


Giving robots a 3D understanding of everyday objects is a major challenge in robotics applications.
When exploring in an unknown environment, existing object pose estimation methods are still unsatisfactory due to the diversity of object shapes.

Recently, researchers from Zhejiang University, ByteDance Artificial Intelligence Laboratory and the Chinese University of Hong Kong jointly proposed a new framework for Category-level object shape and pose estimation from a single RGB-D image.

##Paper address: https://arxiv.org/abs/2210.01112
Project link: https://zju3dv.github.io/gCasp
In order to handle the shape changes of objects within categories, researchers Adopting a semantic primitive representation to encode different shapes into a unified latent space, this representation is the key to establishing reliable correspondence between observed point clouds and estimated shapes.
Then by designing a shape descriptor that is invariant to rigid body similarity transformation, the shape and pose estimation of the object are decoupled, thereby supporting any pose. Implicit shape optimization of target objects. Experiments show that the proposed method achieves leading pose estimation performance in public datasets.
Research backgroundIn the field of robot perception and operation, estimating the shape and pose of daily objects is a basic function and has a variety of applications, including 3D scene understanding, robotic operations and autonomous warehousing.
Early work on this task mostly focused on instance-level pose estimation, which mainly obtains the object pose by aligning the observed object with a given CAD model.
However, such a setup is limited in real-world scenarios because it is difficult to obtain an exact model of any given object in advance.
To generalize to unseen but semantically familiar objects, category-level object pose estimation is attracting increasing research attention because it can potentially handle real Various instances of the same category in the scene.

#Existing class-level pose estimation methods usually try to predict the pixel-level normalized coordinates of instances in a class, or use deformed Refer to the prior model to estimate the object pose.
Although these works have made great progress, these one-shot prediction methods still face difficulties when there are large shape differences in the same category.
In order to handle the diversity of objects within the same category, some works utilize neural implicit representation to adapt to the shape of the target object by iteratively optimizing the pose and shape in the implicit space, and Better performance was obtained.
There are two main challenges in class-level object pose estimation. One is the huge intra-class shape difference, and the other is the existing methods that couple shape and pose together. Optimization can easily lead to more complex optimization problems.
In this paper, researchers decouple the shape and pose estimation of objects by designing a shape descriptor that is invariant to rigid body similarity transformations, thereby supporting arbitrary poses Implicit shape optimization of target objects. Finally, the scale and pose of the object are solved based on the semantic association between the estimated shape and the observation.
Algorithm introductionThe algorithm consists of three modules, Semantic primitive extraction, Generative shape estimationandObject pose estimation.
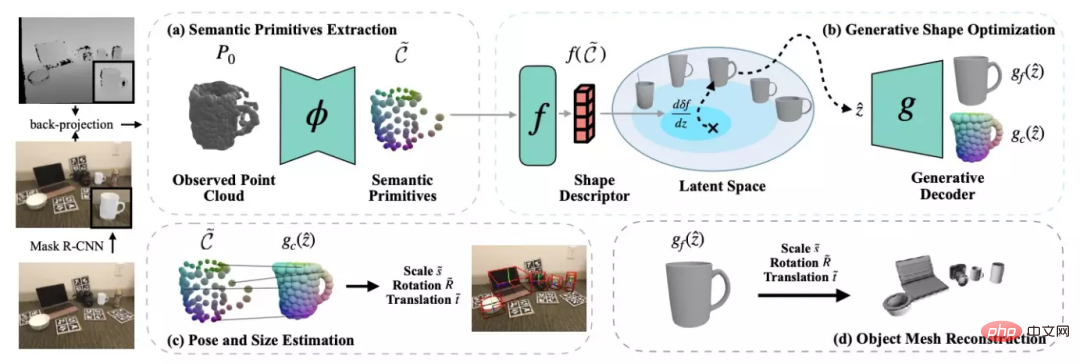
The input of the algorithm is a single RGB-D image. The algorithm uses the pre-trained Mask R-CNN to obtain the semantic segmentation results of the RGB image, and then back-projects the point cloud of each object based on the camera internal parameters. This method mainly processes point clouds and finally obtains the scale and 6DoF pose of each object.
