


We all know that String is immutable in Java. If you change its content, it will generate a new string. If we want to use part of the data in the string, we can use the substring method.
The following is the source code of String in Java11.
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = length() - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
if (beginIndex == 0) {
return this;
}
return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen)
: StringUTF16.newString(value, beginIndex, subLen);
}
public static String newString(byte[] val, int index, int len) {
if (String.COMPACT_STRINGS) {
byte[] buf = compress(val, index, len);
if (buf != null) {
return new String(buf, LATIN1);
}
}
int last = index + len;
return new String(Arrays.copyOfRange(val, index << 1, last << 1), UTF16);
}As shown in the above code, when we need a substring, substring generates a new string, which is constructed through the Arrays.copyOfRange function of the constructor.
This function has no problem after Java7, but in Java6, it has the risk of memory leak. We can study this case to see the problems that may arise from the reuse of large objects. The following is the code in Java6:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ?
this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}As you can see, when creating a substring, it does not just copy the required object, but references the entire value. If the original string is relatively large, the memory will not be released even if it is no longer used.
For example, the content of an article may be several megabytes. We only need the summary information and have to maintain the entire large object.
Some interviewers who have worked for a long time have the impression that substring is still in JDK6, but in fact, Java has already modified this bug. If you encounter this question during the interview, just to be on the safe side, you can answer the question about the improvement process.
What this means for us is: if you create a relatively large object and generate some other information based on this object, at this time, you must remember to remove the reference relationship with this large object.
Object expansion is a common phenomenon in Java, such as StringBuilder, StringBuffer, HashMap, ArrayList, etc. In summary, the data in Java collections, including List, Set, Queue, Map, etc., are uncontrollable. When the capacity is insufficient, there will be expansion operations. The expansion operations require data to be reorganized, so they are not thread-safe.
Let’s first look at the expansion code of StringBuilder:
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}When the capacity is not enough, the memory will be doubled and the source data will be copied using Arrays.copyOf.
The following is the expansion code of HashMap. After expansion, the size is also doubled. Its expansion action is much more complicated. In addition to the impact of the load factor, it also needs to re-hash the original data. Since the native Arrays.copy method cannot be used, the speed will be very slow.
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}You can check the code of List by yourself. It is also blocking. The expansion strategy is 1.5 times the original length.
Since collections are used very frequently in code, if you know the upper limit of specific data items, you may wish to set a reasonable initialization size. For example, HashMap requires 1024 elements and requires 7 expansions, which will affect the performance of the application. This question will come up frequently in interviews, and you need to understand the impact of these expansion operations on performance.
But please note that for a collection like HashMap that has a load factor (0.75), the initial size = the number required/load factor 1. If you are not very clear about the underlying structure, you may as well keep the default.
Next, I will explain the optimization at the application level starting from the structural dimension and time dimension of the data.
Let me share with you a practical case: We have a business system with very high concurrency and need to frequently use the user's basic data.
As shown in the figure below, since the user's basic information is stored in another service, every time the user's basic information is used, a network interaction is required. What is even more unacceptable is that even if only the gender attribute of the user is needed, all user information needs to be queried and pulled.
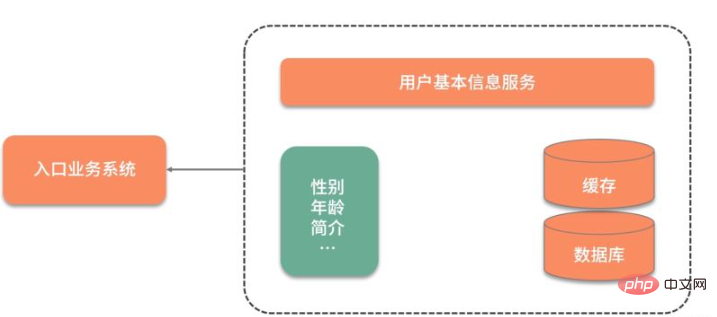
In order to speed up the data query, the data was initially cached and put into Redis. The query performance has been greatly improved, but it still needs to be queried every time. A lot of redundant data.
