


I didn’t expect that ChatGPT would still make stupid mistakes to this day?
Master Andrew Ng pointed it out at the latest class:
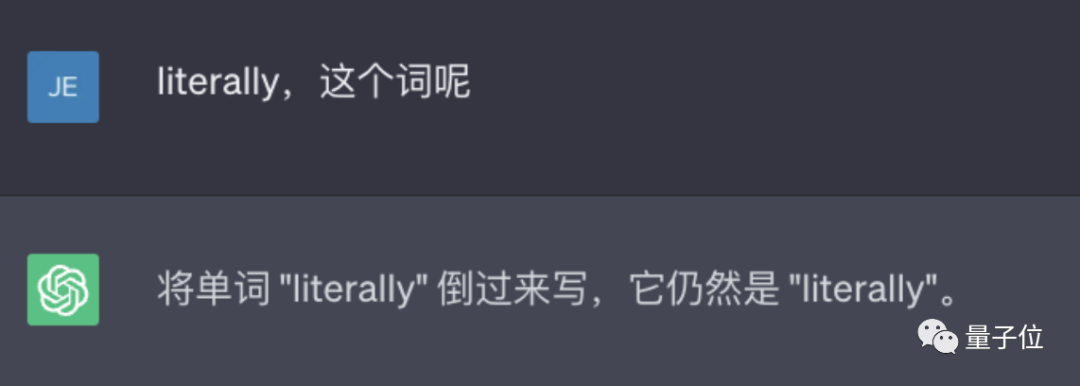
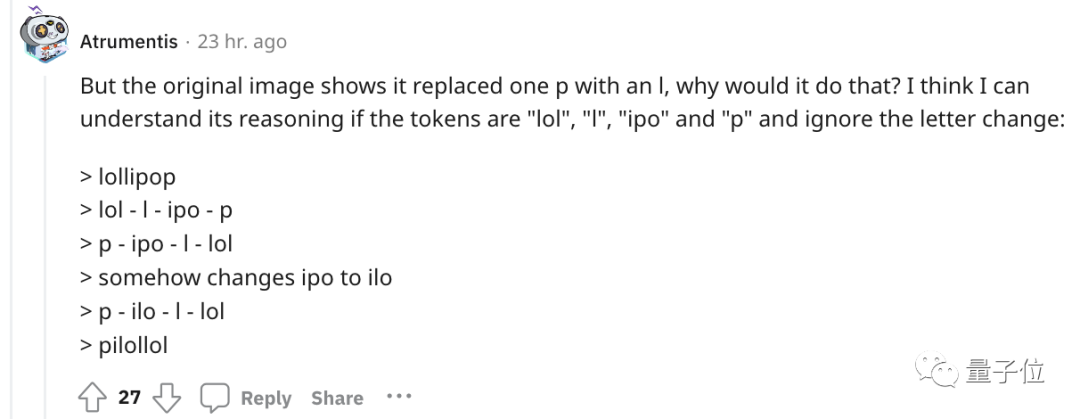
ChatGPT will not reverse words!
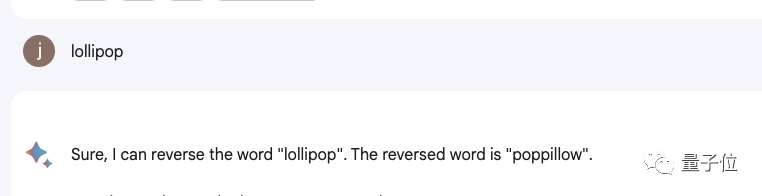
For example, let it reverse the word lollipop, and the output is pilollol, which is completely confusing.

Oh, this is indeed a bit surprising.
So much so that after netizens who listened to the class posted on Reddit, they immediately attracted a large number of onlookers, and the post quickly reached 6k views.
And this is not an accidental bug. Netizens found that ChatGPT is indeed unable to complete this task, and the results of our personal testing are also the same.




