


Currently, although AI models have been involved in a very wide range of application fields, most AI models are designed for specific tasks, and they often require a lot of manpower to complete the correct model architecture, optimization algorithms and hyperparameters. . After ChatGPT and GPT-4 became popular, people saw the huge potential of large language models (LLM) in text understanding, generation, interaction, reasoning, etc. Some researchers try to use LLM to explore new paths towards artificial general intelligence (AGI).
Recently, researchers from the University of Texas at Austin proposed a new idea - to develop task-oriented prompts and use LLM to automate the training pipeline, and based on this Idea launches a new system AutoML-GPT.

Paper address:
https: //m.sbmmt.com/link/39d4b545fb02556829aab1db805021c3
AutoML-GPT uses GPT as a bridge between various AI models and uses optimized hyperparameters to dynamically train the model. AutoML-GPT dynamically receives user requests from Model Card [Mitchell et al., 2019] and Data Card [Gebru et al., 2021] and composes corresponding prompt paragraphs. Finally, AutoML-GPT uses this prompt paragraph to automatically perform multiple experiments, including processing data, building model architecture, tuning hyperparameters, and predicting training logs.
AutoML-GPT solves complex AI tasks across a variety of tests and datasets by maximizing its powerful NLP capabilities and existing AI models. A large number of experiments and ablation studies have shown that AutoML-GPT is versatile and effective for many artificial intelligence tasks (including CV tasks and NLP tasks).
AutoML-GPT is a collaborative system that relies on data and model information to format prompt input paragraphs. Among them, LLM serves as the controller, and multiple expert models serve as collaborative executors. The workflow of AutoML-GPT includes four stages: data processing, model architecture design, hyperparameter adjustment and training log generation.
Specifically, the working mechanism of AutoML-GPT is as follows:
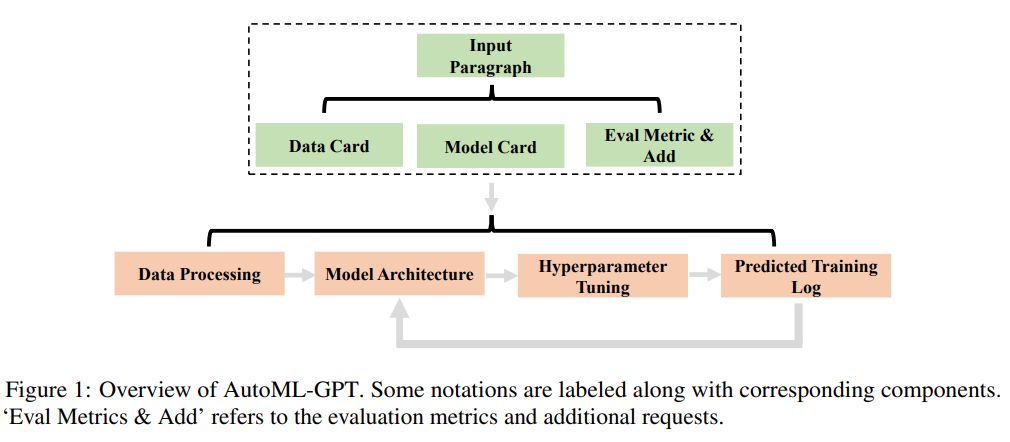
Input Decomposition
The first stage of AutoML-GPT is for LLM to accept user input. In order to improve the performance of LLM and generate effective prompts, this study adopts specific instructions for input prompts. These instructions include three parts: Data Card, Model Card, Evaluation Metrics and Additional Requirements.
