


Running effect:
Before running: There are 9 files under this path.
After running: a merge.txt file is generated
File content display
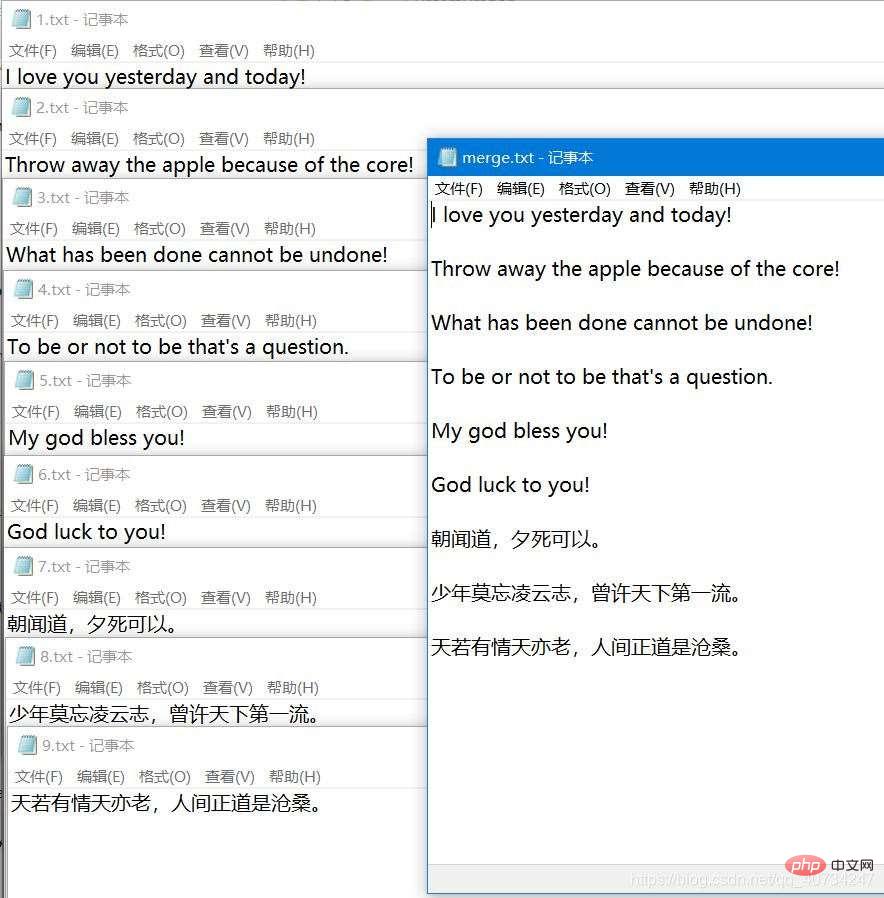
Code part
The function of this part of the code is very simple. It is to merge text files one by one and write them into a total merge.txt file. folder, I learned how to append content to files, so I wrote this demo.
To put it simply, it is to get each file (text file, I filtered it.) to get an input stream, and then within a loop, write the information of one file each time into the merged file. The loop ends and the files are merged. It's finished.
package com.filemerge; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStreamWriter; public class FileMerge { //参数为一个文件夹路径 public static void fileMerge(String path){ File target = new File(path); //待合并文件夹目录 File output = new File(path+File.separator+"merge.txt"); //合并文件夹位置 String[] names = target.list((dir,name)->name.contains(".txt")); //过滤非文本文件,返回值为一个 String 数组 BufferedReader reader = null; BufferedWriter writer = null; //OutputStreamWriter 不要记错了! try { writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(output,true))); for (String name : names) { reader = new BufferedReader(new InputStreamReader(new FileInputStream(target+File.separator+name))); String line = null; while((line = reader.readLine()) != null) { writer.write(line); writer.newLine(); } writer.newLine(); //每个文件进行换行分隔内容! } System.out.println("File merge successfully!"); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } finally { try { reader.close(); writer.close(); } catch (IOException e) { e.printStackTrace(); } } } }
Test code:
package com.filemerge; public class Test { public static void main(String[] args) { FileMerge.fileMerge("D:/DB/DreamDragon"); } }
If you have finished reading the text file merging above, you might as well read a little more , also read the code of the image file below. If there are any errors, please point them out. (There is also some knowledge about pictures, I don’t know who can point it out.)