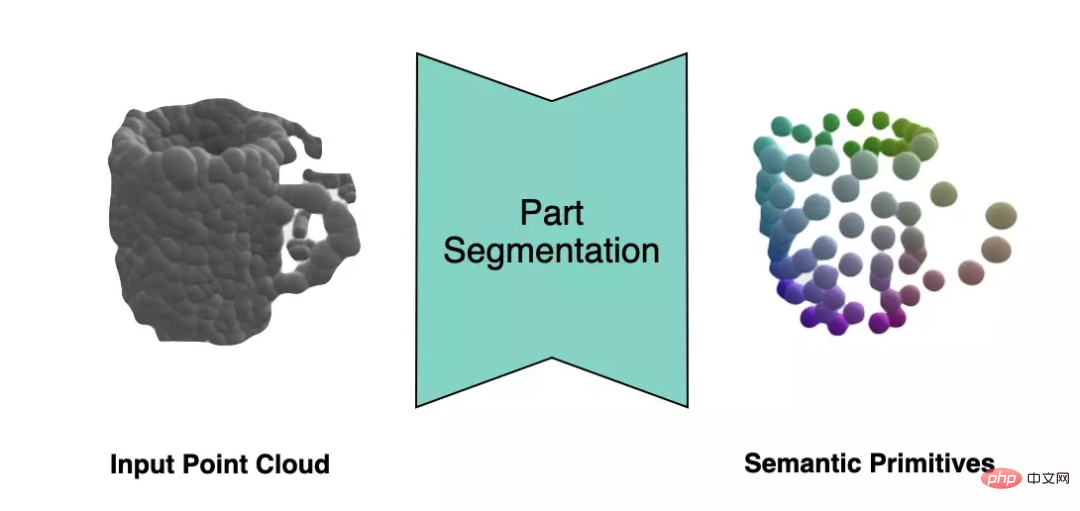
DualSDF[1] proposes a representation method of semantic primitives for similar objects. As shown on the left side of the figure below, in the same type of object, each instance is divided into a certain number of semantic primitives, and the label of each primitive corresponds to a specific part of a certain type of object.
In order to extract the semantic primitives of objects from the observation point cloud, the author utilizes a point cloud segmentation network to segment the observation point cloud into semantic primitives with labels.
3D generative model (such as DeepSDF) mostly operates in a normalized coordinate system.
However, there will be a similar pose transformation (rotation, translation and scale) between the object in the real world observation and the normalized coordinate system.
In order to solve the normalized shape corresponding to the current observation when the pose is unknown, the author proposes a shape descriptor that is invariant to similar transformations based on semantic primitive representation.
This descriptor is shown in the figure below, which describes the angle between vectors composed of different primitives:
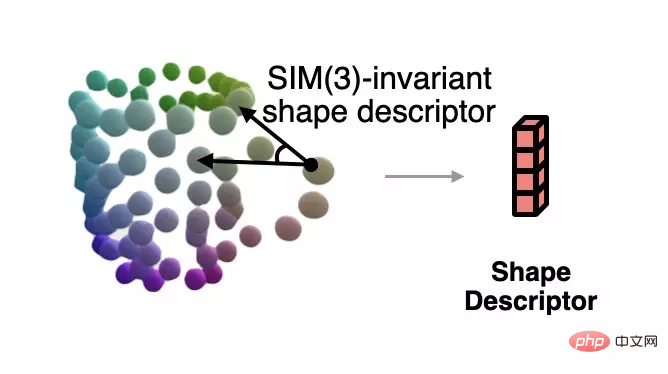
The author uses this descriptor to measure the error between the current observation and the estimated shape, and uses gradient descent to make the estimated shape more consistent with the observation. The process is shown in the figure below.
