


In 2017, the Google team proposed the groundbreaking NLP architecture Transformer in the paper "Attention Is All You Need" and has been cheating ever since.
Over the years, this architecture has been popular with large technology companies such as Microsoft, Google, and Meta. Even ChatGPT, which has swept the world, was developed based on Transformer.
And just today, Transformer’s star rating on GitHub exceeded 100,000!
Hugging Face, which started out as a chatbot program, rose to fame as the centerpiece of the Transformer model, becoming The world-famous open source community.
To celebrate this milestone, Hugging Face also summarized 100 projects based on the Transformer architecture.
In June 2017, when Google released the "Attention Is All You Need" paper, perhaps no one thought of this deep learning architecture Transformer How many surprises can it bring.
Since its birth, Transformer has become the cornerstone king in the AI field. In 2019, Google also applied for a patent specifically for it.

As Transformer occupies a mainstream position in the NLP field, it has also begun to cross-border into other fields, and more and more work has begun. Try to steer it into the CV realm.
Many netizens were very excited to see Transformer break through this milestone.
"I have been a contributor to many popular open source projects, but seeing Transformer reach 10 on GitHub Ten thousand stars, it’s still very special!”
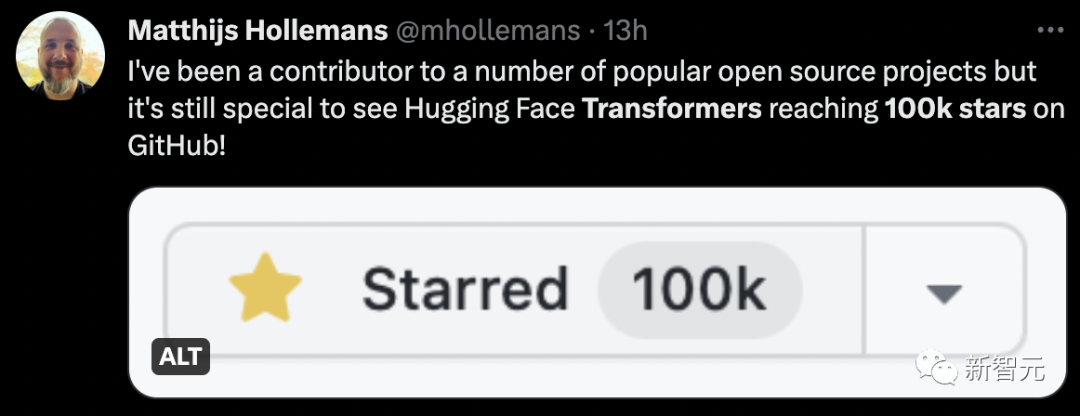
Some time ago, the number of GitHub stars of Auto-GPT exceeded that of pytorch. caused a big stir.
Netizens can’t help but wonder how Auto-GPT compares with Transformer?

In fact, Auto-GPT far surpasses Transformer and already has 130,000 stars.
Currently, Tensorflow has more than 170,000 stars. It can be seen that Transformer is the third machine learning library with a star rating of over 100,000 after these two projects.
Some netizens recalled that when they first used the Transformers library, it was called "pytorch-pretrained-BERT".
Transformers is not only a toolkit that uses pre-trained models, it is also a project built around Transformers and Hugging Face Hub Community.
In the following list, Hugging Face summarizes 100 amazing and novel projects based on Transformer.

