


In machine learning, features refer to measurable and quantifiable attributes or characteristics of an object, person, or phenomenon. Features can be roughly divided into two categories: sparse features and dense features.
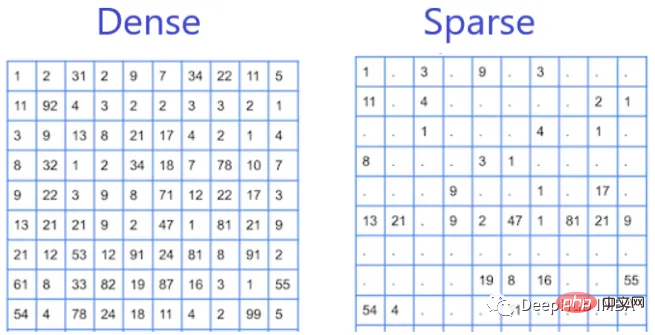
Sparse features are those features that appear discontinuously in the data set, and most of their values are zero. Examples of sparse features include the presence or absence of specific words in a text document or the occurrence of specific items in a transaction dataset. They are called sparse features because they have few non-zero values in the data set and most of the values are zero.
Sparse features are common in natural language processing (NLP) and recommender systems, where data are often represented as sparse matrices. Working with sparse features can be more challenging because they often have many zero or near-zero values, which makes them computationally expensive and slows down the training process. Sparse features are effective when the feature space is large and most features are irrelevant or redundant. Sparse features in these cases help reduce the dimensionality of the data, allowing for faster and more efficient training and inference.
Dense features are those features that appear frequently or regularly in the data set, and most of the values are non-zero. Examples of dense features include age, gender, and income of individuals in a demographic data set. They are called dense features because they have many non-zero values in the data set.
Dense features are common in image and speech recognition, where data are often represented as dense vectors. Dense features are generally easier to handle because they have a higher density of non-zero values, and most machine learning algorithms are designed to handle dense feature vectors. Dense features may be more suitable when the feature space is relatively small and each feature is important to the task at hand.
The difference between sparse features and dense features lies in the distribution of their values in the data set. Sparse features have few non-zero values, while dense features have many non-zero values. This difference in distribution has implications for machine learning algorithms because algorithms may perform differently on sparse features compared to dense features.
Now that we know the feature types of a given dataset, which algorithm should we use if the dataset contains sparse features or if the dataset contains dense features?
Some algorithms are better suited for sparse data, while other algorithms are better suited for dense data.
But it should be noted that the choice of algorithm depends not only on the sparsity or density of the data, but also on other factors such as the size of the data set, the type of features, the complexity of the problem, etc. It must be considered Try different algorithms and compare their performance on a given problem.
The above is the detailed content of Sparse features and dense features. For more information, please follow other related articles on the PHP Chinese website!
 Page replacement algorithm
Page replacement algorithm Top ten currency trading software apps ranking list
Top ten currency trading software apps ranking list How to resize pictures in ps
How to resize pictures in ps What does the rm-rf command mean in linux?
What does the rm-rf command mean in linux? How to modify the registry
How to modify the registry How to change 3dmax to Chinese
How to change 3dmax to Chinese How to solve the WerFault.exe application error
How to solve the WerFault.exe application error What to do if the remote desktop cannot connect
What to do if the remote desktop cannot connect




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



