


Author: Xiaoya Shen Yuan Zhudi et al
Comment search is the core of Dianping App One of the entrances allows users to search to meet their store-finding needs for lifestyle service merchants in different scenarios. The long-term goal of search is to continuously optimize the search experience and improve user search satisfaction. This requires us to understand user search intentions, accurately measure the correlation between search terms and merchants, display relevant merchants as much as possible, and rank more relevant merchants based on forward. Therefore, the calculation of the correlation between search terms and merchants is an important part of review search.
The relevance problems faced by Dianping search scenarios are complex and diverse. Users’ search terms are quite diverse, such as searching for business names, dishes, addresses, categories, and various complexities between them. At the same time, merchants also have multiple types of information, including merchant name, address information, group order information, dish information, and various other facilities and label information. As a result, the matching mode between Query and merchants is extremely complex, and it is easy to breed various Such correlation issues. Specifically, it can be divided into the following types:
##(a) Text mismatch example
(b) Semantic offset example
Figure 1 Example of review search relevance problem
Based on literals The matching correlation method cannot effectively deal with the above problems. In order to solve various irrelevant problems in the search list that do not meet the user's intention, it is necessary to more accurately characterize the deep semantic correlation between the search terms and the merchants. Based on the MT-BERT pre-training model trained on Meituan's massive business corpus, this article optimizes the deep semantics of Query and merchants (POI, corresponding to Doc in general search engines) in Dianping search scenarios. Relevance model, and apply the correlation information between Query and POI in each link of the search link.
This article will introduce the review search relevance technology from four aspects: review of existing search relevance technologies, review search relevance calculation scheme, practical application, summary and outlook. The Dianping search relevance calculation chapter will introduce how we solve the three main challenges of merchant input information construction, adapting the model to the Dianping search relevance calculation, and performance optimization of the model online. The practical application chapter will introduce the offline development of the Dianping search relevance model. and online effects.
2. Search correlation existing technologySearch correlation aims to calculate the degree of correlation between Query and the returned Doc, that is, to determine whether the content in the Doc Meet the needs of user Query and correspond to the semantic matching task in NLP (Semantic Matching). In the search scenario of Dianping, search relevance is to calculate the correlation between the user's Query and the merchant's POI.
Text matching method: Early text matching tasks only considered the literal matching degree between Query and Doc, through Term-based matching features such as TF-IDF and BM25. to calculate the correlation. The online calculation efficiency of literal matching correlation is high, but the generalization performance of term-based keyword matching is poor, lacks semantic and word order information, and cannot handle the problem of multiple meanings of a word or multiple words with one meaning, so missing matches and misunderstandings The matching phenomenon is serious.
Traditional semantic matching model: In order to make up for the shortcomings of literal matching, the semantic matching model is proposed to better understand the semantic correlation between Query and Doc. Traditional semantic matching models mainly include matching based on implicit space: mapping both Query and Doc to vectors in the same space, and then using vector distance or similarity as matching scores, such as Partial Least Square (PLS )[1]; and matching based on translation model: match Doc after mapping it to Query space or calculate the probability of Doc being translated into Query[2].
With the development of deep learning and pre-training models, deep semantic matching models are also widely used in the industry. In terms of implementation methods, deep semantic matching models are divided into representation-based (Representation-based) methods and interaction-based (Interaction-based) methods. As an effective method in the field of natural language processing, pre-trained models are also widely used in semantic matching tasks.
(a) Representation-based multi-domain correlation model
(b) Interaction-based correlation model
Figure 2 Deep semantic matching correlation model
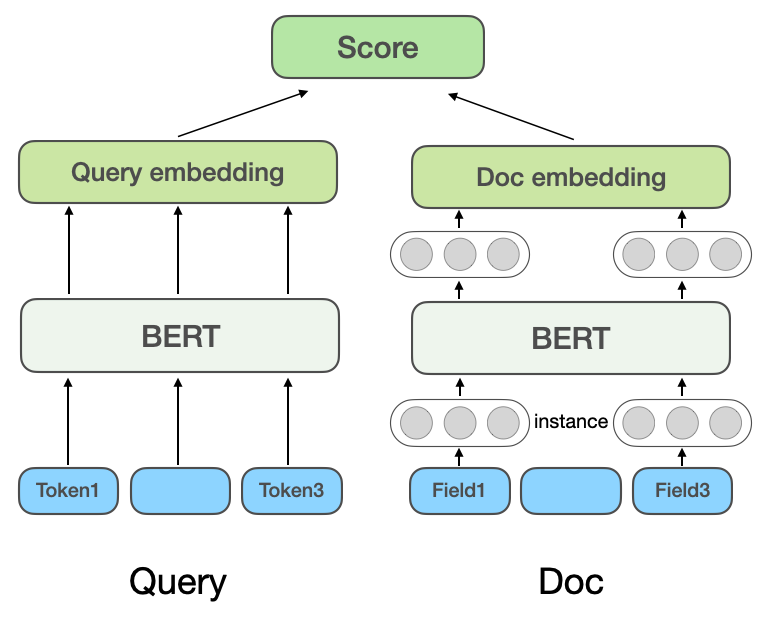
Representation-based deep semantic matching model: The representation-based method learns the semantic vector representations of Query and Doc respectively, and then calculates the similarity based on the two vectors. Microsoft's DSSM model[3] proposes a classic twin-tower structure text matching model, which uses two independent networks to construct vector representations of Query and Doc, and uses cosine similarity to measure the two vectors. degree of correlation. Microsoft Bing Search's NRM[4] Aims at the problem of Doc representation. In addition to the basic Doc title and content, other multi-source information is also considered (Each type of information is called a field Field ), such as external links, queries clicked by users, etc. Consider that there are multiple Fields in a Doc, and there are multiple instances (Instance) in each Field. Each Instance corresponds to a text, such as Query word. The model first learns the Instance vector, aggregates all Instance representation vectors to obtain a Field representation vector, and aggregates multiple Field representation vectors to obtain the final Doc vector. SentenceBERT[5]Introduce the pre-trained model BERT into the coding layer of Query and Doc of Twin Towers, use different Pooling methods to obtain the sentence vectors of Twin Towers, and use dot multiplication, splicing, etc. to query and Doc to interact.
Dianping’s early model of search relevance drew on the ideas of NRM and SentenceBERT, and adopted the representation-based multi-domain relevance model structure shown in Figure 2(a). The representation method can calculate the POI vector in advance and store it in the cache. Only the interactive part between the Query vector and the POI vector is calculated online, so the calculation speed is faster when used online.