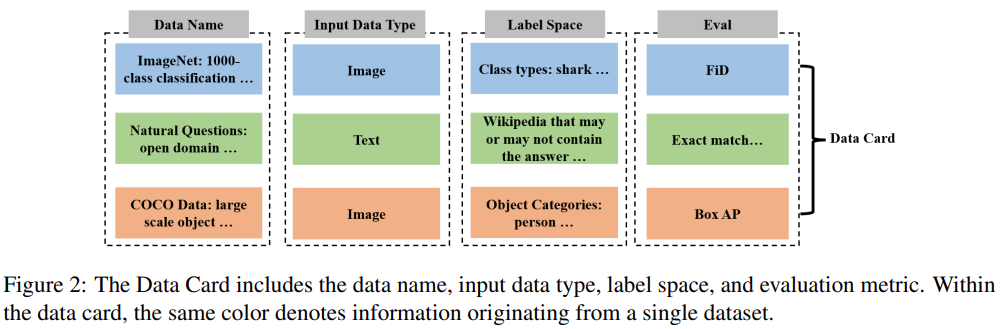
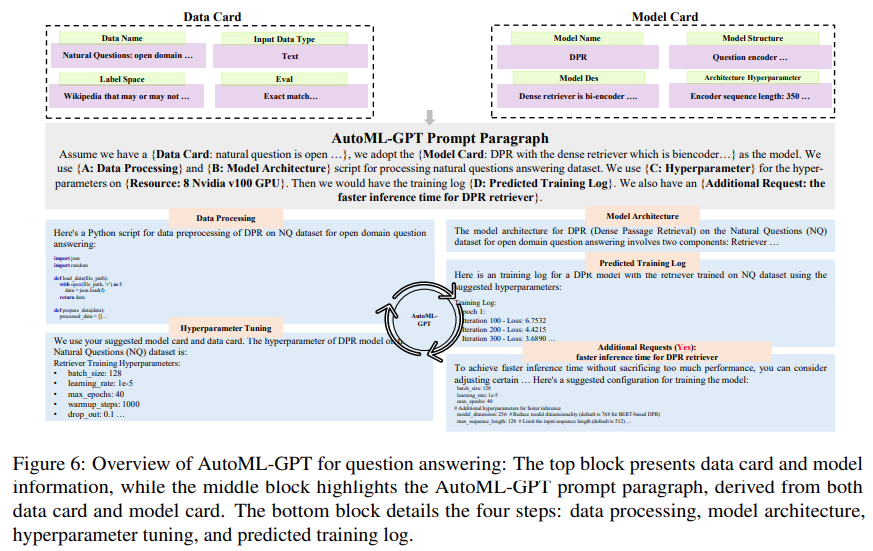
As shown in Figure 2 below, the key parts of the Data Card consist of the data set name, input data set type (such as image data or text data), label space (such as category or resolution) and default evaluation indicators.
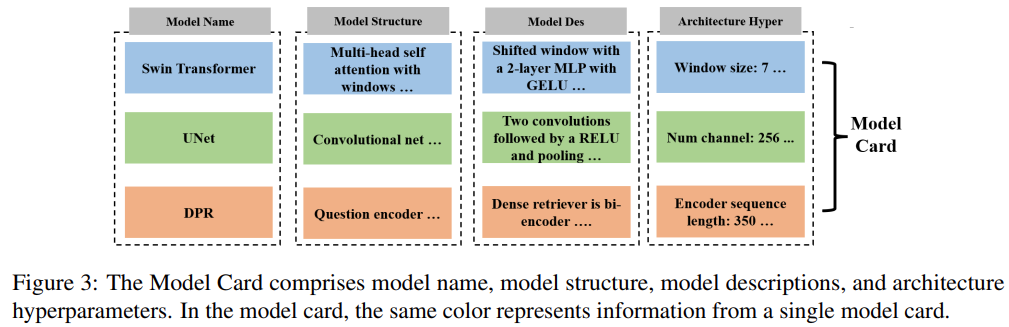
As shown in Figure 3 below, the Model Card consists of the model name, model structure, model description and architecture hyperparameters. By providing this information, the Model Card can tell LLM which models are used throughout the machine learning system, as well as the user's preferences for model architecture.
In addition to Data Card and Model Card, users can also choose to request more evaluation benchmarks, evaluation metrics, or any constraints. AutoML-GPT provides these task specifications as high-level instructions to LLM for analyzing user requirements accordingly.
When there is a series of tasks that need to be processed, AutoML-GPT needs to match the corresponding model for each task. In order to achieve this goal, the system first needs to obtain the model description from the Model Card and user input.
AutoML-GPT then uses the in-context task-model assignment mechanism to dynamically assign models to tasks. This approach enables incremental model access and provides greater openness and flexibility by combining model description with a better understanding of user needs.
Adjust hyperparameters using prediction training logs
AutoML-GPT sets hyperparameters based on Data Card and Model Card, And predict performance by generating training logs of hyperparameters. The system automatically performs training and returns training logs. Model performance training logs on the dataset record various metrics and information collected during the training process, which helps understand the model training progress, identify potential problems, and evaluate the effectiveness of the selected architecture, hyperparameters, and optimization methods .
To evaluate the performance of AutoML-GPT, this study uses ChatGPT (OpenAI’s GPT-4 version) to implement it and conducts multiple experiments from multiple This perspective shows the effect of AutoML-GPT.