Below, we have selected the first 50 projects for introduction:
gpt4all is an open source chatbot ecosystem. It is trained on a large collection of clean assistant data, including code, stories, and conversations. It provides open source large-scale language models, such as LLaMA and GPT-J, for training in an assistant manner.
Keywords: open source, LLaMa, GPT-J, instructions, assistant
This repository contains examples and best practices for building recommender systems, provided in the form of Jupiter notebooks. It covers several aspects needed to build an effective recommendation system: data preparation, modeling, evaluation, model selection and optimization, and operationalization.
Keywords: recommendation system, AzureML
lama-cleanerImage repair tool based on Stable Diffusion technology. You can erase any unwanted objects, defects, or even people from the image and replace anything on the image.
Keywords: patch, SD, Stable Diffusion
Keywords: NLP, text embedding, document embedding, biomedicine, NER, PoS, sentiment analysis
 ##mindsdb
##mindsdb
Keywords: database, low code, AI table
langchain
Keywords: LLM, large language model, agent, chain
ParlAI
Keywords: dialogue, chatbot, VQA, data set, agent
sentence-transformers
Keywords: dense vector representation, text embedding, sentence embedding
ludwig
Keywords: declarative, data-driven, ML framework
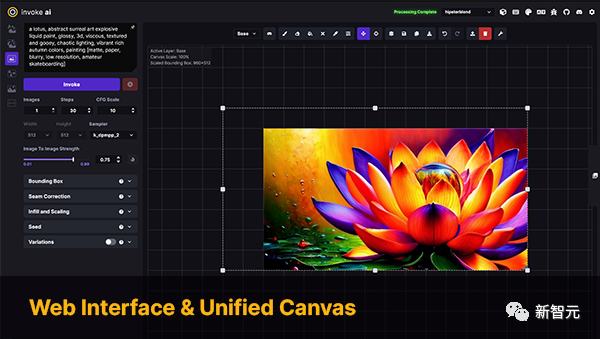
InvokeAI is an engine for the Stable Diffusion model, aimed at professionals, artists and enthusiasts. It leverages the latest AI-driven technology through CLI as well as WebUI.
Keywords: Stable Diffusion, WebUI, CLI
PaddleNLP is an easy-to-use and powerful NLP library, especially for the Chinese language. It supports multiple pre-trained model zoos and supports a wide range of NLP tasks from research to industrial applications.
Keywords: Natural Language Processing, Chinese, Research, Industry
Official Python of the Stanford University NLP Group NLP library. It supports running a wide range of precise natural language processing tools in more than 60 languages, and supports access to Java Stanford CoreNLP software from Python.
Keywords: NLP, multi-language, CoreNLP
DeepPavlov is an open source conversational artificial intelligence library . It is designed for the development of production-ready chatbots, and complex dialogue systems, as well as research in the field of NLP, specifically dialogue systems.
Keywords: dialogue, chatbot
Alpaca-lora includes the use of low-rank adaptation ( LoRA) code to reproduce Stanford Alpaca results. This repository provides training (fine-tuning) and generation scripts.
Keywords: LoRA, efficient fine-tuning of parameters
An open source implementation of Imagen, Google’s closed Source text-to-image neural network beats DALL-E2. imagen-pytorch is the new SOTA for text-to-image synthesis.
Keywords: Imagen, Wenshengtu
adapter-transformers is an extension of the Transformers library that integrates adapters into state-of-the-art language models by incorporating AdapterHub, a central repository of pre-trained adapter modules. It is a drop-in replacement for Transformers and is updated regularly to keep pace with Transformers developments.
