



The paper mainly discusses why the over-parameterized neural network model can have good generalization performance? That is, it does not simply memorize the training set, but summarizes a general rule from the training set, so that it can be adapted to the test set (generalization ability).

Take the classic decision tree model as an example. When the tree model learns the general rules of the data set: a good situation, if the tree first splits the node, It can just about distinguish samples with different labels, the depth is very small, and the number of samples on each corresponding leaf is enough (that is, the amount of data based on statistical rules is also relatively large), then the rules that will be obtained will be more May generalize to other data. (ie: good fit and generalization ability).
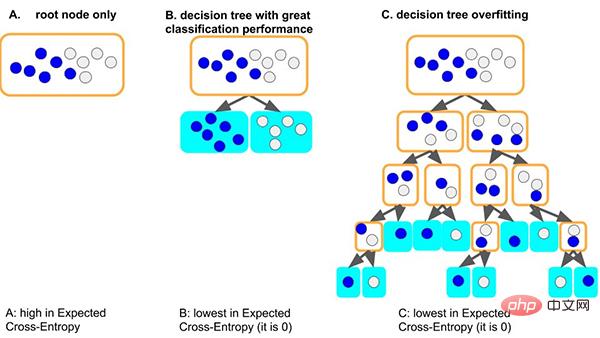
Another worse situation is that if the tree cannot learn some general rules, in order to learn this data set, the tree will become deeper and deeper, maybe every time Each leaf node corresponds to a small number of samples (the statistical information brought by a small amount of data may be just noise). Finally, all the data is memorized by rote (ie: overfitting and no generalization ability). We can see that tree models that are too deep can easily overfit.
So how can an over-parameterized neural network achieve good generalization?
This article explains from a simple and general perspective-exploring the reasons for the generalization ability in the gradient descent optimization process of neural networks:
We summarized the gradient coherence theory: the coherence of gradients from different samples is the reason why neural networks can have good generalization capabilities. When the gradients of different samples are well aligned during training, that is, when they are coherent, gradient descent is stable, can converge quickly, and the resulting model can generalize well. Otherwise, if the samples are too few or the training time is too long, it may not generalize.

Based on this theory, we can make the following explanation.
Wider neural network models have good generalization capabilities. This is because wider networks have more sub-networks and are more likely to produce gradient coherence than smaller networks, resulting in better generalization. In other words, gradient descent is a feature selector that prioritizes generalization (coherence) gradients, and wider networks may have better features simply because they have more features.
But personally, I think it still needs to distinguish the width of the network input layer/hidden layer. Especially for the input layer of data mining tasks, since the input features are usually manually designed, it is necessary to consider feature selection (ie, reduce the width of the input layer). Otherwise, directly inputting feature noise will interfere with the gradient coherence. .
The deeper the network, the gradient coherence phenomenon is amplified and has better generalization ability.

In the deep model, since the feedback between layers strengthens the coherent gradient, there are characteristics of coherent gradients (W6) and characteristics of incoherent gradients ( The relative difference between W1) is exponentially amplified during training. This makes deeper networks prefer coherent gradients, resulting in better generalization capabilities.
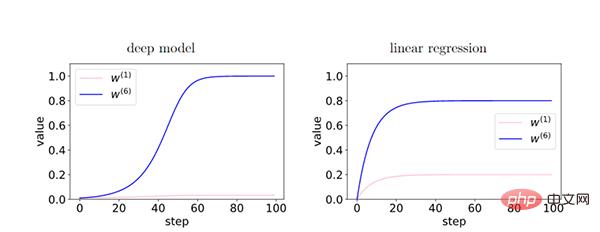
Through early stopping we can reduce the excessive influence of non-coherent gradients and improve generalization.
During training, some easy samples are fitted earlier than other samples (hard samples). In the early stage of training, the correlation gradient of these easy samples dominates and is easy to fit. In the later stage of training, the incoherent gradient of difficult samples dominates the average gradient g(wt), resulting in poor generalization ability. At this time, it is necessary to stop early.

We found that full gradient descent can also have good generalization ability. Furthermore, careful experiments show that stochastic gradient descent does not necessarily lead to better generalization, but this does not rule out the possibility that stochastic gradients are more likely to jump out of local minima, play a role in regularization, etc.
We believe that a lower learning rate may not reduce the generalization error , because lower learning rate means more iterations (opposite of early stopping).
Add L2 and L1 regularization to the objective function, and the corresponding gradient calculation, The gradient that needs to be added to the L1 regular term is sign(w), and the L2 gradient is w. Taking L2 regularization as an example, the corresponding gradient W(i 1) update formula is: Picture
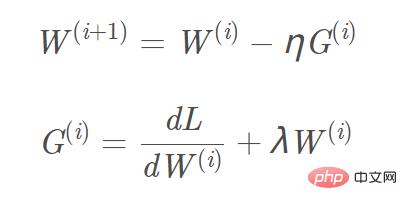
We can think of "L2 regularization (weight attenuation)" as a This kind of "background force" can push each parameter close to a data-independent zero value (L1 can easily obtain a sparse solution, and L2 can easily obtain a smooth solution approaching 0) to eliminate the influence in the weak gradient direction. Only in the case of coherent gradient directions can the parameters be relatively separated from the "background force" and the gradient update can be completed based on the data.

Momentum, Adam For the equal gradient descent algorithm, the parameter W update direction is not only determined by the current gradient, but also related to the previously accumulated gradient direction (that is, the effect of the accumulated coherent gradient is retained). This allows the parameters to be updated faster in dimensions where the gradient direction changes slightly, and reduces the update amplitude in dimensions where the gradient direction changes significantly, thus resulting in the effect of accelerating convergence and reducing oscillation.
We can suppress gradient updates in weak gradient directions by optimizing the batch gradient descent algorithm, further improving generalization capabilities. . For example, we can use winsorized gradient descent to exclude gradient outliers and then take the average. Or take the median of the gradient instead of the mean to reduce the impact of gradient outliers.

A few words at the end of the article. If you are interested in the theory of deep learning, you can read the related research mentioned in the paper.
The above is the detailed content of An article briefly discusses the generalization ability of deep learning. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