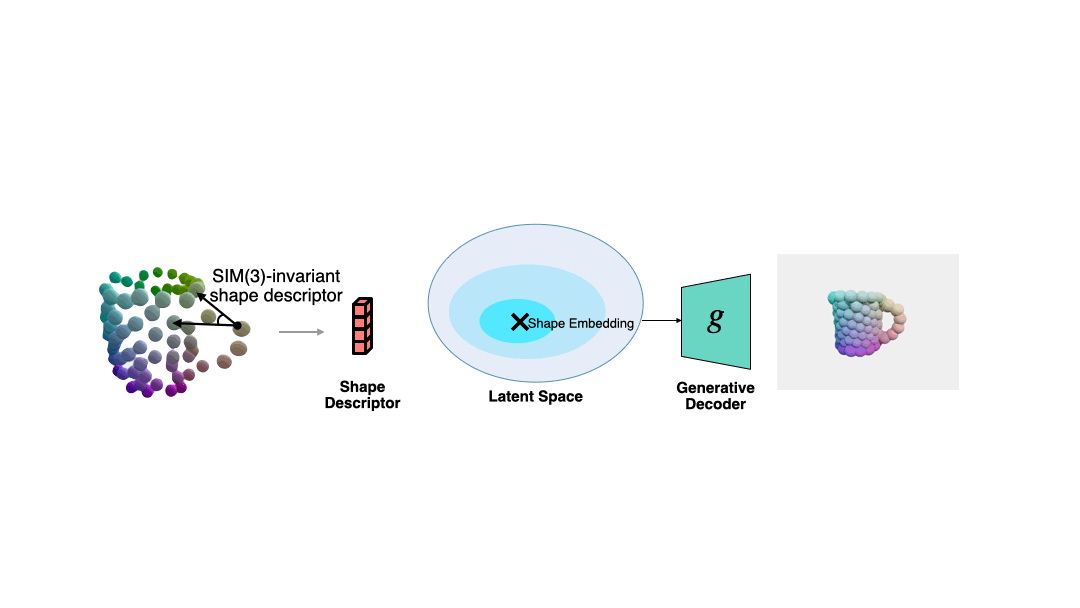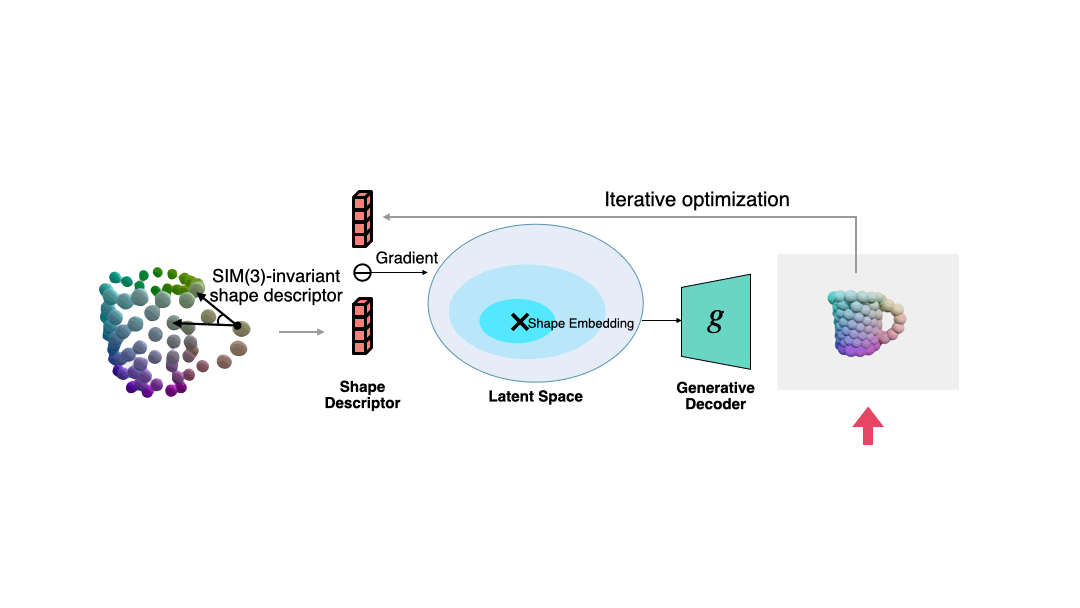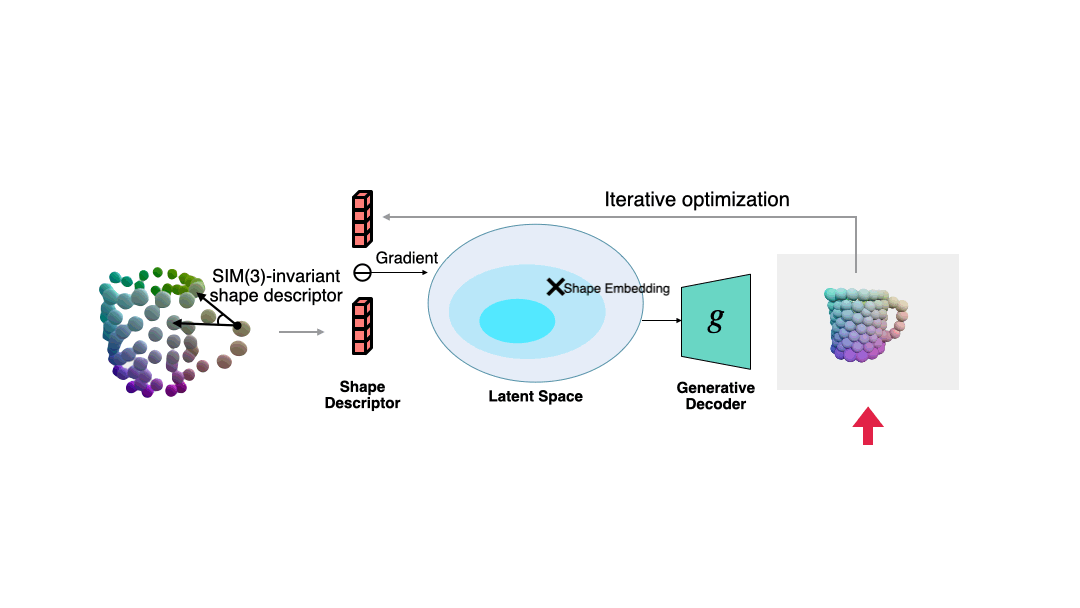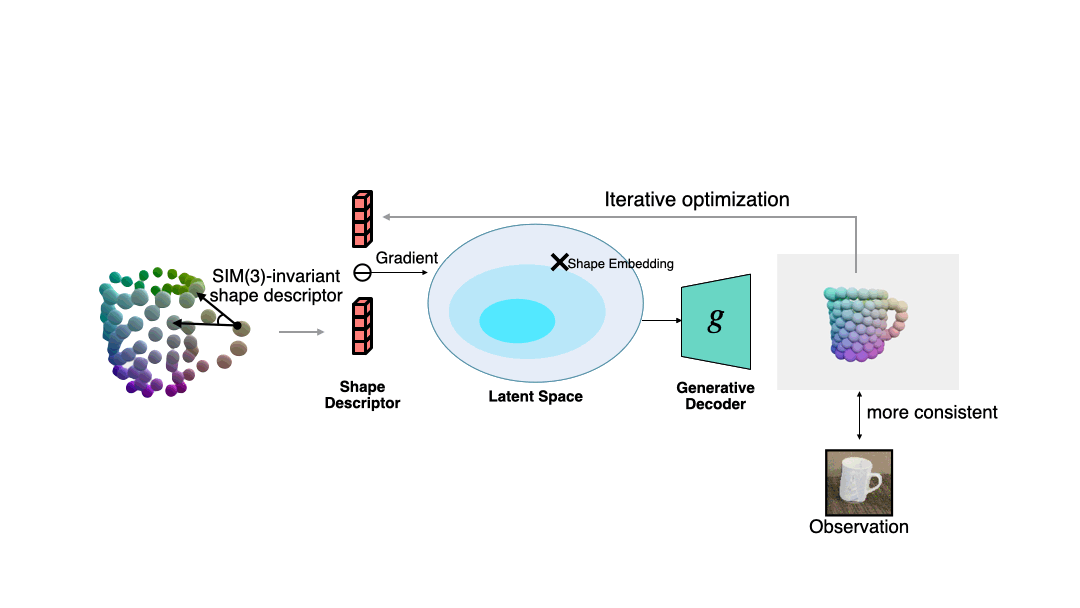
The author also shows more shape optimization examples.

Finally, by observing the point cloud and solving the semantic origin between the shapes Based on the language correspondence, the author uses the Umeyama algorithm to solve the pose of the observed shape.