The code is as follows: Merge Picture Tool Class
package dragon; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.BufferedWriter; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStreamWriter; public class ImageMerge { //图片合并路径,将要合并图片放入同一个文件夹方便操作 public static final String mergePath = "D:/DragonDataFile/beauty"; public static final String outputPath = "D:/DragonDataFile/merge"; //工具类,就只是用静态方法了,不要创建对象了。 private ImageMerge() {} /**执行合并操作 * * 思路如下:首先获取文件夹下面的所有图片文件信息, * 然后使用输入输出流依次将文件进行合并操作。 * * 这里的信息是指的文件大小,最重要的是文件的大小, * 考虑其它因素,不记录文件名,所以拆分时,会丢失文件名, * 但是不影响图片的显示。 */ public static void imageMerge() throws IOException { File mergeFile = new File(ImageMerge.mergePath); File outputFile = new File(ImageMerge.outputPath); if (!initPath(mergeFile, outputFile)) { // 无法创建 mergePath throw new FileNotFoundException("无法创建文件夹: "+ImageMerge.mergePath); } try (//创建输出文件 BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(new File(outputFile, System.currentTimeMillis()+".jpeg")))){ File[] files = mergeFile.listFiles(); recordImageInfo(files, outputFile); //记录文件信息,保存于图片的文件夹下,可能更好点。 for (File file : files) { try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file))){ int hasRead = 0; byte[] b = new byte[1024]; while ((hasRead = bis.read(b)) != -1) { bos.write(b, 0, hasRead); } } } } } //初始化路径,如果 mergePath 不存在 private static boolean initPath(File mergeFile, File outputFile) { boolean mk_mergeFile = false, mk_outputFile = false; if (!mergeFile.exists()) { // mergePath 不存在 mk_mergeFile = mergeFile.mkdirs(); } else { mk_mergeFile = true; } if (!outputFile.exists()) { mk_outputFile = outputFile.mkdirs(); } else { mk_outputFile = true; } return mk_mergeFile && mk_outputFile; } //记录信息 private static void recordImageInfo(File[] files, File outputFile) throws FileNotFoundException, IOException { try ( BufferedWriter bos = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(outputFile,"mergeImageInfo.txt"), true)))){ for (File file : files) { String record = file.length()+" "; bos.write(record); bos.newLine(); } } } }
Image separation tool class
package dragon; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStreamReader; import java.util.LinkedList; import java.util.List; import java.util.UUID; public class ImageSeparate { //拆分文件的位置 private static final String separatePath = "D:/DragonDataFile/separate"; private ImageSeparate() {} /** * 合并后文件夹下面有两个文件(应该每一批合并文件,一个单独的文件夹): * 合并后文件,合并文件信息(大小)。 * * 思路:首先读取合并文件信息,然后依据大小依次从文件中取出 * 对应大小的字节数,写入一个文件中。 * @throws IOException * */ public static void imageSeparate() throws IOException { File separateFile = new File(ImageSeparate.separatePath); if (initPath(separateFile)) { //无法创建文件夹 throw new FileNotFoundException("无法创建文件夹: "+ImageSeparate.separatePath); } File outputFile = new File(ImageMerge.outputPath); //下面获取的都是 String 数组,但是正常情况下应该都是只有一个 String 的字符串 //获取图片文件信息文件 File[] infoFile = outputFile.listFiles(f->f.getName().contains(".txt")); //获取合并图片文件 File[] mergeFile = outputFile.listFiles(f->!f.getName().contains(".txt")); // 获取信息文件信息(图片的长度) List fileInfo = getFileInfo(infoFile[0]); try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream(mergeFile[0]))){ fileInfo.stream().forEach(len->{ String filename = System.currentTimeMillis()+UUID.randomUUID().toString()+".jpeg"; System.out.println(filename); try ( BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(new File(separateFile, filename)))){ long record = 0; int hasRead = 0; byte[] b = new byte[1024]; /** * 这里处理比较麻烦,我说明一下: * 一次性去读 len 长度的数据,考虑到有时候文件会非常大,这个数据对内存的压力很大, * 所以舍弃了,如果文件很小,倒也是一个很好的方式(简便)。 * * 这里采用逐次读取的方式:(一般图片都会大于 1024 字节的,这个不考虑) * 当读取一次后,判断剩余的字节数是否小于 1024,如果小于的话,就直接 * 一次性读取这些字节数,并写入文件中,然后跳出循环,本次文件读取完成。 * */ while ((hasRead = bis.read(b)) != -1) { bos.write(b,0,hasRead); //先判断,再读取数据,否则会出错。 record += (long)hasRead; if (len-record < 1024) { long tail = len-record; bis.read(new byte[(int)tail]); bos.write(b, 0, (int)tail); break; } } } catch (IOException e) { e.printStackTrace(); } }); } } //获取信息文件信息(图片的长度) private static List getFileInfo(File file) throws NumberFormatException, IOException{ List fileInfo = new LinkedList<>(); try ( BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file)))){ String line = null; while ((line = br.readLine()) != null) { //将数据转换为 long 再存入集合,或许使用 DataInputStream 更好吧 //注意,如果这个文件里面被修改了,可能会引发 RuntimeException String[] str = line.split(" "); fileInfo.add(Long.parseLong(str[0])); System.out.println(line); } } return fileInfo; } //初始化 拆分文件位置 private static boolean initPath(File file) { return file.mkdirs(); } }
Test class
package dragon; import java.io.IOException; public class Client { public static void main(String[] args) throws IOException, NumberFormatException, ClassNotFoundException { //如果需要合并图片,就使用第一条语句,注释第二条, //如果需要拆分图片,就使用第二条语句,注释第一条 ImageMerge.imageMerge(); // ImageSeparate.imageSeparate(); } }
Description:
Each class contains many comments , should still be able to express the meaning clearly, there are a few points that need to be explained.
Running effect:
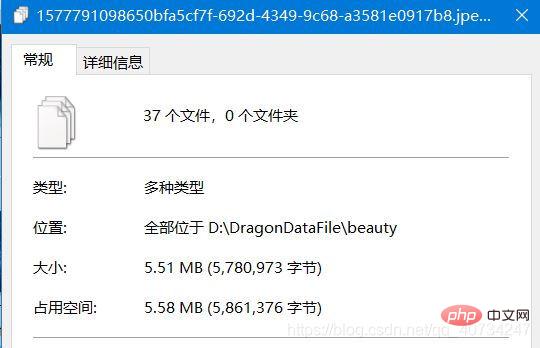
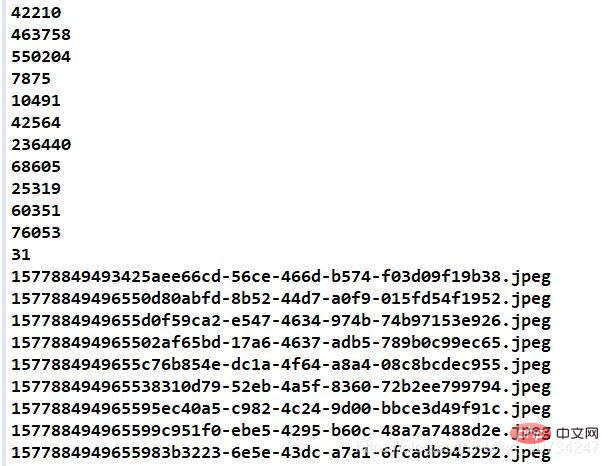
Test preparation pictures:Pay attention to the path of the folder and the first picture.
Test preparation picture information:Pay attention to the file size and occupied space information.
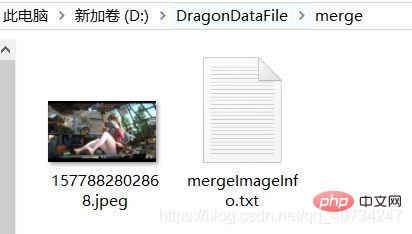
Merge effect:Pay attention to the paths of the merged pictures and merged files.
The merged file will produce a separate text file, which stores the size information of the image, because this information is needed to restore the image, otherwise the image may not be recovered.
