


Deep learning has been widely implemented in actual business scenarios in fields such as natural language processing, and optimizing its inference performance has become an important part of the deployment process. Improvement of reasoning performance: On the one hand, it can give full play to the ability of deployed hardware, reduce user response time, and save costs; on the other hand, it can use deep learning models with more complex structures while keeping response time unchanged. thereby improving business accuracy indicators.
This article carries out inference performance optimization work for the deep learning model in the address standardization service. Through optimization methods such as high-performance operators, quantification, and compilation optimization, the model end-to-end inference speed of the AI model can be achieved up to 4.11 times without reducing accuracy indicators. improvement.
1. Model inference performance optimization methodologyModel inference performance optimization is one of the important links when deploying AI services. On the one hand, it can improve the efficiency of model inference and fully release the performance of the hardware. On the other hand, it can enable the business to adopt more complex models while keeping the reasoning delay unchanged, thereby improving the accuracy index. However, there are some difficulties in optimizing reasoning performance in actual scenarios.
1.1 Difficulties in optimizing natural language processing scenarios
In typical natural language processing (Natural Language Processing, NLP) tasks, recurrent neural networks ( Recurrent Neural Network, RNN) and BERT [7] (Bidirectional Encoder Representations from Transformers.) are two types of model structures with high usage rates. In order to facilitate elastic expansion and contraction mechanisms and cost-effective online service deployment, natural language processing tasks are usually deployed on x86 CPU platforms such as Intel® Xeon® processors. However, as business scenarios become more complex, the inference computing performance requirements of services are getting higher and higher. Taking the above RNN and BERT models as examples, the performance challenges when deployed on the CPU platform are as follows:
Recurrent neural network is a type of recursive neural network that takes sequence data as input, performs recursion in the evolution direction of the sequence, and has all nodes (cyclic units) connected in a chain. Commonly used RNNs in actual use include LSTM, GRU and some derived variants. During the calculation process, as shown in the figure below, each subsequent stage output in the RNN structure depends on the corresponding input and previous stage output. Therefore, RNN can complete sequence-type tasks and has been widely used in the field of NLP and even computer vision in recent years. Compared with BERT, RNN requires less calculation and shares model parameters, but its calculation timing dependency makes it impossible to perform parallel calculations on the sequence.