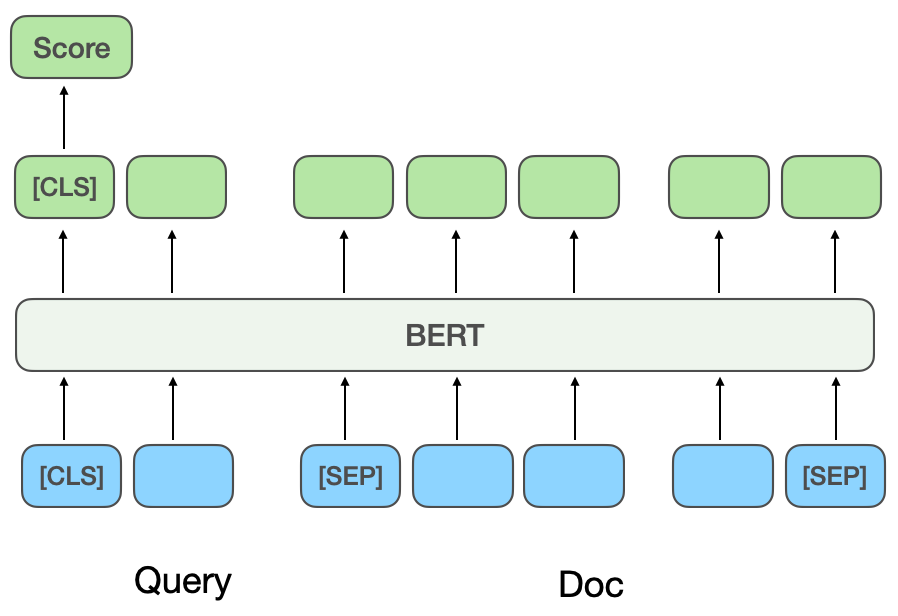
Interaction-based deep semantic matching model: The interaction-based method does not directly learn the semantic representation vectors of Query and Doc, but lets Query Interact with Doc to establish some basic matching signals, and then merge the basic matching signals into a matching score. ESIM[6] is a classic model widely used in the industry before the introduction of pre-training models. First, Query and Doc are encoded to obtain the initial vector, and then the Attention mechanism is used for interactive weighting and then spliced with the initial vector. Finally, Classification results in a relevance score.
When the pre-trained model BERT is introduced for interactive calculations, Query and Doc are usually spliced as the input of the BERT inter-sentence relationship task, and the final correlation score is obtained through the MLP network[ 7], as shown in Figure 2(b). CEDR[8]After the BERT inter-sentence relationship task obtains the Query and Doc vectors, the Query and Doc vectors are split, and the cosine similarity matrix of Query and Doc is further calculated. The Meituan search team [9] introduced interaction-based methods into the Meituan search correlation model, introduced merchant category information for pre-training, and introduced entity recognition tasks for multi-task learning. The Meituan in-store search advertising team [10] proposed a method of distilling the interaction-based model into a representation-based model to achieve virtual interaction of the twin-tower model, while ensuring performance while adding Query and POI interaction.
The representation-based model focuses on representing the global characteristics of POI, lacking the matching information between online Query and POI, and is based on interaction. The method can make up for the shortcomings of the representation-based method, enhance the interaction between Query and POI, and improve the expression ability of the model. At the same time, in view of the strong performance of the pre-trained model in the text semantic matching task, the review search correlation calculation determined the pre-trained model based on Meituan The interactive solution of MT-BERT[11]. When applying interactive BERT based on pre-trained models to the relevance task of review search scenarios, there are still many challenges:
After continuous exploration and experimentation, we constructed a POI text summary adapted to the review search scenario for the complex multi-source information on the POI side; in order to make the model better suited With Dianping search correlation calculation, a two-stage training method was adopted, and the model structure was transformed according to the characteristics of correlation calculation; finally, by optimizing the calculation process, introducing caching and other measures, the real-time calculation and overall application link of the model were successfully reduced. time-consuming, meeting the performance requirements of online real-time calculation of BERT.
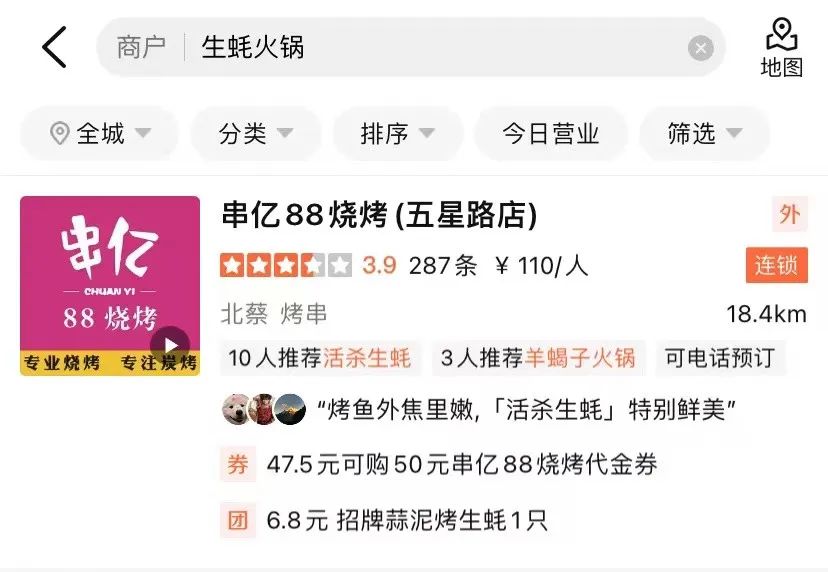
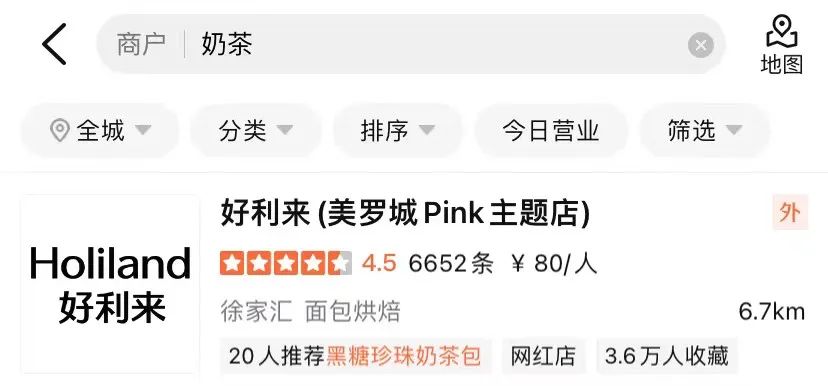
When determining the correlation between Query and POI, there are more than a dozen fields on the POI side that participate in the calculation. There is a lot of content under certain fields (For example, a merchant may have hundreds of recommended dishes), so it is necessary to find a suitable way to extract and organize the POI side information and input it into the correlation model. General search engines (such as Baidu), or common vertical search engines (such as Taobao), the web title or product title of the Doc is rich in information, usually in the process of determining relevance The main content of the Doc side model input.
As shown in Figure 3(a), in a general search engine, the key information of the corresponding website and whether it is related to the Query can be seen at a glance through the title of the search results. In Figure 3(b) Dianping In the search results of the App, sufficient merchant information cannot be obtained only through the merchant name field. It needs to be combined with the merchant category (milk tea juice) and user recommended dishes (olioli milktea) , tag (网 celebrity store), address (武林square) and multiple fields to determine the relevance of the merchant to the Query "Wulin Square Internet Celebrity Milk Tea".
