When evaluating the effect of the model, how to choose some more representative scenes?
Generally speaking, you can choose some common scenarios. The network architecture is designed mainly to ensure that the model has the ability to extract key information from a large amount of data, rather than to hope that the model can learn the characteristics of certain specific scenarios. Therefore, after determining the model architecture, the model will be used To complete some tasks of mining long-tail scenarios, but when selecting a model architecture, general scenarios will be used to evaluate the model's capabilities.
With a high-efficiency and high-precision neural network search system, the calculation efficiency and calculation accuracy are high enough, so that the model effect can quickly converge and it can be quickly found in a huge space. A network architecture that works well.
After the previous basic work is done, we come to the training link. There is a lot to value in the training link. Optimization place.
2.3.1 Optimization operator
Neural network can be understood as consisting of many basic It is derived from the permutation and combination of operators. On the one hand, the calculation of operators occupies computing power resources, and on the other hand, it occupies memory. If the operator can be optimized to improve the computational efficiency of the operator, then the training efficiency can be improved.
There are already some AI training frameworks on the market - such as PyTorch, TensorFlow, etc. These training frameworks can provide basic operators for machine learning engineers to call to build their own models. . Some companies will build their own training framework and optimize the underlying operators in order to improve training efficiency.
PyTorch and TensorFlow need to ensure versatility as much as possible, so the operators provided by PyTorch and TensorFlow are generally very basic. Enterprises can integrate basic operators according to their own needs, eliminating the need to store intermediate results, saving memory usage, and avoiding performance losses.
In addition, in order to solve the problem that some specific operators cannot make good use of the parallelism of the GPU due to their high dependence on intermediate results during calculation, some companies in the industry have built their own acceleration library, which reduces the dependence of these operators on intermediate results, so that the calculation process can take full advantage of the parallel computing advantages of the GPU and improve the training speed.
For example, on four mainstream Transformer models, ByteDance’s LightSeq achieved up to 8 times acceleration based on PyTorch.
2.3.2 Make good use of parallel strategies
Parallel computing is a "use The "space-for-time" method is to parallelize data without computational dependencies as much as possible, split large batches into small batches, reduce GPU idle waiting time in each calculation step, and improve calculation throughput.
Many companies currently adopt the PyTorch training framework. This training framework includes the DDP mode - as a distributed data parallel training mode, the DDP mode designs a data distribution The mechanism can support multi-machine and multi-card training. For example, if a company has 8 servers and each server has 8 cards, then we can use 64 cards for training at the same time.
Without this mode, engineers can only use a single machine with multiple cards to train the model. Suppose we now use 100,000 image data to train the model. In single-machine multi-card mode, the training time will be more than a week. If we want to use the training results to evaluate a certain conjecture, or want to select the best one from several alternative models, such a training time will make the waiting period required to quickly verify the conjecture and quickly test the model effect very long. Then the R&D efficiency will be very low.
With multi-machine and multi-card parallel training, most of the experimental results can be seen in 2-3 days. In this way, the process of verifying the model effect is much faster.
In terms of specific parallel methods, model parallelism and sequence parallelism can be mainly used.
Model parallelism can be divided into Pipeline parallelism and Tensor parallelism, as shown in the figure below.
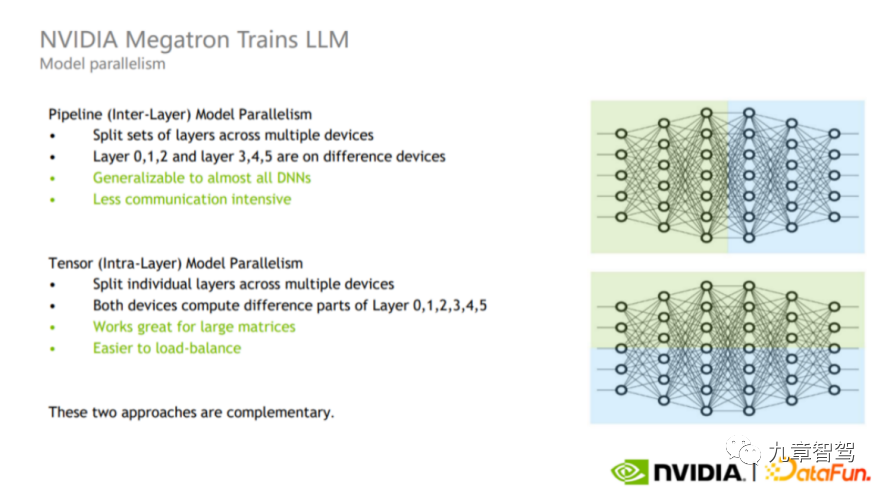
Schematic diagram of Pipeline parallelism and tensor parallelism, the picture comes from NVIDIA
Pipeline parallelism is inter-layer parallelism (upper part of the figure). During the training process, engineers can remember to divide different layers of the model into different GPUs for calculation. For example, as shown in the upper half of the figure, the green part of the layer and the blue part can be calculated on different GPUs.