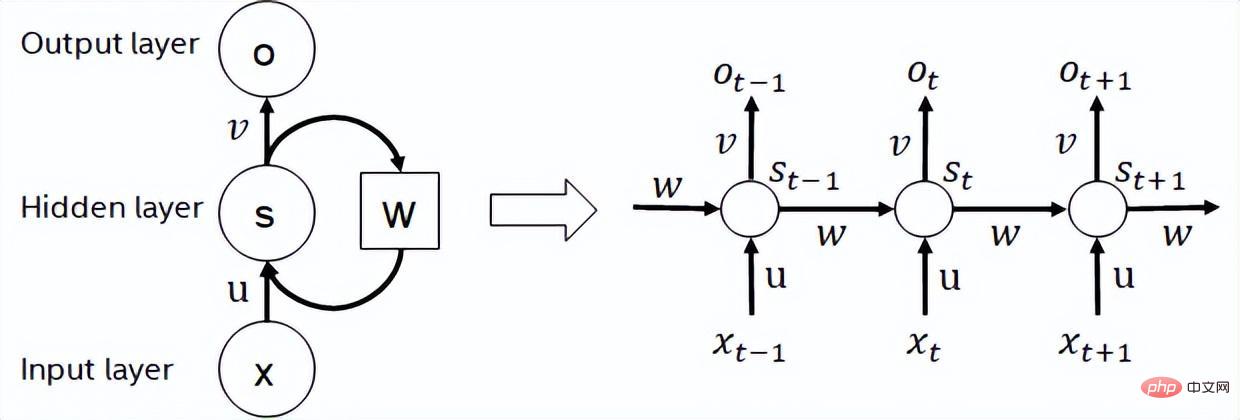
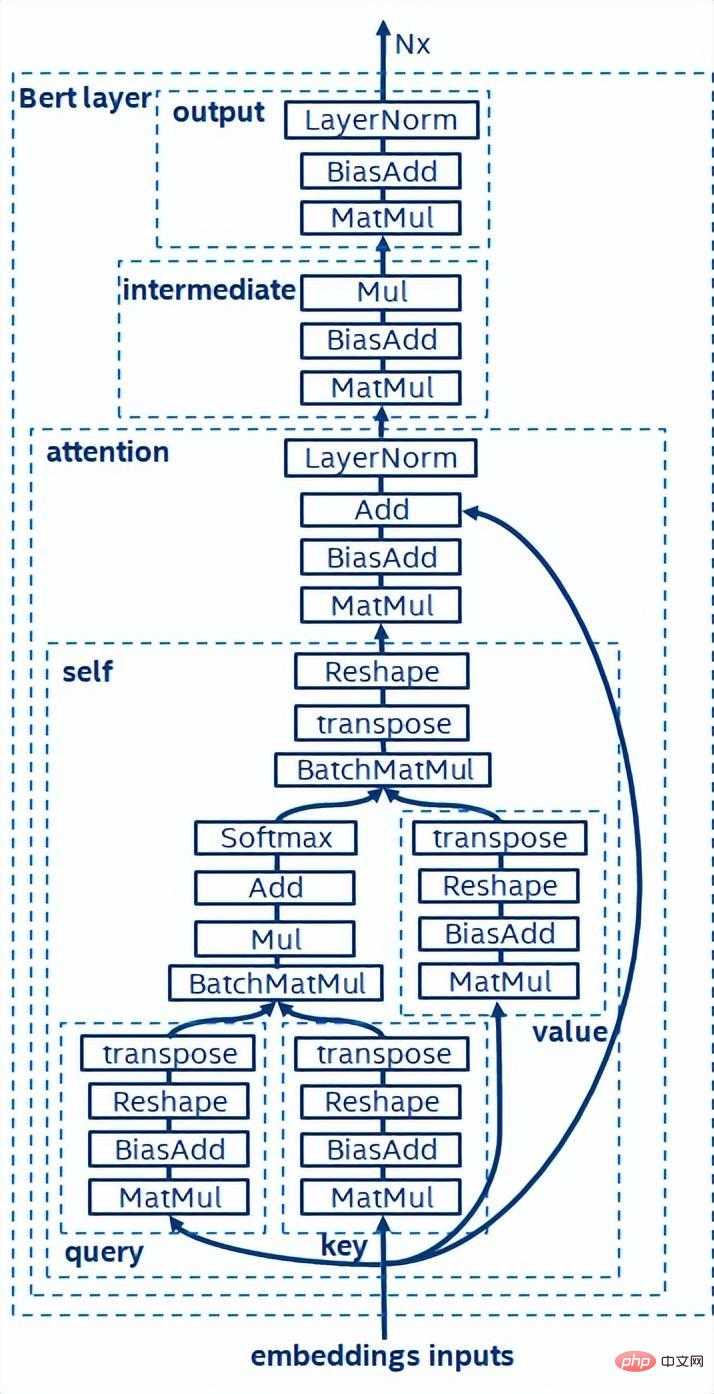 BERT model structure diagram
BERT model structure diagram
Based on the above To analyze the challenges of inference performance, we believe that optimizing model inference from the software stack level mainly includes the following strategies:
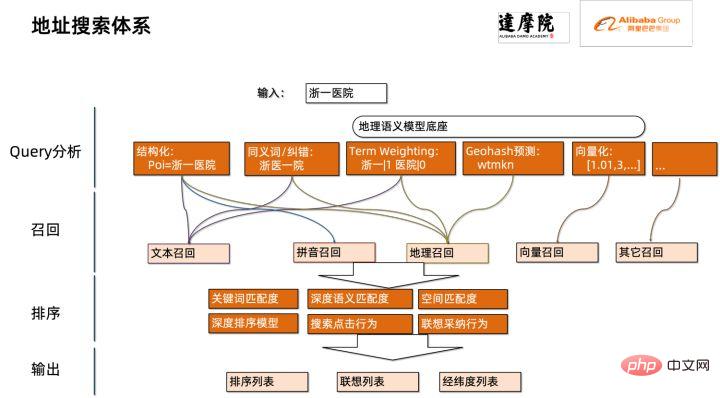
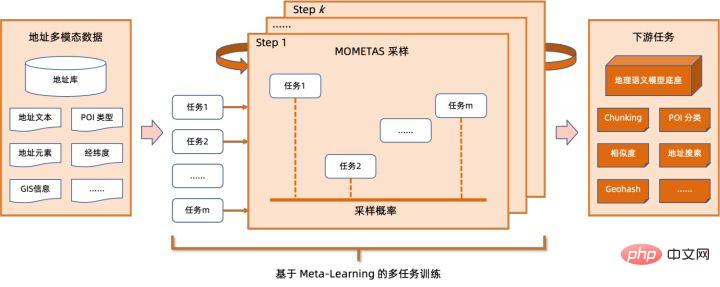
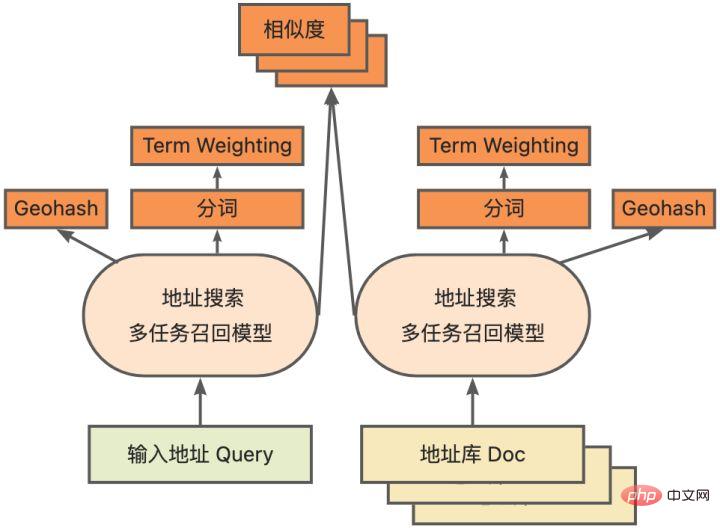
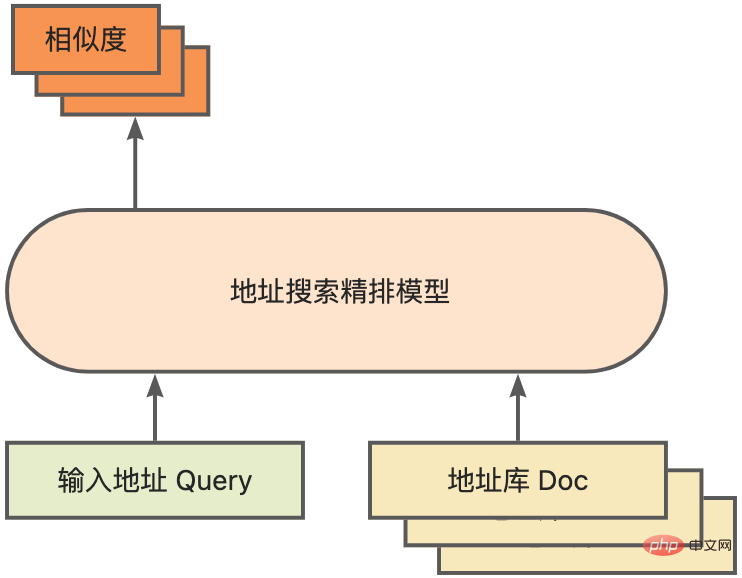
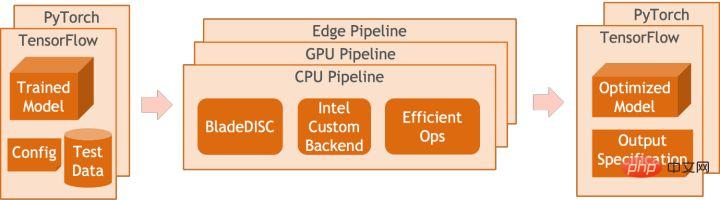
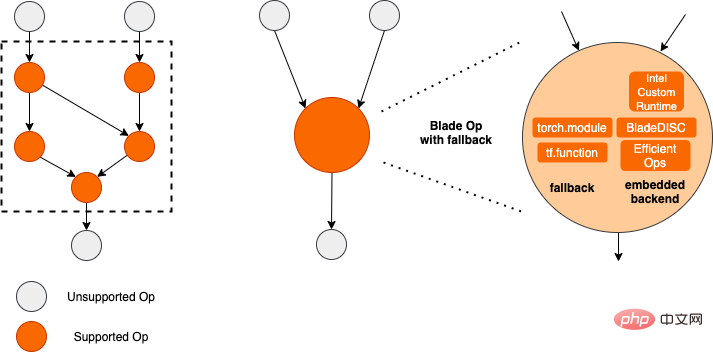
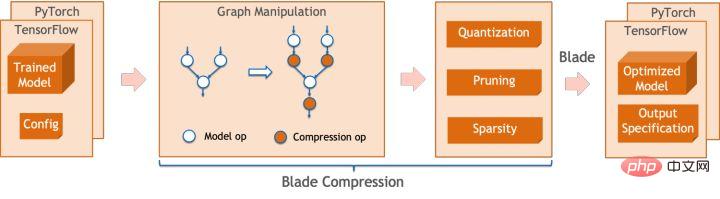
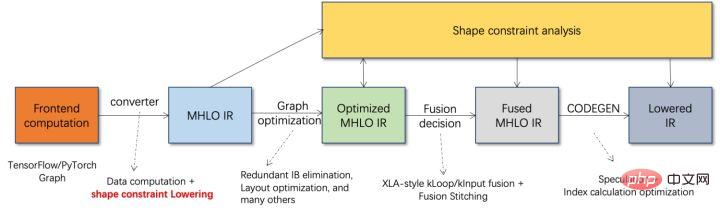
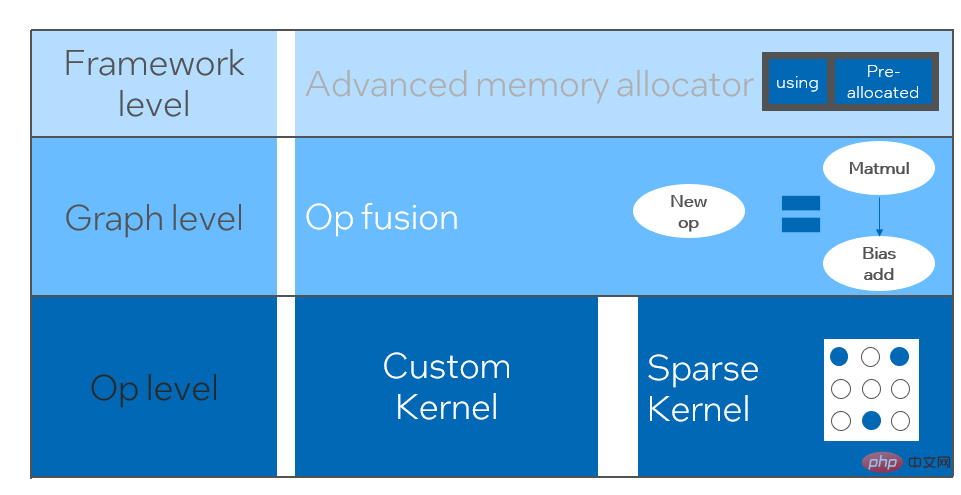
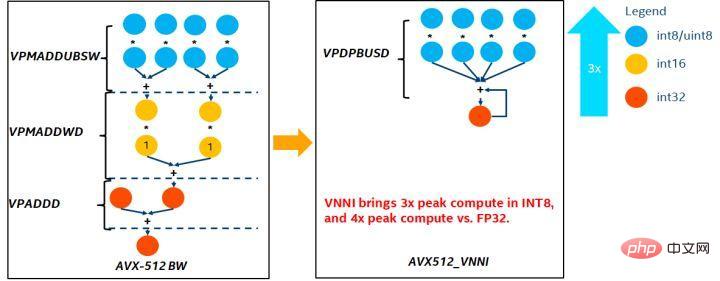
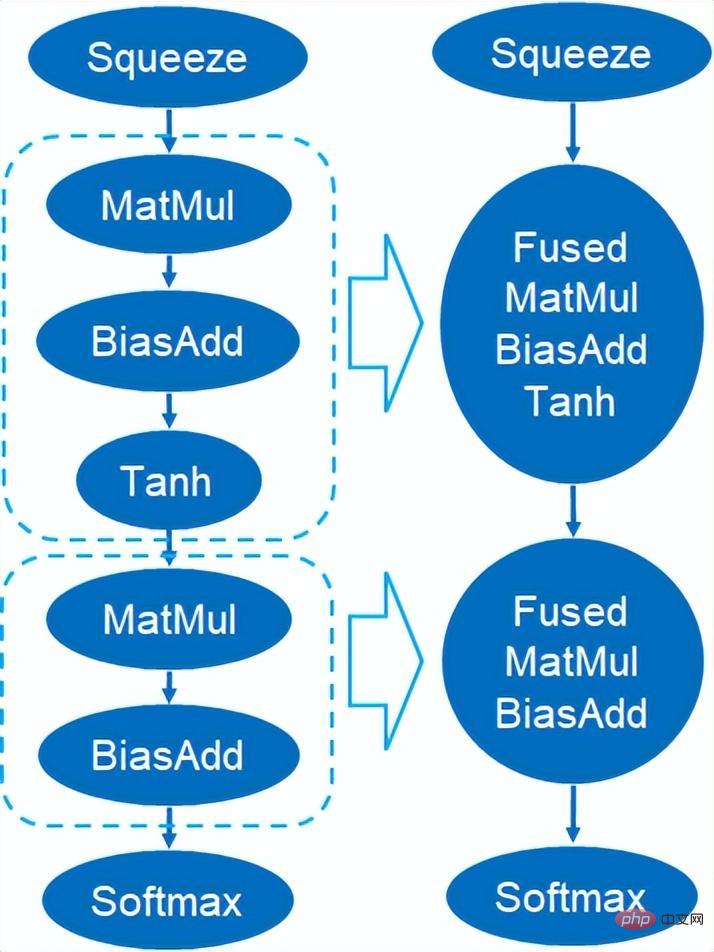
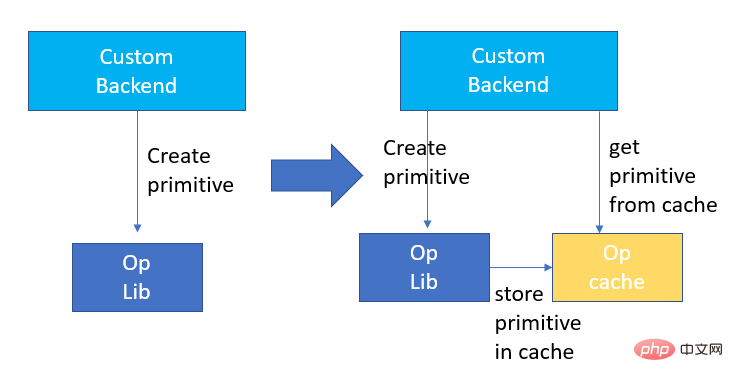
quantification Model quantization refers to approximating floating point activation values or weights (usually represented by 32-bit floating point numbers) to low-bit integers (16 bits or 8 bits), and then completing the calculation in a low-bit representation. process. Generally speaking, model quantization can compress model parameters, thereby reducing model storage overhead; and by reducing memory access and effectively utilizing low-bit computing instructions (such as Intel® Deep Learning Boost Vector Neural Network Instructions, VNNI), Obtain reasoning speed improvement. Given a floating point value, we can map it to a low bit value through the following formula: where the sum is obtained by the quantization algorithm . Based on this, taking the Gemm operation as an example, assuming there is a floating point calculation process: We can complete the corresponding calculation process in the low bit domain: High-performance operator In the deep learning framework, in order to maintain versatility while taking into account various processes (such as training), the inference overhead of the operator There is redundancy. When the model structure is determined, the operator's reasoning process is only a subset of the original full process. Therefore, when the model structure is determined, we can implement high-performance inference operators and replace the general operators in the original model to improve the inference speed. The key to implementing high-performance operators on the CPU is to reduce memory accesses and use a more efficient instruction set. In the calculation process of the original operator, on the one hand, there are a large number of intermediate variables, and these variables will perform a large number of read and write operations on the memory, thus slowing down the reasoning