


General intelligence needs to solve tasks in multiple fields. Reinforcement learning algorithms are thought to have this potential, but it has been hampered by the resources and knowledge required to adapt them to new tasks. In a new study from DeepMind, researchers demonstrate DreamerV3, a general, scalable world model-based algorithm that outperforms previous methods in a wide range of domains with fixed hyperparameters.
DreamerV3 conforms to domains including continuous and discrete actions, visual and low-dimensional inputs, 2D and 3D worlds, varying data volumes, reward frequencies and reward levels. It is worth mentioning that DreamerV3 is the first algorithm to collect diamonds in Minecraft from scratch without human data or active education . The researchers say such a general algorithm could enable widespread applications of reinforcement learning and could potentially be extended to hard decision-making problems.
Diamonds are one of the most popular items in the game "Minecraft". They are one of the rarest items in the game and can be used to craft most of the items in the game. The most powerful tools, weapons and armor. Because diamonds are only found in the deepest layers of rock, production is low.
DreamerV3 is the first algorithm to collect diamonds in Minecraft without the need for human demos or manual crafting of classes. This video shows the first diamond it collected, which occurred within 30M environment steps / 17 days of game time.
If you have no idea about AI playing Minecraft, NVIDIA AI scientist Jim Fan said that compared with AlphaGo playing Go, the number of Minecraft tasks is unlimited and the environmental changes are unlimited. Yes, knowledge also has hidden information.
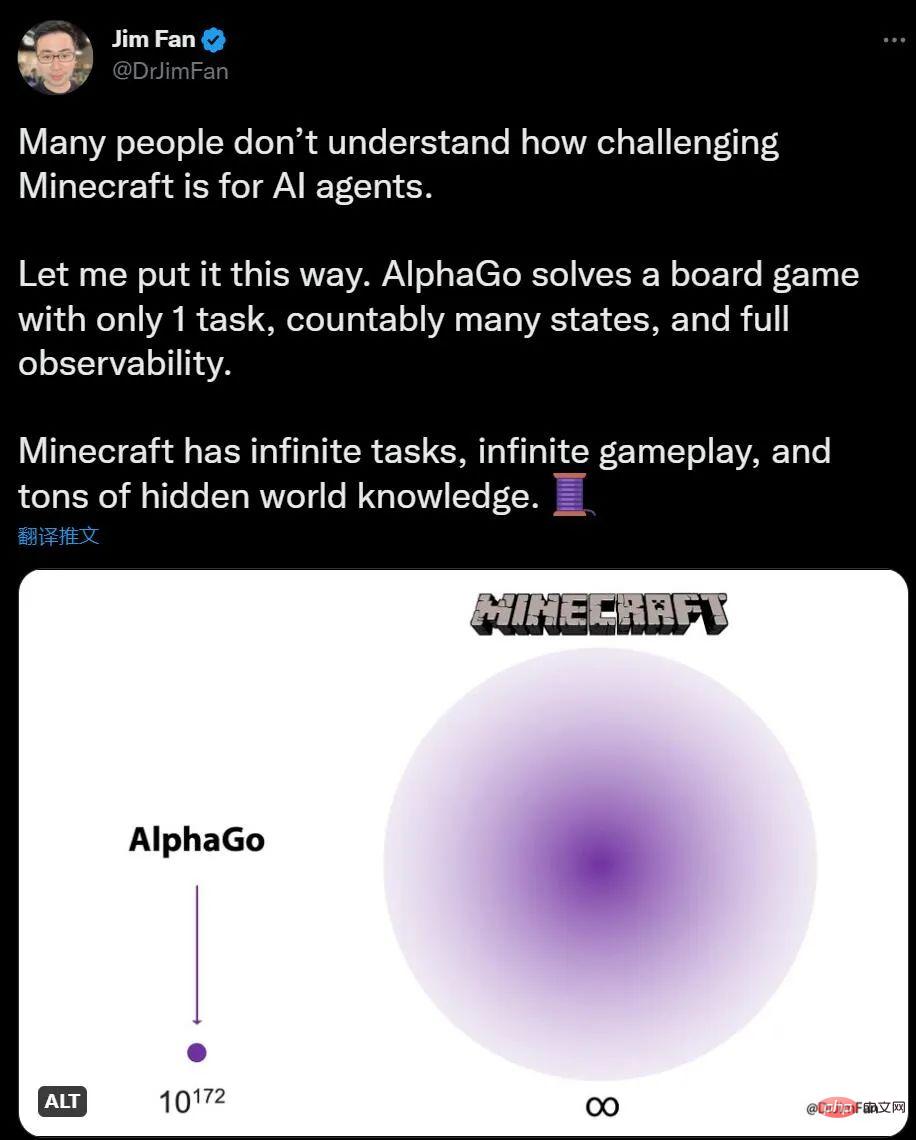
For humans, exploring and building in Minecraft is interesting, while Go seems a bit complicated. For AI, The opposite is true. AlphaGo defeated the human champion 6 years ago, but now there is no algorithm that can compete with the human masters of Minecraft.
