

 Technology peripherals
AI
Transformer unifies voxel-based representations for 3D object detection
Technology peripherals
AI
Transformer unifies voxel-based representations for 3D object detection
Transformer unifies voxel-based representations for 3D object detection

arXiv paper "Unifying Voxel-based Representation with Transformer for 3D Object Detection", June 22, Chinese University of Hong Kong, University of Hong Kong, Megvii Technology (in memory of Dr. Sun Jian) and Simou Technology, etc.

This paper proposes a unified multi-modal 3-D target detection framework called UVTR. This method aims to unify multi-modal representations of voxel space and enable accurate and robust single-modal or cross-modal 3-D detection. To this end, modality-specific spaces are first designed to represent different inputs to the voxel feature space. Preserve voxel space without height compression, alleviate semantic ambiguity and enable spatial interaction. Based on this unified approach, cross-modal interaction is proposed to fully utilize the inherent characteristics of different sensors, including knowledge transfer and modal fusion. In this way, geometry-aware expressions of point clouds and context-rich features in images can be well exploited, resulting in better performance and robustness.
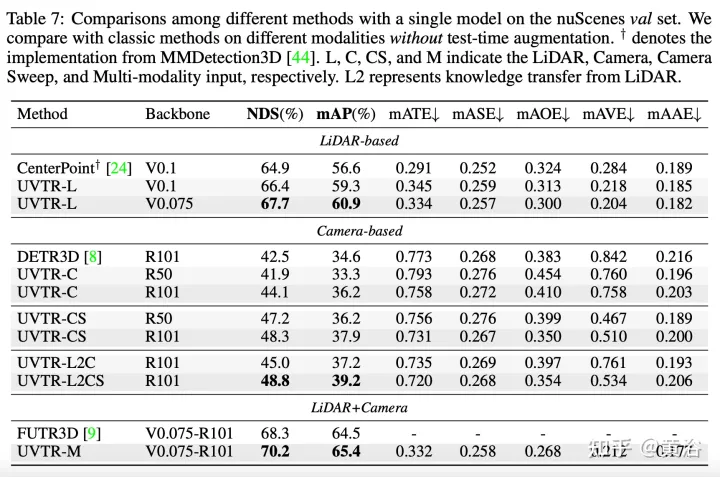
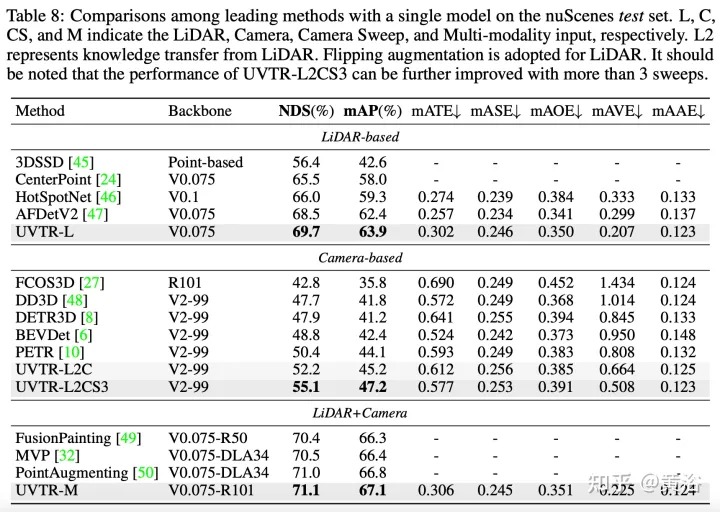
The transformer decoder is used to efficiently sample features from a unified space with learnable locations, which facilitates object-level interactions. Generally speaking, UVTR represents an early attempt to represent different modalities in a unified framework, outperforming previous work on single-modal and multi-modal inputs, achieving leading performance on the nuScenes test set, lidar, camera and The NDS of multi-modal output are 69.7%, 55.1% and 71.1% respectively.
Code:https://github.com/dvlab-research/UVTR.
