


In the view of many scholars, embodied intelligence is a very promising direction towards AGI, and the success of ChatGPT is inseparable from the RLHF technology based on reinforcement learning. DeepMind vs. OpenAI, who can achieve AGI first? The answer seems to have not been revealed yet.
We know that creating general embodied intelligence (i.e., agents that act in the physical world with an agility and dexterity and understand like animals or humans) is an important step for AI researchers and one of the long-term goals of roboticists. Time-wise, the creation of intelligent embodied agents with complex locomotion capabilities goes back many years, both in simulations and in the real world.
The pace of progress has accelerated significantly in recent years, with learning-based methods playing a major role. For example, deep reinforcement learning has been shown to be able to solve complex motion control problems of simulated characters, including complex, perception-driven whole-body control or multi-agent behavior. At the same time, deep reinforcement learning is increasingly used in physical robots. In particular, widely used high-quality quadruped robots have become demonstration targets for learning to generate a range of robust locomotor behaviors.
However, movement in static environments is only one part of the many ways that animals and humans deploy their bodies to interact with the world, and this locomotion modality has been used in much work studying whole-body control and movement manipulation. has been verified, especially for quadruped robots. Examples of related movements include climbing, soccer skills such as dribbling or catching a ball, and simple maneuvers using the legs.
Among them, for football, it shows many characteristics of human sensorimotor intelligence. The complexity of football requires a variety of highly agile and dynamic movements, including running, turning, avoiding, kicking, passing, falling and getting up, etc. These actions need to be combined in a variety of ways. Players need to predict the ball, teammates and opposing players, and adjust their actions according to the game environment. This diversity of challenges has been recognized in the robotics and AI communities, and RoboCup was born.
However, it should be noted that the agility, flexibility and quick response required to play football well, as well as the smooth transition between these elements, are very challenging and time-consuming for manual design of robots. Recently, a new paper from DeepMind (now merged with the Google Brain team to form Google DeepMind) explores the use of deep reinforcement learning to learn agile football skills for a bipedal robot.

Paper address: https://arxiv.org/pdf/2304.13653 .pdf
Project homepage: https://sites.google.com/view/op3-soccer
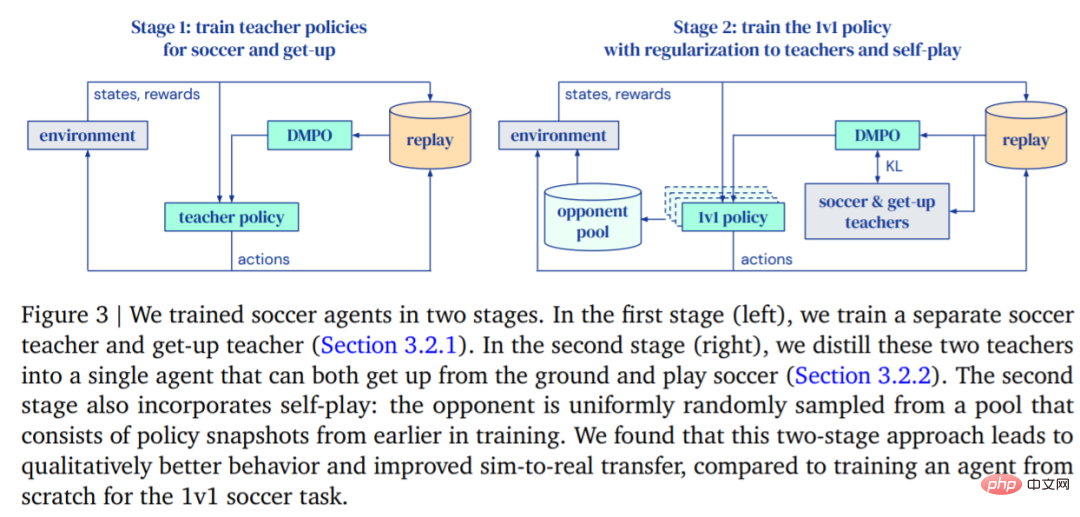
In this paper, researchers study full-body control and object interaction of small humanoid robots in dynamic multi-agent environments. They considered a subset of the overall football problem, training a low-cost miniature humanoid robot with 20 controllable joints to play a 1 v1 football game and observing proprioception and game state characteristics. With the built-in controller, the robot moves slowly and awkwardly. However, researchers used deep reinforcement learning to synthesize dynamic and agile context-adaptive motor skills (such as walking, running, turning, and kicking a ball and getting back up after falling) that the agent combined in a natural and smooth way into complex long-term behaviors.