Tensor parallelism is intra-layer parallelism (lower part of the figure). Engineers can divide the calculations of a layer into different GPUs. This mode is suitable for the calculation of large matrices because it can achieve load balancing between GPUs, but the number of communications and the amount of data are relatively large.
In addition to model parallelism, there is also Sequence parallelism. Since Tensor parallelism does not split Layer-norm and Dropout, these two operators will be repeated between each GPU. Calculation, although the amount of calculation is not large, it takes up a lot of active video memory.
In order to solve this problem, in the actual process, we can take advantage of the fact that Layer-norm and Dropout are independent of each other along the sequence dimensions (that is, Layer_norm between different layers and Dropout do not affect each other), split Layer-norm and Dropout, as shown in the figure below. The advantage of this split is that it does not increase the communication volume and can greatly reduce the memory usage.
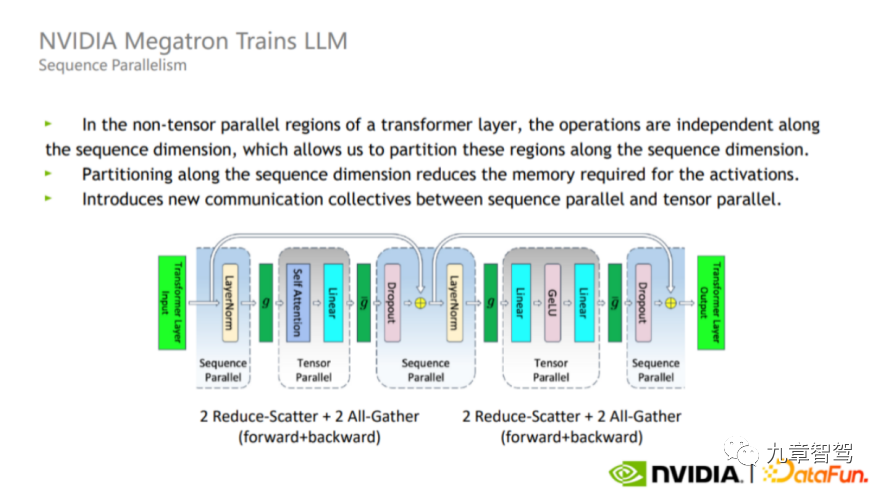
## Sequence parallel diagram, picture from NVIDIA
In practice, different models have different suitable parallel strategies. Engineers need to find a suitable parallel strategy after continuous debugging based on the characteristics of the model, the characteristics of the hardware used, and the intermediate calculation process.
2.3.3 Make good use of "sparse"
When training the model, we must make good use of sparsity, that is, not every neuron must be "activated"-that is, when adding training data, not every model parameter must be based on The newly added data is updated, but some model parameters remain unchanged, and some model parameters are updated with the newly added data.
Good sparse processing can ensure accuracy while improving model training efficiency.
For example, in a perception task, when new pictures are passed in, you can select the parameters that need to be updated based on these pictures to perform targeted feature extraction.
2.3.4 Unified processing of basic information
Generally speaking, there are more than A model will be used, and these models may use the same data. For example, most models use video data. If each model loads and processes the video data, there will be a lot of repeated calculations. We can uniformly process various modal information such as videos, point clouds, maps, CAN signals, etc. that most models need to use, so that different models can reuse the processing results.
2.3.5 Optimizing hardware configuration
When actually using distributed training , 1,000 machines may be used. How to obtain the intermediate results during the training process - such as gradients - from different servers that store data, and then conduct a very large-scale distributed training is a big challenge.
