


收集器是一种通用的、从流生成复杂值的结构。可以使用它从流中生成List、Set、Map等集合。 收集器都是在流的collect方法中调用,并且都在 Collectors类中。
java 的标准类库提供了很多有用的收集器,当然了,也可以自己自定义(这个对于使用者的要求很高)。
下面提供一个代码,用于测试接下里要说的收集器:
提供了一个简单的测试数据
学号 姓名 性别 语文 数学 英语 物理 政治 总分
09509002 节强 男 86 90 90 93 90
09509003 杨青 女 90 90 82 91 92
09509006 徐刚 男 78 92 83 90 87
09509111 马力 男 77 88 99 90 88
09509001 武向丽 女 90 78 83 94 94
09509007 张文静 女 85 90 79 94 88
09509005 徐小红 女 78 85 88 93 92
09509009 李姝 女 92 80 75 90 88
09509004 李文华 男 68 59 70 85 90
09509008 夏婧 女 87 65 73 91 95
09509010 王洪 男 66 48 89 70 57
Student 实体类封装数据
package com.cdragon;
public class Student implements Comparable<Student> {
private String number;
private String name;
private String sex;
private Integer chinese;
private Integer math;
private Integer english;
private Integer physics;
private Integer politics;
//省略getter和setter方法,这个使用IDE自动生成特别方便。
//省略toString方法,同上。
@Override
public int compareTo(Student s) {
return s.getNumber().compareTo(this.getNumber());
}
}LoadData 类加载数据到内存
package com.cdragon;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
public class LoadData {
public static List<Student> readFromFile(File file) {
List<Student> students = new ArrayList<>();
try (BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file)))) {
String record = null;
String header = br.readLine();
//对于数据的第一行头,暂时不做处理。
while ((record = br.readLine() ) != null) {
Student s = resolveLineToStudent(record);
students.add(s);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return students;
}
private static Student resolveLineToStudent(String record) {
String[] array = record.split("\\s+"); // \\s 和 \\s+ 还是有区别的!
Student s = new Student();
s.setNumber(array[0]);
s.setName(array[1]);
s.setSex(array[2]);
s.setChinese(Integer.parseInt(array[3]));
s.setMath(Integer.parseInt(array[4]));
s.setEnglish(Integer.parseInt(array[5]));
s.setPhysics(Integer.parseInt(array[6]));
s.setPolitics(Integer.parseInt(array[7]));
return s;
}
}使用收集器是可以生成其他集合的,例如生成List、Set 和 Map等,下面来分别举例:
//生成 List
List<Student> studentList = students.stream().collect(Collectors.toList());
//生成 Set
Set<Student> studentSet = students.stream().collect(Collectors.toSet());
//生成指定集合
TreeSet<Student> studentTreeSet = students.stream().collect(Collectors.toCollection(TreeSet::new));
//生成 Map
Map<String, Student> studentMap = students.stream().collect(Collectors.toMap(Student::getNumber, s->s));
studentMap.forEach((no, s)->{
System.out.println(no + "->" + s);