The original redis key is designed like this:
type: string
key: user_${userid}
value: jsonThere are two problems with this design:
To query the value of a certain field, you need to query all json data Come out and parse it by yourself;
Updating the value of one of the fields requires updating the entire json string, which is expensive.
For this kind of large-grained json information, it can be optimized in a scattered way, so that every update and query has a focused target.
Next, the data in Redis is designed as follows, using hash structure instead of json structure:
type: hash
key: user_${userid}
value: {sex:f, id:1223, age:23}In this way, we can use the hget command or hmget command to get the desired data to speed up the flow of information.
In addition to the above operations, can it be further optimized? For example, the user's gender data is frequently used in our system to distribute some gifts, recommend some friends of the opposite sex, regularly cycle users to perform some cleaning actions, etc.; or, store some user status information, such as whether they are online and whether they have checked in. , whether information has been sent recently, etc., so as to count active users, etc. Then the operation of the two values of yes and no can be compressed using the Bitmap structure.
这里还有个高频面试问题,那就是 Java 的 Boolean 占用的是多少位?
在 Java 虚拟机规范里,描述是:将 Boolean 类型映射成的是 1 和 0 两个数字,它占用的空间是和 int 相同的 32 位。即使有的虚拟机实现把 Boolean 映射到了 byte 类型上,它所占用的空间,对于大量的、有规律的 Boolean 值来说,也是太大了。
如代码所示,通过判断 int 中的每一位,它可以保存 32 个 Boolean 值!
int a= 0b0001_0001_1111_1101_1001_0001_1111_1101;
Bitmap 就是使用 Bit 进行记录的数据结构,里面存放的数据不是 0 就是 1。还记得我们在之前 《分布式缓存系统必须要解决的四大问题》中提到的缓存穿透吗?就可以使用 Bitmap 避免,Java 中的相关结构类,就是 java.util.BitSet,BitSet 底层是使用 long 数组实现的,所以它的最小容量是 64。
10 亿的 Boolean 值,只需要 128MB 的内存,下面既是一个占用了 256MB 的用户性别的判断逻辑,可以涵盖长度为 10 亿的 ID。
static BitSet missSet = new BitSet(010_000_000_000);
static BitSet sexSet = new BitSet(010_000_000_000);
String getSex(int userId) {
boolean notMiss = missSet.get(userId);
if (!notMiss) {
//lazy fetch
String lazySex = dao.getSex(userId);
missSet.set(userId, true);
sexSet.set(userId, "female".equals(lazySex));
}
return sexSet.get(userId) ? "female" : "male";
}这些数据,放在堆内内存中,还是过大了。幸运的是,Redis 也支持 Bitmap 结构,如果内存有压力,我们可以把这个结构放到 Redis 中,判断逻辑也是类似的。
再插一道面试算法题:给出一个 1GB 内存的机器,提供 60亿 int 数据,如何快速判断有哪些数据是重复的?
