


What if artificial intelligence could read your imagination and turn the images in your mind into reality?

Although this sounds a bit cyberpunk. But a recently published paper has caused a stir in the AI circle.
This paper found that they used the recently very popular Stable Diffusion to reconstruct high-resolution brain activity High-efficiency, high-precision images. The authors wrote that unlike previous studies, they did not need to train or fine-tune an artificial intelligence model to create these images.

How did they do it?
In this study, the authors used Stable Diffusion to reconstruct images of human brain activity obtained through functional magnetic resonance imaging (fMRI). The author also stated that it is also helpful to understand the mechanism of the latent diffusion model by studying different components of brain-related functions (such as the latent vector of image Z, etc.).
This paper has also been accepted by CVPR 2023.
The main contributions of this study include:
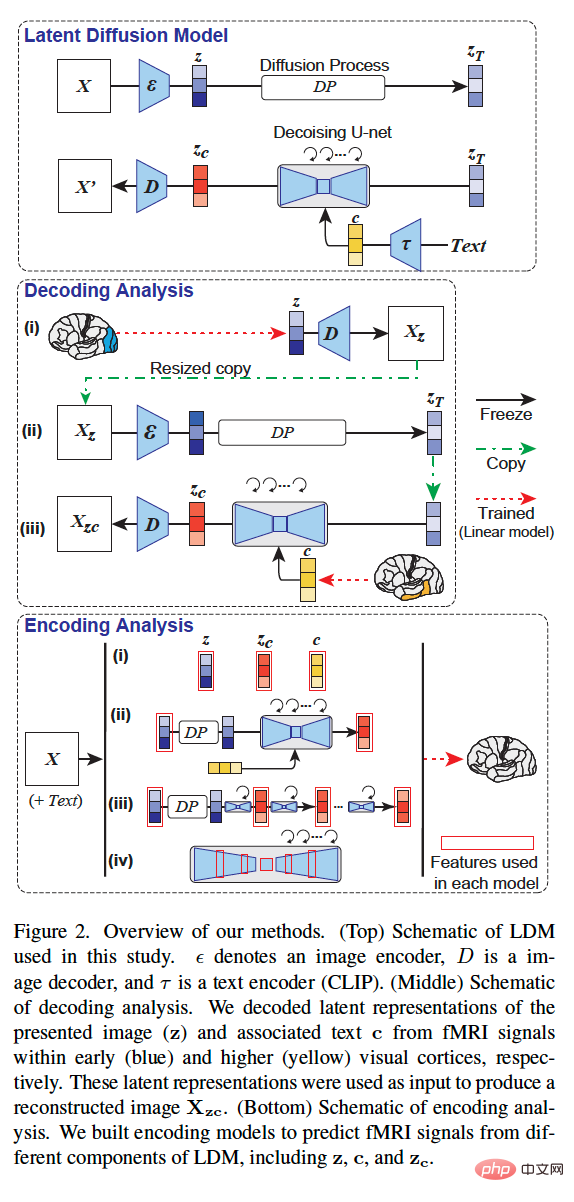
The overall methodology of this study is shown in Figure 2 below. Figure 2 (top) is a schematic diagram of the LDM used in this study, where ε represents the image encoder, D represents the image decoder, and τ represents the text encoder (CLIP).
Figure 2 (middle) is a schematic diagram of the decoding analysis of this study. We decoded the underlying representation of the presented image (z) and associated text c from fMRI signals within early (blue) and advanced (yellow) visual cortex, respectively. These latent representations are used as input to generate the reconstructed image X_zc.
Figure 2 (bottom) is a schematic diagram of the coding analysis of this study. We constructed encoding models to predict fMRI signals from different components of LDM, including z, c, and z_c.
I won’t introduce too much about Stable Diffusion here, I believe many people are familiar with it.
ResultsLet’s take a look at the visual reconstruction results of this study.
Decoding
Figure 3 below shows the visual reconstruction results of a subject (subj01). We generated five images for each test image and selected the image with the highest PSM. On the one hand, the image reconstructed using only z is visually consistent with the original image but fails to capture its semantic content. On the other hand, images reconstructed with only c produce images with high semantic fidelity but are visually inconsistent. Finally, using z_c reconstructed images can produce high-resolution images with high semantic fidelity.

Figure 4 shows the reconstruction of the same image by all testers (all images were generated with z_c) . Overall, the reconstruction quality across testers was stable and accurate.

