


As one of the three elements of artificial intelligence, data plays an important role.
But have you ever thought about: What if one day, all the data in the world is used up?
Actually, the person who asked this question definitely has no mental problem, because this day may be coming soon! ! !
Recently, researcher Pablo Villalobos and others published an article titled "Will We Run Out of Data?" The paper "Analysis of the Limitations of Dataset Scaling in Machine Learning" was published on arXiv.
Based on their previous analysis of data set size trends, they predicted the growth of data set sizes in the language and vision fields and estimated the development trend of the total stock of available unlabeled data in the next few decades. .
Their research shows that high-quality language data will be exhausted as early as 2026! The pace of machine learning development will also slow down as a result. It's really not optimistic.
The research team of this paper consists of 11 researchers and 3 consultants, with members from all over the world, dedicated to shrinking AI Gap between technology development and AI strategy, and provide advice to key decision-makers on AI safety.

Chinchilla is a new predictive computing optimization model proposed by researchers at DeepMind.
In fact, during previous experiments on Chinchilla, a researcher once suggested that "training data will soon become a bottleneck in expanding large language models."
So they analyzed the growth in the size of machine learning datasets for natural language processing and computer vision, and used two methods to extrapolate: using historical growth rates, and for the future The predicted computational budget is estimated to calculate the optimal data set size.
Prior to this, they have been collecting data on machine learning input trends, including some training data, etc., and also by estimating the total stock of unlabeled data available on the Internet in the next few decades. , to investigate data usage growth.
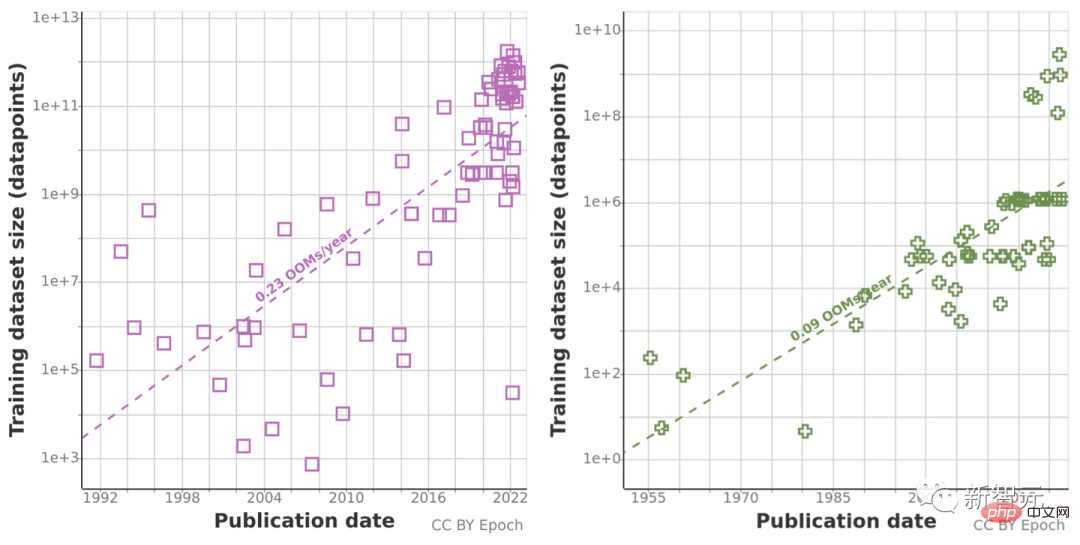
Because historical forecast trends may be "misleading" by the abnormal growth in computing volume over the past decade, the research team also used Chinchilla scaling law to Estimate the size of the data set in the next few years to improve the accuracy of the calculation results.
Ultimately, the researchers used a series of probabilistic models to estimate the total inventory of English language and image data in the next few years and compared the predictions of training data set size and total data inventory. The results are as follows As shown in the figure.
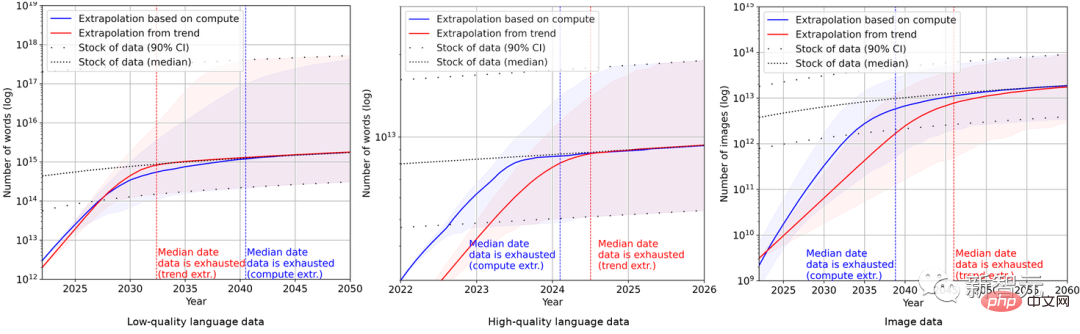
This shows that the growth rate of the data set will be much faster than the data storage.