Figure 4 below shows the results of training on an unknown data set using AutoML-GPT:

Figure 5 below shows the process of AutoML-GPT completing the target detection task on the COCO data set:
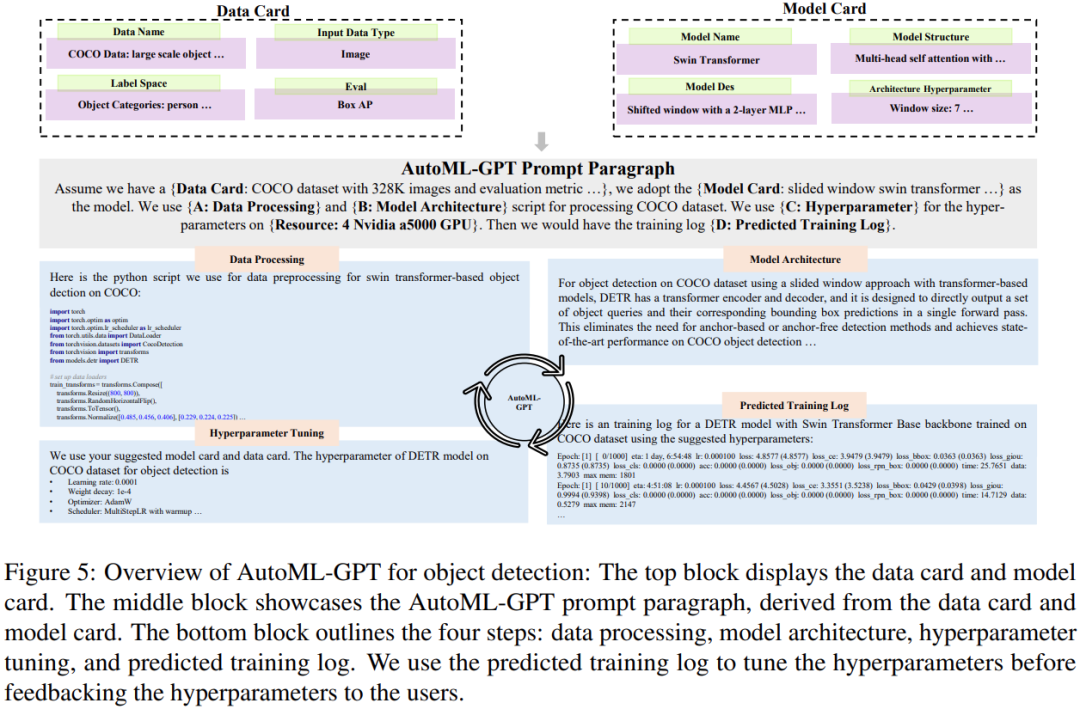
Figure 6 below shows AutoML-GPT Experimental results on the NQ Open Dataset (Natural Questions Open dataset, [Kwiatkowski et al., 2019]):
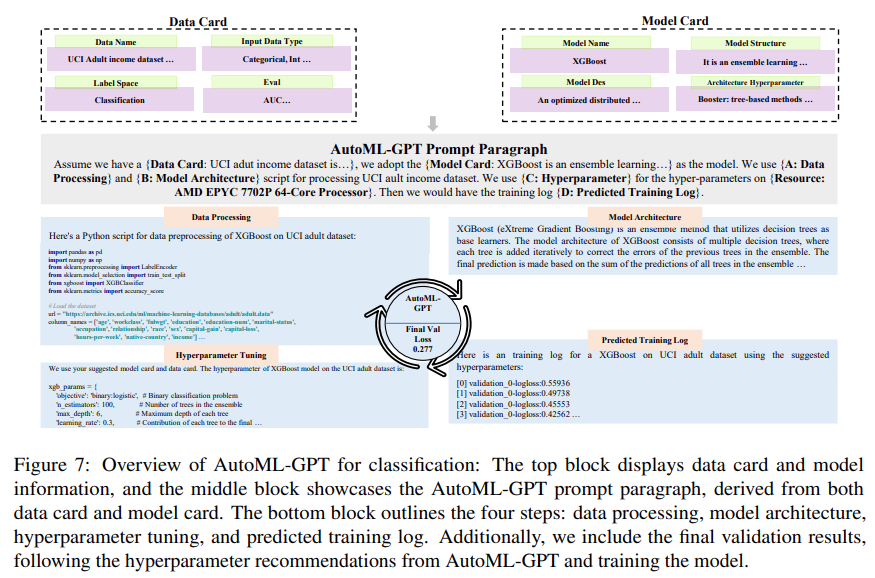
This study also used XGBoost evaluated AutoML-GPT on the UCI Adult data set [Dua and Graff, 2017] to explore its performance on classification tasks. The experimental results are shown in Figure 7 below:
Interested readers can read the original text of the paper to learn more research details.
The above is the detailed content of GPT acts as a brain, directing multiple models to collaborate to complete various tasks. The general system AutoML-GPT is here.. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