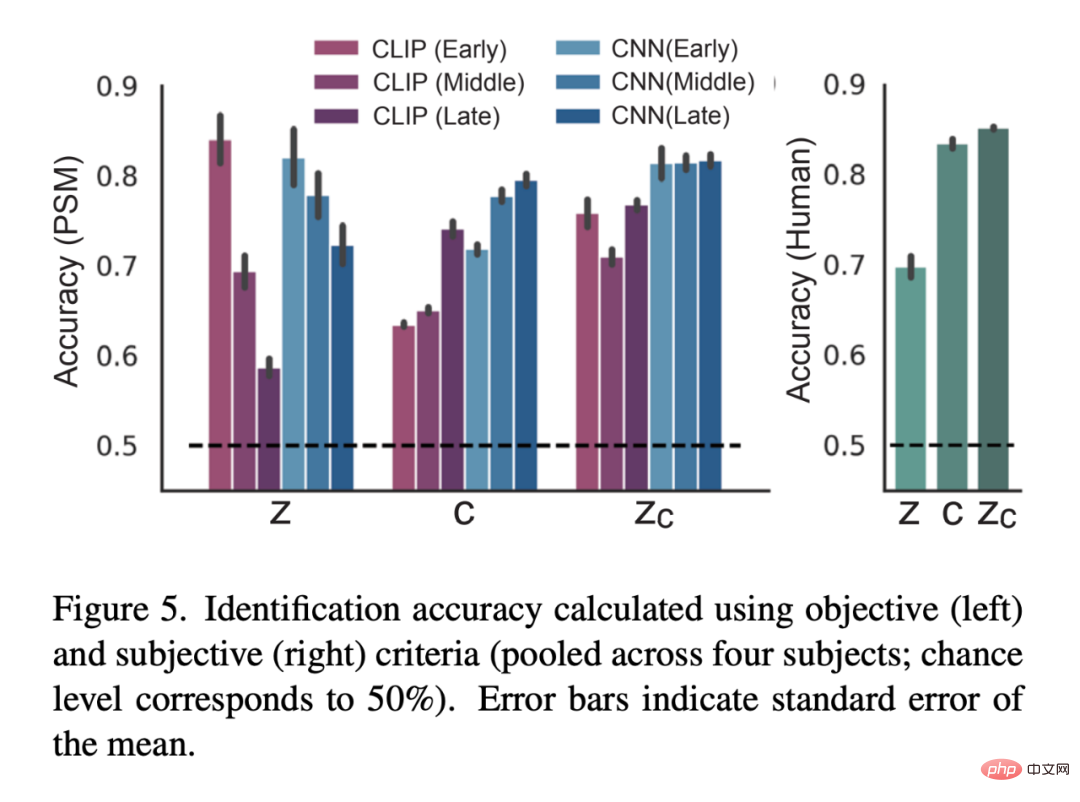
Figure 5 is the result of the quantitative evaluation:
Coding model
## Figure 6 shows the coding model pair related to LDM Prediction accuracy of three latent images: z, the latent image of the original image; c, the latent image of the image text annotation; and z_c, the noisy latent image representation of z after a cross-attention back-diffusion process with c.
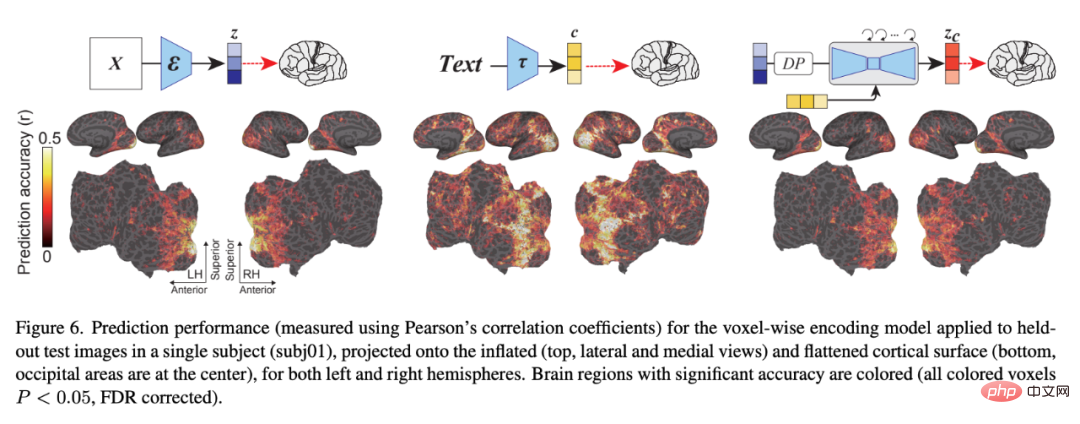
Figure 7 shows that z predicts voxel activity throughout the cortex better than z_c when a small amount of noise is added. Interestingly, z_c predicts voxel activity in high visual cortex better than z when increasing the noise level, indicating that the semantic content of the image is gradually emphasized.

