


There is a story about the Tower of Babel in the Bible. It is said that human beings united to plan to build a high tower, hoping to lead to heaven, but God disrupted human language and the plan failed. Today, AI technology is expected to tear down the barriers between human languages and help mankind create a civilized Tower of Babel.
Recently, a study by Meta has taken an important step towards this aspect. They call the newly proposed method Massively Multilingual Speech (MMS), which is based on "The Bible" was used as part of the training data and the following results were obtained:
How does Meta solve the problem of data scarcity in many rare languages? The method they used is interesting, using religious corpora, because corpora like the Bible have the most "aligned" speech data. Although this dataset is skewed toward religious content and features mostly male voices, the paper shows that the model performs well in other domains as well when using female voices. This is the emergent behavior of the base model, and it's truly amazing. What’s even more amazing is that Meta has released all newly developed models (speech recognition, TTS and language recognition) for free!
In order to create a speech model that can recognize thousands of words, the first challenge is to collect audio data in various languages, because the largest speech data set currently available is only Up to 100 languages. To overcome this problem, Meta researchers used religious texts, such as the Bible, which have been translated into many different languages, and those translations have been extensively studied. These translations have audio recordings of people reading them in different languages, and these audios are also publicly available. Using these audios, the researchers created a dataset containing audio of people reading the New Testament in 1,100 languages, with an average audio length of 32 hours per language.
They then included unannotated recordings of many other Christian readings, increasing the number of available languages to more than 4,000. Although the field of this data set is single and mostly consists of male voices, the analysis results show that Meta’s newly developed model performs equally well on female voices, and the model is not particularly biased towards producing more religious language. The researchers stated in the blog that this is mainly due to the Connectionist Temporal Classification method they used, which is far superior to large language models (LLM) or sequence-to-sequence speech recognition models. More restricted.
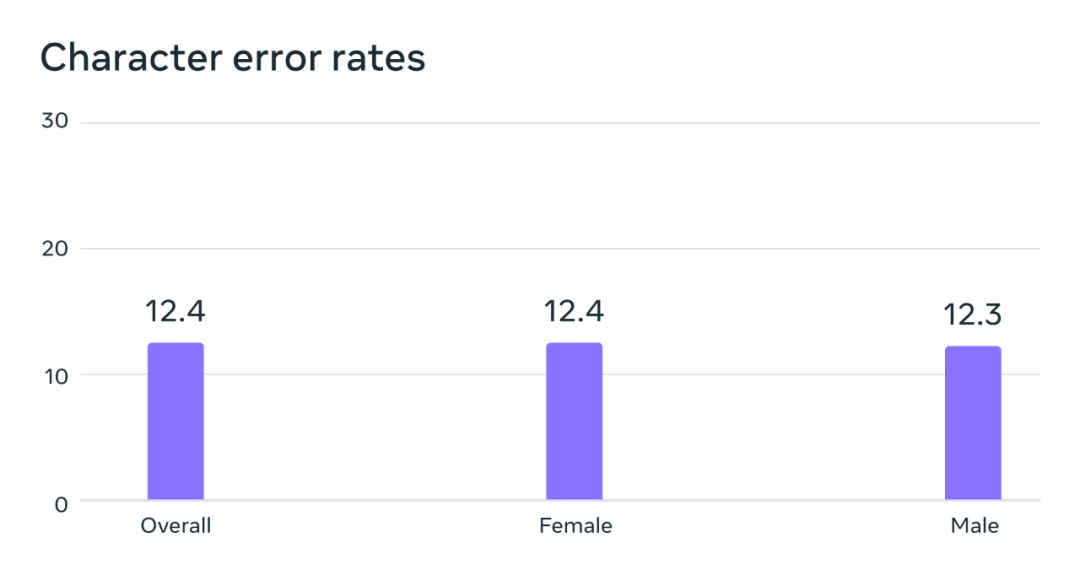
# Analysis of potential gender bias situations. On the FLEURS benchmark, this automatic speech recognition model trained on the Multilingual Speech (MMS) dataset has similar error rates for male and female voices.
In order to improve the quality of data so that it can be used by machine learning algorithms, they also adopted some preprocessing methods. First, they trained an alignment model on existing data from more than 100 languages, and then paired it with an efficient forced alignment algorithm that can handle very long recordings of more than 20 minutes. Afterwards, after multiple rounds of alignment processes, a final step of cross-validation filtering is performed to remove potentially misaligned data based on model accuracy. In order to facilitate other researchers to create new speech data sets, Meta added the alignment algorithm to PyTorch and released the alignment model.
To train a generally usable supervised speech recognition model, just 32 hours of data per language is not enough. Therefore, their model is developed based on wav2vec 2.0, which is their previous research on self-supervised speech representation learning, which can greatly reduce the amount of labeled data required for training. Specifically, the researchers trained a self-supervised model using approximately 500,000 hours of speech data in more than 1,400 languages—more than five times more languages than any previous study. Then, based on specific speech tasks (such as multilingual speech recognition or language recognition), the researchers fine-tune the resulting model.
The researchers evaluated the newly developed model on some existing benchmarks.
The training of its multi-language speech recognition model uses the wav2vec 2.0 model with 1 billion parameters, and the training data set contains more than 1,100 languages. Model performance does decrease as the number of languages increases, but the decrease is very small: when the number of languages increases from 61 to 1107, the character error rate increases by only 0.4%, but the language coverage increases by more than 18 times.