To deal with this challenge, we first need to consider how to configure the CPU, GPU, etc., how to select the network card, and how fast the network card is so that the transmission between machines can be fast.
Secondly, it is necessary to synchronize parameters and save intermediate results, but when the scale is large, this matter will become very difficult, which will involve some network communication work.
In addition, the entire training process takes a long time, so the stability of the cluster needs to be very high.
Now that large models can already play some role in the field of autonomous driving , if we continue to increase the model parameters, can we expect that the large model can show some amazing effects?
According to the author’s communication with algorithm experts in the field of autonomous driving, the current answer is probably no, because the “emergence” phenomenon mentioned above has not yet been applied in CV (computer vision) The field appears. Currently, the number of model parameters used in the field of autonomous driving is much smaller than that of ChatGPT. Because when there is no "emergence" effect, there is a roughly linear relationship between model performance improvement and the increase in the number of parameters. Considering cost constraints, companies have not yet maximized the number of parameters in the model.
Why has the phenomenon of “emergence” not yet occurred in the field of computer vision? An expert’s explanation is:
First of all, although there is far more visual data in the world than text data, image data is sparse, that is, it may not be in most photos. How much effective information is there, and most of the pixels in each image provide no effective information. If we take a selfie, except for the face in the middle, there is no valid information in the background area.
Secondly, the image data has significant scale changes and is completely unstructured. Scale change means that objects containing the same semantics can be large or small in the corresponding picture. For example, I first take a selfie, and then ask a friend who is far away to take another photo for me. In the two photos, the proportion of the face in the photo is very different. Unstructured means that the relationship between each pixel is uncertain.
But in the field of natural language processing, since language is a tool for communication between people, contexts are usually related, and the information density of each sentence is generally large. , and there is no problem of scale changes. For example, in any language, the word "apple" is usually not too long.
Therefore, the understanding of visual data itself will be more difficult than natural language.
An industry expert told the author: Although we can expect that the performance of the model will improve as the number of parameters increases, the current cost-effectiveness of continuing to increase the number of parameters is low.
For example, if we expand the capacity of the model ten times on the existing basis, its relative error rate can be reduced by 90%. At this time, the model can already complete some computer vision tasks such as face recognition. If we continue to expand the capacity of the model ten times at this time and the relative error rate continues to decrease by 90%, but the value it can achieve does not increase ten times, then there is no need for us to continue to expand the capacity of the model.
Expanding model capacity will increase costs, because larger models require more training data and more computing power. When the accuracy of the model reaches an acceptable range, we need to make a trade-off between rising costs and improving accuracy, and reduce costs as much as possible with acceptable accuracy according to actual needs.
Although there are still some tasks that we need to improve accuracy, large models mainly replace some manual work in the cloud, such as automatic annotation, data mining, etc., which can be done by humans. If the cost is too high, then the economic accounts will not be calculated.
But some industry experts told the author: Although it has not yet reached a qualitative change point, as the parameters of the model increase and the amount of data increases, we can indeed observe that the accuracy of the model has been In promotion. If the accuracy of the model used for the labeling task is high enough, the level of automated labeling will be improved, thereby reducing a lot of labor costs. At present, although the training cost will increase as the model size increases, the cost is roughly linearly related to the number of model parameters. Although the training cost will increase, the reduction in manpower can offset this increase, so increasing the number of parameters will still bring benefits.
In addition, we will also use some techniques to increase the number of model parameters while improving training efficiency to minimize training costs. We can increase the number of parameters of the model and improve the accuracy of the model while keeping the cost constant within the existing model scale. This is equivalent to preventing the cost of the model from increasing linearly with the increase in the number of model parameters. We can achieve almost no increase in cost or only a small increase.
In addition to the applications mentioned above, how else can we What about discovering the value of large models?
CMU Research Scientist Max told the author: The core of using large models to achieve perception tasks is not stacking parameters, but To create a framework that can 'internally circulate'. If the entire model cannot achieve internal looping, or cannot achieve continuous online training, it will be difficult to achieve good results.
So, how to implement the "inner loop" of the model? We can refer to the training framework of ChatGPT, as shown in the figure below.