As early as the summer of 2019, the development company of Minecraft proposed the "Diamond Challenge", offering a reward for an AI algorithm that can find diamonds in the game. Until NeurIPS 2019, the submission Of the more than 660 entries, not a single AI was up to the task.
But the emergence of DreamerV3 has changed this situation. Diamond is a highly combined and long-term task that requires complex exploration and planning. The new algorithm can achieve this without any artificial data assistance. Collect diamonds in case. There may be room for improvement in efficiency, but the fact that AI agents can now learn to collect diamonds from scratch is an important milestone. DreamerV3 method overviewThe paper "Mastering Diverse Domains through World Models":
Paper link: https://arxiv.org/abs/2301.04104v1

DreamerV3 algorithm consists of three neural networks, namely the world model (world model), critic and actor. The three neural networks are trained simultaneously based on replay experience without sharing gradients. Figure 3(a) below shows world model learning and figure (b) shows Actor Critic learning.
#To achieve cross-domain success, these components need to adapt to different signal amplitudes and robustly balance terms across their targets. This is challenging because learning is not only for similar tasks within the same domain, but also across different domains using fixed hyperparameters.
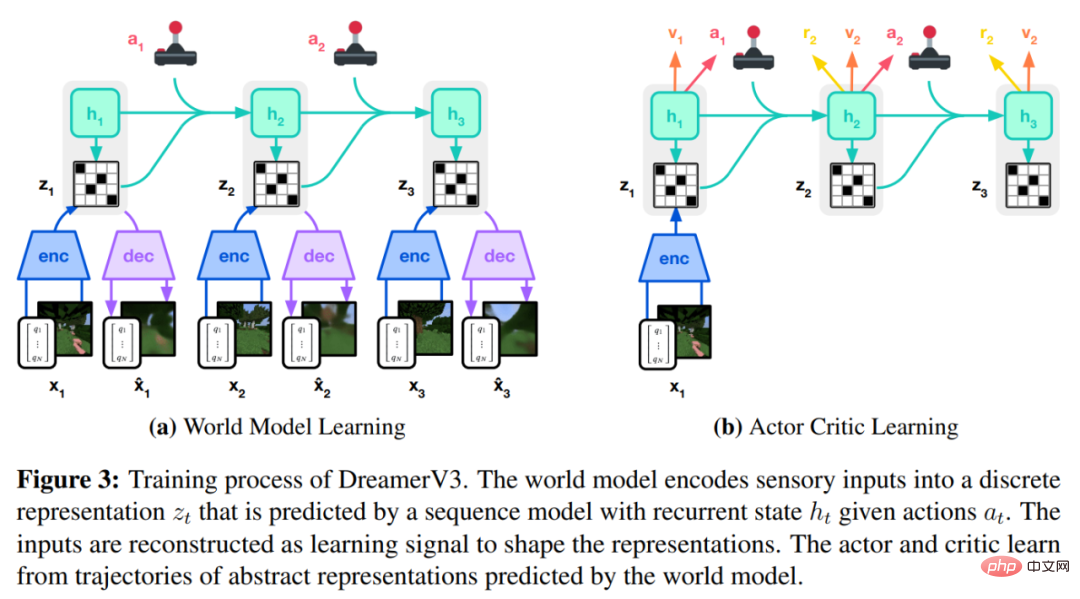
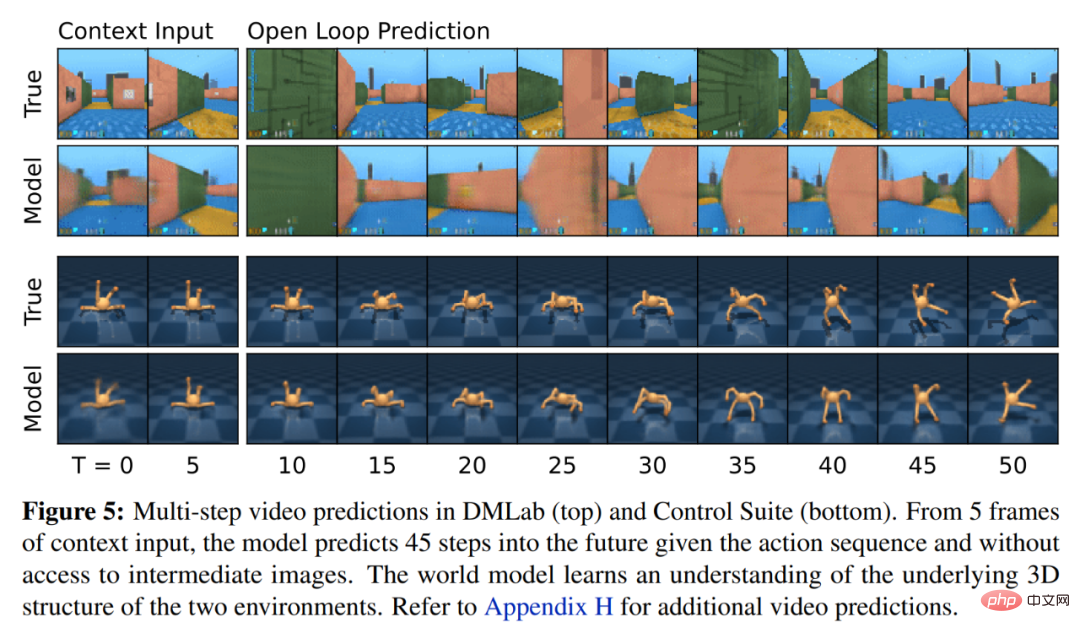
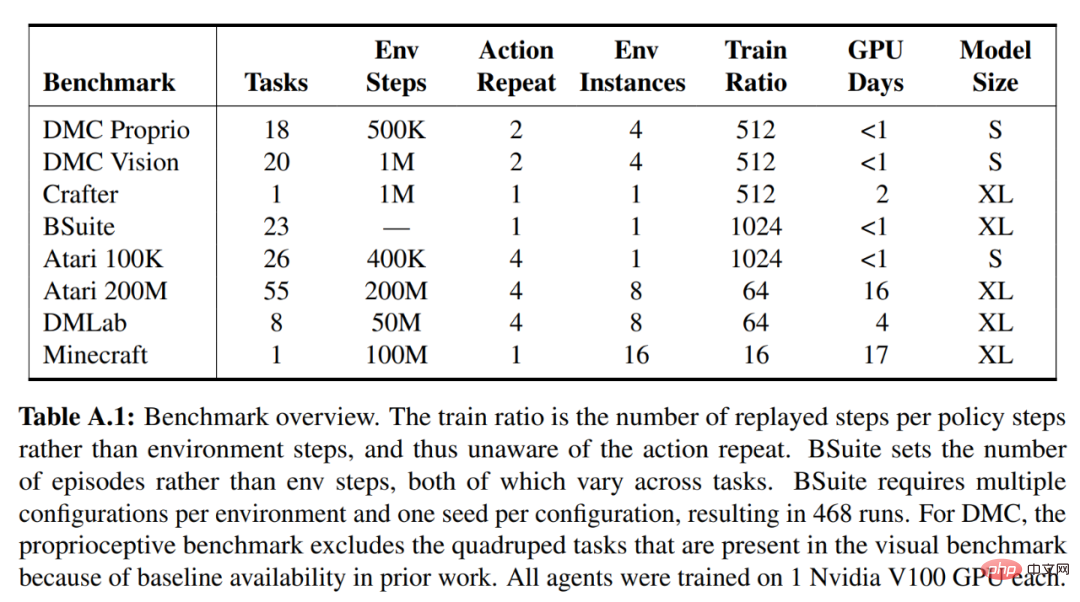
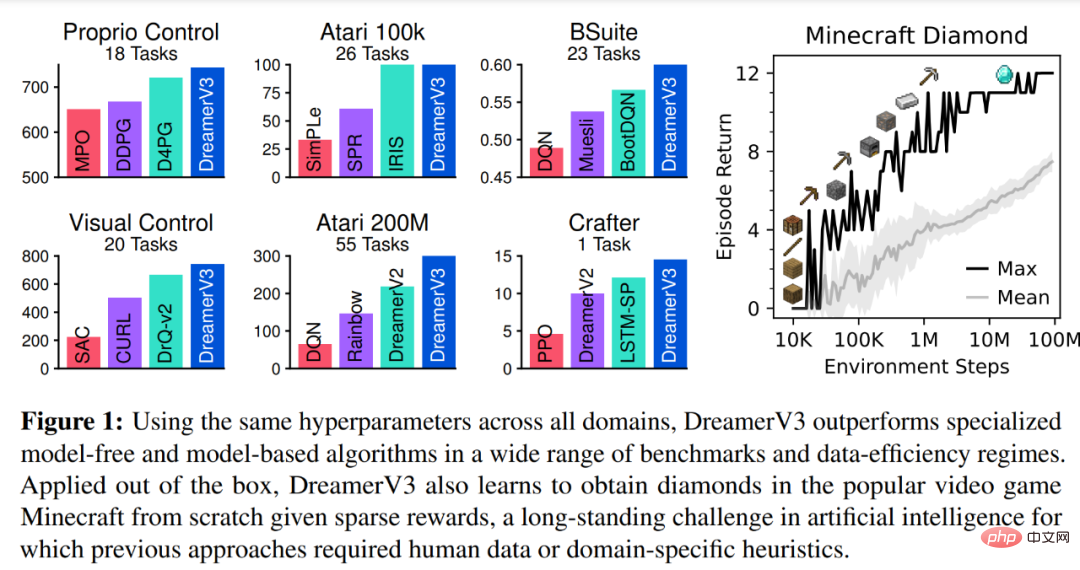
Symlog Prediction #Reconstructing inputs and predicting rewards and values is challenging because their scale can vary from domain to domain. Using squared loss to predict large targets leads to divergence, while absolute loss and Huber loss stall learning. On the other hand, normalization objectives based on operating statistics introduce