


Word embedding representation is the basis for various natural language processing tasks such as machine translation, question answering, text classification, etc. It usually accounts for 20% to 90% of the total model parameters. Storing and accessing these embeddings requires a large amount of space, which is not conducive to model deployment and application on devices with limited resources. In response to this problem, this article proposes the MorphTE word embedding compression method. MorphTE combines the powerful compression capabilities of tensor product operations with prior knowledge of language morphology to achieve high compression of word embedding parameters (more than 20 times) while maintaining the accuracy of the model. performance.

This article proposes The MorphTE word embedding compression method first divides words into the smallest units with semantic meaning - morphemes, and trains a low-dimensional vector representation for each morpheme, and then uses tensor products to realize the mathematical representation of quantum entangled states of low-dimensional morpheme vectors. , thereby obtaining a high-dimensional word representation.
01 The morpheme composition of a wordIn linguistics, a morpheme is the smallest unit with specific semantic or grammatical functions. For languages such as English, a word can be split into smaller units of morphemes such as roots and affixes. For example, "unkindly" can be broken down into "un" for negation, "kind" for something like "friendly," and "ly" for an adverb. For Chinese, a Chinese character can also be split into smaller units such as radicals. For example, "MU" can be split into "氵" and "木" which represent water.

02 Compressed representation of word embeddings in the form of entangled tensors
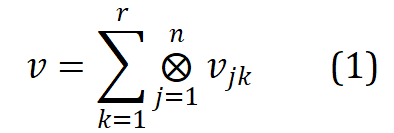 ##where
##where
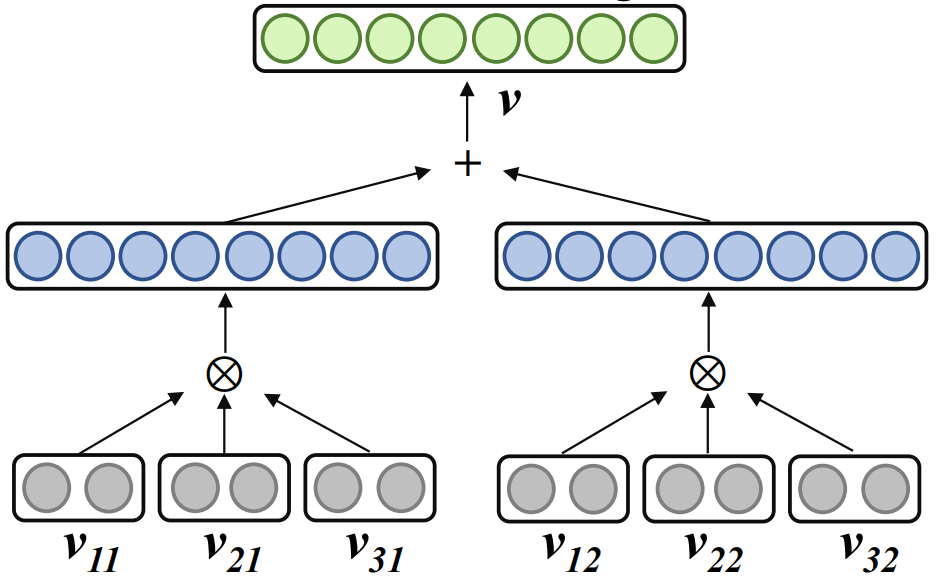
, r is rank, n is order, represents tensor product. Word2ket only needs to store and use these low-dimensional vectors to build high-dimensional word vectors, thereby achieving effective parameter reduction. For example, when r = 2 and n = 3, a word vector with a dimension of 512 can be obtained by two groups of three low-dimensional vector tensor products with a dimension of 8 in each group. At this time, the required number of parameters is reduced from 512 to 48 . 03 Morphology-enhanced tensorized word embedding compression representation
Specifically, first use the morpheme segmentation tool to segment the words in the word list V. The morphemes of all words will form a morpheme list M, and the number of morphemes will be significantly lower than the number of words ().
For each word, construct its morpheme index vector, which points to the position of the morpheme contained in each word in the morpheme table. The morpheme index vectors of all words form a 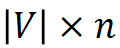 morpheme index matrix, where n is the order of MorphTE.
morpheme index matrix, where n is the order of MorphTE.
For the j-th word 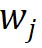 in the vocabulary, use its morpheme index vector