In the experiment, the agent learned to predict the movement of the ball, position it, block attacks, and use bounced balls. Agents achieve these behaviors in a multi-agent environment thanks to a combination of skill reuse, end-to-end training, and simple rewards. The researchers trained agents in simulation and transferred them to physical robots, demonstrating that simulation-to-real transfer is possible even for low-cost robots.
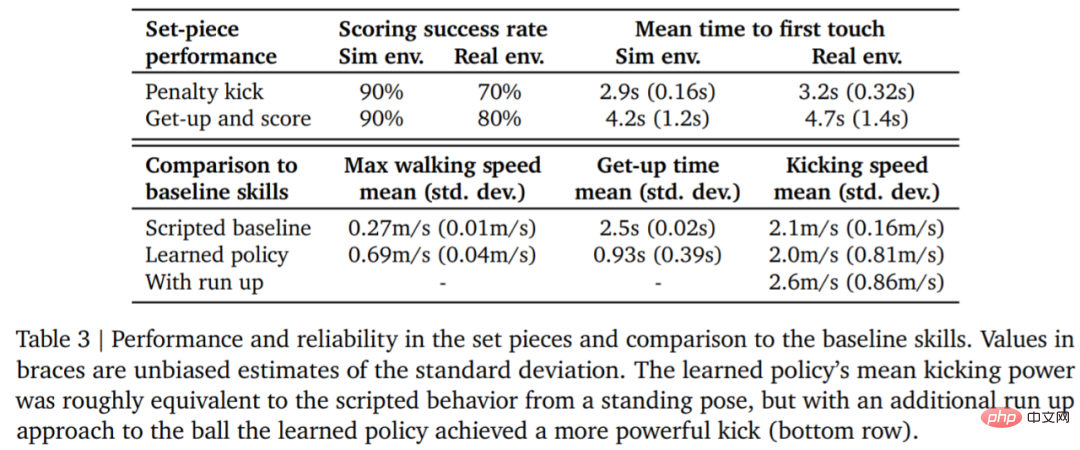
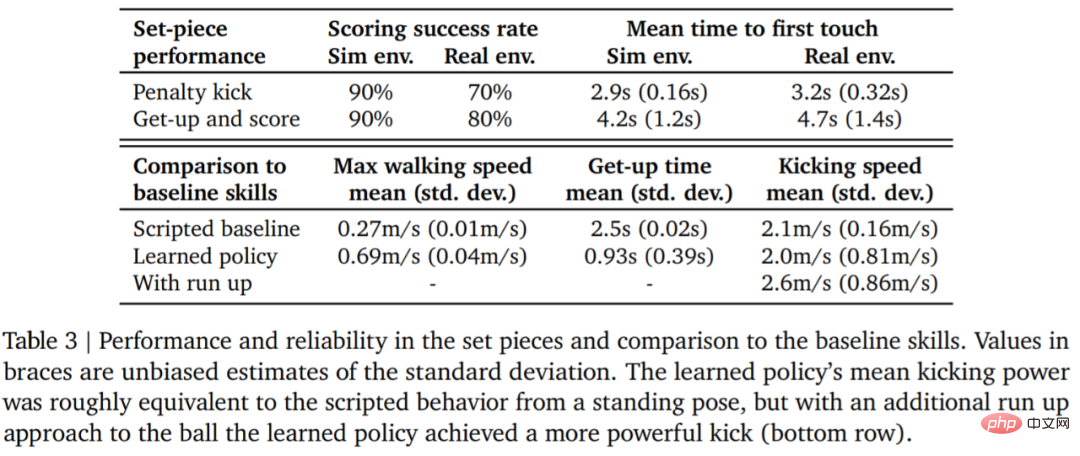
Let the data speak for itself. The robot’s walking speed increased by 156%, the time to get up was reduced by 63%, and the kicking speed was also increased by 24% compared to the baseline.