non-stationarity into the optimization. Therefore, DeepMind proposes symlog prediction as a simple solution to this problem. To do this, a neural network f (x, θ) with an input x and a parameter θ learns to predict a transformed version of its target y. To read out the network's prediction y^, DeepMind uses an inverse transformation, as shown in equation (1) below. As you can see in Figure 4 below, targets with negative values cannot be predicted using logarithm as the transformation. Therefore, DeepMind selects a function from the bisymmetric logarithmic family, named symlog, as the transformation, and uses the symexp function as the inverse function. The symlog function compresses the size of large positive and negative values. DreamerV3 uses symlog prediction in the decoder, reward predictor and critic, and also uses the symlog function to compress the input of the encoder. World model learning World model learns a compact representation of sensory input through autoencoding and predicts future Rewards for representations and potential behaviors to implement planning. As shown in Figure 3 above, DeepMind implements the world model as a Recurrent State Space Model (RSSM). First, an encoder maps sensory input x_t to a random representation z_t, and then a sequence model with recurrent states h_t predicts a sequence of these representations given a past action a_t−1. The concatenation of h_t and z_t forms the model state from which the reward r_t and episode continuity flag c_t ∈ {0, 1} are predicted and the input is reconstructed to ensure information representation, as shown in equation (3) below. Figure 5 below visualizes the long-term video prediction of world world. The encoder and decoder use a convolutional neural network (CNN) for visual input and a multilayer perceptron (MLP) for low-dimensional input. Dynamic, reward, and persistence predictors are also MLPs, and these representations are sampled from