Keywords: Adapter, LoRA, parameter efficient fine-tuning, Hub
NeMoNVIDIA NeMo is designed for automatic speech A conversational AI toolkit built by researchers in recognition (ASR), text-to-speech synthesis (TTS), large language models, and natural language processing. The main goal of NeMo is to help researchers from industry and academia repurpose previous work (code and pre-trained models) and make it easier to create new projects.
Keywords: dialogue, ASR, TTS, LLM, NLP
RunhouseRunhouse allows you to combine code with Python Send data to any computer or data underlying and continue to interact with them normally from existing code and environments. Runhouse developers mentioned:
#You can think of it as an extension package for the Python interpreter, which can bypass remote machines or operate remote data.
Keywords: MLOps, infrastructure, data storage, modeling
MONAI is part of the PyTorch ecosystem and is an open source framework based on PyTorch for deep learning in the field of medical imaging. Its objectives are:
- To develop a collaborative community of academic, industrial and clinical researchers on a common basis;
- To contribute to the medical Imaging creates SOTA, end-to-end training workflow;
- Provides an optimized and standardized method for the establishment and evaluation of deep learning models.
Keywords: medical imaging, training, evaluation
Simple Transformers allows you to quickly train and evaluate Transformer models . Only 3 lines of code are needed to initialize, train and evaluate the model. It supports a wide variety of NLP tasks.
Keywords: framework, simplicity, NLP
JARVIS is a GPT-4, etc. The LLM system merges with other models from the open source machine learning community, leveraging up to 60 downstream models to perform tasks identified by LLM.
Keywords: LLM, agent, HF Hub
transformers.js is a JavaScript library that aims to run models from transformers directly in the browser.
Keywords: Transformers, JavaScript, browser
Bumblebee provides pre-trained on top of Axon Neural network model, Axon is a neural network library for the Elixir language. It includes integration with models, allowing anyone to download and perform machine learning tasks with just a few lines of code.
Keywords: Elixir, Axon
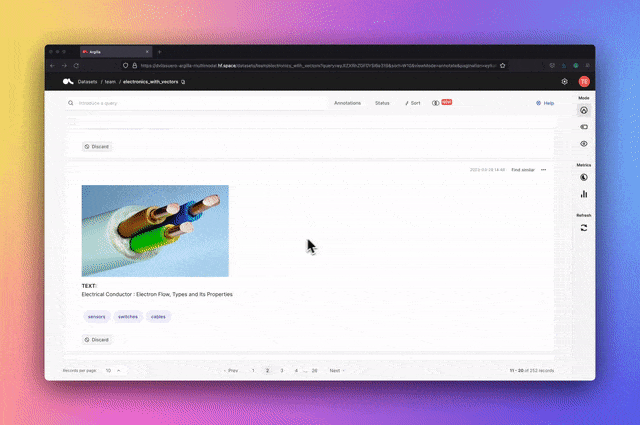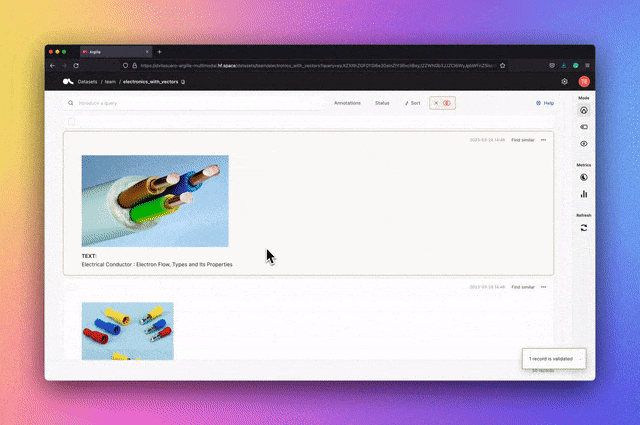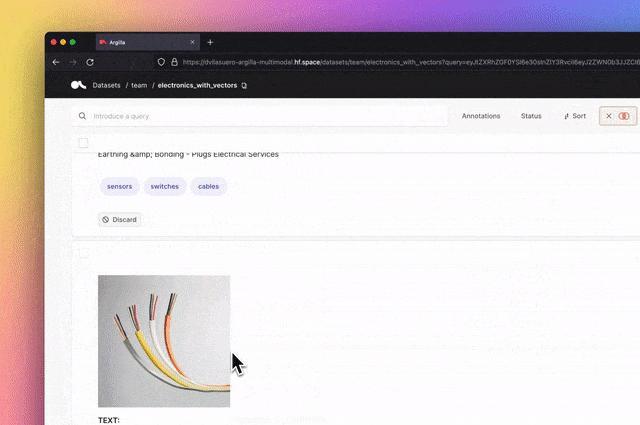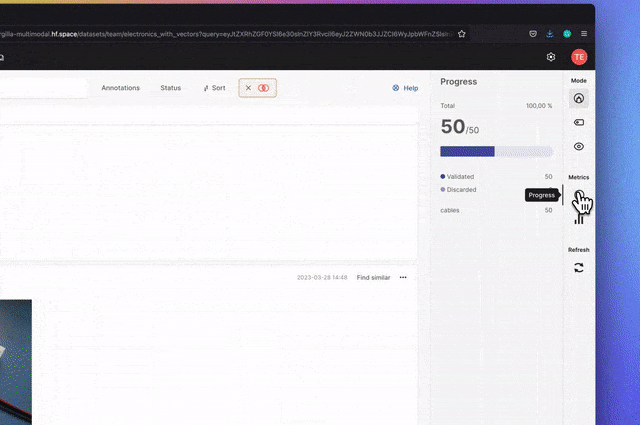
Argilla is a tool that provides advanced NLP labeling, monitoring and workspaces Open source platform. It is compatible with many open source ecosystems such as Hugging Face, Stanza, FLAIR, etc.
Keywords: NLP, labeling, monitoring, workspace
Haystack is an open source NLP framework that can interact with data using Transformer models and LLM. It provides production-ready tools for quickly building complex decision making, question answering, semantic search, text generation applications, and more.
Keywords: NLP, Framework, LLM