speed. In response to this situation, we can modify its calculation logic to reduce the cost of intermediate variables; on the other hand, we can directly call the vectorized instruction set to accelerate some calculation steps inside the operator, such as Intel® Xeon® processing Efficient AVX512 instruction set on the processor. AI compiler optimization With the development of the field of deep learning, the structure of the model and the hardware deployed are presented. show the trend of diversified evolution. When deploying the model to various hardware platforms, we usually call the runtime launched by each hardware manufacturer. In actual business scenarios, this may encounter some challenges, such as: #The AI compiler was proposed to solve the above problems. It abstracts multiple levels to solve some of the above problems. First, it accepts the model calculation graph of each front-end framework as input, and generates a unified intermediate representation through various Converters. Subsequently, graph optimization passes such as operator fusion and loop expansion will be applied to the intermediate representation to improve reasoning performance. Finally, the AI compiler will perform codegen for specific hardware platforms based on the optimized calculation graph to generate executable code. In this process, optimization strategies such as stitch and shape constraint will be introduced. AI compilers are very robust, adaptable, easy to use, and can reap significant optimization benefits. In this article, the Alibaba Cloud machine learning platform PAI team teamed up with the Intel data center software team, Intel artificial intelligence and analysis team, and DAMO Academy NLP address standardization team to perform inference on address standardization services. performance challenges, we collaborated to implement a high-performance inference optimization solution. Business development in public security and government affairs, e-commerce logistics, energy (water, electricity and gas), operators, new retail, finance, medical and other industries The process often involves a large amount of address data, and these data often do not form standard structure specifications, and there are problems such as missing addresses and multiple names in one place. With the upgrade of digitalization, the problem of non-standard urban addresses has become increasingly prominent. Existing problems in address application Address standardization[2](Address Purification) is the NLP team of Alibaba Damo Academy relying on Alibaba Cloud's massive address corpus and its powerful NLP algorithm provide high-performance and high-accuracy standard address algorithm services. Address standardization products provide high-performance address algorithms from the perspective of standardizing address data and establishing a