});说明:通常的 toList() 和 toSet() 方法是不指定生成集合的具体类型,这是由系统来选择最合适的类型,但是有时候我们必须返回特定的类型集合,这就用到了 toCollection() 方法,这个方法可以指定需要生成的集合的类型,这是使用方法引用进行简化代码:TreeSet::new
测试结果:
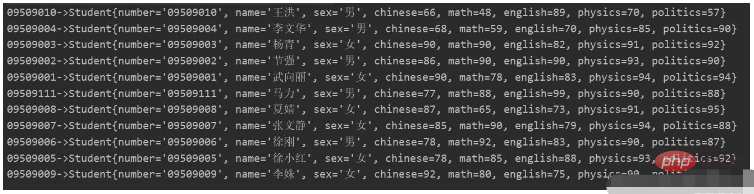
注意:生成 Map 的方式较为复杂,因为需要同时指定键和值。
使用收集器生成一个值。
最大值和最小值
Collectors 类中的 maxBy 和 minBy 允许用户按照某种特定顺序生成一个值。它们的作用就如同它们的名字一样,分别是寻找最大值和最小值。
我写成一个方法,这样调用比较方便。
/**
* 获取单科最高分。
* */
public static Optional<Student> minOrMaxSubject(List<Student> students, Comparator<? super Student> comparator) {
return students.stream().collect(Collectors.maxBy(comparator));
}说明:使用 maxBy 或者 minBy 必须传入一个 Comparator 对象作为参数,即参数为一个比较器。
测试代码
//这个文件的路径应该使用自己指定的
List<Student> students = LoadData.readFromFile(new File("src/grade.txt"));
//获取数学最高分学生
Optional<Student> s1 = TestStream.minOrMaxSubject(students, Comparator.comparing(Student::getMath));
//获取英语最高分
Optional<Student> s2 = TestStream.minOrMaxSubject(students, Comparator.comparing(Student::getEnglish));
System.out.println(s1.get());
System.out.println(s2.get());测试结果

说明:如果想要测试最低分,只要把上面的 maxBy 改成 minBy 就行了,或者直接更进一步,修改参数为collect里面传入的函数,不过那样就会显得格外复杂,而且不止可以查最高分和最低分了。
平均值
上面看过了最大值和最小值,现在来看看平均值。 下面这个方法是用来求单科平均分的。
/**
* 获取单科平均分
* */
public static double averageScore(List<Student> students, ToIntFunction<? super Student> mapper) {
return students.stream().collect(Collectors.averagingInt(mapper));
}测试代码
List<Student> students = LoadData.readFromFile(new File("src/grade.txt"));
double math = TestStream.averageScore(students, Student::getMath);
System.out.println("数学的单科平均分:" + math);测试结果

数据分块是指收集器将流分为两个集合,注意分块是只能分成两块。这里标准类库提供了一个收集器 partitioningBy,它接受一个流,并将其分为两个部分。返回的结果为一个 Map,键只有两种:true 或者 false,值是满足对应条件的集合。
例如我想知道某们成绩 90分以上和一下的学生分别是哪些。
/**
* 以特定分数划分不同学生,例如90分以上(含90分)和90分一下。
* 结果是一个Map集合,只有两个元素,true false 个对应一个集合。
* */
public static Map<Boolean, List<Student>> splitScore(List<Student> students, Predicate<? super Student> predicate) {
return students.stream().collect(Collectors.partitioningBy(predicate));
}说明:partitioningBy的参数为一个 Predicate 对象,这个和过滤器的很相似,功能上可以对比学习。
测试代码
//数学成绩以90分来划分学生
Map<Boolean, List<Student>> booleanListMap = TestStream.splitScore(students, stu->stu.getMath()>=90);
booleanListMap.forEach((bool, list)->{
System.out.println("数学成绩大于90分:" + bool);
list.forEach(System.out::println);
System.out.println("========================");
});测试结果
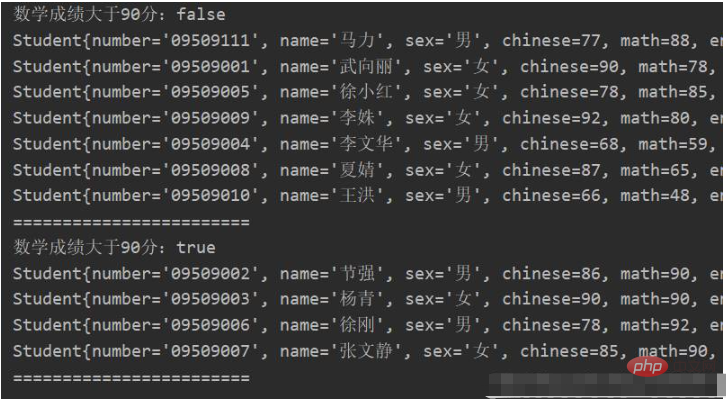
数据分组是一种更为自然的分割数据操作,与将数据分成true和false两部分不同,可以使用任意值对数据分组。比如使用性别对学生进行分组。这很像SQL中的 groupBy 操作。
/**
* 数据分组
* 这里以性别来分组
* */