(a) Example of general search engine search results
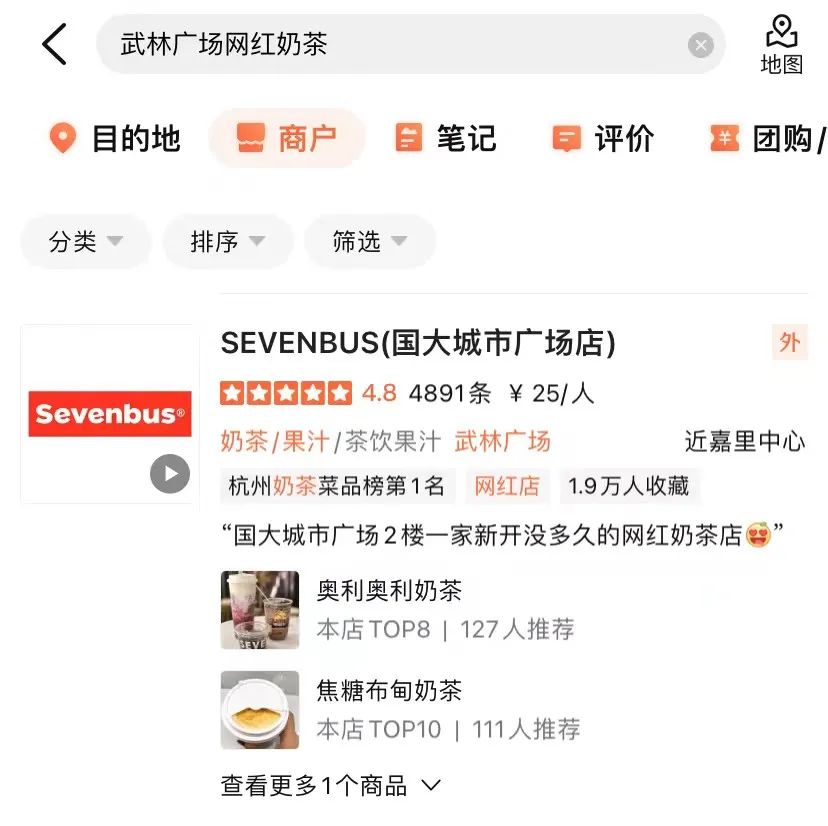
(b) Example of Dianping App search results
Figure 3 Comparison of general search engine and Dianping search results
tag extraction is a common way to extract topic information in the industry, so we first tried to construct the POI-side model input method through merchant tags, and searched for click words based on the merchant's comments, basic information, dishes, and the merchant's corresponding headers, etc. Extract representative merchant keywords as merchant tags. When used online, the extracted merchant tags, merchant name and category basic information are used as input information on the POI side of the model, and interactive calculations are performed with Query. However, the coverage of merchant information by merchant tags is still not comprehensive enough. For example, when a user searches for the dish "egg custard", a Korean restaurant close to the user sells egg custard, but the store's signature dish and head click words are not related to "egg custard", resulting in the label words extracted by the store also having low correlation with "egg custard", so the model will judge the store as irrelevant, thus causing harm to the user experience.
In order to obtain the most comprehensive POI representation, one solution is to directly splice all the fields of the merchant into the model input without extracting keywords. However, this method will cause problems due to the length of the model input. If it is too long, it will seriously affect online performance, and a large amount of redundant information will also affect model performance.
In order to construct more informative POI side information as model input, we proposed a POI matching field summary extraction method, that is, combined with online Query matching The matching field text of the POI is extracted in real time, and the matching field summary is constructed as the POI side model input information. The POI matching field summary extraction process is shown in Figure 4. Based on some text similarity features, we extract the text fields most relevant and informative to the Query, and integrate the field type information to build a matching field summary. When used online, the extracted POI matching field summary, merchant name and category basic information are input as the POI side model.
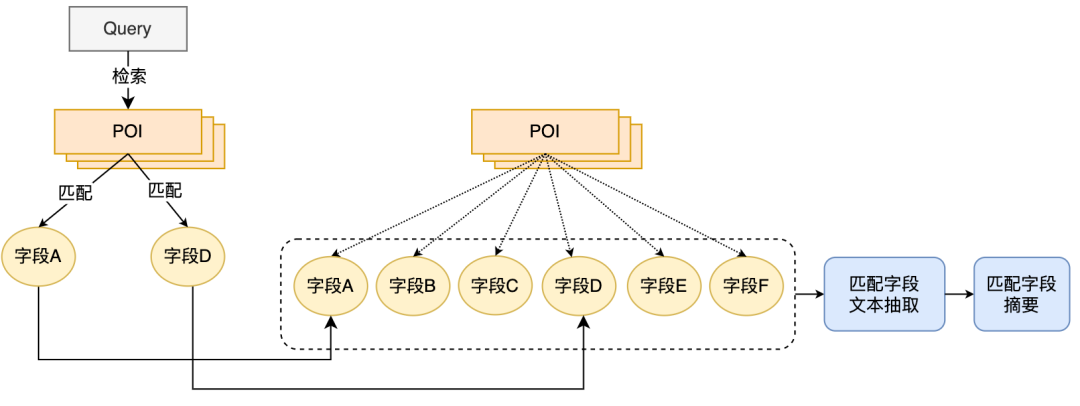
Figure 4 POI matching field summary extraction process After determining the POI side model input information, we use BERT inter-sentence relationship Task, first use MT-BERT to encode the matching field summary information on the Query side and POI side, and then use the pooled sentence vector to calculate the correlation score. After using the POI matching field summary scheme to construct the POI side model and inputting the information, combined with sample iteration, the model's effect has been greatly improved compared to the label-based method.
Let the model better adapt to the review search relevance calculation task contains two levels of meaning : There are certain differences in distribution between the text information in the Dianping search scenario and the corpus used by the MT-BERT pre-training model; the inter-sentence relationship tasks of the pre-training model are also slightly different from the correlation tasks of Query and POI, which require Modify the model structure. After continuous exploration, we adopted a two-stage training scheme based on domain data, combined with the training sample structure, to make the pre-training model more suitable for the relevance task of review search scenarios; and proposed a based on multi-similarity The matrix's deep interactive correlation model strengthens the interaction between Query and POI, improves the model's ability to express complex Query and POI information, and optimizes the correlation calculation effect.