Note: When I saw this result, I felt amazing. Although 37 pictures were merged, it could still display the information of the first picture normally. This may be related to the storage of the picture itself. It has to do with form (I have no knowledge of this).
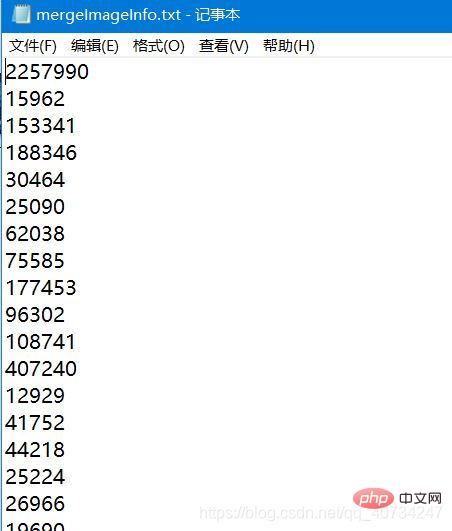
Text file information screenshot:
Note: I store it in row units, one data per row, read This is also the case, it feels more convenient.Never modify any information in this file, otherwise the image information will not be restored.
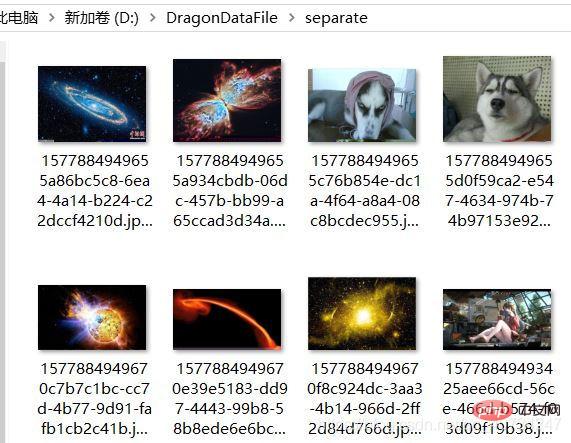
Recover the picture:Pay attention to the picture in the lower right corner, because I did not retain the file name, so the file of the picture was generated The name isgenerated by rewriting. I also noticed that my file name is relatively long. You can refer to the blog link at the beginning. Here is the image name generated using the UUID of the milliseconds of the current date. It is indeed relatively long. But it won't be repeated, which is what I need.
Console input information:
I will combine the read picture information (size data of each picture) and the data generated when restoring the picture The picture file name is printed out, which makes debugging more convenient and looks good, ha!
The merging of pictures is a simple merging of files. It just gets the input stream of each file and writes it in sequence. in an output stream. (A byte stream is used here, and character streams cannot be used for pictures!)
for (File file : files) { try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file))){ int hasRead = 0; byte[] b = new byte[1024]; while ((hasRead = bis.read(b)) != -1) { bos.write(b, 0, hasRead); } } }
这里比较难得是如何从一个整的合并图片中恢复所有图片的信息,因为图片的特殊存储格式,如果在图片的头部产生错误,就无法识别了(我只知道图片头部含有一个魔数,用于标识图片,其他的不是很清楚,我没有这图像方面的知识,如果有人知道,可以在下面评论。),一个字节也不行!