大家可以类比思考一下。Bitmap 是一个比较底层的结构,在它之上还有一个叫作布隆过滤器的结构(Bloom Filter),布隆过滤器可以判断一个值不存在,或者可能存在。
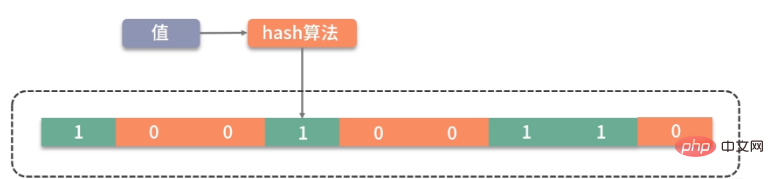
如图,它相比较 Bitmap,它多了一层 hash 算法。既然是 hash 算法,就会有冲突,所以有可能有多个值落在同一个 bit 上。它不像 HashMap一样,使用链表或者红黑树来处理冲突,而是直接将这个hash槽重复使用。从这个特性我们能够看出,布隆过滤器能够明确表示一个值不在集合中,但无法判断一个值确切的在集合中。
Guava 中有一个 BloomFilter 的类,可以方便地实现相关功能。
上面这种优化方式,本质上也是把大对象变成小对象的方式,在软件设计中有很多类似的思路。比如像一篇新发布的文章,频繁用到的是摘要数据,就不需要把整个文章内容都查询出来;用户的 feed 信息,也只需要保证可见信息的速度,而把完整信息存放在速度较慢的大型存储里。
数据除了横向的结构纬度,还有一个纵向的时间维度,对时间维度的优化,最有效的方式就是冷热分离。
所谓热数据,就是靠近用户的,被频繁使用的数据;而冷数据是那些访问频率非常低,年代非常久远的数据。
同一句复杂的 SQL,运行在几千万的数据表上,和运行在几百万的数据表上,前者的效果肯定是很差的。所以,虽然你的系统刚开始上线时速度很快,但随着时间的推移,数据量的增加,就会渐渐变得很慢。
冷热分离是把数据分成两份,如下图,一般都会保持一份全量数据,用来做一些耗时的统计操作。
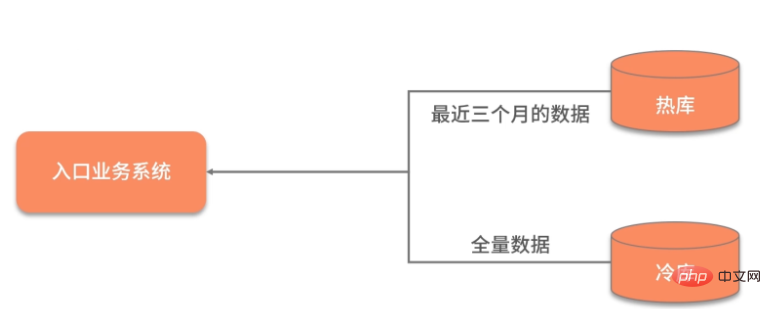
由于冷热分离在工作中经常遇到,所以面试官会频繁问到数据冷热分离的方案。下面简单介绍三种:
把对冷热库的插入、更新、删除操作,全部放在一个统一的事务里面。由于热库(比如 MySQL)和冷库(比如 Hbase)的类型不同,这个事务大概率会是分布式事务。在项目初期,这种方式是可行的,但如果是改造一些遗留系统,分布式事务基本上是改不动的,我通常会把这种方案直接废弃掉。
通过 MQ 的发布订阅功能,在进行数据操作的时候,先不落库,而是发送到 MQ 中。单独启动消费进程,将 MQ 中的数据分别落到冷库、热库中。使用这种方式改造的业务,逻辑非常清晰,结构也比较优雅。像订单这种结构比较清晰、对顺序性要求较低的系统,就可以采用 MQ 分发的方式。但如果你的数据库实体量非常大,用这种方式就要考虑程序的复杂性了。
针对 MySQL,就可以采用 Binlog 的方式进行同步,使用 Canal 组件,可持续获取最新的 Binlog 数据,结合 MQ,可以将数据同步到其他的数据源中。
对于结果集的操作,我们可以再发散一下思维。可以将一个简单冗余的结果集,改造成复杂高效的数据结构。这个复杂的数据结构可以代理我们的请求,有效地转移耗时操作。
For example, our commonly used database index is a kind of reorganization and acceleration of data. B tree can effectively reduce the number of interactions between the database and the disk. It indexes the most commonly used data through a data structure similar to B tree and stores it in a limited storage space.
There is also serialization commonly used in RPC. Some services use the SOAP protocol WebService, which is a protocol based on XML. The transmission of large content is slow and inefficient. Most of today's web services use json data for interaction, and json is more efficient than SOAP.
In addition, everyone should have heard of Google's protobuf. Because it is a binary protocol and compresses data, its performance is very superior. After protobuf compresses the data, the size is only 1/10 of json and 1/20 of xml, but the performance is improved by 5-100 times.
The design of protobuf is worth learning from. It processes the data very compactly through the three sections of tag|leng|value, and the parsing and transmission speed are very fast.
The above is the detailed content of How to deal with large objects in Java. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