vectors of softmax distributions. DeepMind uses pass-through gradients in the sampling step. Actor Critic Learning Actor Critic Neural Network completely learns from the world model Predicting learned behavior in abstract sequences. During interactions with the environment, DeepMind selects actions by sampling from the actor network, without the need for forward planning. actor and critic operate in model state Starting from a representation of the replayed input, the dynamic predictor and actor produce a sequence of expected model states s_1:T , action a_1:T, reward r_1:T and continuous flag c_1:T. To estimate returns for rewards outside the predicted horizon, DeepMind computes bootstrapped λ returns, which integrates expected returns and value. DeepMind conducted extensive empirical studies to evaluate the generality and scalability of DreamerV3 across different domains (over 150 tasks) under fixed hyperparameters, and compared it with existing There are SOTA methods in the literature for comparison. DreamerV3 was also applied to the challenging video game Minecraft. For DreamerV3, DeepMind simplifies setup by directly reporting the performance of stochastic training strategies and avoiding separate evaluation runs with deterministic strategies. All DreamerV3 agents are trained on an Nvidia V100 GPU. Table 1 below provides an overview of the benchmarks. To evaluate the generality of DreamerV3, DeepMind conducted extensive empirical evaluations in seven domains, including continuous and discrete action, vision, and low-dimensional Inputs, dense and sparse rewards, different reward scales, 2D and 3D worlds, and procedural generation. Results in Figure 1 below find that DreamerV3 achieves strong performance in all domains and outperforms all previous algorithms in 4 of them, while using fixed hyperparameters across all benchmarks. #Please refer to the original paper for more technical details and experimental results. 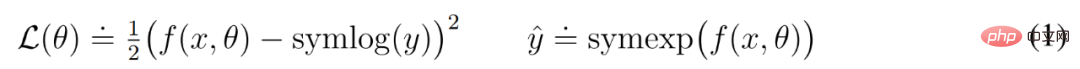