我来说一说我的想法:
举个例子,干巴巴的说着估计很难讲的明白。
先看下面这张图片,假定这是(合并后图片中)某个图片 的信息,我们需要在一个完整的输入流中,完整的取出来这一部分,不能多也不能少!注意是顺序读取数据。再强调一下,这是中间某一张图片,也就是这个图表示某一个图片的数据,但是不是整个文件的数据,也就是说,这个图片下面还有数据,最下面那个小于 1024 byte,只是表示这张图片还剩下少于 1024 byte得数据。
所以下面这种读取方式是错误的,无法正确的恢复图片。
byte[] b = new byte[1024]; while ((hasRead = bis.read(b)) != -1) { bos.write(b, 0, hasRead); }

其实有一种很简单的方式,就是下面注释中的方式,每次直接将整个图片的数据读取出来,写入一个输出流,就是一张完整得图片了,简单粗暴,但是我考虑到,有时候图片太大,对于内存是一个很大的消耗,没有采用这种方式。
仍然采用逐次读取的方式:
说明:
设置一个字节计数器,在每次读取(1024byte)之后,下一次读取之前,判断当前图片的大小和当前读入的字节数的差值是否大于 1024 字节,即是否满足一次完整的读取,如果满足的条件,就继续读取写入操作,如果不足 1024字节,说明不能再进行读取写入了(因为当前图片下面还有其它图片数据,所以仍然是可以读取 1024 字节的,只是属于当前图片的字节数,不足 1024 字节了,即不能进行一次完整的读取了。)所以,如果不足以进行一次完整的读取,那就只读当前还需要的字节,只需要读取一次就行了,读取之后将数据写入输出流,退出当前循环,进行下一张图片的读取。可以画图观察一下,就会理解了。
try ( BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(new File(separateFile, filename)))){ long record = 0; int hasRead = 0; byte[] b = new byte[1024]; /** * 这里处理比较麻烦,我说明一下: * 一次性去读 len 长度的数据,考虑到有时候文件会非常大,这个数据对内存的压力很大, * 所以舍弃了,如果文件很小,倒也是一个很好的方式(简便)。 * * 这里采用逐次读取的方式:(一般图片都会大于 1024 字节的,这个不考虑) * 当读取一次后,判断剩余的字节数是否小于 1024,如果小于的话,就直接 * 一次性读取这些字节数,并写入文件中,然后跳出循环,本次文件读取完成。 * */ while ((hasRead = bis.read(b)) != -1) { bos.write(b,0,hasRead); //先判断,再读取数据,否则会出错。 record += (long)hasRead; if (len-record < 1024) { long tail = len-record; bis.read(new byte[(int)tail]); bos.write(b, 0, (int)tail); break; } } } catch (IOException e) { e.printStackTrace(); }
如果仔细阅读了我的代码,应该可以看出来了,有一些地方写的不好。
主要有以下几点:
没有保存图片的类型,恢复图片时,只能强行指定文件的后缀名为jpeg,这样做不是很好的做法。
恢复图片时,直接指定为jpeg,不太合适。
String filename = System.currentTimeMillis()+UUID.randomUUID().toString()+".jpeg";
这个是创建合并文件时,指定第一张图片的后缀名,这样做也不是很好。
new File(outputFile, System.currentTimeMillis()+".jpeg")
所以我对上面代码进行了改进,在保存图片的大小信息的同时,保存图片的后缀名信息(一般都是有的,但是如果没有的话,我就指定一个 “.none” 作为后缀名了)。一开始我是准备还是直接按照如下形式存储:
图片大小 [空格分隔] 图片后缀名
但是实际处理过程中,这样感觉还是比较麻烦的,因为存储的数据都是字符信息了,Java是没有办法直接使用的,显示转换太麻烦了,所以我决定不使用这种方式了,转而使用Java的对象序列化。因为同时需要大小和后缀名两个属性,而且两个属性之间也是具有很强关系的(一对一),干脆封装一下,做成一个Java类,这样使用起来很方便,而且两个属性之间也建立了联系,序列化恢复也比较方便。而且对象序列化还带来一个好处,Java的对象序列化是二进制序列化,区别于 json 这种字符序列化,二进制是机器读取的,我们就算打开了也是乱码,所以,可以避免这个文件被别人给修改了。(一般是不会去修改二进制文件的吧,哈!)