SpaCy is a library for advanced natural language processing in Python and Cython. It is built on the latest research and designed from the ground up for use in real products. It provides support for the Transformers model through its third-party package spacy-transformers.
Keywords: NLP, architecture

SpeechBrain is an open source, integrated conversational AI toolkit based on PyTorch. Our goal is to create a single, flexible, user-friendly toolkit that can be used to easily develop state-of-the-art speech technologies, including speech recognition, speaker identification, speech enhancement, speech separation, speech recognition, multi-microphone signal processing and other systems.
Keywords: dialogue, speech
Skorch is a wrapper for PyTorch with scikit-learn compatibility Neural network library. It supports models in Transformers, as well as tokenizers from tokenizers.
Keywords: Scikit-Learning, PyTorch
BertViz is an interactive tool used in applications such as Visualize attention in Transformer language models like BERT, GPT2, or T5. It can be run in Jupiter or Colab notebooks via a simple Python API that supports most Huggingface models.
Keywords: Visualization, Transformers

mesh-transformer-jax is a Haiku library that implements Transformers model parallelism using xmap/pjit operators in JAX.
This library is designed to scale to approximately 40B parameters on TPUv3. It is a library used to train GPT-J models.
Keywords: Haiku, model parallelism, LLM, TPUdeepchem
OpenNREA method for neural relationship extraction Open Source Packages (NRE). It targets a wide range of users, from novices, to developers, researchers or students.
Keywords: neural relationship extraction, framework
pycorrectorA Chinese text error correction tool. This method utilizes language model detection errors, pinyin features, and shape features to correct Chinese text errors. Can be used for Chinese Pinyin and stroke input methods.
Keywords: Chinese, error correction tools, language model, Pinyin
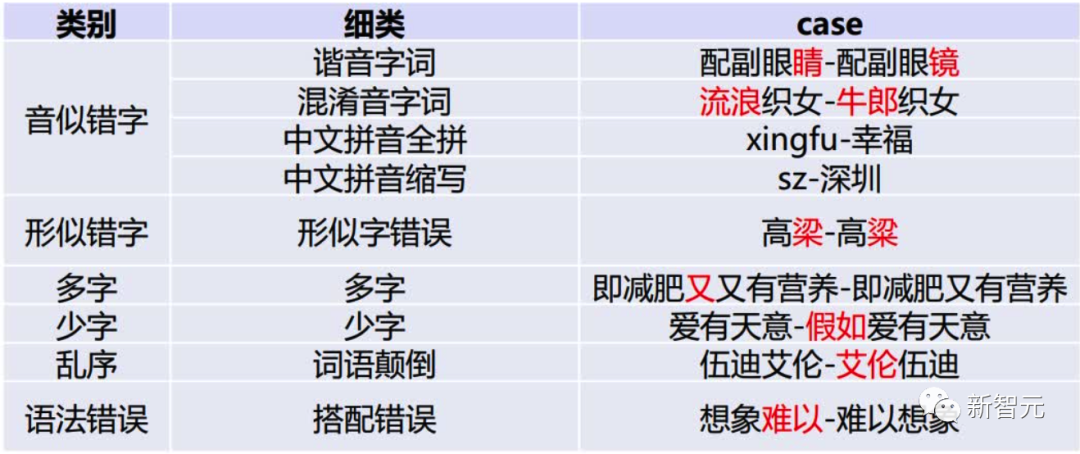
Keywords: data augmentation, synthetic data generation, audio, natural language processing
dream-textures
dream- textures is a library designed to bring stable diffusion support to Blender. It supports multiple use cases such as image generation, texture projection, in/out painting, ControlNet and upgrades.Keywords: Stable-Diffusion, Blender
 ##seldon-core
##seldon-core
Keywords: microservices, modeling, language packaging
This library includes optimized deep learning models and a set of demos to accelerate the development of high-performance deep learning inference applications. Use these free pre-trained models instead of training your own to speed up development and production deployment processes.
Keywords: optimization model, demonstration
ML-Stable-Diffusion is Apple’s A repository that brings Stable Diffusion support to Core ML on Apple silicon devices. It supports stable diffusion checkpoints hosted on Hugging Face Hub.
Keywords: Stable Diffusion, Apple chip, Core ML
Stable-Dreamfusion is a pytorch implementation of text to 3D model Dreamfusion, powered by Stable Diffusion text to 2D model.
Keywords: Text to 3D, Stable Diffusion