unified standard address library. Advantages of address standardization This address algorithm service can automatically standardize address data and can effectively solve the problem of multiple addresses in one place. , address identification, address authenticity identification and other address data are not standardized, manual management is time-consuming and labor-intensive, and address database duplication construction problems provide enterprises, government agencies and developers with address data cleaning and address standardization capabilities to make address data better Provide support to the business. Address standardization products have the following characteristics: The module optimized this time belongs to the search module in address standardization. Address search means that the user inputs information related to the address text. Based on the address library and search engine, the address text input by the user is searched and associated, and relevant Point of Interest (POI) information is returned. The address search function not only improves user data processing experience, but is also the basis for multiple address downstream services, such as latitude and longitude query, door address standardization, address normalization, etc., so it plays a key role in the entire address service system. Schematic diagram of address service search system Specifically, the optimized model is based on Multi-task geographic prediction The multi-task vector recall model and refined ranking model produced by the training language model base. Multi-task geographical pre-training language model base combines relevant interest point classification and address based on the Masked Language Model (MLM) task Element identification (province, city, district, POI, etc.), and through meta learning (Meta Learning), the sampling probability of multiple tasks is adaptively adjusted, and general address knowledge is integrated into the language model. Multi-task address pre-training model base diagram Multi-task vector recall modelBased on the above base training The results include four tasks: twin tower similarity, Geohash (address encoding) prediction, word segmentation and Term Weighting (word weight). Schematic diagram of multi-task vector recall model As the core module for calculating address similarity matching, Fine ranking model is based on the above-mentioned base, introducing massive click data and annotation data training [3], and improving the efficiency of the model through model distillation technology [4]. Finally reordered with address library documents applied to recall model recall. The 4-layer single model trained based on the above process can achieve better results than the 12-layer baseline model on the CCKS2021 Chinese NLP address correlation task [5] (see the Performance Display section for