图片对象模型
package dragon; import java.io.Serializable; /** * 文件信息模型类: * 记录文件的大小和后缀名,因为总是 * 需要使用这个,就把它封装起来使用吧。 * */ public class FileInfo implements Serializable{ /** * 序列化 id */ private static final long serialVersionUID = 1L; private long len; private String suffix; public FileInfo(long len, String suffix) { this.len = len; this.suffix = suffix; } public long getLen() { return this.len; } public String getSuffix() { return this.suffix; } //重写 toString 方法,方便打印调试代码 @Override public String toString() { return "FileInfo [len=" + len + ", suffix=" + suffix + "]"; } }
对于原来的图片合并和分隔方法,都进行了一点改进,所以命名规则上都在原来的类前面加了一个 Enhance (增强、改进)。
改进的图片合并类:EnhanceImageMerge
package dragon; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectOutputStream; import java.util.LinkedList; import java.util.List; public class EnhanceImageMerge { //图片合并路径,将要合并图片放入同一个文件夹方便操作 public static final String mergePath = "D:/DragonDataFile/beauty"; public static final String outputPath = "D:/DragonDataFile/merge"; //工具类,就只是用静态方法了,不要创建对象了。 private EnhanceImageMerge() {} /**执行合并操作 * * 思路如下:首先获取文件夹下面的所有图片文件信息, * 然后使用输入输出流依次将文件进行合并操作。 * * 这里的信息是指的文件大小,最重要的是文件的大小, * 考虑其它因素,不记录文件名,所以拆分时,会丢失文件名, * 但是不影响图片的显示。 */ public static void imageMerge() throws IOException { File mergeFile = new File(EnhanceImageMerge.mergePath); File outputFile = new File(EnhanceImageMerge.outputPath); if (!initPath(mergeFile, outputFile)) { // 无法创建 mergePath throw new FileNotFoundException("无法创建文件夹: "+EnhanceImageMerge.mergePath); } File[] files = mergeFile.listFiles(); String suffix = recordImageInfo(files, outputFile); //记录文件信息,保存于图片的文件夹下,可能更好点。 try (//创建输出文件 BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(new File(outputFile, System.currentTimeMillis()+suffix)))){ for (File file : files) { try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file))){ int hasRead = 0; byte[] b = new byte[1024]; while ((hasRead = bis.read(b)) != -1) { bos.write(b, 0, hasRead); } } } } } //初始化路径,如果 mergePath 不存在 private static boolean initPath(File mergeFile, File outputFile) { boolean mk_mergeFile = false, mk_outputFile = false; if (!mergeFile.exists()) { // mergePath 不存在 mk_mergeFile = mergeFile.mkdirs(); } else { mk_mergeFile = true; } if (!outputFile.exists()) { mk_outputFile = outputFile.mkdirs(); } else { mk_outputFile = true; } return mk_mergeFile && mk_outputFile; } 使用对象序列化进行数据的存储,方便快捷。 private static String recordImageInfo(File[] files, File outputFile) throws FileNotFoundException, IOException { try ( //二进制保存的数据,无法直接阅读,不加扩展名了 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File(outputFile, "fileinfo"), true))){ List fileInfos = new LinkedList<>(); for (File file : files) { String filename = file.getName(); //记录文件的大小和扩展名信息 如果没有的话,默认设置为 none。 long len = file.length(); String suffix = filename.lastIndexOf(".") != -1 ? filename.substring(filename.lastIndexOf(".")) : ".none"; FileInfo fileInfo = new FileInfo(len, suffix); System.out.println(fileInfo.toString()); fileInfos.add(fileInfo); } oos.writeObject(fileInfos); //直接将集合序列化,序列化单个对象,读取的时候太麻烦了 } String firstFileName = files[0].getName(); //返回第一个文件的后缀名。 return firstFileName.lastIndexOf(".") != -1 ? firstFileName.substring(firstFileName.lastIndexOf(".")) : ".none"; } }