Therefore, if the current trend continues, it will be inevitable that the data stock will be used up. The table below shows the median number of years to exhaustion at each intersection on the forecast curve.
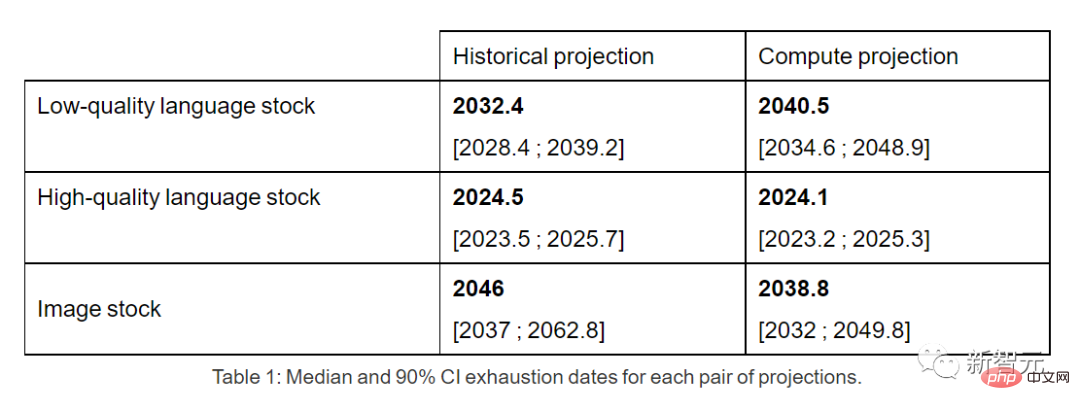
High-quality language data inventories may be exhausted by 2026 at the earliest.
In contrast, the situation of low-quality language data and image data is slightly better: the former will be used up between 2030 and 2050, and the latter will be used up between 2030 and 2060. between.
At the end of the paper, the research team concluded: If data efficiency is not significantly improved or new data sources are available, the growth trend of machine learning models that currently rely on the ever-expanding huge data sets is likely to slow down. slow.
However, in the comment area of this article, most netizens think that the author is unfounded.
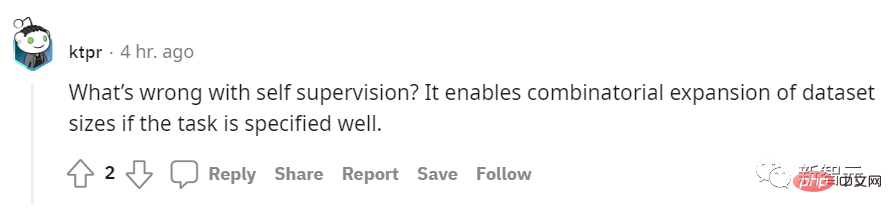
On Reddit, a netizen named ktpr said:
"What's wrong with self-supervised learning? If the tasks are well specified , it can even be combined to expand the data set size."
A netizen named lostmsn was even more unkind. He said bluntly:
"You don't even understand Efficient Zero? I think the author has seriously lost touch with the times."
Efficient Zero is a reinforcement learning algorithm that can efficiently sample, proposed by Dr. Gao Yang of Tsinghua University.
In the case of limited data volume, Efficient Zero has solved the performance problem of reinforcement learning to a certain extent, and has been verified on the Atari Game, a universal test benchmark for algorithms.
On the blog of the author team of this paper, even they themselves admitted:
"All of our conclusions are based on the unrealistic assumption that current trends in machine learning data usage and production will continue without significant improvements in data efficiency."
"A more reliable model should take into account the improvement of machine learning data efficiency, the use of synthetic data, and other algorithmic and economic factors."
"So in practical terms, this This analysis has serious limitations. Model uncertainty is very high."
"However, overall, we still believe that by 2040, due to the lack of training data, machine learning models There is about a 20% chance that the expansion will slow down significantly."
The above is the detailed content of The global stock of high-quality language data is in short supply and cannot be ignored. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