details). Schematic diagram of refined model Blade product support launched by Alibaba Cloud Machine Learning Platform PAI team All the optimization solutions mentioned above provide a unified user interface and have multiple software backends, such as high-performance operators, Intel Custom Backend, BladeDISC, etc. Blade model inference optimization architecture diagram 3.1 Blade Blade is a general inference optimization tool launched by the Alibaba Cloud machine learning PAI team (Platform of Artificial Intelligence). It can jointly optimize the model system to achieve optimal inference performance. It organically integrates computational graph optimization, vendor optimization libraries such as Intel® oneDNN, BladeDISC compilation optimization, Blade high-performance operator library, Costom Backend, Blade mixed precision and other optimization methods. At the same time, the simple usage lowers the threshold for model optimization and improves user experience and production efficiency. PAI-Blade supports multiple input formats, including Tensorflow pb, PyTorch torchscript, etc. For the model to be optimized, PAI-Blade will analyze it, then apply a variety of possible optimization methods, and select the one with the most obvious acceleration effect from various optimization results as the final optimization result. Blade optimization diagram In order to obtain the maximum optimization effect while ensuring the deployment success rate, PAI-Blade adopts Optimize in a "circle graph" manner, that is: Blade circle diagram diagram Blade Compression is a model compression model launched by Blade Toolkit designed to assist developers in efficient model compression and optimization work. It contains a variety of model compression functions, including quantization, pruning, sparsification, etc. The compressed model can be further optimized easily through Blade to obtain the ultimate optimization of model system combination. In terms of quantification, Blade Compression: At the same time, we provide a rich atomic capability API to facilitate customized development for specific situations. Blade Compression diagram BladeDISC is a machine learning-oriented product launched by the Alibaba Cloud machine learning platform PAI team. The dynamic shape deep learning compiler of the scene is one of the backends of Blade. It supports mainstream front-end frameworks (TensorFlow, PyTorch) and back-end hardware (CPU, GPU), and also supports optimization of inference and training. BladeDISC Architecture Diagram 3.2 High-performance operator based on Intel® Xeon® Subnetworks in neural network models usually have long-term general and universality, such as Linear Layer and Recurrent Layers in PyTorch, etc., which are the basic modules of model construction and are responsible for specific functions. Various models can be obtained