注意:对象序列化的时候,如果每次序列化一个对象的话,那么读取的时候,就无法判断怎么结束了,因为程序不知道该读取多少次才结束,而且似乎不能使用读取结果为 null 来判断,那样会引发一个 EOFException。
我去查阅资料,有人推荐了,在序列化的最后,添加一个 null 对象,这确实是一个很好的方法,但是感觉还是不好。
另一种方式就是直接序列化一个List 集合,这样确实是方便多了,存入一个集合,读取回来了还是一个集合,可以直接操作了,还省去将对象再组装成集合的时间。(对象序列化,我只是了解,用过那么一两次,不是很熟。)
对象序列化部分
使用对象序列化进行数据的存储,方便快捷。 private static String recordImageInfo(File[] files, File outputFile) throws FileNotFoundException, IOException { try ( //二进制保存的数据,无法直接阅读,不加扩展名了 ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(new File(outputFile, "fileinfo"), true))){ List fileInfos = new LinkedList<>(); for (File file : files) { String filename = file.getName(); //记录文件的大小和扩展名信息 如果没有的话,默认设置为 none。 long len = file.length(); String suffix = filename.lastIndexOf(".") != -1 ? filename.substring(filename.lastIndexOf(".")) : ".none"; FileInfo fileInfo = new FileInfo(len, suffix); System.out.println(fileInfo.toString()); fileInfos.add(fileInfo); } oos.writeObject(fileInfos); //直接将集合序列化,序列化单个对象,读取的时候太麻烦了 } String firstFileName = files[0].getName(); //返回第一个文件的后缀名。 return firstFileName.lastIndexOf(".") != -1 ? firstFileName.substring(firstFileName.lastIndexOf(".")) : ".none"; }
改进的图片分隔类:EnhanceImageSeparate
package dragon; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.ObjectInputStream; import java.util.List; import java.util.UUID; public class EnhanceImageSeparate { //拆分文件的位置 private static final String separatePath = "D:/DragonDataFile/separate"; private EnhanceImageSeparate() {} /** * 合并后文件夹下面有两个文件(应该每一批合并文件,一个单独的文件夹): * 合并后文件,合并文件信息(大小)。 * * 思路:首先读取合并文件信息,然后依据大小依次从文件中取出 * 对应大小的字节数,写入一个文件中。 * * @throws IOException * @throws ClassNotFoundException * @throws NumberFormatException * */ public static void imageSeparate() throws IOException, NumberFormatException, ClassNotFoundException { File separateFile = new File(EnhanceImageSeparate.separatePath); if (initPath(separateFile)) { //无法创建文件夹 throw new FileNotFoundException("无法创建文件夹: "+EnhanceImageSeparate.separatePath); } File outputFile = new File(ImageMerge.outputPath); //下面获取的都是 String 数组,但是正常情况下应该都是只有一个 String 的字符串 //获取图片文件信息文件 File[] infoFile = outputFile.listFiles(f->!f.getName().contains(".")); //序列化文件是没有后缀名的 //获取合并图片文件 File[] mergeFile = outputFile.listFiles(f->f.getName().contains(".")); //图片文件都是有后缀名的 // 获取信息文件信息(图片的长度) System.out.println(infoFile[0]); List fileInfos = getFileInfo(infoFile[0]); mergeOperation(fileInfos, mergeFile[0], separateFile); } /** * 执行文件合并操作 * @param fileInfos 文件信息集合 * @param 需要合并文件的文件夹 * @param separateFile 合并操作后的文件夹 * * @throws IOException * @throws