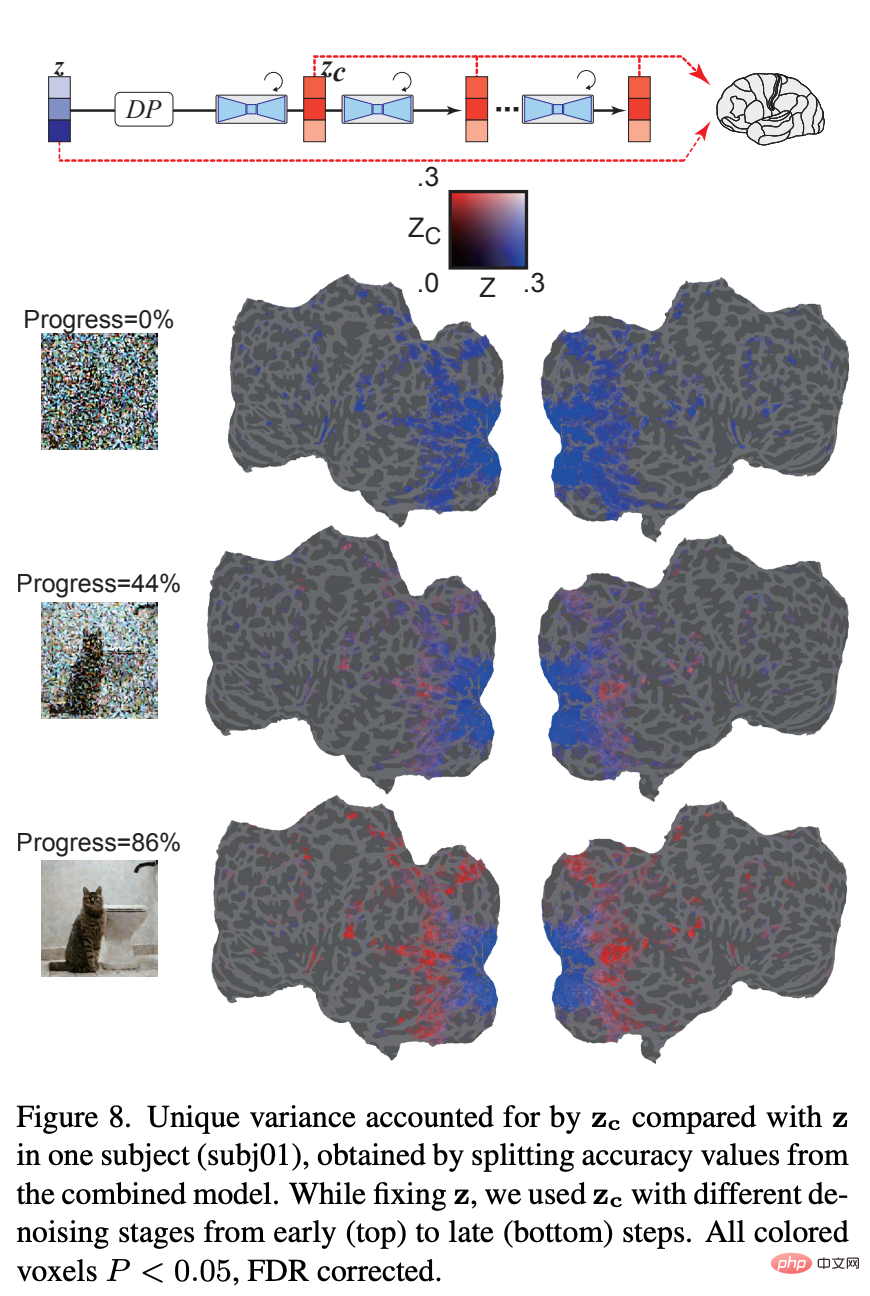
How does the underlying representation of added noise change during the iterative denoising process? Figure 8 shows that in the early stages of the denoising process, the z-signal dominates the prediction of the fMRI signal. At the intermediate stage of the denoising process, z_c predicts activity within high visual cortex much better than z, indicating that most of the semantic content emerges at this stage. The results show how LDM refines and generates images from noise.