in the vocabulary, use its morpheme index vector 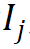 to parameterize it from the r group The corresponding morpheme vector is indexed into the morpheme embedding matrix, and the corresponding word embedding is obtained by entangled tensor representation through tensor product. The process is formalized as follows:
to parameterize it from the r group The corresponding morpheme vector is indexed into the morpheme embedding matrix, and the corresponding word embedding is obtained by entangled tensor representation through tensor product. The process is formalized as follows:
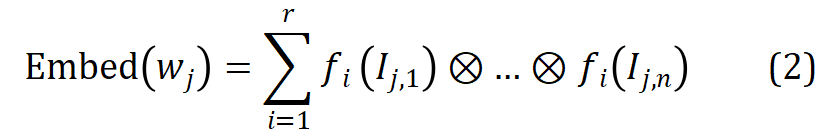
Through the above methods, MophTE can inject morpheme-based linguistic prior knowledge into the word embedding representation, and the sharing of morpheme vectors between different words can explicitly build inter-word connections. In addition, the number and vector dimensions of morphemes are much lower than the size and dimension of the vocabulary, and MophTE achieves compression of word embedding parameters from both perspectives. Therefore, MophTE is able to achieve high-quality compression of word embedding representations.
This article mainly conducts experiments on translation, question and answer tasks in different languages, and compares it with related decomposition-based word embedding compression methods.
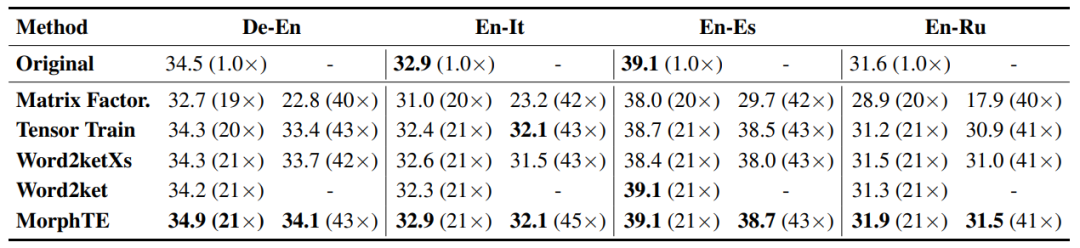
As you can see from the table, MorphTE can adapt to different languages such as English, German, and Italian. At a compression ratio of more than 20 times, MorphTE is able to maintain the effect of the original model, while almost all other compression methods show a decrease in effect. In addition, MorphTE performs better than other compression methods on different data sets at a compression ratio of more than 40 times.
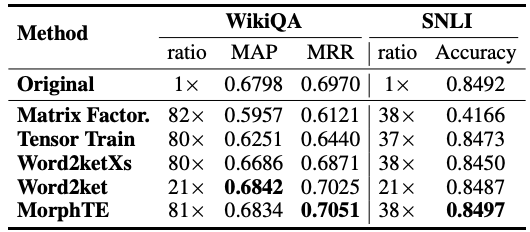
Similarly, MorphTE achieved a compression ratio of 81 times and 38 times respectively on WikiQA's question and answer task and SNLI's natural language reasoning task. , while maintaining the effect of the model.
MorphTE combines a priori morphological language knowledge and the powerful compression capability of tensor products to achieve high-quality compression of word embeddings. Experiments on different languages and tasks show that MorphTE can achieve 20 to 80 times compression of word embedding parameters without damaging the effect of the model. This verifies that the introduction of morpheme-based linguistic knowledge can improve the learning of compressed representations of word embeddings. Although MorphTE currently only models morphemes, it can actually be extended into a general word embedding compression enhancement framework that explicitly models more a priori linguistic knowledge such as prototypes, parts of speech, capitalization, etc., to further improve word embedding compression. express.
The above is the detailed content of Does word embedding represent too large a proportion of parameters? MorphTE method 20 times compression effect without loss. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