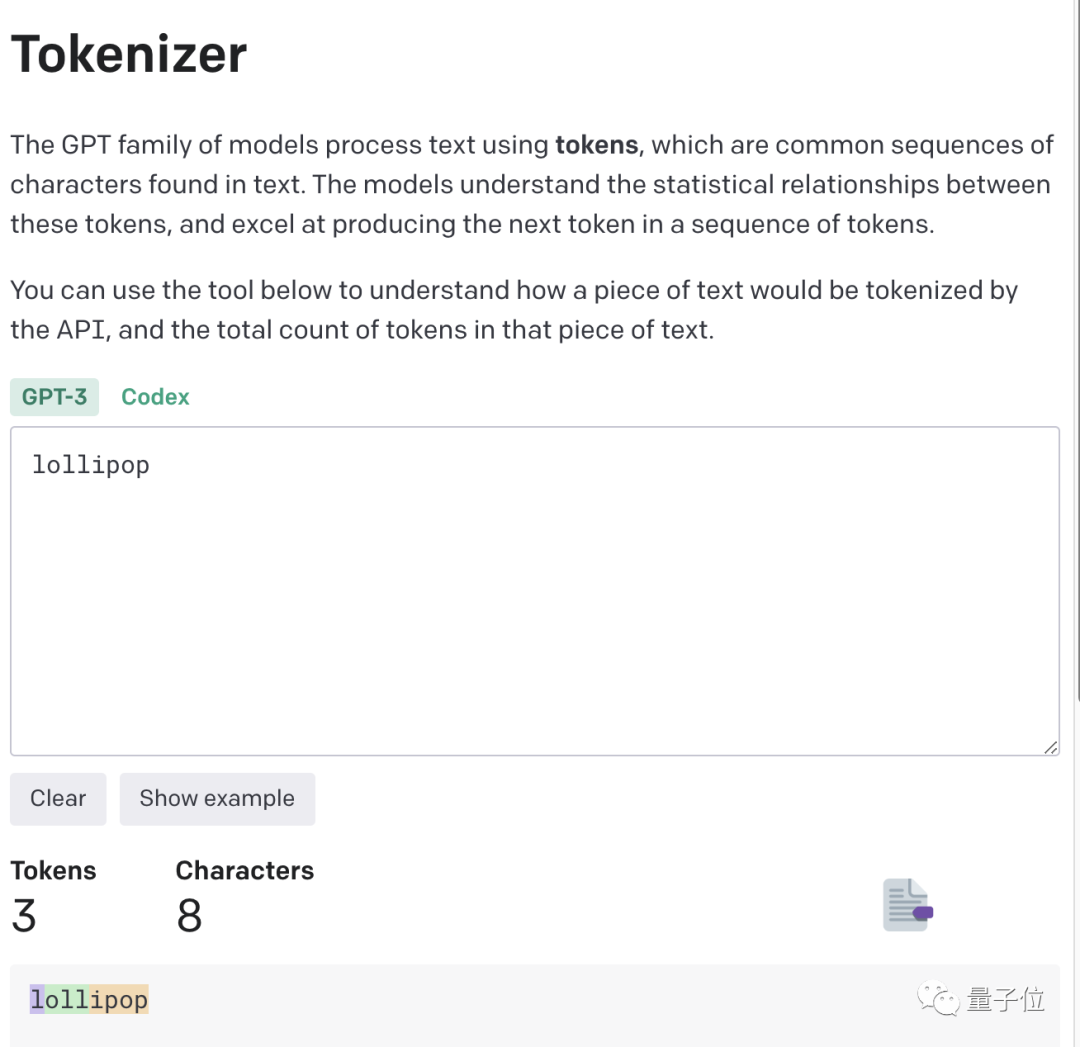
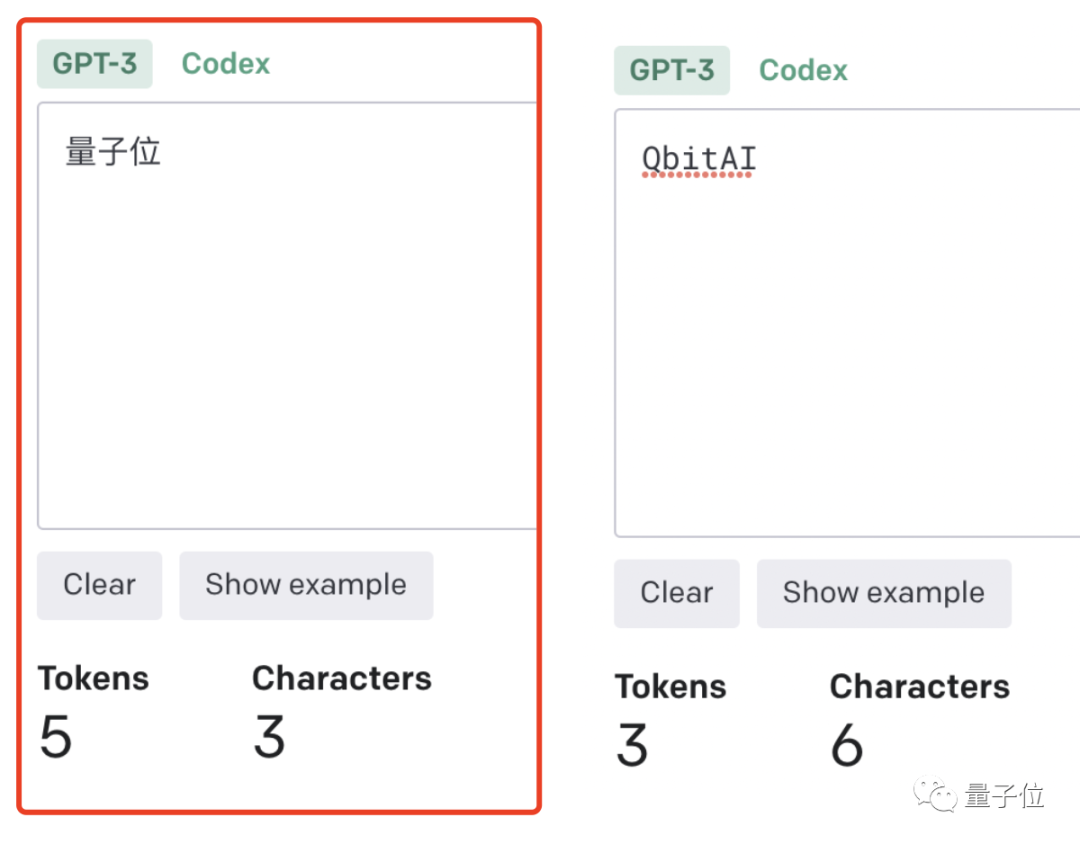
The higher the token-to-char (token to word) ratio, the higher the processing cost. Therefore, processing Chinese tokenize is more expensive than English.
It can be understood that token is a way for large models to understand the real world of humans. It's very simple and greatly reduces memory and time complexity.
But there is a problem with tokenizing words, which makes it difficult for the model to learn meaningful input representations. The most intuitive representation is that it cannot understand the meaning of the words.
At that time, Transformers had done corresponding optimization. For example, a complex and uncommon word was divided into a meaningful token and an independent token.
Just like "annoyingly" is divided into two parts: "annoying" and "ly", the former retains its own meaning, while the latter is more common.
This has also resulted in the amazing effects of ChatGPT and other large model products today, which can understand human language very well.
As for the inability to handle such a small task as word reversal, there is naturally a solution.
The simplest and most direct way is to separate the words yourself~