In order to effectively utilize user click data and make the pre-trained model MT-BERT more suitable for the review search relevance task, we learn from Baidu search Based on the idea of correlation[12], a multi-stage training method is introduced, using user clicks and negative sampling data to conduct pre-training of the first stage of domain adaptation (Continual Domain-Adaptive Pre-training), using manually labeled data for the second stage of training (Fine-Tune), the model structure is shown in Figure 5 below:
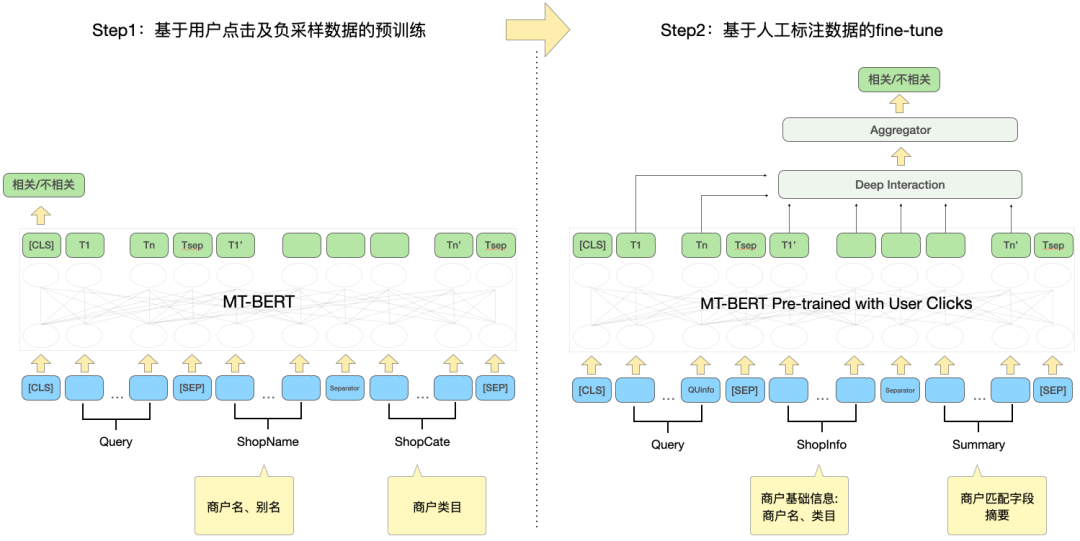
Figure 5 Two-stage training model structure based on click and manual annotation data
First-stage training based on click data
The direct reason for introducing click data as the first stage training task is that there are some unique problems in the review search scenario. For example, the words "happy" and "happy" are almost completely synonymous in common scenarios. words, but in the review search scenario, "Happy BBQ" and "Happy BBQ" are two completely different brand merchants, so the introduction of click data can help the model learn some unique knowledge in the search scenario. However, there will be a lot of noise in directly using click samples for correlation judgment, because the user may click on a merchant by mistake due to a higher ranking, and the user may not click on a merchant simply because the merchant is far away. It is not because of the correlation problem, so we introduced a variety of features and rules to improve the accuracy of automatic annotation of training samples.
When constructing the sample, candidate samples are screened by counting whether the click is clicked, the click position, the distance between the largest click merchant and the user, etc., and the Query-POI whose click rate is greater than a certain threshold is exposed Use it as a positive example, and adjust different thresholds for different types of merchants based on business characteristics. In terms of the structure of negative examples, the Skip-Above sampling strategy uses merchants that are located before the clicked merchant and whose click rate is less than the threshold as negative samples. In addition, the random negative sampling method can supplement the training samples with simple negative examples, but when considering random negative sampling, some noise data will also be introduced. Therefore, we use artificially designed rules to denoise the training data: When the category intention of Query is different from When the category system of a POI is relatively consistent or highly matches the POI name, it will be eliminated from the negative samples.
The second stage of training based on artificially labeled data
After the first stage of training, considering that it cannot be completely To remove the noise in the click data and the characteristics of the correlation task, it is necessary to introduce a second-stage training based on manually labeled samples to correct the model. In addition to randomly sampling a portion of the data and handing it over to manual annotation, in order to improve the model's capabilities as much as possible, we produce a large number of high-value samples through difficult example mining and comparative sample enhancement and hand them over to manual annotation. The details are as follows:
1) Difficult example mining
2) Contrast sample enhancement: Draw on the idea of contrastive learning, generate contrast samples for some highly matching samples for data enhancement, and perform manual annotation Ensure sample label accuracy. By comparing the differences between samples, the model can focus on truly useful information and improve its generalization ability for synonyms, thereby achieving better results.
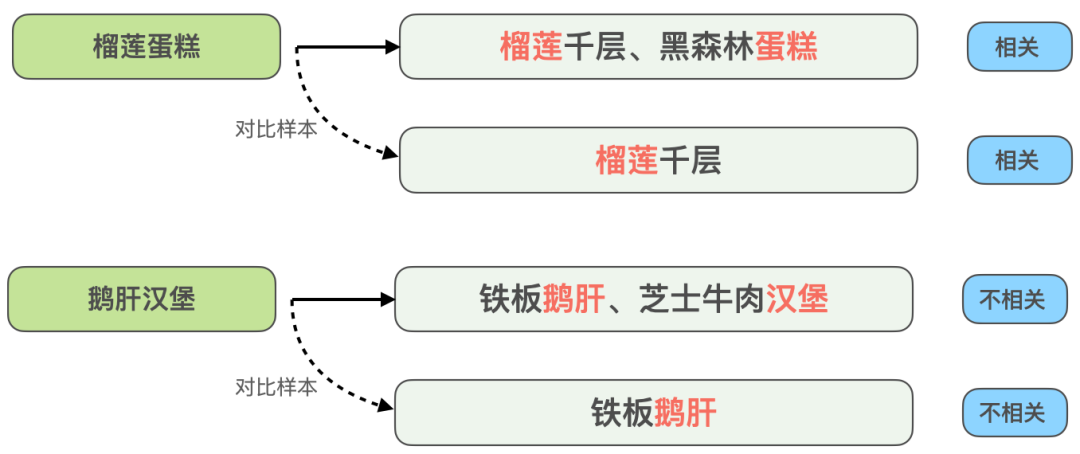
Figure 6 Comparative sample enhancement example
To solve the correlation problem of cross-dish matching For example, as shown in Figure 6 above, it is also the case that Query is split and matched with multiple recommended dish fields of the merchant. Query "Durian Cake" is related to the recommended dish "Durian Thousand Crepe, Black Forest Cake", but Query "Foie gras burger" and "Sizzling foie gras, cheese beef burger" are not related. In order to enhance the model's ability to identify this type of highly matching but opposite results, we constructed "durian cake" and "durian mille-feuille" ", "Foie Gras Burger" and "Sizzling Foie Gras" are two sets of comparison samples. The information that matches the Query text but is not helpful for the model's judgment is removed, allowing the model to learn the key information that truly determines whether it is relevant. At the same time, Improve the model's generalization ability for synonyms such as "cake" and "thousand-layer". Similarly, other types of difficult examples can also use this sample enhancement method to improve the effect.