Keywords: semantic search, LLM
 ##djl
##djl
Keywords: Java, architecture
 lm-evaluation-harness
lm-evaluation-harness
Keywords: LLM, evaluation, few samples
gpt-neox
Keywords: training, LLM, Megatron, DeepSpeed
muzic
Keywords: music understanding, music generation
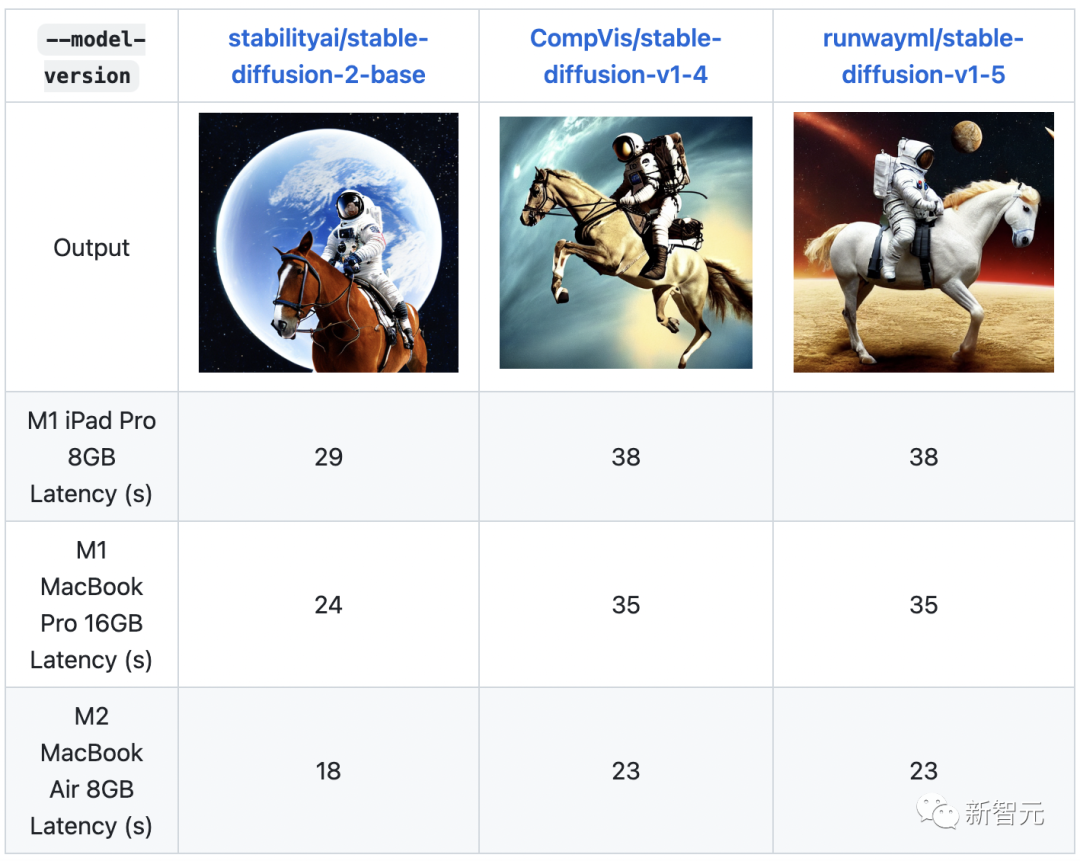
DALL · E Flow is an interactive workflow for generating high-definition images from text prompts. It uses DALL·E-Mega, GLID-3 XL and Stable Diffusion to generate candidate images, and then calls CLIP-as-service to prompt sort the candidate images. Preferred candidates are fed to GLID-3 XL for diffusion, which often enriches textures and backgrounds. Finally, the candidate is extended to 1024x1024 via SwinIR.
Keywords: High-definition image generation, Stable Diffusion, DALL-E Mega, GLID-3 XL, CLIP, SwinIR
LightSeq is a high-performance training and inference library implemented in CUDA for sequence processing and generation. It is capable of efficiently computing modern NLP and CV models such as BERT, GPT, Transformer, etc. Therefore, it is useful for machine translation, text generation, image classification, and other sequence-related tasks.
Keywords: training, inference, sequence processing, sequence generation

The goal of this project is to create a learning-based system that takes an image of a mathematical formula and returns the corresponding LaTeX code.
Keywords: OCR, LaTeX, mathematical formulas
OpenCLIP is an open source implementation of OpenAI’s CLIP.
The goal of this repository is to enable the training of models with contrastive image-text supervision and to study their properties such as robustness to distribution shifts. The starting point of the project is an implementation of CLIP that matches the accuracy of the original CLIP model when trained on the same dataset.
Specifically, a ResNet-50 model trained on OpenAI’s 15 million image subset YFCC as the code base achieved the highest accuracy of 32.7% on ImageNet.
Keywords: CLIP, open source, comparison, image text

A playground to generate images from any text prompt using Stable Diffusion and Dall-E mini.
Keywords: WebUI, Stable Diffusion, Dall-E mini
FedML is a federated learning and analytics library that enables secure and collaborative machine learning on distributed data anywhere and at any scale.
Keywords: federated learning, analysis, collaborative machine learning, decentralized
The above is the detailed content of The star mark exceeded 100,000! After Auto-GPT, Transformer reaches new milestone. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