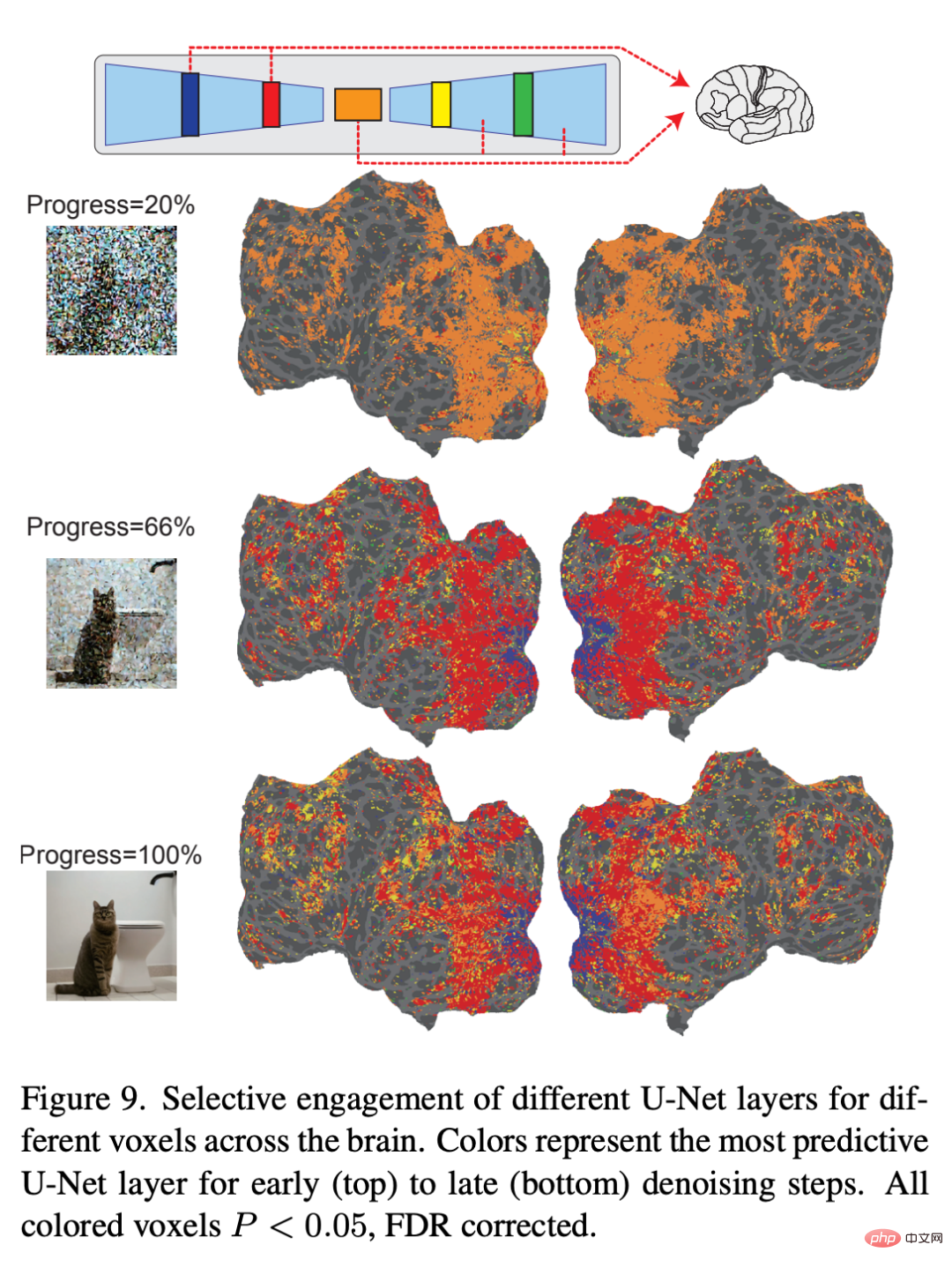
Finally, the researchers explored what information each layer of U-Net is processing. Figure 9 shows the results of different steps of the denoising process (early, mid, late) and the encoding model of different layers of U-Net. In the early stages of the denoising process, U-Net's bottleneck layer (orange) yields the highest prediction performance across the entire cortex. However, as denoising proceeds, the early layers of U-Net (blue) predict activity within early visual cortex, while the bottleneck layers shift to superior predictive power for higher visual cortex.
For more research details, please view the original paper.
The above is the detailed content of 'Using Stable Diffusion technology to reproduce images, related research was accepted by the CVPR conference'. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