BERT inter-sentence relationship is a general NLP task, used to determine the relationship between two sentences, and The correlation task is to calculate the correlation between Query and POI. During the calculation process, the inter-sentence relationship task not only calculates the interaction between Query and POI, but also calculates the interaction within Query and within POI, while the correlation calculation pays more attention to the interaction between Query and POI. In addition, during the model iteration process, we found that some types of difficulty BadCase have higher requirements on the expressive ability of the model, such as types where the text is highly matched but irrelevant. Therefore, in order to further improve the model's calculation effect on complex Query and POI correlation tasks, we modified the BERT inter-sentence relationship task in the second stage of training and proposed a deep interaction model based on multiple similarity matrices. By introducing Multiple similarity matrices are used to conduct in-depth interaction between Query and POI, and the indicator matrix is introduced to better solve the difficult BadCase problem. The model structure is shown in Figure 7 below:
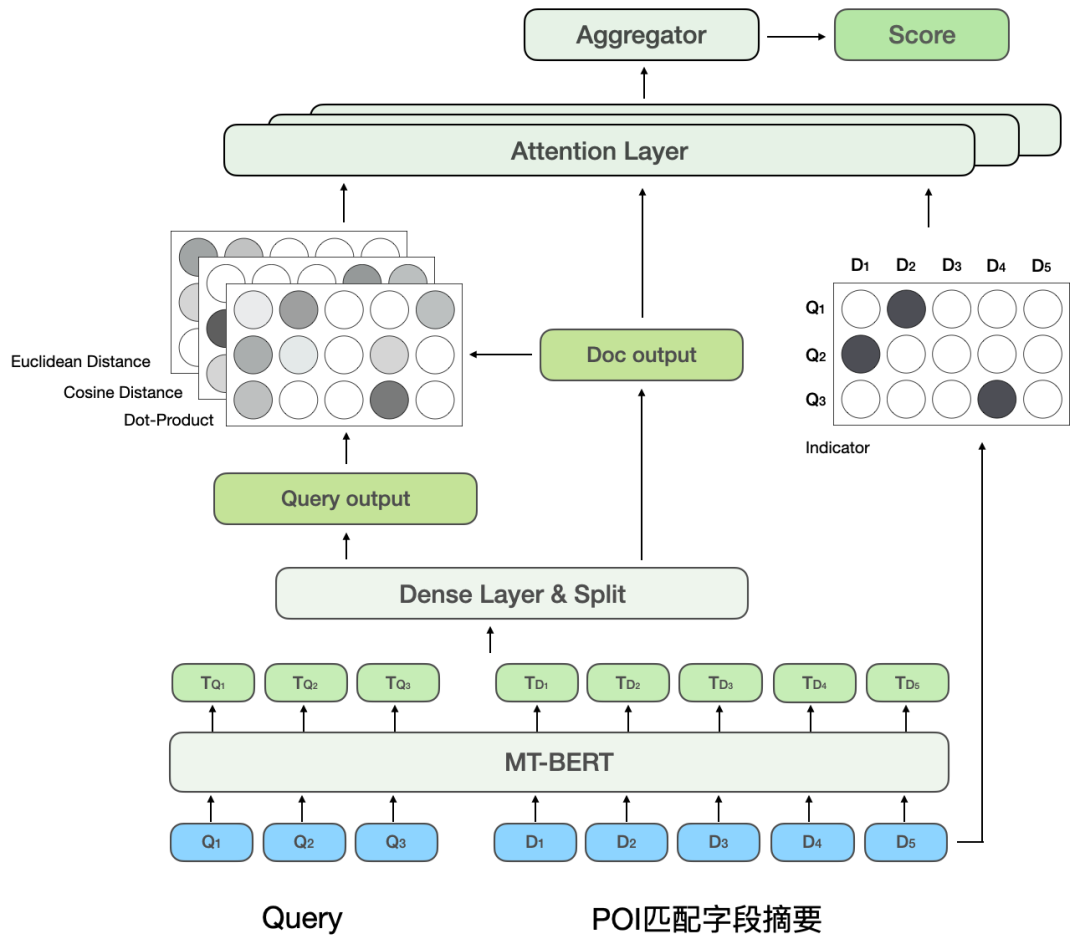
Figure 7 Deep cross-correlation model based on multiple similarity matrices
Inspired by CEDR[8], we will encode the Splitting the Query and POI vectors is used to explicitly calculate the in-depth interaction relationship between the two parts. Splitting the Query and POI vectors and conducting in-depth interaction can be used specifically to learn the correlation between Query and POI. On the other hand, The increased number of parameters can improve the fitting ability of the model.
Referring to the MatchPyramid[13] model, the deep cross-correlation model calculates four different Query-Doc similarity matrices and fuses them, including Indicator, Dot- product, cosine distance and Euclidean distance, and are Attention weighted with the output of the POI part. The Indicator matrix is used to describe whether the Token of Query and POI are consistent. The calculation method is as follows:
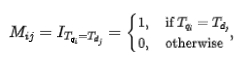
which represents the element corresponding to the row and column of the matching matrix, The Token representing Query and the Token representing POI. Since the Indicator matrix is a matrix that indicates whether the Query and POI literally match, the input format of the other three semantic matching matrices is different. The three matching matrices of Dot-product, cosine distance, and Euclidean distance are first fused, and then the obtained results are combined with the Indicator matrix. The matrices are further fused before calculating the final correlation score.
The Indicator matrix can better describe the matching relationship between Query and POI. The introduction of this matrix mainly takes into account a difficulty in determining the degree of correlation between Query and POI: sometimes even if the text is highly matched, the two are not relevant. The interaction-based BERT model structure makes it easier to determine that Query and POI with a high degree of text matching are relevant. However, in the review search scenario, this may not be the case in some difficult cases. For example, although "bean juice" and "mung bean juice" are highly matched, they are not related. Although "Maokong" and "Cat's Sky Castle" are separate matches, they are related because the former is the abbreviation of the latter. Therefore, different text matching situations are directly input to the model through the Indicator matrix, allowing the model to explicitly receive text matching situations such as "contains" and "split matching", which not only helps the model improve its ability to distinguish difficult cases, but also It will affect the performance of most normal Cases.
The deep interactive correlation model based on multiple similarity matrices splits Query and POI and then calculates the similarity matrix, which is equivalent to allowing the model to explicitly interact with Query and POI, making the model more suitable. Match related tasks. Multiple similarity matrices increase the model's representation ability in calculating the correlation between Query and POI, while the Indicator matrix is specially designed for complex text matching situations in correlation tasks, making the model's judgment of irrelevant results more accurate.
When deploying correlation calculations online, existing solutions usually use the twin towers of knowledge distillation Structure [10,14] to ensure online calculation efficiency, but this processing method is more or less detrimental to the effect of the model. Review search correlation calculation In order to ensure the model effect, the 12-layer BERT pre-trained correlation model based on interaction is used online, which requires hundreds of POIs under each Query to be predicted by the 12-layer BERT model. In order to ensure online computing efficiency, we started from the two perspectives of model real-time computing process and application link, and optimized by introducing caching mechanism, model prediction acceleration, introducing front-end golden rule layer, parallelizing correlation calculation and core sorting, etc. The performance bottleneck of the correlation model when deployed online enables the 12-layer interaction-based BERT correlation model to run stably and efficiently online, ensuring that it can support correlation calculations between hundreds of merchants and Query.