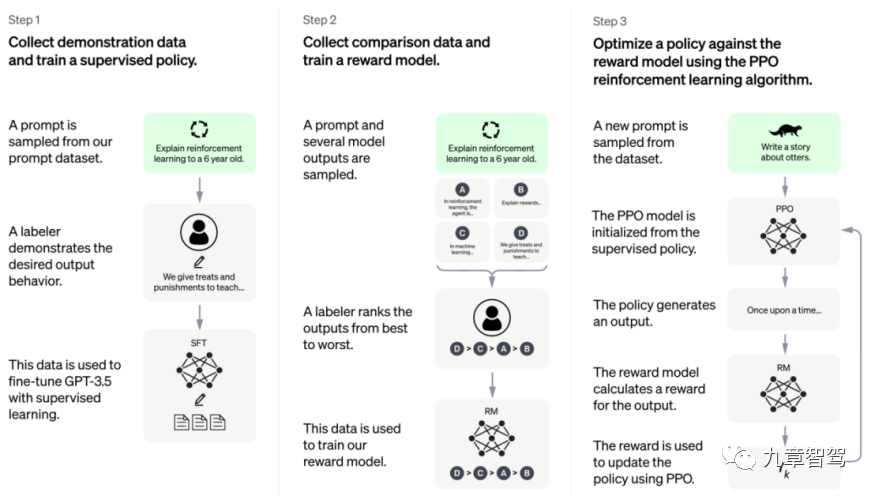
##ChatGPT training framework, the picture is taken from the Open AI official website
ChatGPT’s model framework can be divided into three steps: the first step is supervised learning. Engineers first collect and label a part of the data, and then use this part of the data to train the model; the second step is to design a reward model ( Reward Model), the model can output some labeling results by itself; in the third step, we can implement self-supervised learning through a path similar to reinforcement learning, which in more popular language is called "playing with yourself", or Say "inner loop".
As long as the third step is reached, the model no longer requires engineers to add labeled data. Instead, it can calculate the loss by itself after getting the unlabeled data, and then update the parameters, and so on. cycle, and finally complete the training.
"If we can design a suitable Reward Policy when doing perception tasks so that model training no longer relies on annotated data, we can say that the model has achieved an 'inner loop'. Parameters can be continuously updated based on unlabeled data.”
In fields such as Go, it is easier to judge the quality of each step, because our goal generally only includes winning the game in the end.
However, in the field of autonomous driving planning, the evaluation system for the behavior displayed by the autonomous driving system is unclear. In addition to ensuring safety, everyone has different feelings about comfort, and we may also want to reach our destination as quickly as possible.
Switching to the chat scene, whether the feedback the robot gives each time is "good" or "bad" is not actually a very clear evaluation system like Go. It's similar to this with self-driving, each person has different standards of what is "good" and "bad", and he or she may have needs that are difficult to articulate.
In the second step of the ChatGPT training framework, the annotator sorts the results output by the model, and then uses this sorted result to train the Reward Model. At the beginning, this Reward Model is not perfect, but through continuous training, we can make this Reward Model continue to approach the effect we want.
An expert from an artificial intelligence company told the author: In the field of autonomous driving planning, we can continuously collect data on car driving, and then tell the model under what circumstances a human will take over ( In other words, people will feel that there is danger), under what circumstances it can drive normally, then as the amount of data increases, the Reward Model will get closer and closer to perfection.
In other words, we can consider giving up explicitly writing a perfect Reward Model, and instead obtain a solution that is constantly approaching perfection by continuously giving feedback to the model.
Compared with the current common practice in the field of planning, which is to try to explicitly find the optimal solution by relying on manual writing rules, first using an initial Reward Model, and then continuously optimizing based on the data , is a paradigm shift.
After adopting this method, the optimization planning module can adopt a relatively standard process. All we need to do is to continuously collect data and then train the Reward Model, which is no longer like the traditional method. That depends on the depth of an engineer's understanding of the entire planning module.
In addition, all historical data can be used for training. We don’t have to worry about that after a certain rule change, although some of the current problems are solved, some of them have been used before. Problems that were solved reappear that would have plagued us had we adopted traditional methods.
The above is the detailed content of A long article of 10,000 words explains the application of large models in the field of autonomous driving. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