Or you can let ChatGPT do it step by step , first tokenize each letter.

Or maybe let it write a program that reverses letters, and then the result of the program is correct. (dog head)

However, GPT-4 can also be used, and there is no such problem in actual testing.

In short, token is the cornerstone of AI’s understanding of natural language.
As a bridge for AI to understand human natural language, the importance of tokens has become increasingly obvious.
It has become a key determinant of the performance of AI models and the billing standard for large models.
As mentioned above, token can facilitate the model to capture more fine-grained semantic information, such as word meaning, word order, grammatical structure, etc. In sequence modeling tasks (such as language modeling, machine translation, text generation, etc.), position and order are very important for model building.
Only when the model accurately understands the position and context of each token in the sequence can it predict the content better and correctly and give reasonable output.
Therefore, the quality and quantity of tokens have a direct impact on the model effect.
Starting this year, when more and more large models are released, the number of tokens will be emphasized. For example, the details of the exposure of Google PaLM 2 mentioned that it used 3.6 trillion tokens for training.
And many big names in the industry have also said that tokens are really crucial!
Andrej Karpathy, an AI scientist who switched from Tesla to OpenAI this year, said in his speech:
More tokens can enable models Think better.

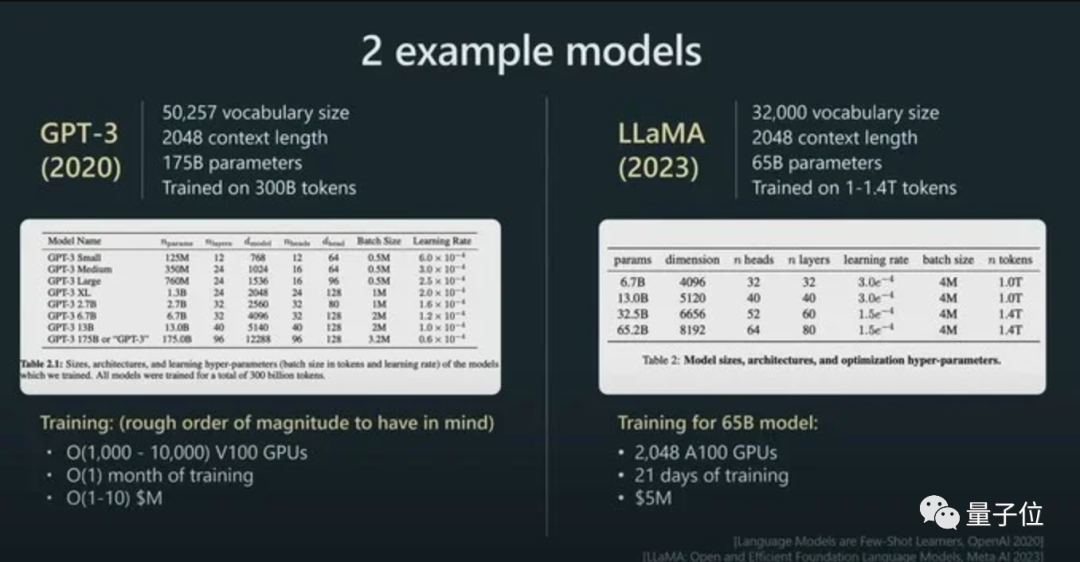
And he emphasized that the performance of the model is not determined solely by the parameter size.
For example, the parameter size of LLaMA is much smaller than that of GPT-3 (65B vs 175B), but because it uses more tokens for training (1.4T vs 300B), LLaMA is more powerful.
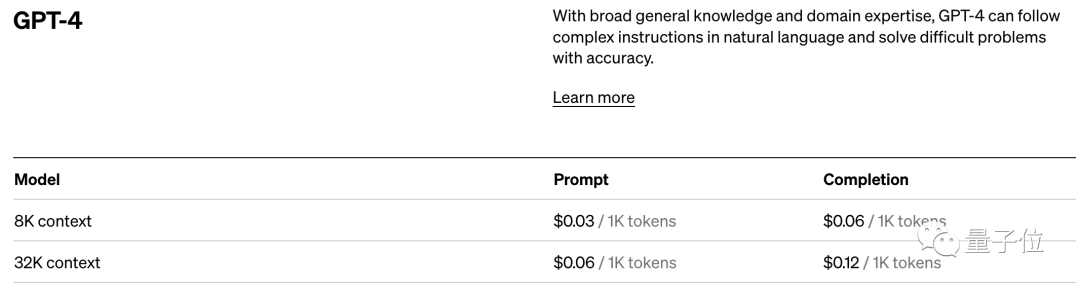
With its direct impact on model performance, token is still the billing standard for AI models.
Take OpenAI’s pricing standard as an example. They charge in units of 1K tokens. Different models and different types of tokens have different prices.
In short, once you step into the field of AI large models, you will find that token is an unavoidable knowledge point.
Well, even token literature has been derived...
But it is worth mentioning that, what role does token play in the Chinese world? What it should be translated into has not been fully decided yet.
The literal translation of "token" is always a bit weird.
GPT-4 thinks it is better to call it "word element" or "tag", what do you think?

Reference link:
[1]https://www.reddit.com/r/ChatGPT/comments/13xxehx/chatgpt_is_unable_to_reverse_words/
[2]https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them
[3]https://openai.com /pricing
The above is the detailed content of Andrew Ng's ChatGPT class went viral: AI gave up writing words backwards, but understood the whole world. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