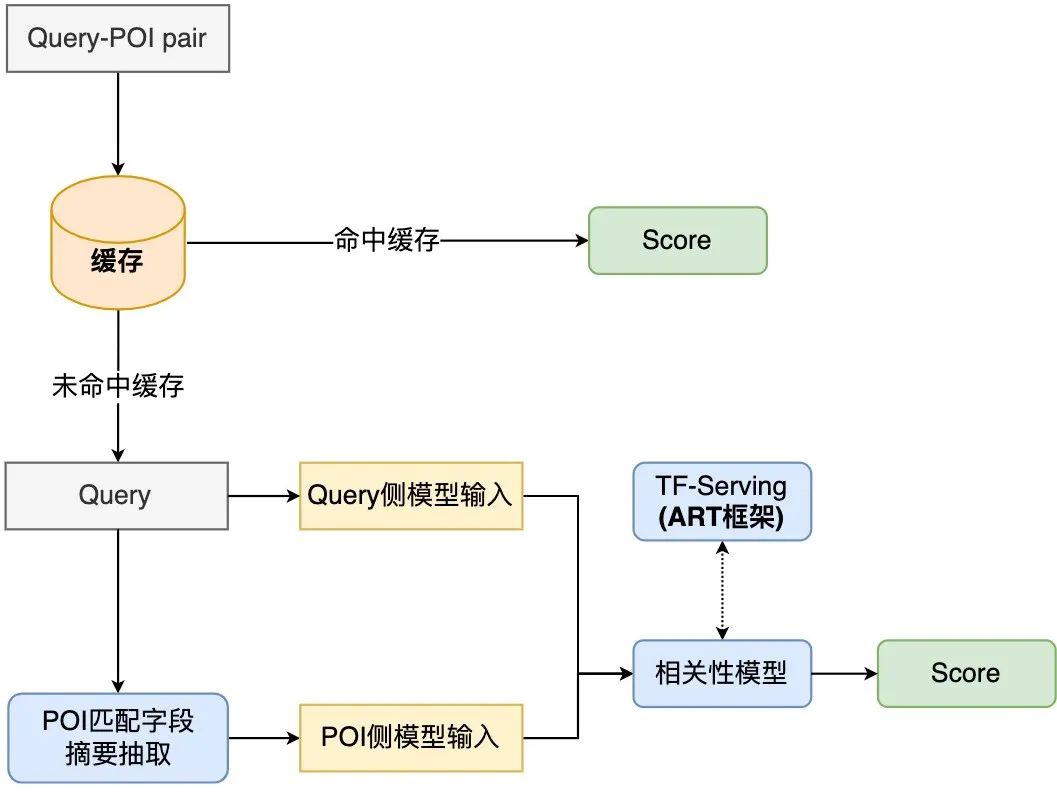
Figure 8 Correlation model online calculation flow chart
The online calculation process of the review search correlation model is shown in Figure 8. The caching mechanism and TF-Serving model prediction acceleration are used to optimize the performance of the real-time calculation of the model.
In order to effectively utilize computing resources, the model online deployment introduces a caching mechanism to write the correlation score of high-frequency Query into the cache. In subsequent calls, the cache will be read first. If the cache is hit, the score will be output directly. If the cache is not hit, the score will be calculated online in real time. The caching mechanism greatly saves computing resources and effectively alleviates the performance pressure of online computing.
For Query that misses the cache, process it as Query-side model input, obtain the matching field summary of each POI through the process described in Figure 4, and process it as a POI-side model Enter the format, and then call the online correlation model to output the correlation score. The correlation model is deployed on TF-Serving. During model prediction, the model optimization tool ART framework of the Meituan machine learning platform is used (Based on Faster-Transformer[15]Improved). Acceleration greatly improves model prediction speed while ensuring accuracy.
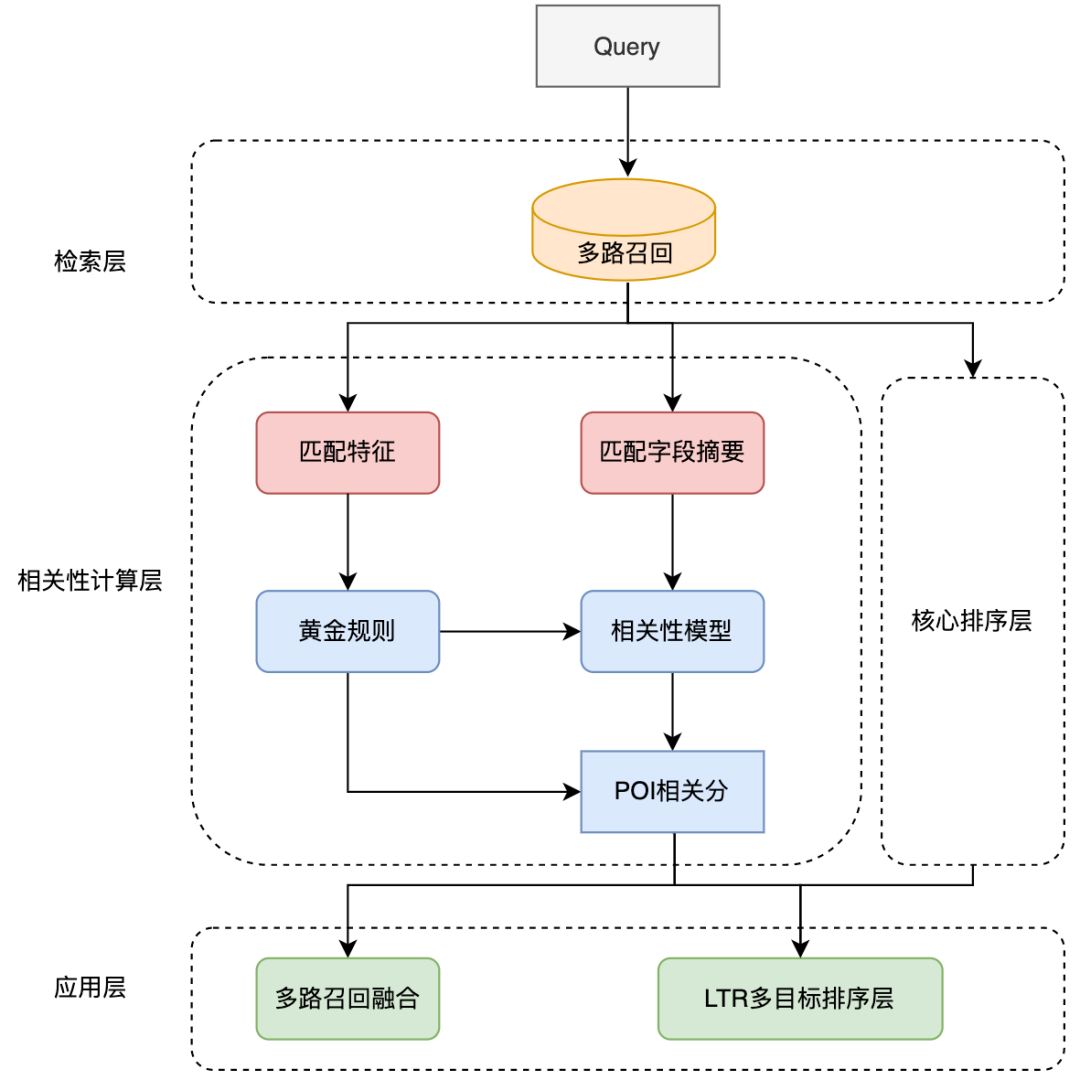
Figure 9 Application of correlation model in review search link
The application of the correlation model in the search link is shown in Figure 9 above. By introducing the pre-golden rule and parallelizing the correlation calculation with the core sorting layer, the overall search link is optimized. performance.