As shown in the figure:
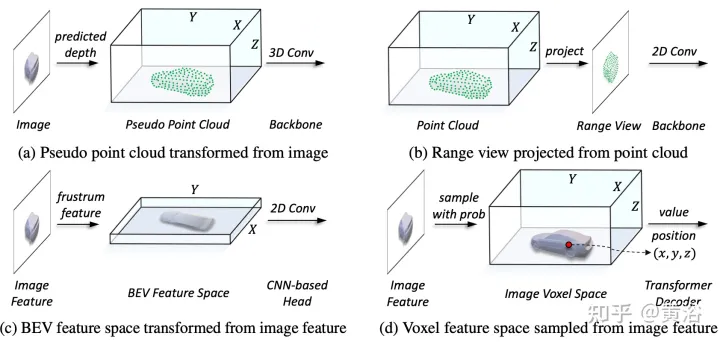
#In the representation unification process, it can be roughly divided into the representation of input-level flow and feature-level flow. For the first approach, multimodal data are aligned at the beginning of the network. In particular, the pseudo point cloud in (a) is converted from the predicted depth-assisted image, while the range view image in (b) is projected from the point cloud. Due to depth inaccuracies in pseudo point clouds and 3-D geometric collapse in range view images, the spatial structure of the data is destroyed, leading to poor results. For feature-level methods, the typical method is to convert image features into frustum and then compress them into BEV space, as shown in Figure (c). However, due to its ray-like trajectory, the height information (height) compression at each position aggregates the features of various targets, thus introducing semantic ambiguity. At the same time, its implicit approach is difficult to support explicit feature interaction in 3-D space and limits further knowledge transfer. Therefore, a more unified representation is needed to bridge the modal gaps and facilitate multifaceted interactions.
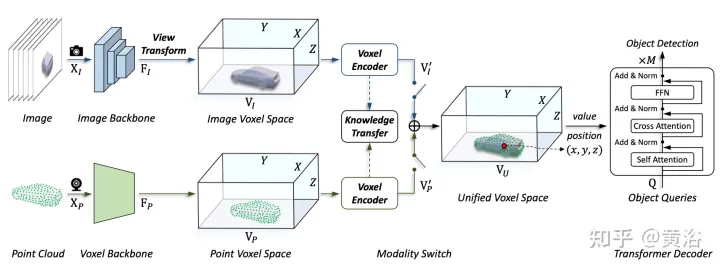
The framework proposed in this article unifies voxel-based representation and transformer. In particular, feature representation and interaction of images and point clouds in voxel-based explicit space. For images, the voxel space is constructed by sampling features from the image plane according to the predicted depth and geometric constraints, as shown in Figure (d). For point clouds, accurate locations naturally allow features to be associated with voxels. Then, a voxel encoder is introduced for spatial interaction to establish the relationship between adjacent features. In this way, cross-modal interactions proceed naturally with features in each voxel space. For target-level interactions, a deformable transformer is used as a decoder to sample target query-specific features at each position (x, y, z) in the unified voxel space, as shown in Figure (d). At the same time, the introduction of 3-D query positions effectively alleviates the semantic ambiguity caused by height information (height) compression in the BEV space.
As shown in the figure is the UVTR architecture of multi-modal input: given a single frame or multi-frame image and point cloud, it is first processed in a single backbone and converted into modality-specific spatial VI and VP, where view transformation is used for images. In voxel encoders, features interact spatially, and knowledge transfer is easy to support during training. Depending on the settings, select single-modal or multi-modal features via the modal switch. Finally, features are sampled from the unified spatial VU with learnable locations and predicted using the transformer decoder.
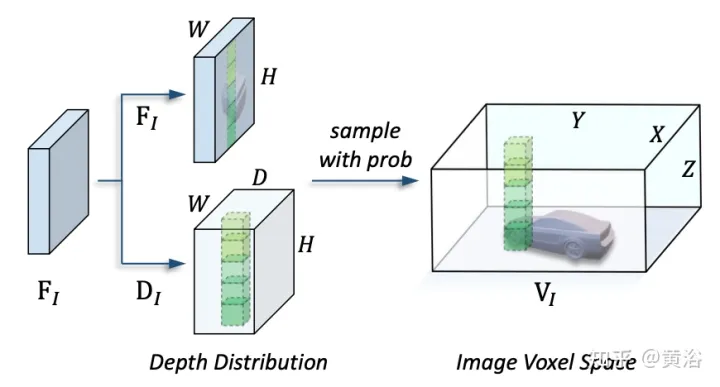
The picture shows the details of the view transformation:
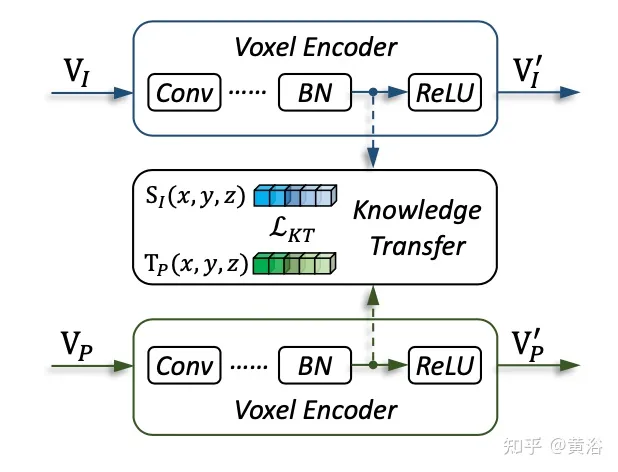
The picture shows the details of the knowledge migration:
The experimental results are as follows:
The above is the detailed content of Transformer unifies voxel-based representations for 3D object detection. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to evaluate the cost-effectiveness of commercial support for Java frameworks
Jun 05, 2024 pm 05:25 PM
How to evaluate the cost-effectiveness of commercial support for Java frameworks
Jun 05, 2024 pm 05:25 PM
Evaluating the cost/performance of commercial support for a Java framework involves the following steps: Determine the required level of assurance and service level agreement (SLA) guarantees. The experience and expertise of the research support team. Consider additional services such as upgrades, troubleshooting, and performance optimization. Weigh business support costs against risk mitigation and increased efficiency.