public static Map<String, List<Student>> groupBy(List<Student> students) {
return students.stream().collect(Collectors.groupingBy(Student::getSex));
}测试代码
Map<String, List<Student>> stringListMap = TestStream.groupBy(students);
stringListMap.forEach((sex, list)->{
System.out.println("性别:" + sex);
list.forEach(System.out::println);
System.out.println("============");
});测试结果
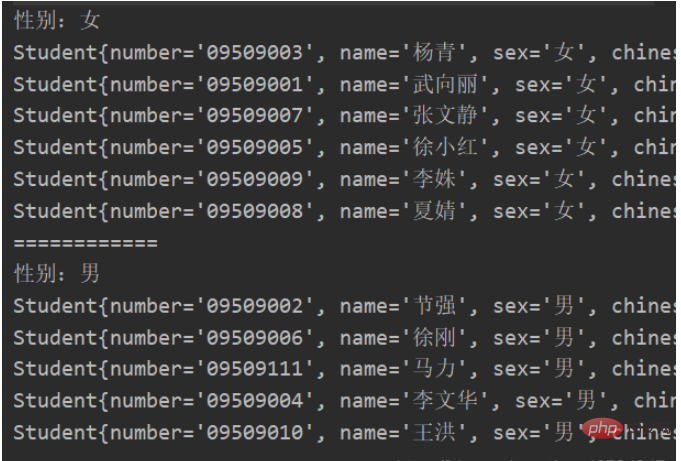
收集流中的数据最后生成一个字符串,这是一个很平常的操作。 例如一个所有学生的姓名列表,使用传统的迭代列表操作代码如下:
/**
* 获取所有学生姓名的字符串
* 传统的迭代操作
* 格式如下:[张三,李四]
* */
public static String nameStr1(List<Student> students) {
StringBuilder builder = new StringBuilder("[");
for (Student stu : students) {
if (builder.length() > 1){
builder.append(",");
}
String name = stu.getName();
builder.append(name);
}
builder.append("]");
return builder.toString();
}然后是使用收集器进行操作,代码如下: 这里我添加一些细节处理,学生的排名按照学生的总成绩从高到底排列,这是很符合习惯的。
/**
* 获取所有学生姓名的字符串
* 函数式方法
* 格式如下:[张三,李四]
*
* 注意,他只能连接字符串,所有这里使用 map 操作,将 Student 转成 String(学生姓名)
* */
public static String nameStr2(List<Student> students) {
return students.stream()
.sorted(Comparator.comparing(s -> {
return s.getChinese() + s.getMath() + s.getEnglish()
+ s.getPhysics() + s.getPolitics();
}, Comparator.reverseOrder())) //(sum1, sum2)-> sum2.compareTo(sum1)
.map(Student::getName)
.collect(Collectors.joining(",","[","]"));
}说明:这里的 sorted 需要传入一个 Comparator 对象,但是可以使用静态方法 Compring 进行简化,但是它只是指定需要排序的标准,并没有说是从小到大还是从大到小,后来才发现,这个是默认的:大小到大排序。但是我需要的是使用从大到小,然后发现原来 compring 还有重载方法,具有两个参数,另一个参数是可以指定大小顺序的,所以第二个参数我传入了一个 Lambda 表达式:
(sum1, sum2)-> sum2.compareTo(sum1)
但是如果这样使用的话,还不如直接使用 Lambda 表达式创建 Comparator 对象方便呢,后来发现这个 IDE 比较智能,它指出这句代码,可以被替换为:
Comparator.reverseOrder();// 看意思就知道是 反序的意思。
这样看来使用 Comparator 静态的 comparing 方法还是比直接创建 Comparator 对象简单一些。
注意:如果不需要排序的话,就只有一个map方法和join方法了。这个map方法的作用是映射(我一开始把它和map集合总是搞混了),将Student对象映射为name字符串,然后使用 join 方法进行连接。
收集器还可以组合起来使用,这个和 SQL 感觉更像了,几乎具有函数式编程的语言,都有SQL那种处理数据的方式,例如最大值、最小值和分组等操作。 考虑对于学生按照性别分组,然后再分别统计男女生的人数。(这个在 SQL 里面也是一个基本的练习。)
/**
* 组合收集器
* 这里以性别来分组,再分别计数
* */
public static Map<String, Long> combination(List<Student> students) {
return students.stream().collect(Collectors.groupingBy(Student::getSex, Collectors.counting()));
}测试代码
Map<String, Long> stringLongMap = TestStream.combination(students);
stringLongMap.forEach((sex, count)->{
System.out.println("性别:" + sex + ", 人数:" + count);
});测试结果

对于流的使用,应该达到一个较为熟练的地步,但是由于没有什么机会实践,还是比较陌生。下面介绍几个我写的方法,来看看流的操作:
//通过过滤器选择特定的学生,过滤器用于过滤,然后选择第一个学生。
//这里应该加一个排序操作比较好。