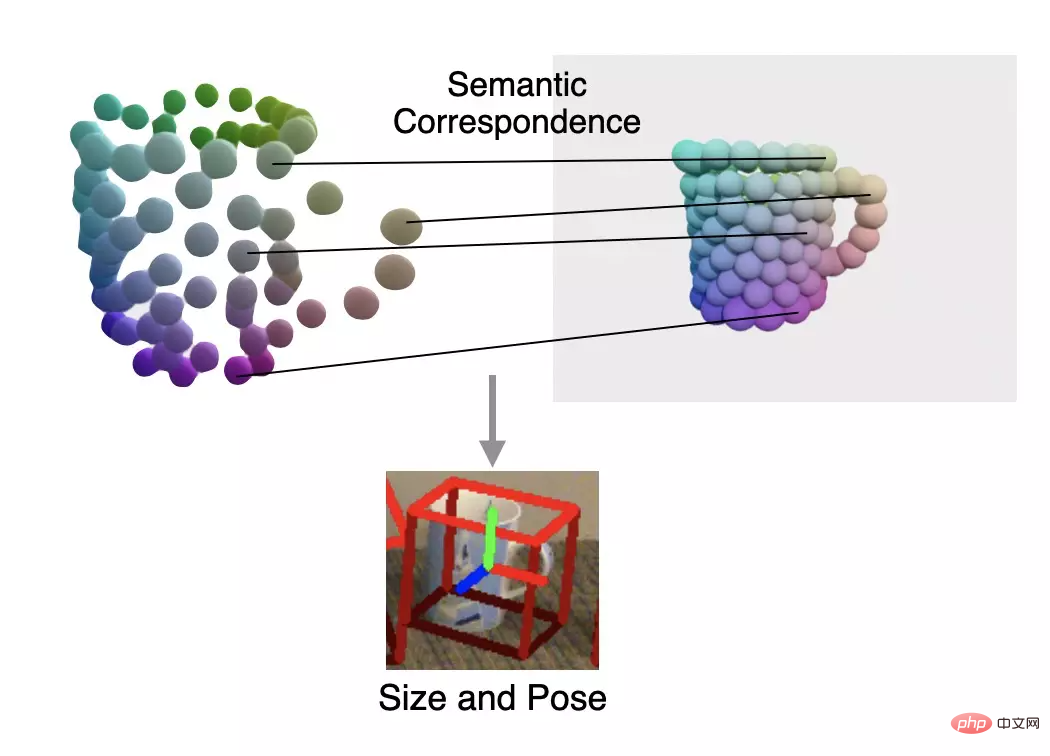
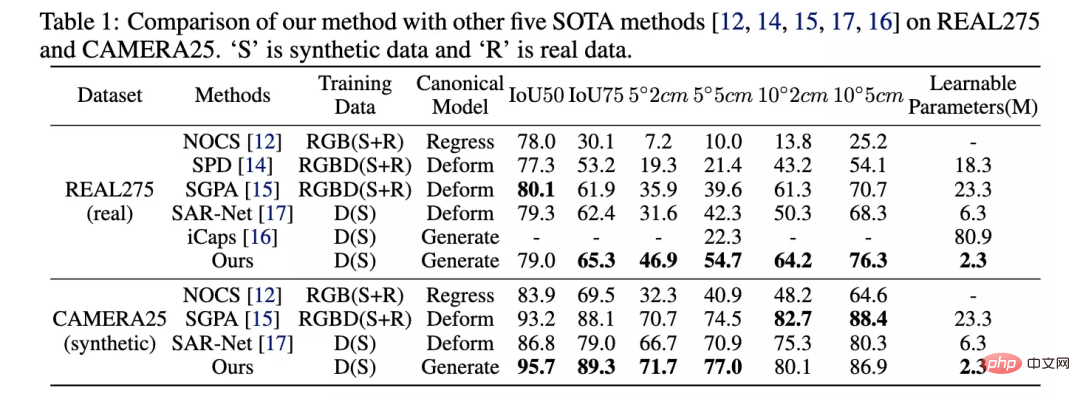
The author is on the REAL275 (real data set) and CAMERA25 (synthetic data set) data sets provided by NOCS Comparative experiments were conducted to compare the pose estimation accuracy with other methods. The proposed method far exceeded other methods in multiple indicators.
At the same time, the author also compared the amount of parameters that need to be trained on the training set provided by NOCS. The author requires a minimum of 2.3M parameters to reach the state-of-the-art level.
The above is the detailed content of Only 10% of the parameters are needed to surpass SOTA! Zhejiang University, Byte, and Hong Kong Chinese jointly proposed a new framework for the 'category-level pose estimation' task. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