In order to further accelerate the correlation call link, we introduced the pre-golden rule to divert Query, and directly output the correlation score through rules for some Query, thereby easing the model calculation pressure. In the golden rule layer, text matching features are used to judge Query and POI. For example, if the search term is exactly the same as the merchant name, the "relevant" judgment is directly output through the golden rule layer without calculating the correlation score through the correlation model.
In the overall calculation link, the correlation calculation process and the core sorting layer are operated concurrently to ensure that the correlation calculation has basically no impact on the overall time-consuming of the search link. At the application layer, correlation calculations are used in many aspects such as recall and sorting of search links. In order to reduce the proportion of irrelevant merchants on the first screen of the search list, we introduced the relevance score into the LTR multi-objective fusion sorting to sort the list pages, and adopted a multi-way recall fusion strategy. Using the results of the correlation model, only the supplementary recall path Related merchants in are merged into the list.
In order to accurately reflect the offline effect of model iteration, we constructed a model through multiple rounds of manual annotation. Batch Benchmark, considering that the main goal in current online actual use is to reduce BadCase indicators, that is, to accurately identify irrelevant merchants, we use the accuracy, recall rate, and F1 value of negative examples as measurement indicators. The benefits brought by the two-stage training, sample construction and model iteration are shown in Table 1 below:
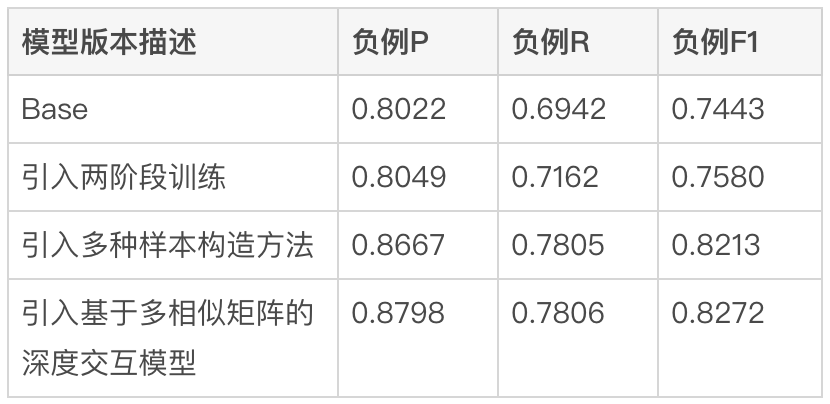
Table 1 Review search correlation model iteration offline Indicator
The initial method (Base) uses Query to splice POI matching field summary information for the BERT sentence pair classification task. The Query side model input uses the original Query input by the user. The POI side adopts the text splicing method of merchant name, merchant category and matching field summary. After the introduction of two-stage training based on click data, the negative example F1 index increased by 1.84% compared to the Base method. By introducing comparison samples and difficult example samples to continuously iterate training samples and cooperate with the second stage model input structure, the negative example F1 index compared with the Base method A significant improvement of 10.35%. After the introduction of the deep interaction method based on multiple similarity matrices, the negative example F1 improved by 11.14% compared to Base. The overall indicators of the model on Benchmark also reached high values of AUC of 0.96 and F1 of 0.97.
In order to effectively measure user search satisfaction, Dianping Search samples actual online traffic every day and manually annotates it, using BadCase on the first screen of the list page rate as the core indicator for evaluating the effectiveness of the correlation model. After the correlation model was launched, the monthly average BadCase rate indicator of Dianping search dropped significantly by 2.9pp (Percentage Point, percentage absolute point) compared to before the launch, and the BadCase rate indicator stabilized at a low point in the following weeks. Nearby, at the same time, the NDCG indicator of the search list page has steadily increased by 2pp. It can be seen that the correlation model can effectively identify irrelevant merchants and significantly reduce the proportion of irrelevant problems on the first screen of search, thereby improving the user's search experience.