 How do the lightweight options of PHP frameworks affect application performance?
Jun 06, 2024 am 10:53 AM
How do the lightweight options of PHP frameworks affect application performance?
Jun 06, 2024 am 10:53 AM
The lightweight PHP framework improves application performance through small size and low resource consumption. Its features include: small size, fast startup, low memory usage, improved response speed and throughput, and reduced resource consumption. Practical case: SlimFramework creates REST API, only 500KB, high responsiveness and high throughput
 Golang framework documentation best practices
Jun 04, 2024 pm 05:00 PM
Golang framework documentation best practices
Jun 04, 2024 pm 05:00 PM
Writing clear and comprehensive documentation is crucial for the Golang framework. Best practices include following an established documentation style, such as Google's Go Coding Style Guide. Use a clear organizational structure, including headings, subheadings, and lists, and provide navigation. Provides comprehensive and accurate information, including getting started guides, API references, and concepts. Use code examples to illustrate concepts and usage. Keep documentation updated, track changes and document new features. Provide support and community resources such as GitHub issues and forums. Create practical examples, such as API documentation.
 How does the learning curve of PHP frameworks compare to other language frameworks?
Jun 06, 2024 pm 12:41 PM
How does the learning curve of PHP frameworks compare to other language frameworks?
Jun 06, 2024 pm 12:41 PM
The learning curve of a PHP framework depends on language proficiency, framework complexity, documentation quality, and community support. The learning curve of PHP frameworks is higher when compared to Python frameworks and lower when compared to Ruby frameworks. Compared to Java frameworks, PHP frameworks have a moderate learning curve but a shorter time to get started.
 How to choose the best golang framework for different application scenarios
Jun 05, 2024 pm 04:05 PM
How to choose the best golang framework for different application scenarios
Jun 05, 2024 pm 04:05 PM
Choose the best Go framework based on application scenarios: consider application type, language features, performance requirements, and ecosystem. Common Go frameworks: Gin (Web application), Echo (Web service), Fiber (high throughput), gorm (ORM), fasthttp (speed). Practical case: building REST API (Fiber) and interacting with the database (gorm). Choose a framework: choose fasthttp for key performance, Gin/Echo for flexible web applications, and gorm for database interaction.
 RedMagic Tablet 3D Explorer Edition features glasses-free 3D display
Sep 06, 2024 am 06:45 AM
RedMagic Tablet 3D Explorer Edition features glasses-free 3D display
Sep 06, 2024 am 06:45 AM
The RedMagic Tablet 3D Explorer Edition has launched alongside the Gaming Tablet Pro. However, while the latter is more for gamers, the former is geared more for entertainment. The new Android tablet has what the company calls a "naked-eye 3D&qu
 Detailed practical explanation of golang framework development: Questions and Answers
Jun 06, 2024 am 10:57 AM
Detailed practical explanation of golang framework development: Questions and Answers
Jun 06, 2024 am 10:57 AM
In Go framework development, common challenges and their solutions are: Error handling: Use the errors package for management, and use middleware to centrally handle errors. Authentication and authorization: Integrate third-party libraries and create custom middleware to check credentials. Concurrency processing: Use goroutines, mutexes, and channels to control resource access. Unit testing: Use gotest packages, mocks, and stubs for isolation, and code coverage tools to ensure sufficiency. Deployment and monitoring: Use Docker containers to package deployments, set up data backups, and track performance and errors with logging and monitoring tools.
 Golang framework performance comparison: metrics for making wise choices
Jun 05, 2024 pm 10:02 PM
Golang framework performance comparison: metrics for making wise choices
Jun 05, 2024 pm 10:02 PM
When choosing a Go framework, key performance indicators (KPIs) include: response time, throughput, concurrency, and resource usage. By benchmarking and comparing frameworks' KPIs, developers can make informed choices based on application needs, taking into account expected load, performance-critical sections, and resource constraints.