through different combinations of these modules, and these modules are also optimized by the AI compiler. Target. Accordingly, in order to obtain the best-performing basic modules and thereby achieve the best-performing model, Intel has carried out multi-level optimization of these basic modules for the X86 architecture, including enabling efficient AVX512 instructions, operator internal calculation scheduling, operator Fusion, cache optimization, parallel optimization, etc. In address standardization services, the Recurrent Neural Network (RNN) model often appears, and the module that most affects performance in the RNN model is LSTM or GRU. This chapter uses LSTM as the An example shows how to achieve the ultimate performance optimization of LSTM when inputs are of variable length and multiple batches. Usually, in order to meet the needs and requests of different users, cloud services that pursue high performance and low cost will batch different user requests to maximize the utilization of computing resources. . As shown in the figure below, there are a total of three embedding sentences, and the content and input length are different. Original input data In order to make the LSTM calculation more efficient, you need to use PyTorch's pack_padded_sequence() function for the Batched input. padding and sorting, as shown in the figure below, a padding data tensor, a batch size tensor describing the data tensor, and an original serial number tensor describing the data tensor. Original input data So far, the input of LSTM has been prepared. The calculation process of LSTM is as shown in the figure below Indicates that the input tensor is calculated in batches and zero value calculations are skipped. LSTM calculation steps for input The more in-depth calculation optimization of LSTM is shown in Figure 17 below. The matrix in the formula The multiplication part is calculated and fused between formulas. As shown in the figure below, the original 4 matrix multiplications are converted into 1 matrix multiplication, and AVX512 instructions are used for numerical calculations and multi-thread parallel optimization to achieve efficient LSTM operators. Among them, numerical calculation refers to matrix multiplication and subsequent elementwise element operations. For the matrix multiplication part, this solution uses the oneDNN library for calculation. The library has an efficient AVX512 GEMM implementation. For elementwise element operations, this solution The AVX512 instruction set is used for operator fusion, which improves the hit rate of data in the cache. LSTM computing fusion[8] 3.3 Custom Backend Intel custom backend[9], as the software backend of Blade, powerfully accelerates model quantization and sparse reasoning performance, and mainly includes three levels of optimization. First, the Primitive Cache