Figure 10 below lists some examples of online BadCase solutions. The subtitle is the Query corresponding to the example. The left side is the experimental group that applied the correlation model, and the right side is the control group. In Figure 10(a), when the search term is "Pei Jie", the correlation model determines that the merchant "Pei Jie Famous Products" whose core word contains "Pei Jie" is relevant, and selects high-end items that the user may want to find but enters incorrectly. The quality target merchant "Pei Jie Lao Hot Pot" is also judged to be relevant. At the same time, by introducing the address field identifier, the merchants located next to "Pei Jie" in the address are judged to be irrelevant. In Figure 10(b), the user passes the Query "Pei Zi Ri" "Self-service Food" wants to find a Japanese food self-service store named "Yuzu". The correlation model will match the split words to the Japanese food self-service store "Takewako Tuna" that sells Yuzu-related products and correctly judge it as irrelevant and rank it accordingly. Finally, it is guaranteed that the merchants displayed at the top are merchants that are more in line with the user's main needs.
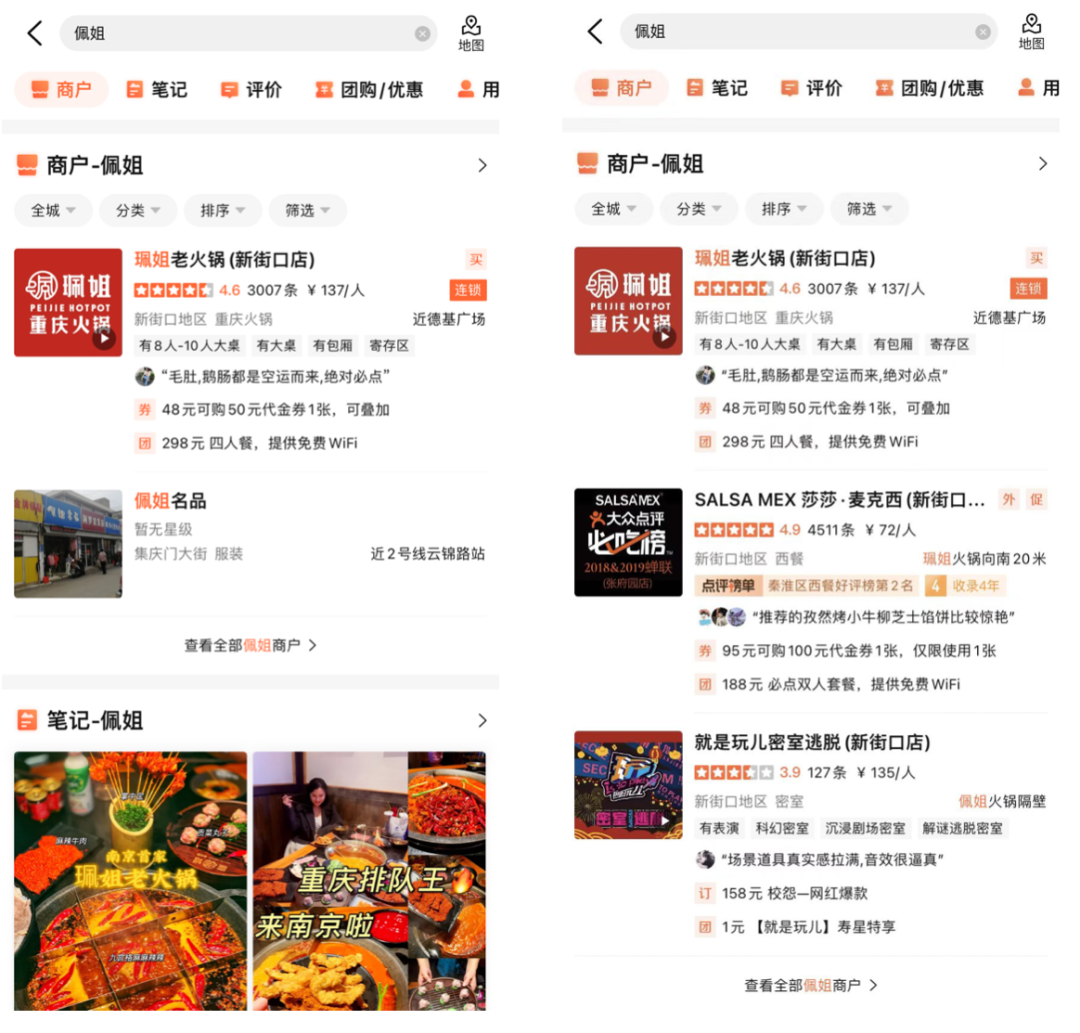
(a) Sister Pei
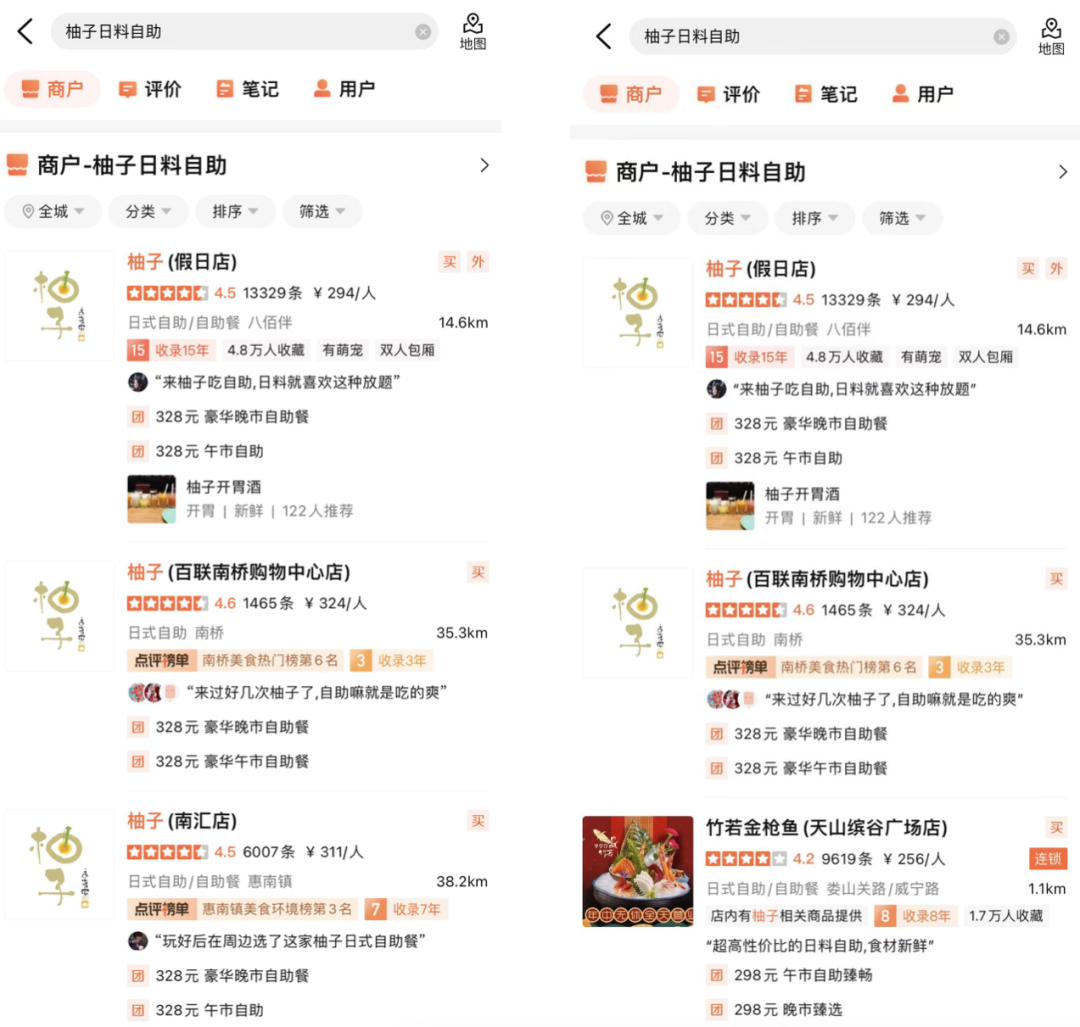 (b) Pomelo Japanese Food BuffetFigure 10 Online BadCase solution example
(b) Pomelo Japanese Food BuffetFigure 10 Online BadCase solution example
This article introduces the technical solution and practical application of the Dianping search correlation model. In order to better construct the merchant-side model input information, we introduced a method of extracting merchant matching field summary text in real time to construct merchant representations as model input; in order to optimize the model to better adapt to review search correlation calculations, a two-stage process was used The training method adopts a two-stage training scheme based on clicks and manual annotation data to effectively utilize the user click data of Dianping. According to the characteristics of correlation calculation, a deep interaction structure based on multiple similarity matrices is proposed to further improve the correlation model. Effect; In order to alleviate the online computing pressure of the correlation model, the caching mechanism and TF-Serving prediction acceleration are introduced during online deployment, the golden rule layer is introduced to offload Query, and the correlation calculation is parallelized with the core sorting layer, thus satisfying the online requirements. Performance requirements for real-time calculation of BERT. By applying the correlation model to each link of the search link, the proportion of irrelevant questions is significantly reduced and the user's search experience is effectively improved.
Currently, the review search correlation model still has room for improvement in model performance and online applications. In terms of model structure, we will explore ways to introduce prior knowledge in more fields. For example, multi-task learning to identify entity types in Query, input from external knowledge optimization models, etc.; in terms of practical applications, it will be further refined into more levels to meet users' needs for refined store search. We will also try to apply the ability of relevance to non-merchant modules to optimize the search experience of the entire search list.
Xiao Ya*, Shen Yuan*, Zhu Di, Tang Biao, Zhang Gong, etc. , all from the Search Technology Center of Meituan/Dianping Division. * is a co-author of this article.
The above is the detailed content of Exploration and practice of Dianping search relevance technology. For more information, please follow other related articles on the PHP Chinese website!
 What skills are needed to work in the PHP industry?
What skills are needed to work in the PHP industry?
 How to convert html to txt text format
How to convert html to txt text format
 What are the linux deletion commands?
What are the linux deletion commands?
 jquery validate
jquery validate
 What are the basic components of a computer?
What are the basic components of a computer?
 Solution to the problem that win7 system cannot start
Solution to the problem that win7 system cannot start
 Cancel WeChat campaign
Cancel WeChat campaign
 What to do if the web page cannot be accessed
What to do if the web page cannot be accessed





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