FileNotFoundException * */ private static void mergeOperation(List fileInfos, File mergeFile, File separateFile) throws FileNotFoundException, IOException { try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream(mergeFile))){ fileInfos.stream().forEach(fileInfo->{ long len = fileInfo.getLen(); String filename = System.currentTimeMillis()+UUID.randomUUID().toString()+fileInfo.getSuffix(); System.out.println(filename); try ( BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(new File(separateFile, filename)))){ long record = 0; int hasRead = 0; byte[] b = new byte[1024]; /** * 这里处理比较麻烦,我说明一下: * 一次性去读 len 长度的数据,考虑到有时候文件会非常大,这个数据对内存的压力很大, * 所以舍弃了,如果文件很小,倒也是一个很好的方式(简便)。 * * 这里采用逐次读取的方式:(一般图片都会大于 1024 字节的,这个不考虑) * 当读取一次后,判断剩余的字节数是否小于 1024,如果小于的话,就直接 * 一次性读取这些字节数,并写入文件中,然后跳出循环,本次文件读取完成。 * */ while ((hasRead = bis.read(b)) != -1) { bos.write(b,0,hasRead); //先判断,再读取数据,否则会出错。 record += (long)hasRead; if (len-record < 1024) { long tail = len-record; bis.read(new byte[(int)tail]); bos.write(b, 0, (int)tail); break; } } } catch (IOException e) { e.printStackTrace(); } }); } } //获取信息文件信息(图片的长度) //抑制一下 unchecked 警告 @SuppressWarnings("unchecked") private static List getFileInfo(File file) throws NumberFormatException, IOException, ClassNotFoundException{ try ( ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file))){ return (List) ois.readObject(); //强制类型转换一下,读取出来的数据都是 Object 类型 } } //初始化 拆分文件位置 private static boolean initPath(File file) { return file.mkdirs(); } }
注意:分隔还原图片时,图片的后缀名部分代码为:
使用Java封装属性后,使用很方便了。
String filename = System.currentTimeMillis()+UUID.randomUUID().toString()+fileInfo.getSuffix();
反序列化读取集合:
这里我抑制了一个强制类型转换的警告。
通过序列化,可以发现代码量大大减少了,直接就是集合,使用非常方便。
//抑制一下 unchecked 警告 @SuppressWarnings("unchecked") private static List getFileInfo(File file) throws NumberFormatException, IOException, ClassNotFoundException{ try ( ObjectInputStream ois = new ObjectInputStream(new FileInputStream(file))){ return (List) ois.readObject(); //强制类型转换一下,读取出来的数据都是 Object 类型 } }
测试代码
package dragon; import java.io.IOException; public class Client { public static void main(String[] args) throws IOException, NumberFormatException, ClassNotFoundException { //如果需要合并图片,就使用第一条语句,注释第二条, //如果需要拆分图片,就使用第二条语句,注释第一条 EnhanceImageMerge.imageMerge(); // EnhanceImageSeparate.imageSeparate(); } }
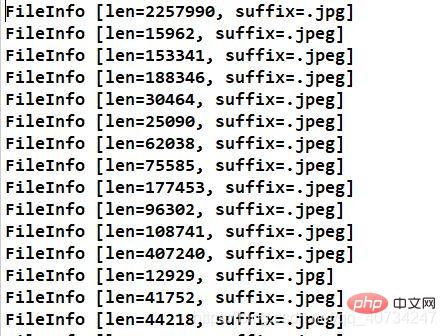
改进后代码运行结果 执行合并方法时,打印的图片对象模型的信息
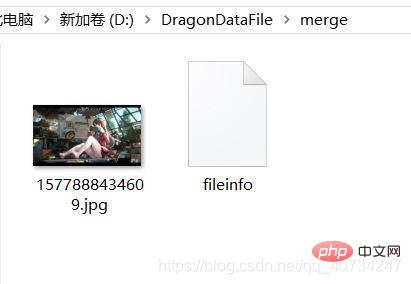
合并后的效果
注意观察右边的 fileinfo 文件,因为是二进制数据,我就没有给它加上文件后缀名,加上了也是无法直接阅读的,里面存储的是图片对象模型集合的序列化信息。
执行分隔操作后的效果
控制台输出图片信息,可以看到每个图片的后缀名都恢复了,注意看最后一个,有一个文本文件!哈哈!这个图片后面似乎可以添加任何数据,也许视频也是可以的,只是我没有测试,这个应该和图片的存储格式、显示方式有关。
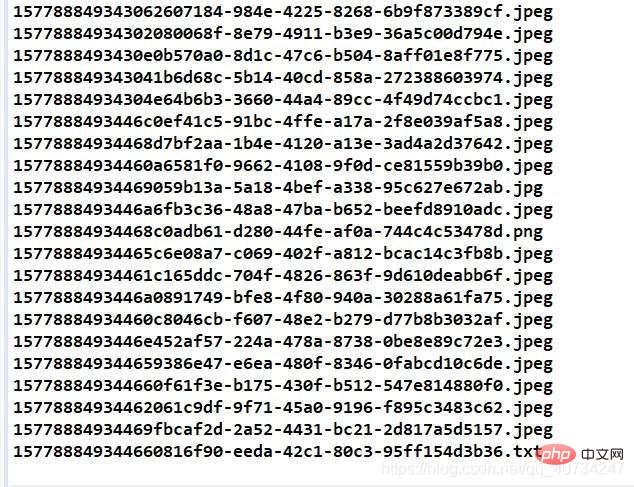
注意,下面恢复的时候,确实是有一个文本文件,并且是完好的,可以阅读的。

合并后被分隔出的文本文件的信息
The above is the detailed content of How to solve the problem of merging java files and modifying md5 value. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