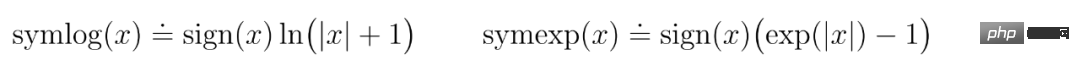
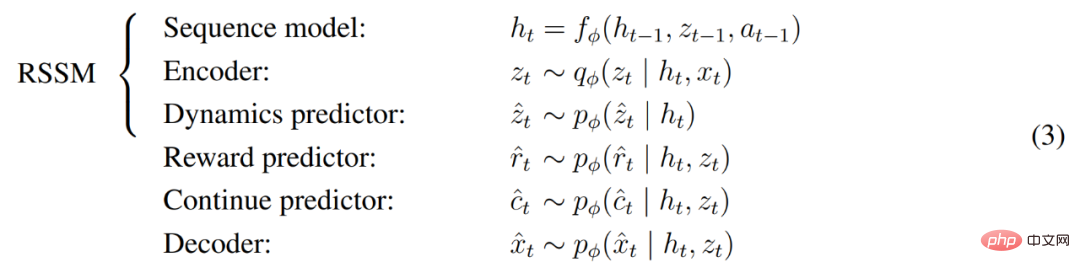
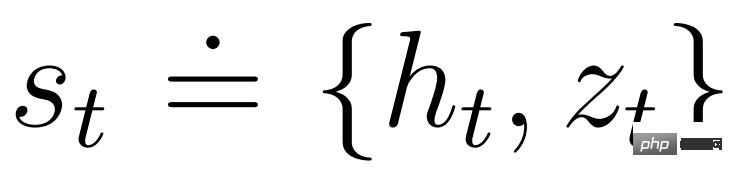 and can benefit from the Markov representation learned by the world model. The actor's goal is to maximize the expected return
and can benefit from the Markov representation learned by the world model. The actor's goal is to maximize the expected return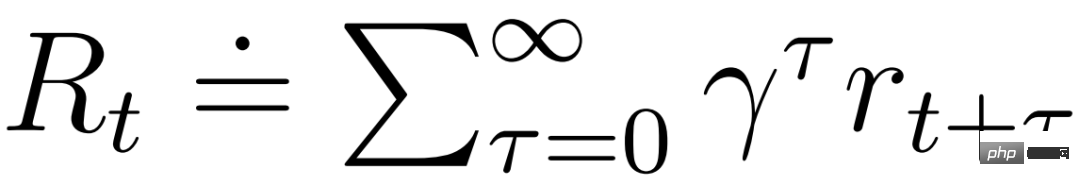 at a discount factor γ = 0.997 for each model state. To account for rewards beyond the prediction range T = 16, the critic learns to predict the reward for each state given the current actor behavior.
at a discount factor γ = 0.997 for each model state. To account for rewards beyond the prediction range T = 16, the critic learns to predict the reward for each state given the current actor behavior. 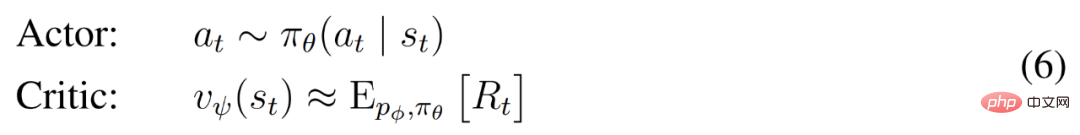
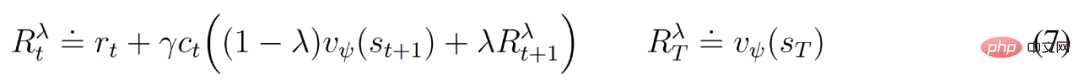
Experimental Results
The above is the detailed content of AI learns to play 'Minecraft' from scratch, DeepMind AI generalization makes breakthrough. For more information, please follow other related articles on the PHP Chinese website!
 What to do if win8wifi connection is not available
What to do if win8wifi connection is not available
 Comparative analysis of iqooneo8 and iqooneo9
Comparative analysis of iqooneo8 and iqooneo9
 How to use fit function in Python
How to use fit function in Python
 Solid state drive data recovery
Solid state drive data recovery
 Change word background color to white
Change word background color to white
 Google earth cannot connect to the server solution
Google earth cannot connect to the server solution
 What are the reasons why a mobile phone has an empty number?
What are the reasons why a mobile phone has an empty number?
 css beyond display...
css beyond display...








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