Before going into the technical interpretation, let’s take a look at some of the highlights of robots in 1v1 football matches. For example, shooting:


## Penalty kick:

Turn, dribble and kick, all in one go

 Experimental settings
Experimental settings
In terms of environment, DeepMind first simulates and trains the agent in a customized football environment, and then migrates the strategy to the corresponding real environment, as shown in Figure 1. The environment consisted of a football pitch 5 m long and 4 m wide, with two goals, each with an opening width of 0.8 m. In both simulated and real environments, the court is bounded by ramps to keep the ball in bounds. The real court is covered with rubber tiles to reduce the risk of damaging the robot from a fall and to increase friction on the ground.
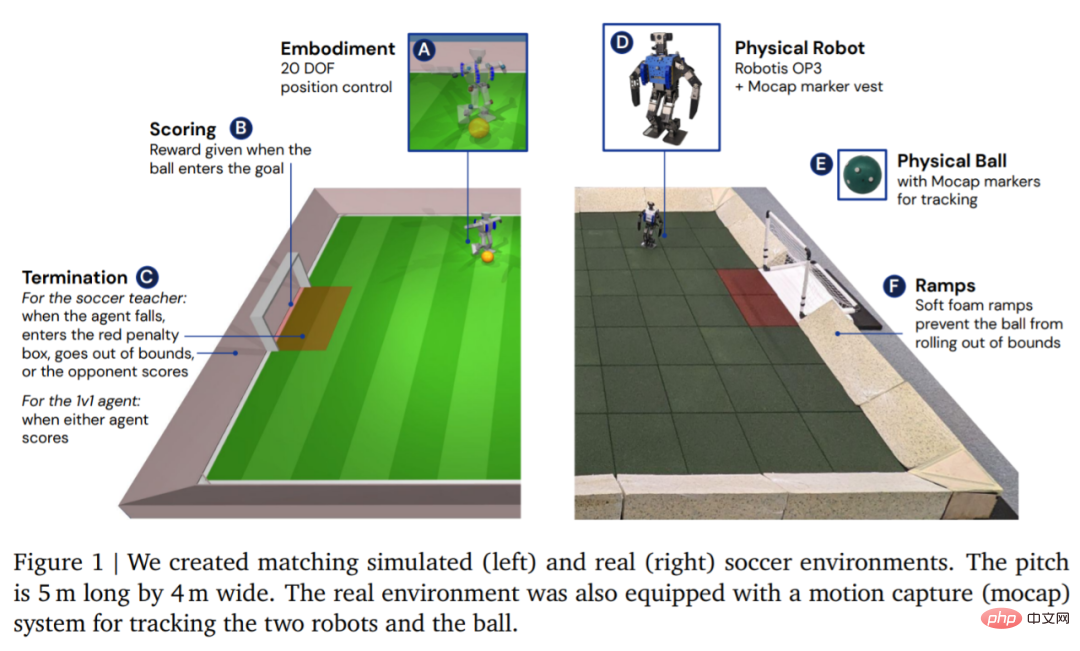

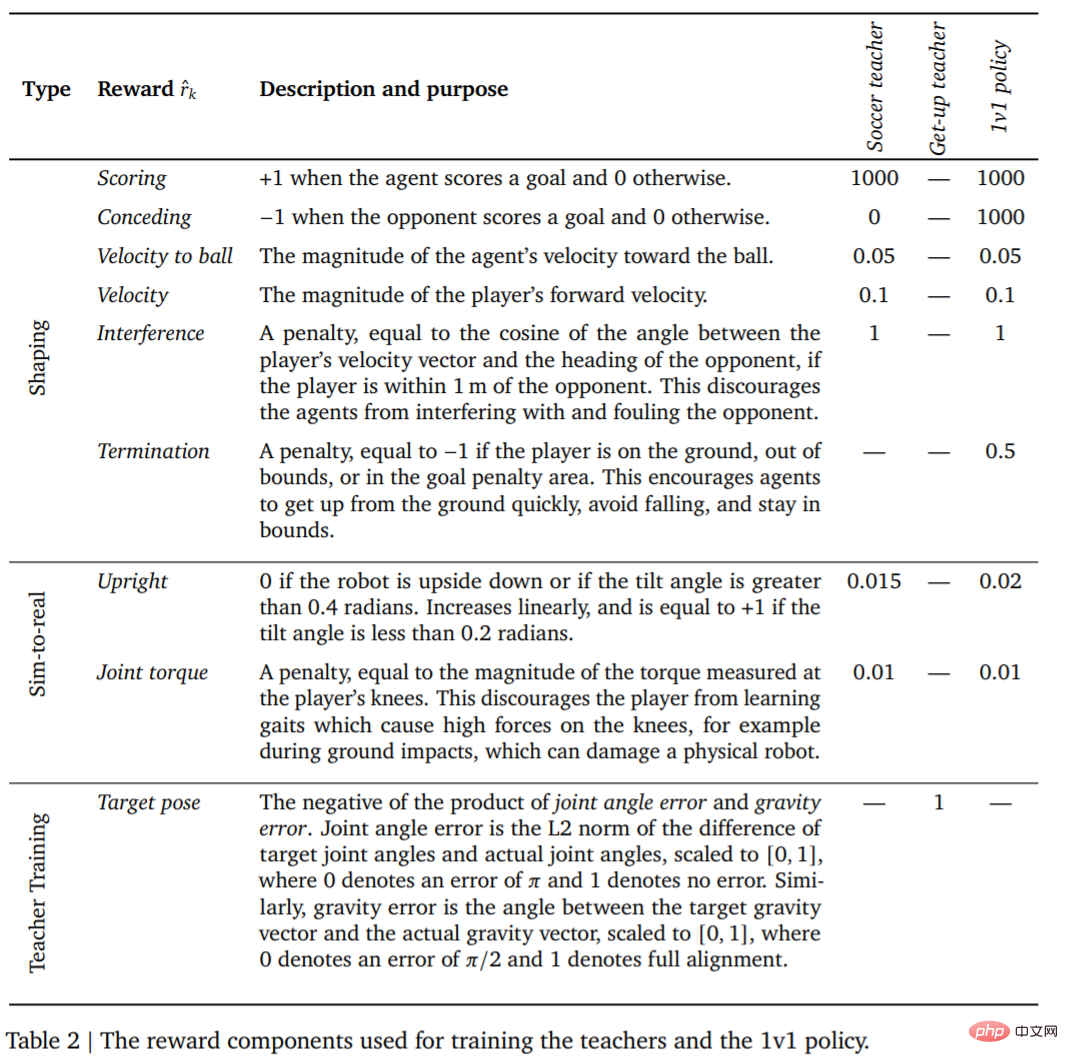
After the agent is trained, the next step is to transfer the trained kicking strategy to the real robot with zero samples. In order to improve the success rate of zero-shot transfer, DeepMind reduces the gap between simulated agents and real robots through simple system identification, improves the robustness of the strategy through domain randomization and perturbation during training, and includes shaping the reward strategy to obtain different results. Behavior that is too likely to harm the robot. 1v1 Competition: The soccer agent can handle a variety of emergent behaviors, including flexible motor skills such as getting up from the ground, quickly recovering from falls, and running and turn around. During the game, the agent transitions between all these skills in a fluid manner. Experiment

Table 3 below shows the quantitative analysis results. It can be seen from the results that the reinforcement learning strategy performs better than specialized artificially designed skills, with the agent walking 156% faster and taking 63% less time to get up.