strategy is used to optimize the memory. Second, graph fusion optimization is performed. Finally, at the operator level, an efficient operator library including sparse and quantized operators is implemented. Intel Custom Backend Architecture Diagram Low Precision Quantization High-speed operators such as sparse and quantization benefit from the Intel® DL Boost acceleration instruction set, such as the VNNI instruction set. VNNI instruction introduction The picture above shows the VNNI instruction. 8bits can be accelerated using three AVX512 BW instructions. VPMADDUBSW first multiplies and adds 2 pairs of arrays composed of 8bits to obtain 16bits data. , VPMADDWD adds up the adjacent data to obtain 32bits data. Finally, VPADDD adds a constant. These three functions can form an AVX512_VNNI. This instruction can be used to accelerate matrix multiplication in inference. Graph fusion In addition, Custom Backend also provides graph fusion, such as matrix multiplication Instead of outputting the intermediate temporary Tensor, the subsequent instructions are directly run, that is, the post op of the subsequent item is fused with the previous operator, thus reducing data handling and reducing running time. The following figure is an example, the operator in the red box After fusion, additional data movement can be eliminated and it becomes a new operator. Graph fusion Memory optimization Memory Allocation and release will communicate with the operating system, resulting in increased runtime delay. In order to reduce this part of the overhead, the Custom Backend has added the design of Primitive Cache. Primitive Cache is used to cache Primitives that have been created, so that Primitives cannot Recycled by the system, reducing the creation overhead for the next call. At the same time, a cache mechanism has been established for time-consuming operators to speed up the operation of the operators, as shown in the following figure: Primitive Cache Quantitative function As mentioned before, after the model size is reduced, the calculation and access overhead are greatly reduced, thus the performance is greatly improved. We selected two typical model structures in the address search service to verify the effect of the above optimization solution. The test environment is as follows: ) in the PyTorch module. The ESIM tested this time contains two LSTM structures. The performance before and after single operator optimization is shown in the table: After optimization RT Acceleration ratio LSTM - A 7x200 0.199ms 0.066ms ## 3.02x ## 2.98x 70x50 0.266ms 0.098ms 2.71x ##202x50 Before and after optimization, the end-to-end inference speed of ESIM is as shown in the table, while the . ESIM[6] ##ESIM[6] Blade operator optimization Acceleration ratio ##RT 6.3ms ##3.4ms 1.85x ESIM model optimization before and after inference performance 