public static Optional<Student> selectStudent(List<Student> students, Predicate<? super Student> pre) {
return students.stream().filter(pre).findFirst();
}
public static List<Student> orderBy(List<Student> students, Comparator<? super Student> comparator) {
if (comparator != null){
return students.stream().sorted(comparator).collect(Collectors.toList());
} else {
return students.stream().sorted().collect(Collectors.toList());
}
}
//获取一列数据。不是一行学生记录,是一列。
public static List<?> getAColumn(List<Student> students, Function<? super Student, ?> mapper) {
return students.stream().map(mapper).collect(Collectors.toList());
}
/**
* 获取所有学生的总分和学号
* */
public static Map<String, Integer> getSum(List<Student> students) {
return students.stream().collect(Collectors.toMap(Student::getNumber, stu->{
return stu.getChinese() + stu.getEnglish() + stu.getMath() + stu.getPhysics() + stu.getPolitics();
}));
}
/**
* peek 和 forEach 的区别
* peek 是一个中间操作,forEach 是一个终结操作。
*
* 假如实现一个功能:每个学生的某门科目分数进行修改。
*
* peek 操作后得到的仍然是一个 stream,此时可以进一步操作,
* 但是 forEach 是终结操作,操作结束,流就结束了,如果需要进一步处理,
* 必须再次进行得到流的操作。
* */
public static List<Student> addScore1(List<Student> students, Consumer<? super Student> action) {
return students.stream().peek(action).collect(Collectors.toList());
}
public static void addScore2(List<Student> students, Consumer<? super Student> action) {
students.stream().forEach(action);
}
//指定返回类型为 LinkedList,这时一个测试,并不是说需要这样写。
//多数情况下,我们还是应该使用 ArrayList
public static List<Student> addScore3(List<Student> students, Consumer<? super Student> action) {
return students.stream().peek(action).collect(Collectors.toCollection(LinkedList::new));
}对于其中的几个进行测试(不是全部方法,如果感兴趣,可以自己尝试。):
//对于学生进行排序,参数为一个比较器,参数为空的话,使用默认的 sorted 排序。
//测试代码 按照学号排序(默认从小到大)
TestStream.orderBy(students,Comparator.comparing(Student::getNumber)).forEach(System.out::println);
//按照学号排序(从大到小)
TestStream.orderBy(students,Comparator.comparing(Student::getNumber, Comparator.reverseOrder())).forEach(System.out::println);
//使用默认的排序
TestStream.orderBy(students).forEach(System.out::println);
//获取一列学生的记录,例如这里是英语成绩,这里返回值我使用通配符应该没有错吧
//因为返回数据可能为 String 也可能是 Integer
TestStream.getAColumn(students,Student::getEnglish).forEach(System.out::println);
//测试学生的总分
TestStream.getSum(students).forEach((no, stu)->{
System.out.println(no + " -> " + stu);
});The above is the detailed content of How to apply the collector in Java8 functional programming. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