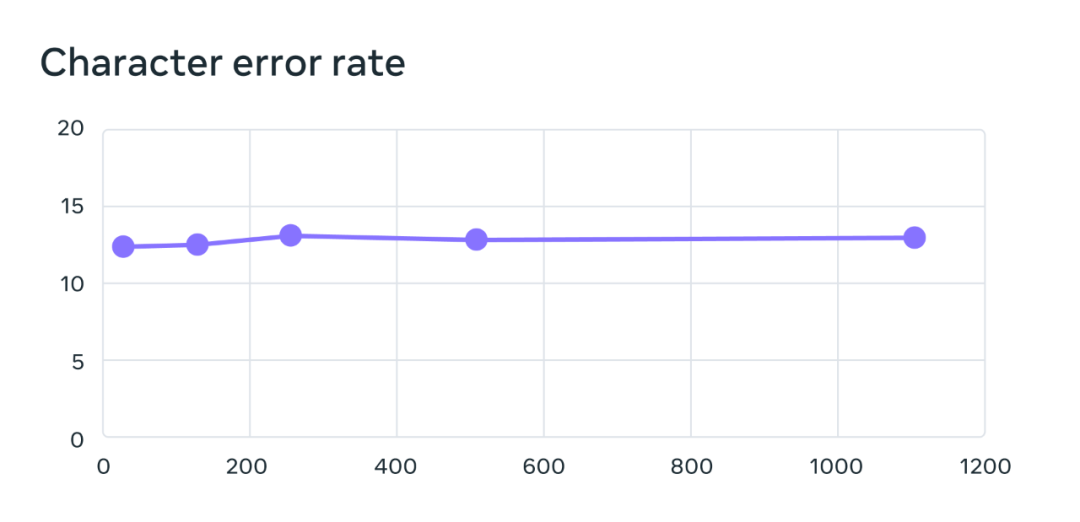
On the benchmark test of 61 FLEURS languages, the character error rate changes as the number of languages increases, error rate The higher it is, the worse the model is.
By comparing OpenAI's Whisper model, the researchers found that their model's word error rate was only half that of Whisper, while the new model supported 11 times more languages. This result demonstrates the superior capabilities of the new method.
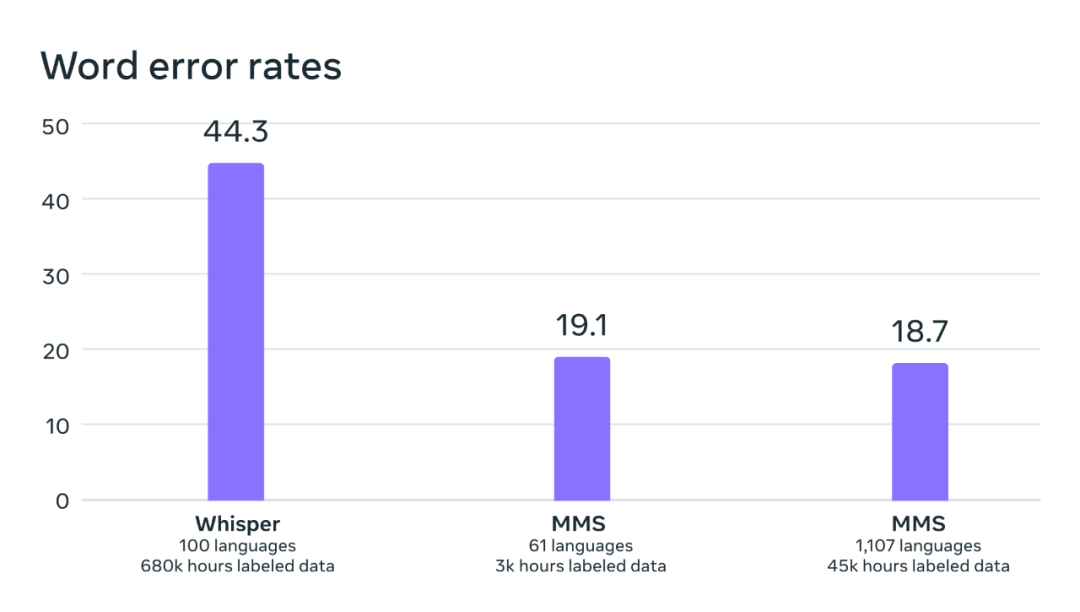
Comparison of word error rates between OpenAI Whisper and MMS on benchmarks of 54 directly comparable FLEURS languages .
Next, using previously existing data sets (such as FLEURS and CommonVoice) and new data sets, Meta researchers also trained a language identification (LID) model and used The FLEURS LID task was evaluated. The results show that not only does the new model perform great, but it also supports 40 times more languages.
Previous research also only supported more than 100 languages on the VoxLingua-107 benchmark, while MMS supports more than 4000 languages.
In addition, Meta has built a text-to-speech system that supports 1,100 languages. The training data for current text-to-speech models is usually speech corpus from a single speaker. One limitation of the MMS data is that many languages have only a small number of speakers, often even a single speaker. However, this became an advantage when building a text-to-speech system, so Meta built a TTS system that supports more than 1,100 languages. Researchers say the quality of speech generated by these systems is actually quite good, and several examples are given below.
Demo of MMS text-to-speech model for Yoruba, Iroko and Maithili languages.
Despite this, researchers say that AI technology is still not perfect, and the same is true for MMS. For example, MMS may mistranscribe selected words or phrases during speech-to-text. This may result in offensive and/or inaccurate language in the output. The researchers emphasized the importance of working with the AI community to develop responsibly.
Many languages around the world are endangered, and the limitations of current speech recognition and speech generation technology will only further accelerate this trend. The researcher imagined in the blog: Maybe technology can encourage people to retain their own language, because with good technology, they can use their favorite language to obtain information and use technology.
They believe the MMS project is an important step in this direction. They also said that the project will continue to be developed and will support more languages in the future, and will even solve the problems of dialects and accents.
The above is the detailed content of Meta uses the Bible to train a super multi-language model: recognize 1107 languages and identify 4017 languages. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