4.2 BERT BERT[7] has been widely used in natural language processing (NLP) in recent years. ), computer vision (CV) and other fields have been widely adopted. Blade has various methods such as compilation optimization (FP32) and quantization (INT8) for this structure. In the speed test, the shape of the test data is fixed at 10x53. The speed performance of various backends and various optimization methods are as shown in the table below. It can be seen that the model inference speed after blade compilation and optimization or after INT8 quantization is better than libtorch and onnxruntime, and the backend of the inference is Intel Custom Backend & BladeDisc. It is worth noting that the speed of 4-layer BERT after quantitative acceleration is 1.5 times that of 2-layer BERT, which means that while speeding up, the business can use a larger model and obtain better business accuracy. Address BERT inference performance display In terms of accuracy, we display related models based on the CCKS2021 Chinese NLP address correlation task [5] performance, as shown in the table below. The accuracy of the 4-layer BERT macro F1 self-developed by the DAMO Academy address team is higher than the standard 12-layer BERT-base. Blade compilation optimization can achieve lossless accuracy, and the accuracy of the real quantized model after Blade Compression quantization training is slightly higher than the original floating point model. ##Model structure macro F1 (the higher, the better) 78.72(1.48) 78.85(1.61) Address BERT related accuracy results2. Introduction to address standardization
3. Model inference optimization solution




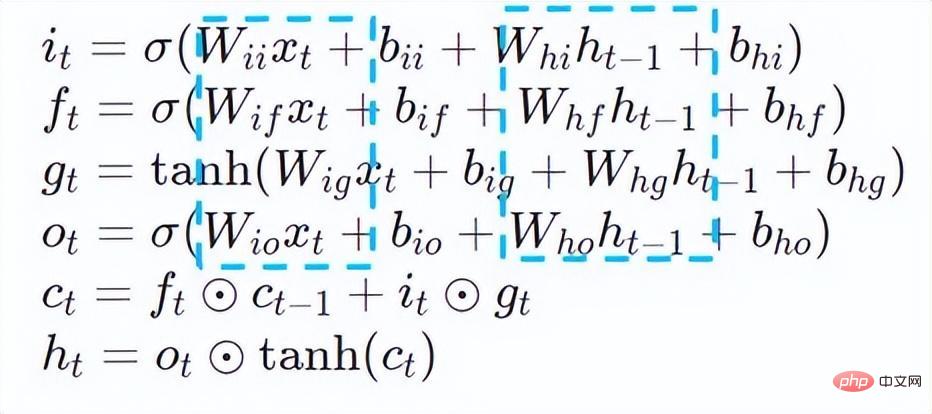
4. Overall performance display
BaselineInput shape ##202x200 ##0.914ms##0.804ms ##0.209ms 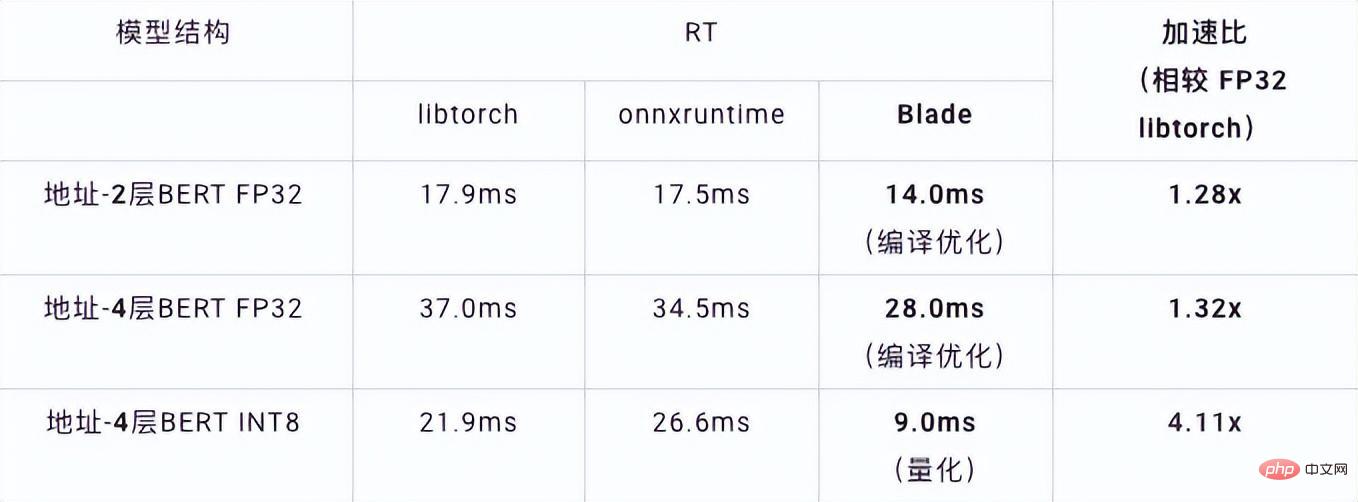
##12-layer BERT-base 77.24 ##Address - Layer 4 BERT ##Address-4-layer BERT Blade compilation optimization
The above is the detailed content of Address standardization service AI deep learning model inference optimization practice. For more information, please follow other related articles on the PHP Chinese website!
 What are the office software
What are the office software
 The role of Apple's Do Not Disturb mode
The role of Apple's Do Not Disturb mode
 What should I do if IE browser prompts a script error?
What should I do if IE browser prompts a script error?
 What is the difference between rabbitmq and kafka
What is the difference between rabbitmq and kafka
 What is the transfer limit of Alipay?
What is the transfer limit of Alipay?
 What is Spring MVC
What is Spring MVC
 Common encryption methods for data encryption storage
Common encryption methods for data encryption storage
 Introduction to the usage of vbs whole code
Introduction to the usage of vbs whole code





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