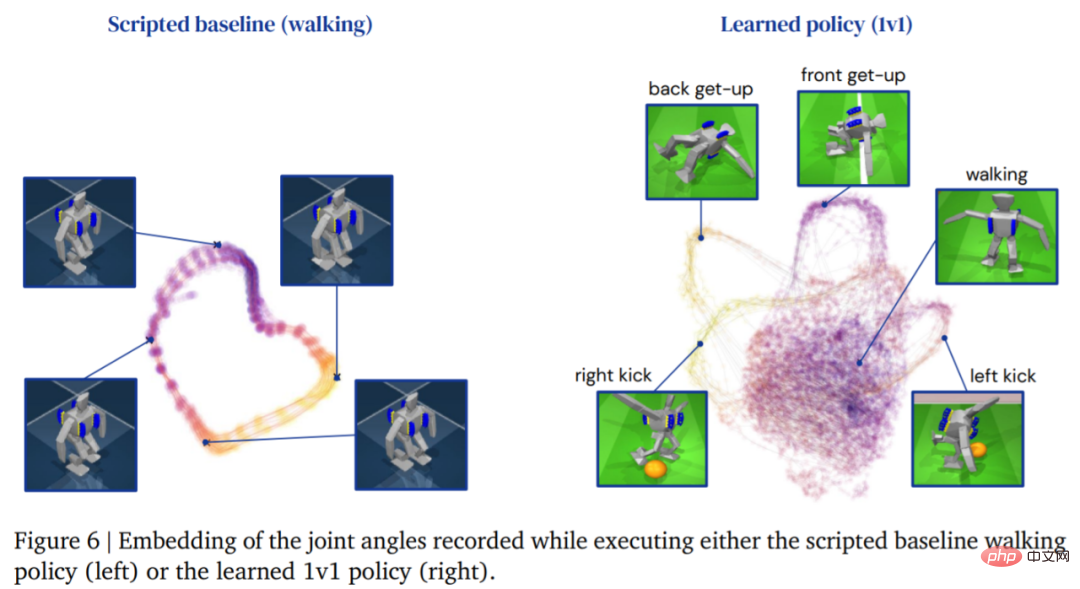
The following figure shows the walking trajectory of the agent. In contrast, the trajectory structure of the agent generated by the learning strategy Richer:
#To evaluate the reliability of the learning strategy, DeepMind designed penalty kicks and jumping shot set pieces, and Implemented in simulated and real environments. The initial configuration is shown in Figure 7.
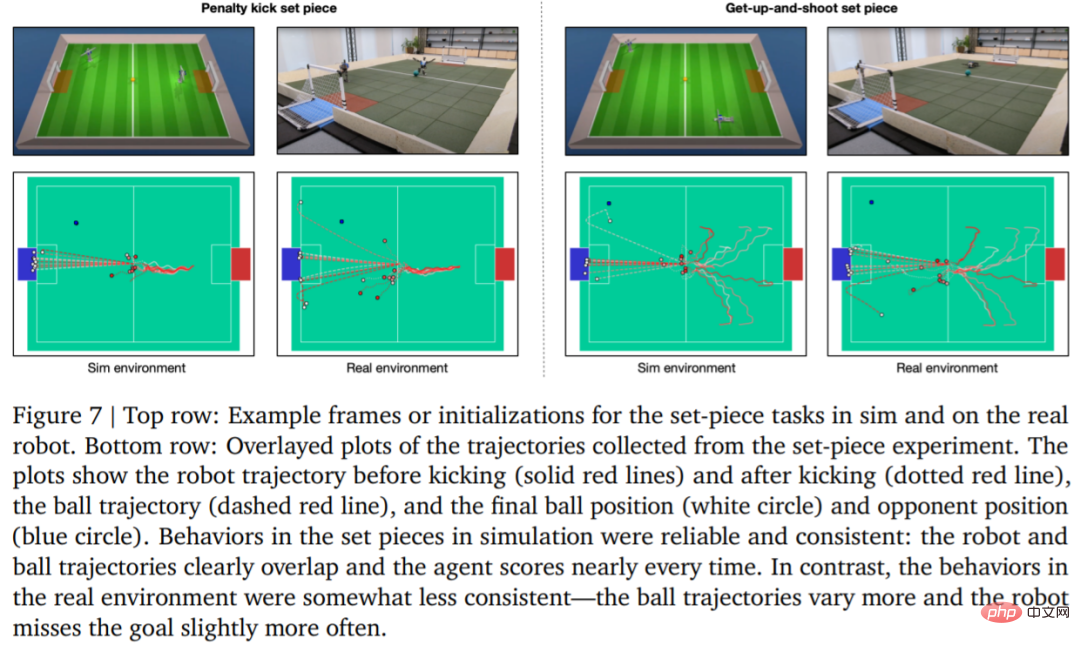
#In the real environment, the robot scored 7 out of 10 times (70%) in the penalty kick task. Hit 8 out of 10 times (80%) on launch missions. In the simulation experiment, the agent's scores in these two tasks were more consistent, which shows that the agent's training strategy is transferred to the real environment (including real robots, balls, floor surfaces, etc.), the performance is slightly degraded, and the behavioral differences are has increased, but the robot is still able to reliably get up, kick the ball, and score. The results are shown in Figure 7 and Table 3.
The above is the detailed content of Why is DeepMind absent from the GPT feast? It turned out that I was teaching a little robot to play football.. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



